







异步爬取
异步爬取即爬取动态URL的数据,在网页源代码中找不到需要的数据只有在F12控制台中通过查看资源请求包才能找到对应的数据了URL。一般动态网页采用AJAX框架,只有在访问时才从服务器获取数据不会提前全部静态展示。 其工作原理如下图:
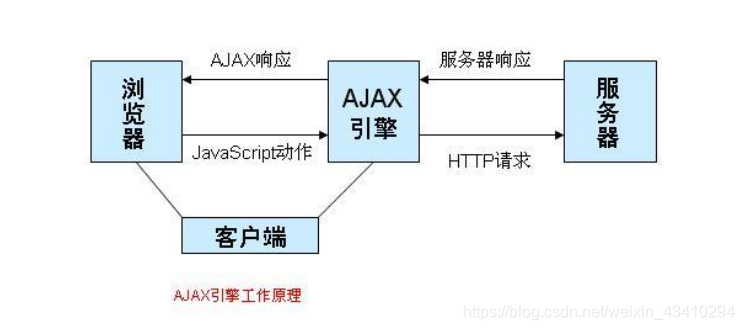
下面以NHK新闻网为例,其URL为link。查看源代码发现不能找到新闻内容,在F12控制台中刷新网页找到含新闻内容的资源包,其中第二页URL为link。以该URL进行爬取数据。
1、导入模块
import json
import re
import urllib.request,urllib.error
2、定义主函数
def main():
url = "https://www3.nhk.or.jp/news/json16/word/0000967_003.json"
AskUrl(url)
print(AskUrl(url))
3、数据爬取
#得到指定一个URL的网页内容
def AskUrl(url):
#head模拟浏览器头部信息,向豆瓣发送消息
#User-Agent告诉豆瓣服务器,我们为xxx浏览器(伪装)
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
request = urllib.request.Request(url,headers=head) #封装请求
html = ""
try:
response = urllib.request.urlopen(request) #发送请求
html = response.read().decode("gbk") #读取解码返回值
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):#出错代码
print(e.code)
if hasattr(e,"reason"):#出错原因
print(e.reason)
return html
注意:获取到的网页源代码中含有的新闻信息是json字符串格式,利用正则表达式筛选需要的数据后需要利用json.loads()函数将json字符串转为字典类型再作处理。














 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









