






1. 概述
应用程序注册信号,信号事件发生后,内核将信号置为pending状态,在中断返回或者系统调用返回时,查看pending的信号,内核在应用程序的栈上构建一个信号处理栈帧,然后通过中断返回或者系统调用返回到用户态,执行信号处理函数。执行信号处理函数之后,再次通过sigreturn系统调用返回到内核,在内核中再次返回到应用程序被中断打断的地方或者系统调用返回的地方接着运行。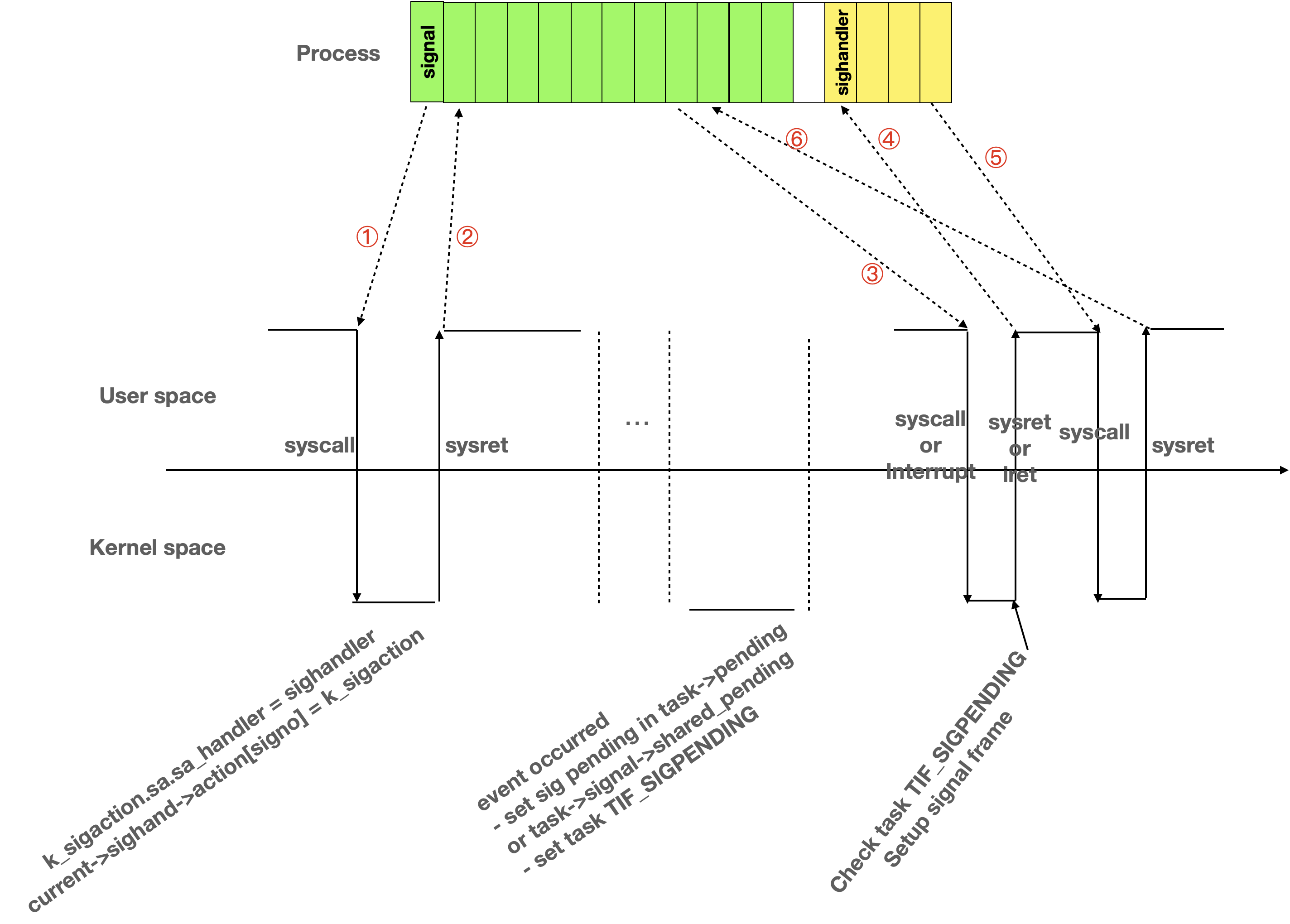
如果应用程序没有注册对应的信号处理函数,那么信号发生后,内核按照内核默认的信号处理方式处理该信号,比如访问非法内存地址,发生SIGSEGV,内核将进程终止。
2. 基本数据结构
- task_strcut
struct task_struct {
...
struct signal_struct *signal; // 指向线程组的struct signal结构体
struct sighand_struct *sighand; // 描述的action,即信号发生后,如何处理
sigset_t blocked, real_blocked; // 该线程阻塞的信号,信号被阻塞,但是可以pending
// 当取消阻塞后,就可以执行信号处理
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending; // 该线程的pending信号
unsigned long sas_ss_sp; // 用户执行信号执行栈、栈大小、flag
size_t sas_ss_size; // 可以通过系统调用sigaltstack指定
unsigned sas_ss_flags;
...
};
- signal_struct
struct signal_struct {
...
/* shared signal handling: */
struct sigpending shared_pending; // 线程组的pending信号
...
}
- sighand_struct
struct sighand_struct {
atomic_t count;
struct k_sigaction action[_NSIG]; // 描述信号的action,即信号发生时,如何处理该信号
spinlock_t siglock;
wait_queue_head_t signalfd_wqh;
};
- sigpending
struct sigpending {
struct list_head list; // sigqueue的链表头,用来链接处于pending状态的信号
sigset_t signal; // 处于Pending的sig号集合
};
- sigset_t
#define _NSIG_WORDS (_NSIG / _NSIG_BPW)
typedef struct {
unsigned long sig[_NSIG_WORDS]; // 是一个位掩码,对应的信号会置位/清零
} sigset_t;
这些数据结构组织在一起,如下图。每个线程有一个自己私有的信号pending链表,链表上是发送给该线程,需要该线程自己去处理的信号。struct sigpending的成员head_list是pending信号sigqueue的链表头,成员signal是这些pending信号的信号编号掩码。
另外,属于同一个进程的线程组共享一个信号pending链表,这个链表上的信号没有绑定特定的线程,该线程租中的任意线程都可以处理。
线程组还共享sighand数据结构,里面有64个信号的action。每个action用来描述如何处理该信号,比如忽略、默认方式处理、或者执行用户注册的信号handler。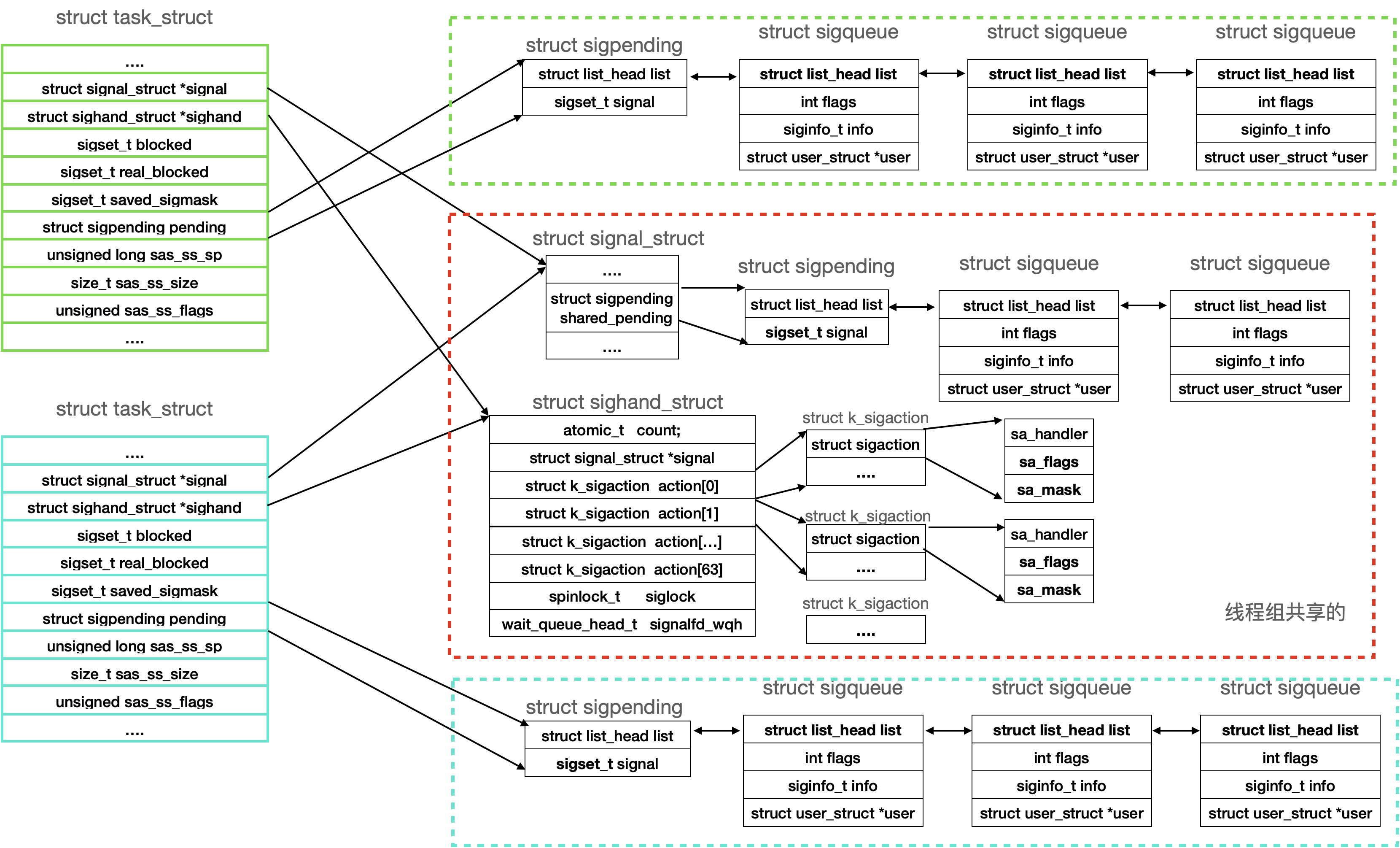
3. 注册信号
用户态的应用程序通过系统调用函数signal或者函数sigaction注册一个信号服务,当进程或者线程接收到信号后,调用注册的信号服务函数。
虽然现在内核源码中kernel/signal.c中有定义signal系统调用,但是libc库中使用系统调用sigaction实现应用程序中使用的signal函数。
3.1 内核中sigaction系统调用
内核kernel/signal.c中定义了系统调用sigaction函数。
该系统调用的功能是为信号sig注册新的信号action,同时返回旧的信号action。如果输入参数act为空,则不注册新的信号action,如果输出参数oact为空,则不返回老的信号action。
sigaction系统调用函数代码主要流程:
如果输入参数act不为空,检查act的合法性,并读取act的各个成员,然后赋值个局部变量new_ka
调用do_sigaction做底层的工作
如果输出参数oact不为空,检查oact的合法性,并将旧的信号action通过oact返回
#ifdef CONFIG_COMPAT_OLD_SIGACTION
COMPAT_SYSCALL_DEFINE3(sigaction, int, sig,
const struct compat_old_sigaction __user *, act,
struct compat_old_sigaction __user *, oact)
{
struct k_sigaction new_ka, old_ka;
int ret;
compat_old_sigset_t mask;
compat_uptr_t handler, restorer;
if (act) {
if (!access_ok(VERIFY_READ, act, sizeof(*act)) ||
__get_user(handler, &act->sa_handler) ||
__get_user(restorer, &act->sa_restorer) ||
__get_user(new_ka.sa.sa_flags, &act->sa_flags) ||
__get_user(mask, &act->sa_mask))
return -EFAULT;
#ifdef __ARCH_HAS_KA_RESTORER
new_ka.ka_restorer = NULL;
#endif
new_ka.sa.sa_handler = compat_ptr(handler);
new_ka.sa.sa_restorer = compat_ptr(restorer);
siginitset(&new_ka.sa.sa_mask, mask);
}
ret = do_sigaction(sig, act ? &new_ka : NULL, oact ? &old_ka : NULL);
if (!ret && oact) {
if (!access_ok(VERIFY_WRITE, oact, sizeof(*oact)) ||
__put_user(ptr_to_compat(old_ka.sa.sa_handler),
&oact->sa_handler) ||
__put_user(ptr_to_compat(old_ka.sa.sa_restorer),
&oact->sa_restorer) ||
__put_user(old_ka.sa.sa_flags, &oact->sa_flags) ||
__put_user(old_ka.sa.sa_mask.sig[0], &oact->sa_mask))
return -EFAULT;
}
return ret;
}
#endif
do_sigaction函数代码流程:
检查sig是否是合法值。这里除了检查sig数值的合法性,也要求用户不能注册SIGKILL和SIGSTOP信号action,这两种信号由内核处理,应用程序不能拦截。
将信号sig的action注册到sighand数组中,并返回旧的action
如果新注册的信号为可忽略信号,那么丢弃线程组共享的pending链表和线程组内各线程私有的pending链表中已经pending的sigqueue.
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
struct task_struct *p = current, *t;
struct k_sigaction *k;
sigset_t mask;
// 检查sig是否是合法值:
// 1. 1 <= sig <= _NSIG
// 2. sig不是Kernel特有的:SIGKILL, SIGSTOP,
// 内核不允许注册SIGKILL, SIGSTOP的信号处理函数,这两种信号由内核自己处理
if (!valid_signal(sig) || sig < 1 || (act && sig_kernel_only(sig)))
return -EINVAL;
k = &p->sighand->action[sig-1];
spin_lock_irq(&p->sighand->siglock);
// 返回旧的信号action
if (oact)
*oact = *k;
sigaction_compat_abi(act, oact);
if (act) {
// 确保act->sa.sa_mask中没有SIGKILL和SIGSTOP
sigdelsetmask(&act->sa.sa_mask,
sigmask(SIGKILL) | sigmask(SIGSTOP));
*k = *act; // 赋值新的信号action
/*
* POSIX 3.3.1.3:
* "Setting a signal action to SIG_IGN for a signal that is
* pending shall cause the pending signal to be discarded,
* whether or not it is blocked."
*
* "Setting a signal action to SIG_DFL for a signal that is
* pending and whose default action is to ignore the signal
* (for example, SIGCHLD), shall cause the pending signal to
* be discarded, whether or not it is blocked"
*/
// 如果当前进程忽略该信号:1. handler == IGNR
// 或者
// 2. handler == DFLT && (sig为SIGCONT | SIGCHLD | SIGWINCH |SIGURG之一)
// 那么,丢弃已经pending的信号
if (sig_handler_ignored(sig_handler(p, sig), sig)) {
sigemptyset(&mask);
sigaddset(&mask, sig);
// 清除共享信号中该sig的pending信号
flush_sigqueue_mask(&mask, &p->signal->shared_pending);
// 清除线程组中其他新线程该sig的pending信号
for_each_thread(p, t)
flush_sigqueue_mask(&mask, &t->pending);
}
}
spin_unlock_irq(&p->sighand->siglock);
return 0;
}
注:创建进程时,会将该进程的所有线程添加到task_struct中signal->thread_head链表中
4. send_signal 发送信号
发送信号,即在进程共享信号pending链表或者线程信号pending链表中添加一个信号sigqueue,并置信号接收者TIF_SIGPENDING位。如果信号接收者在此时没有在运行,那么直接唤醒;如果正在运行,有可能在用户态运行,那么kick_process给信号接收者发送一个IPI,让其进入一次kernel。最终,信号处理是在线程由内核返回用户态的时候,检查线程的TIF_SIGPENDING是否有置位,如果有,就执行信号的服务函数。
static int send_signal(int sig, struct siginfo *info, struct task_struct *t,
enum pid_type type)
{
int from_ancestor_ns = 0;
#ifdef CONFIG_PID_NS
from_ancestor_ns = si_fromuser(info) &&
!task_pid_nr_ns(current, task_active_pid_ns(t));
#endif
return __send_signal(sig, info, t, type, from_ancestor_ns);
}
__send_signal是发送信号的核心,代码执行流程:
- 检查信号是否可以被发送
- 决定将信号挂载到线程私有的pending链表还是线程组共享的pending链表上
- 分配sigqueue结构,并初始化,链接到pending链表上
- 唤醒目标线程,尽快去相应信号
static int __send_signal(int sig, struct siginfo *info, struct task_struct *t,
enum pid_type type, int from_ancestor_ns)
{
struct sigpending *pending;
struct sigqueue *q;
int override_rlimit;
int ret = 0, result;
assert_spin_locked(&t->sighand->siglock);
result = TRACE_SIGNAL_IGNORED;
// 检查是否可以发送该信号
// 1. 如果当前进程正在退出,或者出于coredump状态,同时要发送的信号是SIG_KILL,那么不需要发送该信号
// 2. 如果信号没有被阻塞
if (!prepare_signal(sig, t,
from_ancestor_ns || (info == SEND_SIG_FORCED)))
goto ret;
// 判断信号是发送给线程私有的pending链表还是给线程组的pending链表
pending = (type != PIDTYPE_PID) ? &t->signal->shared_pending : &t->pending;
/*
* Short-circuit ignored signals and support queuing
* exactly one non-rt signal, so that we can get more
* detailed information about the cause of the signal.
*/
result = TRACE_SIGNAL_ALREADY_PENDING;
// 如果legacy信号(sig < SIGRTMIN),而且该信号在pending链表中已经存在,那么不需要再发送
// 言外之意,如果信号不是legacy信号,或者pending链表中不存在该信号,就需要发送
// SIGRTMIN <= sig <= SIGRTMAX的信号实时信号,这些信号可以被发送多次。
if (legacy_queue(pending, sig))
goto ret;
result = TRACE_SIGNAL_DELIVERED;
/*
* fast-pathed signals for kernel-internal things like SIGSTOP
* or SIGKILL.
*/
// SEND_SIG_FORCED不用pending ??? 还不是很明白
if (info == SEND_SIG_FORCED)
goto out_set;
/*
* Real-time signals must be queued if sent by sigqueue, or
* some other real-time mechanism. It is implementation
* defined whether kill() does so. We attempt to do so, on
* the principle of least surprise, but since kill is not
* allowed to fail with EAGAIN when low on memory we just
* make sure at least one signal gets delivered and don't
* pass on the info struct.
*/
// 判断在分配sigqueue时,是否可以突破RLIMIT_SIGPENDING的限制
// 允许pend的信号个数受RLIMIT_SIGPENDING的限制
if (sig < SIGRTMIN)
override_rlimit = (is_si_special(info) || info->si_code >= 0);
else
override_rlimit = 0;
// 分配sigqueue结构,将其挂载在pending链表上
q = __sigqueue_alloc(sig, t, GFP_ATOMIC, override_rlimit);
if (q) {
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
clear_siginfo(&q->info);
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current,
task_active_pid_ns(t));
q->info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
break;
case (unsigned long) SEND_SIG_PRIV:
clear_siginfo(&q->info);
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
userns_fixup_signal_uid(&q->info, t);
// 没有分配到sigqueue
// 如果不是特殊的info
} else if (!is_si_special(info)) {
if (sig >= SIGRTMIN && info->si_code != SI_USER) {
/*
* Queue overflow, abort. We may abort if the
* signal was rt and sent by user using something
* other than kill().
*/
result = TRACE_SIGNAL_OVERFLOW_FAIL;
ret = -EAGAIN;
goto ret;
} else {
/*
* This is a silent loss of information. We still
* send the signal, but the *info bits are lost.
*/
result = TRACE_SIGNAL_LOSE_INFO;
}
}
out_set:
// 通知signalfd
signalfd_notify(t, sig);
// 将该信号添加到pending信号的掩码中
sigaddset(&pending->signal, sig);
/* Let multiprocess signals appear after on-going forks */
if (type > PIDTYPE_TGID) {
struct multiprocess_signals *delayed;
hlist_for_each_entry(delayed, &t->signal->multiprocess, node) {
sigset_t *signal = &delayed->signal;
/* Can't queue both a stop and a continue signal */
if (sig == SIGCONT)
sigdelsetmask(signal, SIG_KERNEL_STOP_MASK);
else if (sig_kernel_stop(sig))
sigdelset(signal, SIGCONT);
sigaddset(signal, sig);
}
}
// 如果线程t可以接收该信号,那么t就是目标线程
// 如果是发送个线程组的信号,从组内找一个可以接收该信号的线程
// 如果这个信号是fatal信号,必须要让进程退出。发送SIGKILL信号给进程组线程,
// 并唤醒线程,尽快执行进程退出, 然后返回
// 最后,唤醒目标线程,尽快执行信号
complete_signal(sig, t, type);
ret:
trace_signal_generate(sig, info, t, type != PIDTYPE_PID, result);
return ret;
}
5. 信号处理
内核只有在系统调用返回用户态或者中断返回用户态的时候检查线程的**_TIF_SIGPENDING**标志,如果该标志置位,则进行信号处理。
提示:内核线程不会收到信号,信号是针对用户线程或者进程的一种异步机制。
5.1 信号处理的调用栈:
// call stack
do_syscall_64()
|-> syscall_return_slowpath()
|-> prepare_exit_to_usermode()
|-> exit_to_usermode_loop()
|-> do_signal(regs)
//或者
common_interrupt()
|-> do_IRQ()
|-> retint_user()
|-> prepare_exit_to_usermode()
|-> exit_to_usermode_loop()
|-> do_signal()
5.2 信号处理do_signal
如果当前线程的_TIF_SIGPENDING置位,表明该线程有pending信号需要处理。通过函数do_signal来处理pending信号。 do_signal函数和架构相关,x86的的do_signal函数定义在arch/x86/kernel/signal.c。 do_signal代码流程为: 如果获取到一个需要投递到用户态执行的信号,调用handle_signal投递信号。该函数返回后,要么通过中断返回,要么通过系统调用返回到用户态,执行这个信号的handler。 如果没有获取到,说明pending的信号在内核里面已经被处理了。对于系统调用,该系统调用可能是被信号打断。判断系统调用的返回值,决定是否需要重新执行该系统调用。 最后,如果没有信号pending的情形,如果标记了线程TIF_RESTORE_SIGMASK标记,表明需要恢复线程的阻塞mask,那么把current->saved_sigmask恢复到current->blocked。 提示:对于一些系统调用,如sigsuspend,epoll_pwait等,在线程睡眠等待的时候,会重新设置信号的阻塞mask,并保存原来的阻塞mask。当系统调用执行完成后,需要恢复原来的阻塞mask。如果需要恢复,那么置位线程TIF_RESTORE_SIGMASK标记,在所有的pending信号处理完后恢复原来的阻塞mask。
void do_signal(struct pt_regs *regs)
{
struct ksignal ksig;
if (get_signal(&ksig)) {
/* Whee! Actually deliver the signal. */
// 投递这个信号,在用户态执行用户注册的信号handler
handle_signal(&ksig, regs);
return;
}
/* Did we come from a system call? */
// do_signal函数有可能是从中断返回用户态时调用,也有可能是系统调用返回用户态时调用。
// 在中断的入口处,将中断号已经调整为[-256, -1],regs->origin_rax为中断号;
// 在异常的入口处,将regs->origin_rax的值填充为-1。
// 而系统调用的regs->origin_rax是系统调用号,为正数。
// 进而,可以通过regs->origin_rax 确认是否来自系统调用。
// 如果此处是后者,那么获取系统调用的返回错误码errno
// 将返回用户态的ip地址向后移动2个字节(syscall指令是两个字节),
// CPU返回后重新执行该系统调用
if (syscall_get_nr(current, regs) >= 0) {
/* Restart the system call - no handlers present */
switch (syscall_get_error(current, regs)) {
case -ERESTARTNOHAND:
case -ERESTARTSYS:
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
case -ERESTART_RESTARTBLOCK:
regs->ax = get_nr_restart_syscall(regs);
regs->ip -= 2;
break;
}
}
/*
* If there's no signal to deliver, we just put the saved sigmask
* back.
*/
// 恢复之前的task阻塞的sig mask
restore_saved_sigmask();
}
5.2.1 获取需要投递的pending信号
get_signal函数从线程私有的pending链表或者线程组共享的pending链表中,找到pending信号,如果需要投递到用户态去执行,返回1。如果没有需要投递到用户态去执行的pending信号,返回0。如果遇到需要kernel处理的信号,在该函数内部就会消化掉。
struct ksignal {
struct k_sigaction ka;
siginfo_t info;
int sig;
};
struct k_sigaction {
struct sigaction sa;
#ifdef __ARCH_HAS_KA_RESTORER
__sigrestore_t ka_restorer;
#endif
};
struct sigaction {
#ifndef __ARCH_HAS_IRIX_SIGACTION
__sighandler_t sa_handler;
unsigned long sa_flags;
#else
unsigned int sa_flags;
__sighandler_t sa_handler;
#endif
#ifdef __ARCH_HAS_SA_RESTORER
__sigrestore_t sa_restorer;
#endif
sigset_t sa_mask; /* mask last for extensibility */
};
get_signal代码流程为:
查看当前进程是否有task work需要处理,如果有,执行注册的task work回调函数。task_work和信号毫不相关,不知放在这里是何意思!
忽略调试、子进程STOP/CONTINUE运行通知父进程相关逻辑
如果当前进程需要退出,那么直接之心退出逻辑do_group_exit
获取(dequeue)一个pending信号,如果该信号的handler是SIG_IGN,那么忽略之,继续找下一个;如果handler不是SIG_DFL,那么是该信号内核不能直接处理,需要执行用户注册的信号处理函数,get_signal返回,调用信号注册的handler;如果信号的handler是SIG_DFL,进而细分:1)内核忽略这种信号,2)内核执行相应的stop进程流程。
int get_signal(struct ksignal *ksig)
{
struct sighand_struct *sighand = current->sighand;
struct signal_struct *signal = current->signal;
int signr;
// 有task_work需要处理,比如numa work
if (unlikely(current->task_works))
task_work_run();
// 调试相关,暂时忽略
if (unlikely(uprobe_deny_signal()))
return 0;
/*
* Do this once, we can't return to user-mode if freezing() == T.
* do_signal_stop() and ptrace_stop() do freezable_schedule() and
* thus do not need another check after return.
*/
try_to_freeze();
relock:
spin_lock_irq(&sighand->siglock);
/*
* Every stopped thread goes here after wakeup. Check to see if
* we should notify the parent, prepare_signal(SIGCONT) encodes
* the CLD_ si_code into SIGNAL_CLD_MASK bits.
*/
// 这部分和子进程stop/continue相关,暂且忽略
if (unlikely(signal->flags & SIGNAL_CLD_MASK)) {
int why;
if (signal->flags & SIGNAL_CLD_CONTINUED)
why = CLD_CONTINUED;
else
why = CLD_STOPPED;
signal->flags &= ~SIGNAL_CLD_MASK;
spin_unlock_irq(&sighand->siglock);
/*
* Notify the parent that we're continuing. This event is
* always per-process and doesn't make whole lot of sense
* for ptracers, who shouldn't consume the state via
* wait(2) either, but, for backward compatibility, notify
* the ptracer of the group leader too unless it's gonna be
* a duplicate.
*/
read_lock(&tasklist_lock);
do_notify_parent_cldstop(current, false, why);
if (ptrace_reparented(current->group_leader))
do_notify_parent_cldstop(current->group_leader,
true, why);
read_unlock(&tasklist_lock);
goto relock;
}
/* Has this task already been marked for death? */
// 进程在退出中,认为找到了SIGKILL信号是pending信号
if (signal_group_exit(signal)) {
ksig->info.si_signo = signr = SIGKILL;
sigdelset(¤t->pending.signal, SIGKILL);
trace_signal_deliver(SIGKILL, SEND_SIG_NOINFO,
&sighand->action[SIGKILL - 1]);
// 重新评估是否有信号pending,如果再没有信号pending,(而且当前线程没有被freeze)
// 则清除task的TIF_SIGPENDING位。
recalc_sigpending();
goto fatal;
}
for (;;) {
struct k_sigaction *ka;
if (unlikely(current->jobctl & JOBCTL_STOP_PENDING) &&
do_signal_stop(0))
goto relock;
if (unlikely(current->jobctl & JOBCTL_TRAP_MASK)) {
do_jobctl_trap();
spin_unlock_irq(&sighand->siglock);
goto relock;
}
/*
* Signals generated by the execution of an instruction
* need to be delivered before any other pending signals
* so that the instruction pointer in the signal stack
* frame points to the faulting instruction.
*/
// 先找同步信号,如果没有找到,
signr = dequeue_synchronous_signal(&ksig->info);
if (!signr)
signr = dequeue_signal(current, ¤t->blocked, &ksig->info);
if (!signr)
break; /* will return 0 */
// 如果当前进程被ptrace, 处理trace信号。可以参考ptrace的系统调用,
// 在ptrace_traceme()中,设置current->ptrace,然后发送SIG_TRAP信号,
// 在此处理trap信号。
if (unlikely(current->ptrace) && signr != SIGKILL) {
signr = ptrace_signal(signr, &ksig->info);
if (!signr)
continue;
}
// 获取信号注册的action
ka = &sighand->action[signr-1];
/* Trace actually delivered signals. */
trace_signal_deliver(signr, &ksig->info, ka);
// 如果信号的handler是SIG_IGN,那么忽略该信号
if (ka->sa.sa_handler == SIG_IGN) /* Do nothing. */
continue;
// 该信号有对应的非默认handler,那么返回action到ksig->ka
if (ka->sa.sa_handler != SIG_DFL) {
/* Run the handler. */
ksig->ka = *ka;
// 该信号是一次性的,恢复信号的hanler为默认
if (ka->sa.sa_flags & SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
break; /* will return non-zero "signr" value */
}
// 至此,信号的处理函数是默认处理函数,需要内核去按照默认的方式去处理
/*
* Now we are doing the default action for this signal.
*/
// 内核忽略该信号
if (sig_kernel_ignore(signr)) /* Default is nothing. */
continue;
/*
* Global init gets no signals it doesn't want.
* Container-init gets no signals it doesn't want from same
* container.
*
* Note that if global/container-init sees a sig_kernel_only()
* signal here, the signal must have been generated internally
* or must have come from an ancestor namespace. In either
* case, the signal cannot be dropped.
*/
if (unlikely(signal->flags & SIGNAL_UNKILLABLE) &&
!sig_kernel_only(signr))
continue;
// stop signal handler
if (sig_kernel_stop(signr)) {
/*
* The default action is to stop all threads in
* the thread group. The job control signals
* do nothing in an orphaned pgrp, but SIGSTOP
* always works. Note that siglock needs to be
* dropped during the call to is_orphaned_pgrp()
* because of lock ordering with tasklist_lock.
* This allows an intervening SIGCONT to be posted.
* We need to check for that and bail out if necessary.
*/
if (signr != SIGSTOP) {
spin_unlock_irq(&sighand->siglock);
/* signals can be posted during this window */
if (is_current_pgrp_orphaned())
goto relock;
spin_lock_irq(&sighand->siglock);
}
if (likely(do_signal_stop(ksig->info.si_signo))) {
/* It released the siglock. */
goto relock;
}
/*
* We didn't actually stop, due to a race
* with SIGCONT or something like that.
*/
continue;
}
fatal:
spin_unlock_irq(&sighand->siglock);
/*
* Anything else is fatal, maybe with a core dump.
*/
current->flags |= PF_SIGNALED;
if (sig_kernel_coredump(signr)) {
if (print_fatal_signals)
print_fatal_signal(ksig->info.si_signo);
proc_coredump_connector(current);
/*
* If it was able to dump core, this kills all
* other threads in the group and synchronizes with
* their demise. If we lost the race with another
* thread getting here, it set group_exit_code
* first and our do_group_exit call below will use
* that value and ignore the one we pass it.
*/
do_coredump(&ksig->info);
}
/*
* Death signals, no core dump.
*/
// 进程退出流程
do_group_exit(ksig->info.si_signo);
/* NOTREACHED */
}
spin_unlock_irq(&sighand->siglock);
ksig->sig = signr;
return ksig->sig > 0;
}
5.2.1.1 dequeue 同步信号
从pending list取出一个同步信号。代码流程为:
判断非阻塞的pending信号里面是否有同步信号,如果没有就返回0
如果有,从pending 链表里面找到一个同步信号
接着判断链表后面是否还有该信号pending,分两种情况:1)没有找到,将该信号从pending->signal移除,重新评估pending信号,决定是否移除任务的TIF_SIGPENDING。后面和2)相同。2)将当前找到的信号从pending链表中删除,复制该信号的info到返回值,释放该信号的sigqueue结构体。
| 没有找到 | 找到 |
|---|---|
| 将信号移除pending->signal, 重新评估pending信号 | - |
| 将当前信号移除链表 | 将当前信号移除链表 |
| 复制该信号的info | 复制该信号的info |
| 释放该信号的sigqueue结构体 | 该信号的sigqueue结构体 |
static int dequeue_synchronous_signal(siginfo_t *info)
{
struct task_struct *tsk = current;
struct sigpending *pending = &tsk->pending;
struct sigqueue *q, *sync = NULL;
/*
* Might a synchronous signal be in the queue?
*/
// 检查Pending的非阻塞信号里面,是否有同步信号。
// 同步信号包括:SIGSEGV, SIGBUS, SIGILL, SIGTRAP, SIGFPE, SIGSYS
if (!((pending->signal.sig[0] & ~tsk->blocked.sig[0]) & SYNCHRONOUS_MASK))
return 0;
/*
* Return the first synchronous signal in the queue.
*/
list_for_each_entry(q, &pending->list, list) {
/* Synchronous signals have a postive si_code */
if ((q->info.si_code > SI_USER) &&
(sigmask(q->info.si_signo) & SYNCHRONOUS_MASK)) {
sync = q;
// 找到一个同步信号,下面检查pending list里面是否还有
// 该信号pending(允许相同信号pending多次)
goto next;
}
}
// 没有找到
return 0;
next:
/*
* Check if there is another siginfo for the same signal.
*/
list_for_each_entry_continue(q, &pending->list, list) {
if (q->info.si_signo == sync->info.si_signo)
// 该信号被pending至少两次,那么不用从pending->signal移除该信号
goto still_pending;
}
// 移除该信号,并重新评估信号,决定是否清除TIF_SIGPENDING
sigdelset(&pending->signal, sync->info.si_signo);
recalc_sigpending();
still_pending:
list_del_init(&sync->list);
copy_siginfo(info, &sync->info);
__sigqueue_free(sync);
return info->si_signo;
}
5.2.1.2 dequeue普通信号
从信号的pending list里面取出一个非block的信号。
代码流程为:
先尝试从当前task的pending list里面找有没有非屏蔽的信号
如果当前task的pending list里面没有找到,再尝试从进程共享shared_pending链表里面找
函数__dequeue_signal()如果找到pend信号,会将信号从对应的sigset和pending list中移除。
上面两步如果找到信号,同时会通过resched_timer判断该信号是否是timer定时时间到信号。这中类型的timer是POSIX timers。函数最后,会重新调度该timer,即设置timer的下一次超时时间,如果timer请求需要重新调度,在do_schedule_next_timer中实现。
如果在shared_pending中找到pending的信号是SIGALRM信号,同样需要重新设定timer的超时时间。
如果是STOP信号,设置当前任务的current->jobctl |= JOBCTL_STOP_DEQUEUED位。
int dequeue_signal(struct task_struct *tsk, sigset_t *mask, siginfo_t *info)
{
bool resched_timer = false;
int signr;
/* We only dequeue private signals from ourselves, we don't let
* signalfd steal them
*/
signr = __dequeue_signal(&tsk->pending, mask, info, &resched_timer);
if (!signr) {
signr = __dequeue_signal(&tsk->signal->shared_pending,
mask, info, &resched_timer);
/*
* itimer signal ?
*
* itimers are process shared and we restart periodic
* itimers in the signal delivery path to prevent DoS
* attacks in the high resolution timer case. This is
* compliant with the old way of self-restarting
* itimers, as the SIGALRM is a legacy signal and only
* queued once. Changing the restart behaviour to
* restart the timer in the signal dequeue path is
* reducing the timer noise on heavy loaded !highres
* systems too.
*/
if (unlikely(signr == SIGALRM)) {
struct hrtimer *tmr = &tsk->signal->real_timer;
if (!hrtimer_is_queued(tmr) &&
tsk->signal->it_real_incr.tv64 != 0) {
hrtimer_forward(tmr, tmr->base->get_time(),
tsk->signal->it_real_incr);
hrtimer_restart(tmr);
}
}
}
recalc_sigpending();
if (!signr)
return 0;
if (unlikely(sig_kernel_stop(signr))) {
/*
* Set a marker that we have dequeued a stop signal. Our
* caller might release the siglock and then the pending
* stop signal it is about to process is no longer in the
* pending bitmasks, but must still be cleared by a SIGCONT
* (and overruled by a SIGKILL). So those cases clear this
* shared flag after we've set it. Note that this flag may
* remain set after the signal we return is ignored or
* handled. That doesn't matter because its only purpose
* is to alert stop-signal processing code when another
* processor has come along and cleared the flag.
*/
current->jobctl |= JOBCTL_STOP_DEQUEUED;
}
if (resched_timer) {
/*
* Release the siglock to ensure proper locking order
* of timer locks outside of siglocks. Note, we leave
* irqs disabled here, since the posix-timers code is
* about to disable them again anyway.
*/
spin_unlock(&tsk->sighand->siglock);
do_schedule_next_timer(info);
spin_lock(&tsk->sighand->siglock);
}
return signr;
}
5.2.2 handle_signal
在系统调用返回的时执行handle_signal函数,从系统调用的栈帧里读取系统调用号,如果大于零,则说明handlde_signal是从系统调用路调用的。
补充: 异常、中断、系统调用的栈帧结构都一样,但是origin_rax的值不一样。对于中断异常,origiin_rax < 0, 对于系统调用,origin_rax >=0
读取系统调用的errno值,判断系统是成功执行完成,还是被中断打断。对于一些errno,表明需要重新执行系统调用,那么将返回的IP -2,等到执行外信号的处理函数后,CPU返回到用户态,会再次执行syscall指令。
构建信号处理的栈帧。这部分在函数setup_rt_frame()中完成。
static void
handle_signal(struct ksignal *ksig, struct pt_regs *regs)
{
bool stepping, failed;
struct fpu *fpu = ¤t->thread.fpu;
if (v8086_mode(regs))
save_v86_state((struct kernel_vm86_regs *) regs, VM86_SIGNAL);
/* Are we from a system call? */
// 在系统调用返回的时候调用handle_signal()函数
if (syscall_get_nr(current, regs) >= 0) {
/* If so, check system call restarting.. */
switch (syscall_get_error(current, regs)) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->ax = -EINTR; // 标记系统调用被中断打断
break;
case -ERESTARTSYS:
if (!(ksig->ka.sa.sa_flags & SA_RESTART)) {
regs->ax = -EINTR;
break;
}
/* fallthrough */
// 需要重新执行系统调用
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
}
}
/*
* If TF is set due to a debugger (TIF_FORCED_TF), clear TF now
* so that register information in the sigcontext is correct and
* then notify the tracer before entering the signal handler.
*/
stepping = test_thread_flag(TIF_SINGLESTEP);
if (stepping)
user_disable_single_step(current);
// 为在用户态执行信号回调函数建立栈帧
// 解释:由于信号回调函数是用户态的函数,由于权限原因不能直接在内核执行,所以此时CPU要回到用户态,
// 执行信号处理函数,而后再次通过一个特殊的信号处理相关的系统调用进入内核,内核最后
// 完成原来系统调用的返回。此处就是建立一个栈帧,以便CPU返回到用户态后CPU转向执行信号handler
failed = (setup_rt_frame(ksig, regs) < 0);
if (!failed) {
/*
* Clear the direction flag as per the ABI for function entry.
*
* Clear RF when entering the signal handler, because
* it might disable possible debug exception from the
* signal handler.
*
* Clear TF for the case when it wasn't set by debugger to
* avoid the recursive send_sigtrap() in SIGTRAP handler.
*/
regs->flags &= ~(X86_EFLAGS_DF|X86_EFLAGS_RF|X86_EFLAGS_TF);
/*
* Ensure the signal handler starts with the new fpu state.
*/
if (fpu->fpstate_active)
fpu__clear(fpu);
}
signal_setup_done(failed, ksig, stepping);
}
5.2.2.1 setup_rt_frame
setup_rt_frame函数的核心是,在线程的用户态栈上构建一个栈帧,初始化栈帧,包括将系统调用的栈帧信息记录在这个栈帧上,为信号handler函数准备参数,CPU从系统调用返回后(并不是真实的系统调用返回,而是返回到信号的handler),开始执行信号handler,执行完成之后,再通过系统调用sigreturn返回到内核,最后在内核再次恢复上一个系统调用的真正返回。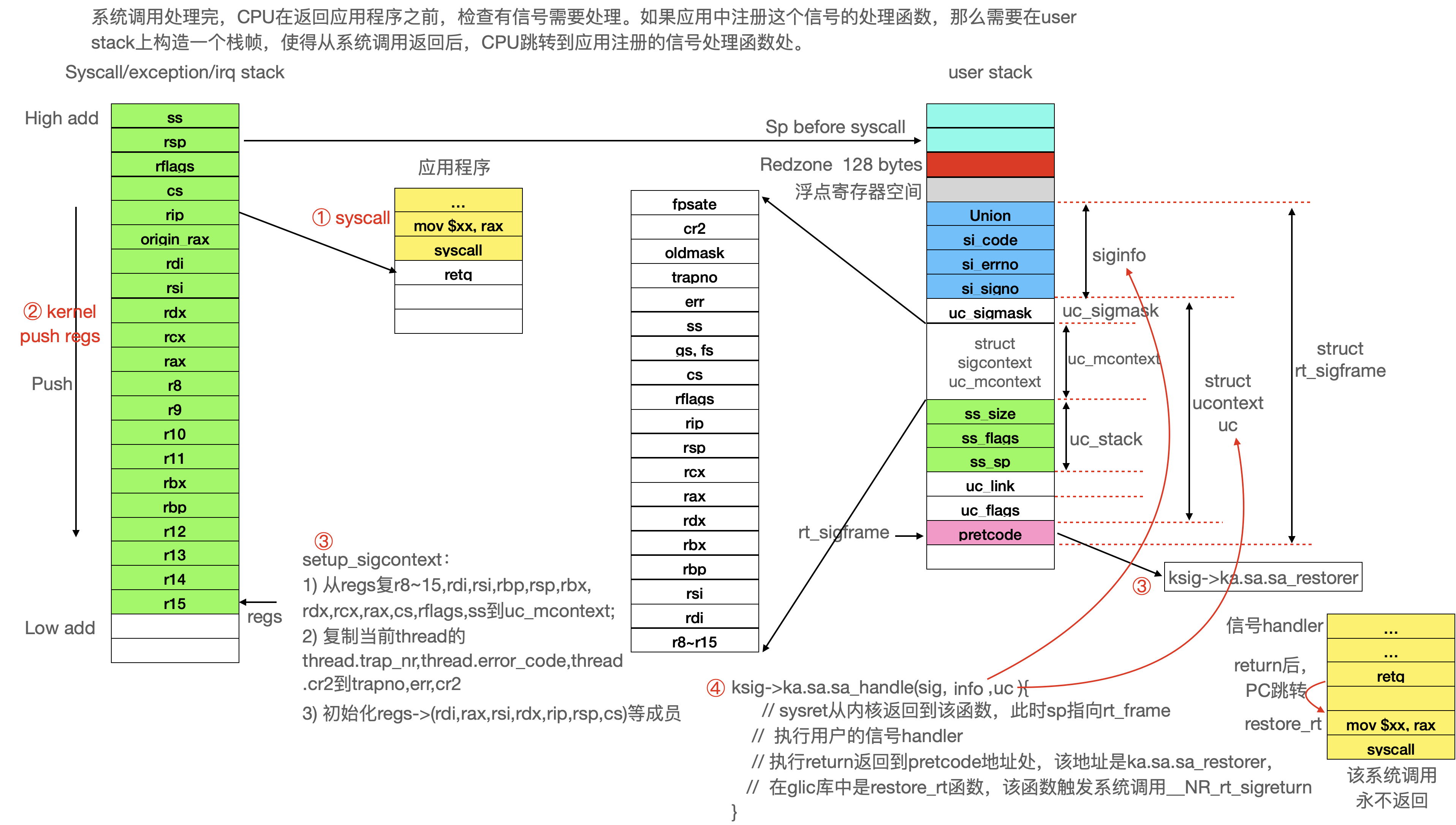
__setup_rt_frame的代码流程为:
从用户态的栈上为信号处理函数分配一个struct rt_sigframe栈帧。可能会为浮点数从用户态栈上也分配空间。
如果注册信号时指定了sa_flags & SA_SIGINFO,那么意味着信号处理函数使用void (*sa_sigaction)(int, siginfo_t *, void *)形式,而不是void (*sa_handler)(int)。那么需要将siginfo复制到信号处理栈帧上。
将系统调用栈帧上的寄存器保存到信号处理函数栈帧上
初始化系统调用栈帧上的rdi, rsi, rdx, rsp, rip, cs, ss寄存器,为系统调用返回到信号处理函数和信号处理函数的参数做准备。
static int __setup_rt_frame(int sig, struct ksignal *ksig,
sigset_t *set, struct pt_regs *regs)
{
struct rt_sigframe __user *frame;
void __user *fp = NULL;
unsigned long uc_flags;
int err = 0;
// 从regs->rsp指项的栈上分配栈空间,作为栈帧,如果使能了浮点数,也要为浮点数从
// 栈上分配空间
frame = get_sigframe(&ksig->ka, regs, sizeof(struct rt_sigframe), &fp);
if (!access_ok(VERIFY_WRITE, frame, sizeof(*frame)))
return -EFAULT;
// SA_SIGINFO:指定使用第二种信号处理函数,需要将siginfo复制到栈帧上
// 参考: https://man7.org/linux/man-pages/man2/sigaction.2.html
// void (*sa_handler)(int);
// void (*sa_sigaction)(int, siginfo_t *, void *);
if (ksig->ka.sa.sa_flags & SA_SIGINFO) {
if (copy_siginfo_to_user(&frame->info, &ksig->info))
return -EFAULT;
}
uc_flags = frame_uc_flags(regs);
put_user_try {
/* Create the ucontext. */
// put_user_ex()函数将数据复制到用户态内存空间
put_user_ex(uc_flags, &frame->uc.uc_flags);
put_user_ex(0, &frame->uc.uc_link);
// 保存信号处理栈信息栈帧上
// 信号处理栈,参考:https://man7.org/linux/man-pages/man2/sigaltstack.2.html
save_altstack_ex(&frame->uc.uc_stack, regs->sp);
/* Set up to return from userspace. If provided, use a stub
already in userspace. */
/* x86-64 should always use SA_RESTORER. */
if (ksig->ka.sa.sa_flags & SA_RESTORER) {
// 设置栈帧上的信号处理函数返回地址,信号处理函数执行完成后,返回到该地址
put_user_ex(ksig->ka.sa.sa_restorer, &frame->pretcode);
} else {
/* could use a vstub here */
err |= -EFAULT;
}
} put_user_catch(err);
// 复制系统调用栈帧上的寄存器到信号处理栈帧, 并设置信号处理栈帧上的gs、fs、ss、oldmask、cr2等
err |= setup_sigcontext(&frame->uc.uc_mcontext, fp, regs, set->sig[0]);
err |= __copy_to_user(&frame->uc.uc_sigmask, set, sizeof(*set));
if (err)
return -EFAULT;
// 设置信号处理函数的参数
// x86 C函数的传参(rdi, rsi, rdx, rcx, r8, r9)
// 所以真实的信号处理函数参数是:ka.sa.sa_handler(sig, info, uc)
/* Set up registers for signal handler */
regs->di = sig;
/* In case the signal handler was declared without prototypes */
regs->ax = 0;
/* This also works for non SA_SIGINFO handlers because they expect the
next argument after the signal number on the stack. */
regs->si = (unsigned long)&frame->info;
regs->dx = (unsigned long)&frame->uc;
regs->ip = (unsigned long) ksig->ka.sa.sa_handler;
// 系统调用返回后,ka.sa.sa_handler()函数的栈起始地址为frame
regs->sp = (unsigned long)frame;
// 设置执行信号处理函数时的CS、SS段寄存器
regs->cs = __USER_CS;
if (unlikely(regs->ss != __USER_DS))
force_valid_ss(regs);
return 0;
}
6. sigreturn恢复线程现场
rt_sigreturn
5.2.2.1节图中右下角有写到,用户态的信号handler执行return后,回到glibc库中,然后glibc中又调用__NR_rt_sigreturn的系统调用,进入内核的__NR_rt_sigreturn系统调用中,函数为signal.c: rt_sigreturn。
获取线程的上下文寄存器regs, 此处regs是执行完用户态信号处理函数后,再次调用系统进入内核前的寄存器值(即执行syscall指令时,CPU寄存器的值)。
通过regs->sp,找到前面构造的栈帧地址frame
将frame中记录的执行用户态信号处理函数前的线程regs恢复到线程当前regs寄存器中。等这次系统调用返回后,线程就回到原来被信号或者中断打断的地方继续运行
// sigframe.h
struct rt_sigframe {
char __user *pretcode;
struct ucontext uc;
struct siginfo info;
/* fp state follows here */
};
// signal.c
SYSCALL_DEFINE0(rt_sigreturn)
{
// 获取线程进入内核系统调用后,内核保存的线程用户态寄存器regs指针,参考5.2.2.1节图片左侧绿色的部分。
struct pt_regs *regs = current_pt_regs();
struct rt_sigframe __user *frame;
sigset_t set;
unsigned long uc_flags;
// regs->sp是执行完用户信号处理函数,又在glibc中调用__NR_rt_sigreturn系统调用执行syscall函数是的栈地址。
// 此处,为什么要减去一个sieof(long),我没有仔细去探究,我猜测是从用户的信号handler返回后,又通过函数调用的
// 方式进入一个函数执行了__NR_rt_sigreturn系统调用,这次函数调用会往用户态栈上压栈一个返回地址,此处是要在从
// 栈上减去这个返回地址所占的空间。
// 计算得到的frame 指向5.2.2.1图中的rt_sigframe指针指向的位置。
frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long));
if (!access_ok(frame, sizeof(*frame)))
goto badframe;
if (__get_user(*(__u64 *)&set, (__u64 __user *)&frame->uc.uc_sigmask))
goto badframe;
if (__get_user(uc_flags, &frame->uc.uc_flags))
goto badframe;
set_current_blocked(&set);
// 在执行用户信号处理函数之前,在用户态栈上构造了一个栈帧,我们将线程的regs寄存器保存在uc_mcontext中,
// 此处,我们再从uc_mcontext中再次恢复到线程的regs寄存器。等到本次系统调用返回到用户态后,就恢复到线程被信号、
// 或者中断打断的地方继续执行。
if (!restore_sigcontext(regs, &frame->uc.uc_mcontext, uc_flags))
goto badframe;
if (restore_altstack(&frame->uc.uc_stack))
goto badframe;
return regs->ax;
badframe:
signal_fault(regs, frame, "rt_sigreturn");
return 0;
}
参考:
https://senlinzhan.github.io/2017/03/02/linux-signal/















 9360
9360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









