






首先先来说说 AUC 的概念
AUC:Area Under Curve,译为:ROC 曲线下的面积。可通过对 ROC 积分得到,AUC 通常大于 0.5 小于 1。
在求解 ROC 的时候,我们知道是通过设置 FPR 为 x 轴,TPR 为 y 轴,然后通过取不同阈值对应的 [FRP、TPR] 点,连接形成的一条曲线
ok,下面这样:

需要说一下中间的那条红色的虚线,我们知道曲线中 TPR 和 FPR 分别表示:
TPR:实际为 1 的样本预测为 1 的概率(真正率)
FPR:实际为 0 的样本预测为 1 的概率(假正率)
而中间那条红虚线刚好表示 TPR=FPR,相当于抛一枚均匀的硬币,正面朝上的概率和反面朝上的概率总是相等的。
如果想要正面朝上的概率大一些,对应的就是红虚线上方的任一点,也就是预测正确的概率要大于预测错误的概率。
当然,最理想的情况是:既没有将实际为1的样本预测为0,也没有将实际为0的样本预测为1,此时模型的性能最好,达到最大值1,对应上图左上方的 [0,1] 点。
也就是下图中对应的几种取值:
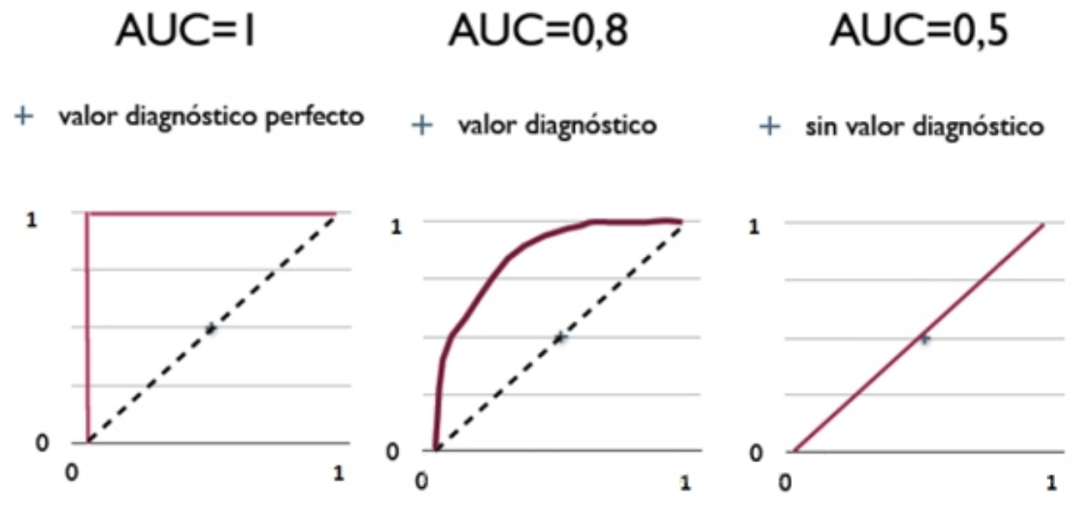
综上,AUC 的取值大概会出现如下几种:
AUC=1,是完美分类器。
0.5<AUC <1,优于随机猜测,有预测价值。
AUC=0.5,跟随机猜测一样,说了等于白说。
AUC<0.5,反预测 效果会好点
用 1-AUC 即可,这种情况一般是 Target 定义反了
总结一下:AUC 越大,则模型分类效果越好。
AUC 的概念理解起来不难,难的是它的计算过程。当然,如果你只是一个调包虾,你可以不用会。
AUC 的计算一共有三种方法,分别是:
方法 1-计算面积
AUC 为 ROC 曲线下的面积,那我们直接计算面积可得。
其实曲线下的面积为一个个小的梯形面积之和,所以可以直接进行积分。
需要注意的是,AUC 计算的精度与阈值的精度有关,如下图:
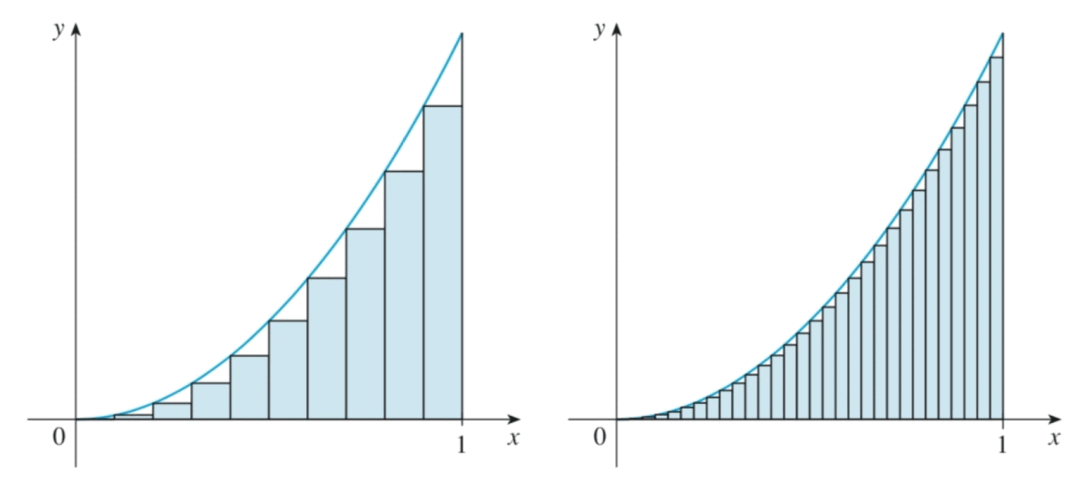
很明显,左图的精度是不如右图的,对应的 AUC 计算中如果阈值的取值越多,结果的精度越高。
方法 2-AUC 物理意义
首先需要明确一下 AUC 的物理意义:随机选择一个正样本和一个负样本,分类器输出该正样本为正的那个概率值比分类器输出该负样本为正的那个概率值要大的可能性。
例如对于正样本 A、B 和负样本 C、D,会出现 A+C、A+D、B+C、B+D 四种情况,需要计算每一个组中是 正得分>负得分 还是 正得分<负得分。
如果 A>C 说明 A 预测为正的概率大于 C 预测为正的概率,同理 A>D、B>C、B>D 都发生的话说明 TPR 的得分为 1,即正样本都预测为正的概率为 100%。
对应的 ROC 曲线是这样的:
在上面的例子中,一共有 2*2=4 个正负样本二元组,其中正样本得分大于负样本得分的二元组有 4 个,所以上例中的
总结一下,大概是这样的:
在 M 个正类样本,N 个负类样本,一共有 M*N 个二元组,其中对于每一个正负二元组,正样本得分大于负样本得分的二元组的占比 就是整个模型的 AUC 值。
写成公式是这样的:
其中在比较正样本和负样本的得分时:
P正>P负,score=1
P正=P负,score=0.5
P正<P负,score=0
也就是说如果上例中 4 个正负二元组, 其中 B+D 的二元组:P正=P负,那么 AUC 的结果为:
方法 3-改进版
方法 2 中如果样本数量过多,对应的二元组会相当庞大,计算 AUC 的时间复杂度是 O(n^2),n 为正负样本数之和。
所以,方法 3 在方法 2 的基础上进行了改进,将时间复杂度降低至 O(M+N),M 为正样本个数,N 为负样本个数。
首先将样本按照得分(预测为正标签的得分)从大到小排序,然后令最大得分对应的样本的 rank1 为 n=M+N,则存在 M-1 个正样本得分比它小,rank1-M 个负样本得分比它小;第二大得分对应样本的 rank2 为 n=M+N-1,则存在 M-2 个正样本得分比它小,rank2-M+1 个负样本得分比它小,以此类推。
借鉴方法 2 中计算每个二元组中正样本得分大于负样本得分的二元组个数,方法 3 中计算每个正样本的 rank 大于负样本的 rank 的 rank 个数。
例如:正样本 A、B 和负样本 C、D,假设 A>C 、A>D、B>C、B>D 都发生
对于 A 而言,rank1=M+N=4,存在 2-1=1 个正样本得分比它小、4-2=2 个负样本得分比它小。
对于 B 而言,rank2=M+N-1=3,存在 2-2=0 个正样本得分比它小、3-2+1=2 个负样本得分比它小。
之后我们把所有的正样本大于负样本的 rank 相加,也就是 (rank1-M)+(rank2-M+1)+...+(rank_M-1),对应上例中的 (4-2)+(3-2+1)=4
上式的整体结果再除以 M×N 得到的就是正类样本的得分大于负类样本的得分占整体的比例,公式为:
同样的,当两个样本的得分相等时,无论是同类(同正同负)还是非同类,都应该赋予相同的 rank,直接点的做法是取平均即可。
例如 样本 B 和样本 C 得分相同,B 的 rank=2,C 的 rank=3,则 rank_B=rank_A=(2+3)/2
AUC 的代码实现
直接通过 metrics 包调用 roc_curve 函数计算每一步的 tpr、fpr 和对应 阈值 thresholds
之后通过 auc 函数计算 AUC 的得分,代码如下:
from sklearn import metrics
import numpy as np
y_true = np.array([0, 1, 1, 1, 1])
y_score = np.array([0.4, 0.4, 0.55, 0.8, 0.7])
fpr, tpr, thresholds = metrics.roc_curve(y_true, y_score)
roc_auc = metrics.auc(fpr, tpr)
# 输出
0.875
更具体一点,auc 函数中是通过 np.trapz(y, x) 方法进行积分计算 AUC 的得分。
总结一下
关于 AUC 的概念基本上就这些,其中计算方法啥的除非在 关键时候 会被问到,平常只需要知道怎么用、什么时候用就行了
会被问到,平常只需要知道怎么用、什么时候用就行了















 2047
2047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









