








完整代码、数据集和相应的报告 链接已经放在了正文最下方, 供大家参考学习
摘要
本文探讨了中文垃圾短信分类的问题,通过收集实际数据集,运用多种机器学习算法进行分类,并对比了不同算法在垃圾短信分类任务上的性能。本研究旨在提高中文垃圾短信的识别准确率,为构建更健康的通信环境提供技术支持。
关键词:数据规范化,朴素贝叶斯、随机森林,决策树、垃圾短信、文本分类
数据集介绍
本研究使用了一个包含大量中文短信的数据集,该数据集包括了约 70 万条数据,有 3 个字段 label、 message 和 msg_new, 分别代表了短信的类别、短信的内容和分词后的短信,其中0 代表正常的短信,1 代表恶意的短信, 中文分词工具采用jieba, 已经将短信内容处理好。 下面是正常短信和恶意短信的举例:

导入程序必要的库
import warnings
warnings.filterwarnings('ignore')
import os
os.environ["HDF5_USE_FILE_LOCKING"] = "FALSE"
import pandas as pd
import numpy as np
import os
import zipfile
数据预处理
读取数据集
# 3.1数据集的路径
data_path = "./dataset/data140152/5f9ae242cae5285cd734b91e-momodel/sms_pub.csv"
# 3.2读取数据
sms = pd.read_csv(data_path, encoding='utf-8')
# 3.3显示前 5 条数据
sms.head()

划分训练集和测试集
from sklearn.model_selection import train_test_split
X = np.array(sms.msg_new)
y = np.array(sms.label)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.1)
停用词
停用词处理在自然语言处理中是一项常见的预处理步骤,其主要目的是去除在文本分析中无实际意义或者对分析结果影响较小的词语。停用词通常包括高频词汇(如“的”、“了”、“是”等),介词、连词、助词等,这些词语在文本中频繁出现,但并不承载文本的实际信息。在实际操作中,通常会使用预定义的停用词列表或者根据具体任务和语料库自行构建停用词列表。这些列表包含了需要从文本中剔除的词汇。在处理每个文档或者文本集合时,通过比对文本中的词汇与停用词列表,将匹配的停用词从文本中移除。本文采用的是四川大学机器智能实验室停用词库
def read_stopwords(stopwords_path):
with open(stopwords_path, 'r', encoding='utf-8') as f:
stopwords = f.read()
stopwords = stopwords.splitlines()
return stopwords
# 4.2.1停用词库路径
stopwords_path = r'./dataset/data140152/5f9ae242cae5285cd734b91e-momodel/scu_stopwords.txt'
# 4.2.2读取停用词
stopwords = read_stopwords(stopwords_path)
# 4.2.3展示一些停用词
print(stopwords[-20:])

文本向量化
词向量表示(Word Embedding)是自然语言处理中一种将词语映射到实数向量的技术,它将文本中的词汇转换为计算机可以理解和处理的形式,从而在机器学习和深度学习模型中应用。词向量的表示方式可以捕捉词汇之间的语义和语法关系,使得计算机能够更好地理解和处理自然语言文本。我们可以借助 sklearn 中 CountVectorizer 来实现文本的向量化,CountVectorizer 实际上是在统计每个词出现的次数,这样的模型也叫做词袋模型。
from sklearn.feature_extraction.text import CountVectorizer
# 设置匹配的正则表达式和停用词
vect = CountVectorizer(token_pattern=r"(?u)\b\w+\b", stop_words=stopwords)
X_train_dtm = vect.fit_transform(X_train)
X_test_dtm = vect.transform(X_test)
训练模型
朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
# 5.1 朴素贝叶斯
nb = MultinomialNB()
# 5.2对测试集的数据集进行预测
y_pred = nb.predict(X_test_dtm)
# 5.3在测试集上评估训练的模型
from sklearn import metrics
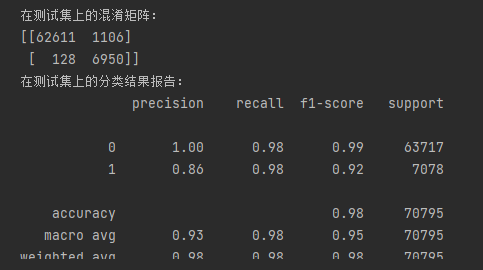
print("在测试集上的混淆矩阵:")
print(metrics.confusion_matrix(y_test, y_pred))
print("在测试集上的分类结果报告:")
print(metrics.classification_report(y_test, y_pred))
print("在测试集上的 f1-score :")
print(metrics.f1_score(y_test, y_pred))
随机森林分类器
from sklearn.ensemble import RandomForestClassifier
# 6.2随机森林分类器
# 6.2.1创建随机森林分类器
# 设置并行计算的参数 n_jobs=-1 使用所有可用的CPU核心
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
# clf.fit(X_train, y_train)
# clf = RandomForestClassifier(n_estimators=80, random_state=0)
# 6.2.2训练模型
clf.fit(X_train_dtm, y_train)
# 6.2.3预测结果
train_predictions = clf.predict(X_test_dtm)
#6.2.4测评模型
evaluate(y_test, train_predictions)
决策树
#7.1 决策树
from sklearn.tree import DecisionTreeClassifier
# 7.1.1初始化决策树分类器
clf = DecisionTreeClassifier()
# 7.1.2训练模型
clf.fit(X_train_dtm, y_train)
# 7.1.3使用模型进行预测
predictions = clf.predict(X_test_dtm)
# 6.1.4测评结果
evaluate(y_test, predictions)
完整项目链接
https://mbd.pub/o/bread/ZpebmpZp
















 2866
2866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











