







摘要
本课设旨在利用LSTM(长短期记忆)网络实现股票价格预测,通过收集、预处理股票数据集,并构建预测模型进行训练与优化。实验结果显示,经过优化调整模型参数,模型在测试集上取得了较为理想的预测效果。尽管存在部分预测不准确的情况,总体而言,该模型在股票价格预测任务中表现良好,具有实际应用的潜力和效果。
导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import torch
import torch.nn as nn
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
加载数据集
该项目所用数据来自飞浆开源数据集,数据集采用的是上证指数的股票
数据集包含10列 (股票来源、日期、开盘价、收盘价、最低价、最高价、交易量、交易额、跌涨幅、后一天最高价) ,共有6109天的股票数据
该项目中,我们利用历史数据中的开盘价、收盘价、最低价、最高价、交易量、交易额、跌涨幅来对下一日的最高价进行预测
数据集中所有数据都来自同一支股票,同时按照时间顺序排列好, 从1990年12月20日到2015年12月10日, 共6106条数据
#导入数据
data=pd.read_csv(r'.\datasets\stock_dataset.csv')
df=pd.DataFrame(data)
dataset = df.iloc[:,2:].to_numpy()
df.head()

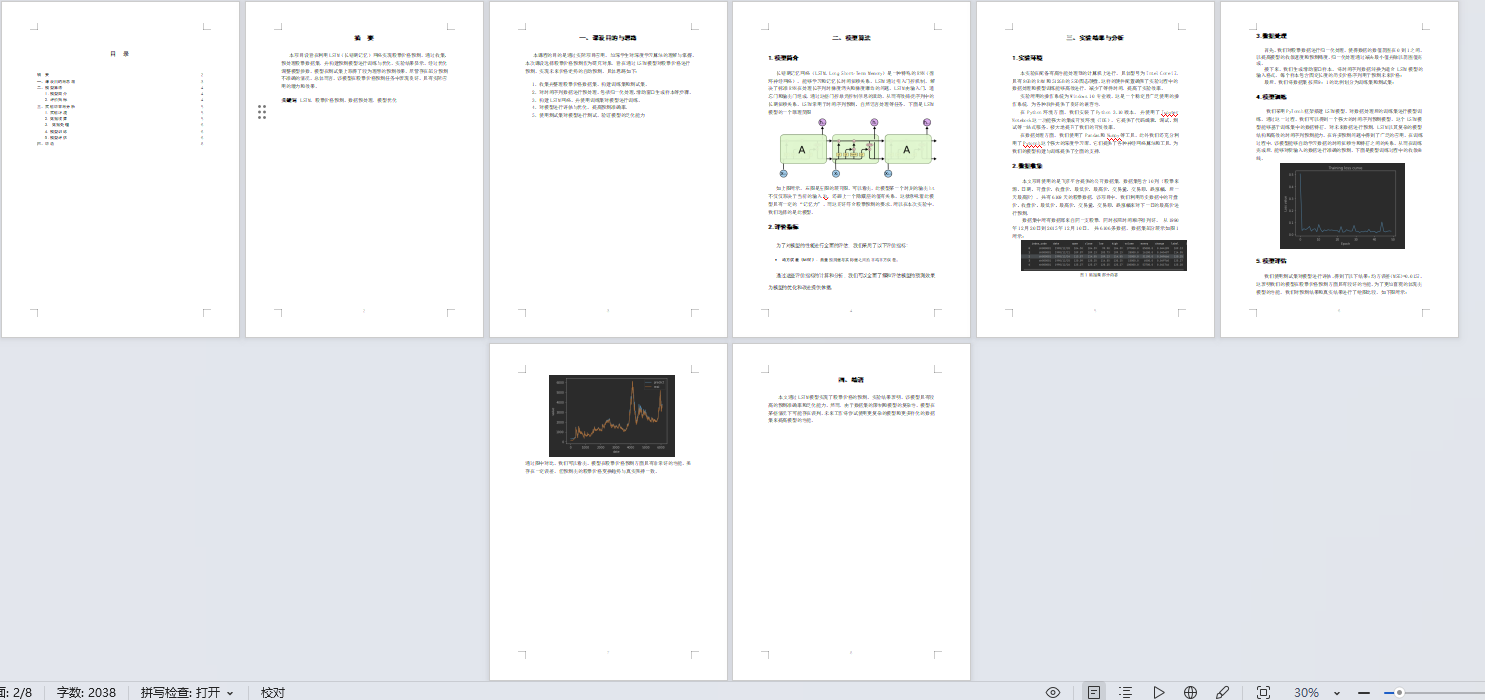
股票价格走势图像 这里我们对股票的每日的最高价格进行显示
df=pd.DataFrame(data,columns=['high'])
plt.plot(df)
plt.show()
数据预处理
数据预处理, 这里因为所有数据都是存在的,所以不用再检查缺失值
# 3.1 得到训练数据与对应label
X = np.array(dataset[:,:-1])
y = np.array(dataset[:,-1])
# 3.2 标准化处理,归一化
st = StandardScaler()
X = st.fit_transform(X)
y = y / 1000
# 3.3 划分训练集和测试集 按照9:1的概率划分
X_train = X[0:int(len(X)*0.9),:]
y_train = y[0:int(len(y)*0.9)]
X_test = X[int(len(X)*0.9):,:]
y_test = y[int(len(y)*0.9):]
# 3.4 定义 PyTorch Dataset 类
class MyDataset(Dataset):
def __init__(self, x, y, sequence_length):
self.x = x
self.y = y
self.sequence_length = sequence_length
def __len__(self):
return len(self.x) - self.sequence_length
def __getitem__(self, idx):
return (
torch.tensor(self.x[idx:idx+self.sequence_length], dtype=torch.float),
torch.tensor(self.y[idx+self.sequence_length], dtype=torch.float),
)
# 3.5 根据划分的训练集测试集生成需要的时间序列样本数据, 预测长度定为14,及根据前13天数据 预测后一天数据
sequence_length = 14
dataset_train = MyDataset(X_train, y_train, sequence_length)
train_dataloader = DataLoader(dataset_train, batch_size=64, shuffle=True)
dataset_test = MyDataset(X_test, y_test, sequence_length)
test_dataloader = DataLoader(dataset_test, batch_size=64, shuffle=False) # 不需要打乱测试集
搭建模型
# 4.1 LSTM 模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
self.init_weights()
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :]) # 使用最后一个时间步的输出
return out
def init_weights(self):
# 设置随机数种子
torch.manual_seed(42)
# 遍历 LSTM 层的参数,对参数进行初始化
for name, param in self.named_parameters():
if 'weight' in name:
nn.init.normal_(param, mean=0, std=0.1) # 使用正态分布初始化权重
elif 'bias' in name:
nn.init.constant_(param, 0) # 将偏置项初始化为零
训练模型
# 5.1 初始化模型、损失函数和优化器
略
# 初始化最佳模型参数和最佳验证损失
best_model_params = model.state_dict()
best_val_loss = float('inf')
# 5.2 训练模型
num_epochs = 50
train_loss_list = []
val_loss_list = []
for epoch in range(num_epochs):
train_loss = 0
for batch_input, batch_target in train_dataloader:
optimizer.zero_grad()
output = model(batch_input)
loss = criterion(output.squeeze(), batch_target)
train_loss+=loss
loss.backward()
optimizer.step()
train_loss = train_loss/len(train_dataloader)
train_loss_list.append(train_loss.item())
# 在验证集上计算损失并保存最佳模型
with torch.no_grad():
val_losses = []
for val_batch_input, val_batch_target in test_dataloader:
val_output = model(val_batch_input)
val_loss = criterion(val_output.squeeze(), val_batch_target)
val_losses.append(val_loss.item())
avg_val_loss = np.mean(val_losses)
val_loss_list.append(avg_val_loss)
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
best_model_params = model.state_dict()
torch.save(best_model_params, './best_model_LSTM.pth', _use_new_zipfile_serialization=False)
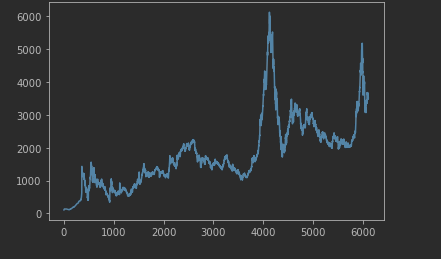
print(f'Epoch [{epoch+1}/{num_epochs}], Training Loss: {train_loss.item():.4f}, Validation Loss: {avg_val_loss:.4f}')
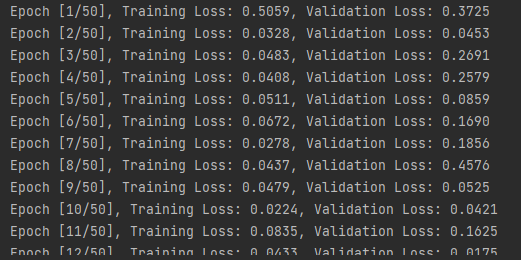
# 5.3 绘制损失曲线
plt.title("Training loss curve")
plt.plot(train_loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss value")
plt.show()
模型推理
# 6.1 加载模型
model_lstm = LSTMModel(input_size, hidden_size, num_layers, output_size)
model_lstm.load_state_dict(torch.load('./best_model_LSTM.pth'))
# 6.2 将数据集重新按照长度为14的序列进行划分, 以此划分方式,前sequence_length-1个的结果不会被预测,所以真实值中也应去除
res = []
for idx in range(0, len(X)- sequence_length):
res.append(X[idx:idx+sequence_length])
res = torch.stack(res, dim=0)
# 6.3 开始推理
with torch.no_grad():
val_output = model_lstm(res)
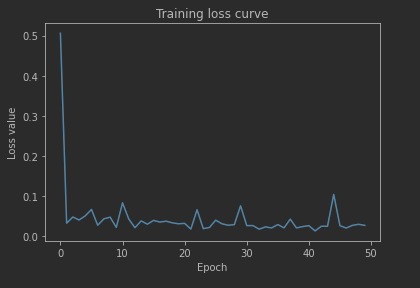
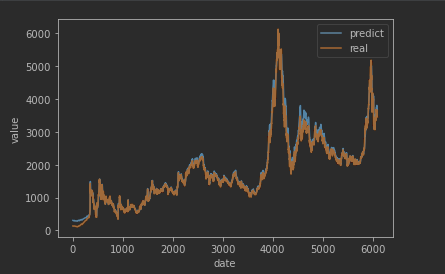
# 6.4 将推理结果 与 实际结果绘图进行比较
plt.plot(val_output*1000, label='predict')
plt.plot(y[sequence_length:]*1000, label='real')
plt.xlabel("date")
plt.ylabel("value")
plt.legend()
plt.show()
完整项目
数据集、代码、报告
https://mbd.pub/o/bread/Zpeck5lt


















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











