






差分编码思想
差分编码利用了图像文件前后像素数值大概率相似极小概率跳变的特点。大大减小了图像中的冗余信息,讲原本不太规则的亮度值的分布变换为近似于拉普拉斯分布,再利用熵编码对于差分编码后的信息进行压缩。
差分编解码的算法
DPCM编码的编码器内嵌了一个解码器
其步骤为:1、当前值与预测值相减获得差分值。2、将范围是-255到255的值变换到0-255范围传送到解码端。3、将变换后的值反变换缓存为预测值用于下一个值到来时进行差分。
关键代码
for (int i = 0; i < height*width; i++)
{
if (i%width == 0)
{
last = Y[i];
}
difference = Y[i] - last;
P[i] = (unsigned char)((difference+254.5)/2);
R[i] =(unsigned char) (2 * P[i]-254.5+last);
last = R[i];
}last为预测值,difference是差分值。
DPCM编码与熵编码分析
将初始图像,差分值图像与预测值图像显示出来对比。

可以发现差分编码后的图像几乎都为灰色,可以知道差分后的数据更为集中,可压缩的空间更大。
如果直接对原图像进行熵编码,则huffcode运行结果为219kb,而对差分数据进行上编码,则可压缩为101kb,可以看出经过预测编码后可比原始数据直接熵编码压缩一倍以上。
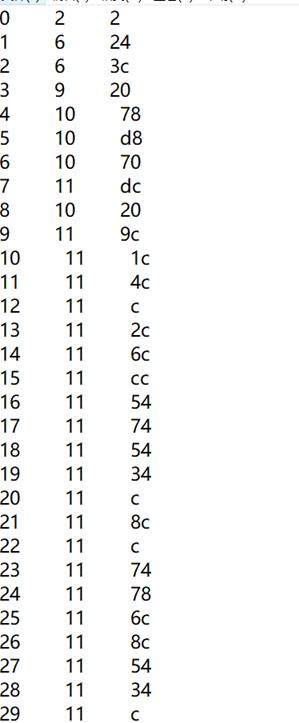
而查看霍夫曼的码字,可以看到dpcm后的再熵编码的码字长度从1到18,而且只有部分数值被编码,其中128的码字长度为1,如图可以看出几乎大部分的灰色都如此,只用长度为1 的码字就可以表示了。

而未经过dpcm而直接进行熵编码,几乎所有的码字的码长都在11左右,且0-255所有数值都被编码,在图中的月球部分几乎全部都是11码长左右。因此压缩比更小。















 4059
4059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









