







算法描述
1.朴素贝叶斯思想是使用条件概率公式计算类别概率并进行分类。
注:朴素贝叶斯在[2]有较为完善的叙述,本篇笔者贡献仅为要点的整理与举例推理部分。十分建议大家读原文。
2.问题假设:论坛的评论区有侮辱性评论,需要过滤掉此类评论。[2]
3.数据输入:该论坛已有的评论文本及标签。
4.算法过程:
①将评论文本转换为向量。
②计算侮辱类的条件概率、非侮辱类的条件概率并统计两类的占比。
③根据②所得的三个数据计算新的评论文本的侮辱类的概率。
知识储备
1.条件概率;在此引用《Machine Learning in Action》中的例子:已知有7块石头放在两桶中,求右桶中取到白色石头的概率。
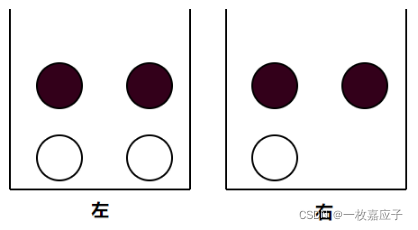

举个栗子
1.若评论文本如下:

首先是分词,然后遍历所有文本内容做成一个词汇的集合(不重复),接着再遍历每个文本,倘若文本出现该词则将对应的向量位置1。以上文本公有32个不重复的单词,每个文本对应向量如图2-7行。

2.统计两个类的总字数(S)、词频向量( C)和侮辱类文档的概率( P)。此处原作者采用了拉普拉斯平滑和对数的方法分别解决零概率和溢出问题。([2]章节4.4)
例如,标签为0的文本共有24个单词,拉普拉斯平滑为24+2(S)。同样,为避免零概率,每个词的初始值为1,而不是0,统计的词频向量( C)如图第9行。非侮辱类(标签0)的条件概率向量公式:
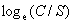
结果如上图第10行。标签1的文本结果如图11及12行。
侮辱类文档的概率就是标签1的概率0.5( P)。
3.将待分类的文本(love my dalmation)转换为32维向量T(如图14行),计算两个类别的概率。
①标签0概率:
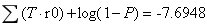
②标签1概率:
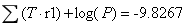
∵①>②
∴该文本为非侮辱类。
实现代码
1.debug代码引用《机器学习实战》提供的demon,此书作者提供完整代码和数据集,强烈推荐。[1]
2.sklearn实现版本。[3]
算法分析
1.少量数据依然有效。(文本分类需要对数据做预处理)
资料引用
[1]GitHub:https://github.com/wzy6642/Machine-Learning-in-Action-Python3/tree/master/Bayes_Project1
[2]CSDN:https://blog.csdn.net/jiaoyangwm/article/details/79552267
[3]CSDN:https://zhzhx.blog.csdn.net/article/details/79518235
此算法笔记会在CSDN、知乎、b站及公众号同步更新,账号名为一枚嘉应子。转载注明出处,侵权必究。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









