







一、认识scrapy
1、简介
Scrapy是一个基于Python开发的爬虫框架,可以说它是当前Python爬虫生态中最流行的爬虫框架,该框架提供了非常多的爬虫相关的基础组件,架构清洗,可扩展性极强。
官网:Scrapy | A Fast and Powerful Scraping and Web Crawling Framework
文档:Scrapy 2.13 documentation — Scrapy 2.13.0 documentation
2、架构
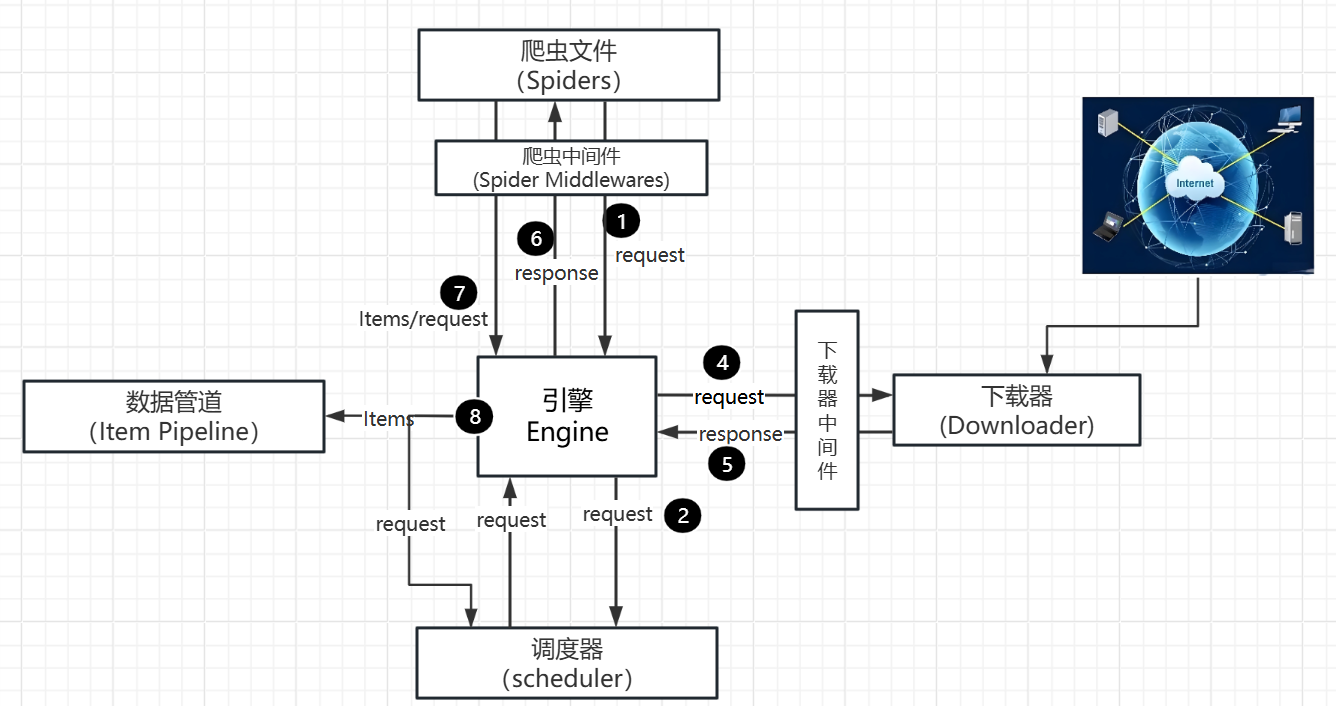
Engine:图中最中间的部分,中文可以称为引擎,用来处理整个系统的数据流和事件,是整个框架的核心,可以理解为整个框架中的中央处理器,负责数据的流转和逻辑的处理。
Item:它是一个抽象的数据结构,它定义了爬取结果的数据结构,爬取的数据会被赋值成Item对象。每个Item就是一个类,类里面定义了爬取结果的数据字段,可以理解为它用来规定爬取数据的存储格式。
Scheduler:图中下方的部分,中文可以称为调度器,它用来接受Engine发过来的Request并将其加入队列中,同时也可以将Request发回给Engine供Downloader执行,它主要维护Request的调度逻辑,比如先进先出、先进后出、优先级进出等等。
Spiders:图中上方的部分,中文可以称为蜘蛛,Spiders是一个复数统称,其可以对应多个Spider,每个Spider里面定义了站点的爬取逻辑和页面的解析规则,它主要负责解析响应并生成Item和新的请求然后发给Engine进行处理。
Downloader:图中右侧部分,中文可以称为下载器,即完成“向服务器发送请求,然后拿到响应”的过程,得到的响应会再发送给Engine处理。
Item Pipelines:图中左侧部分,中文可以称为项目管道,这也是一个复数统称,可以对应多个Item Pipeline。Item Pipeline主要负责处理由Spider从页面中抽取的Item,做一些数据清洗、验证和存储等工作,比如将Item的某些字段进行规整,将Item存储到数据库等操作都可以由Item Pipeline来完成。
Downloader Middlewares:图中Engine和Downloader之间的方块部分,中文可以称为下载器中间件,同样这也是复数统称,其包含多个Downloader Middleware,它是位于Engine和Downloader之间的Hook框架,负责实现Downloader和Engine之间的请求和响应的处理过程
Spider Middlewares:图中 Engine 和 Spiders 之间的方块部分,中文可以称为蜘蛛中间件,它是位于 Engine 和 Spiders 之间的 Hook 框架,负责实现 Spiders 和 Engine 之间的 Item、请求和响应的处理过程。
以上就是Scrapy所有的核心组件。
3、数据流
在整个爬虫运的过程中,Engine负责这个数据流的分配和处理,数据流主要包括 Item、Request、Response 这三大部分,它们又是怎么被 Engine 控制和流程的呢?
下面我们结合上面的架构图 来对数据流做一个简单说明:
(1) 启动爬虫项目时,Engine 根据需要爬取的目标站点找到处理该站点的 Spider,Spider 会生成最初需要爬取的页面对应的一个或多个 Request,然后发给 Engine。
(2) Engine 从 Spider 中获取这些 Request,然后把它们交给 Scheduler 等待被调度。
(3) Engine 向 Scheduler 索取下一个要处理的 Request,这时候 Scheduler 根据其调度逻辑选择合适的 Request 发送给 Engine。
(4) Engine 将 Scheduler 发来的 Request 转发给 Downloader 进行下载执行,将 Request 发送给
Downloader 的过程会经由许多定义好的 Downloads or Middlewares 的处理。
(5) Downloader 将 Request 发送给目标服务器,得到对应的 Response,然后将其返回给 Engine。将 Response 返回 Engine 的过程同样会经由许多定义好的 Downloads or Middlewares 的处理。
(6) Engine 从 Downloads 处接收到的 Response 里包含了爬取的目标站点的内容,Engine 会将此
Response 发送给对应的 Spider 进行处理,将 Response 发送给 Spider 的过程中会经由定义好的 Spider Middlewares 的处理。
(7) Spider 处理 Response,解析 Response 的内容,这时候 Spider 会产生一个或多个爬取结果 Item或者后续要爬取的目标页面对应的一个或多个 Request,然后再将这些 Item 或 Request 发送给 Engine进行处理,将 Item 或 Request 发送给 Engine 的过程会经由定义好的 Spider Middlewares 的处理。
(8) Engine 将 Spider 发回的一个或多个 Item 转发给定义好的 Item Pipelines 进行数据处理或者存储的一系列操作,将 Spider 发回的一个或多个 Request 转发给 Scheduler 等待下一次被调度。
重复第 (2) 步到第 (8) 步,直到 Scheduler 中没有更多的 Request,这时候 Engine 会关闭 Spider,整个爬取过程结束。
4、项目结构
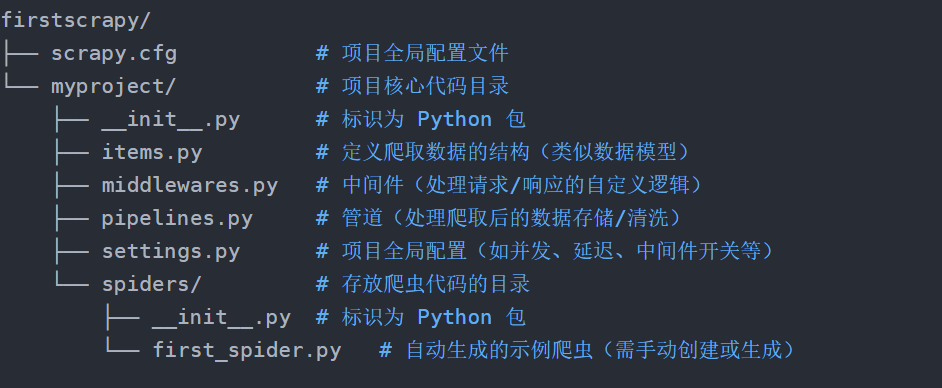
scrapy.cfg: Scrapy项目的配置文件,其中定义了项目的配置文件路径、部署信息等。
items.py: 定义了Item数据结构,所有爬取的数据结构都在这里定义
pipelines.py: 定义了 Item Pipeline 的实现,所有的爬取的数据存储都放在这里,可以存储到csv,excel,mysql,json等地方。
settings.py: 定义了项目的全局配置,如header,并发、延迟的全局配置都放在这里。
middlewares.py: 定义了 Spider Middlewares 和 Downloader Middlewares 的实现。
spiders: 里面包含一个个 Spider 的实现,每个 Spider 都对应一个 Python 文件。
二、Scrapy实战
通过上面的介绍我们对scrapy的用法和原理有了一定的认识,下面我们来完成一个Scrapy实战项目。我们需要爬取的站点为https://finance.eastmoney.com/,爬取财经导读的新闻标题和内容财经导读 _ 东方财富网。
1、分析
打开财经导读 _ 东方财富网,然后分析页面的呈现逻辑。
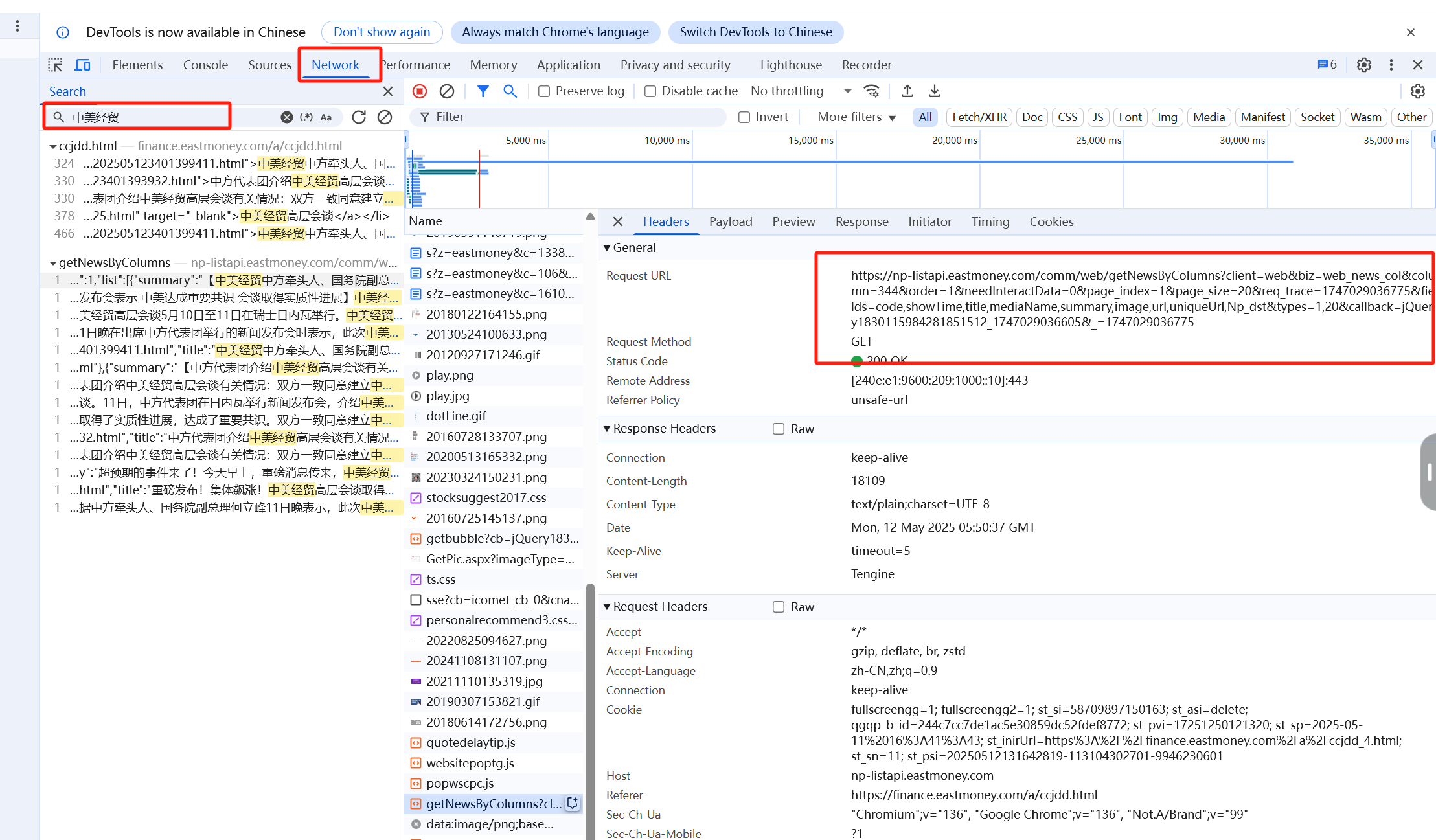
通过F12(开发者页面),进入network,使用ctrl+R刷新页面,点击ctrl+F找到新闻标题,如下图
查看Preview选项卡看返回结果
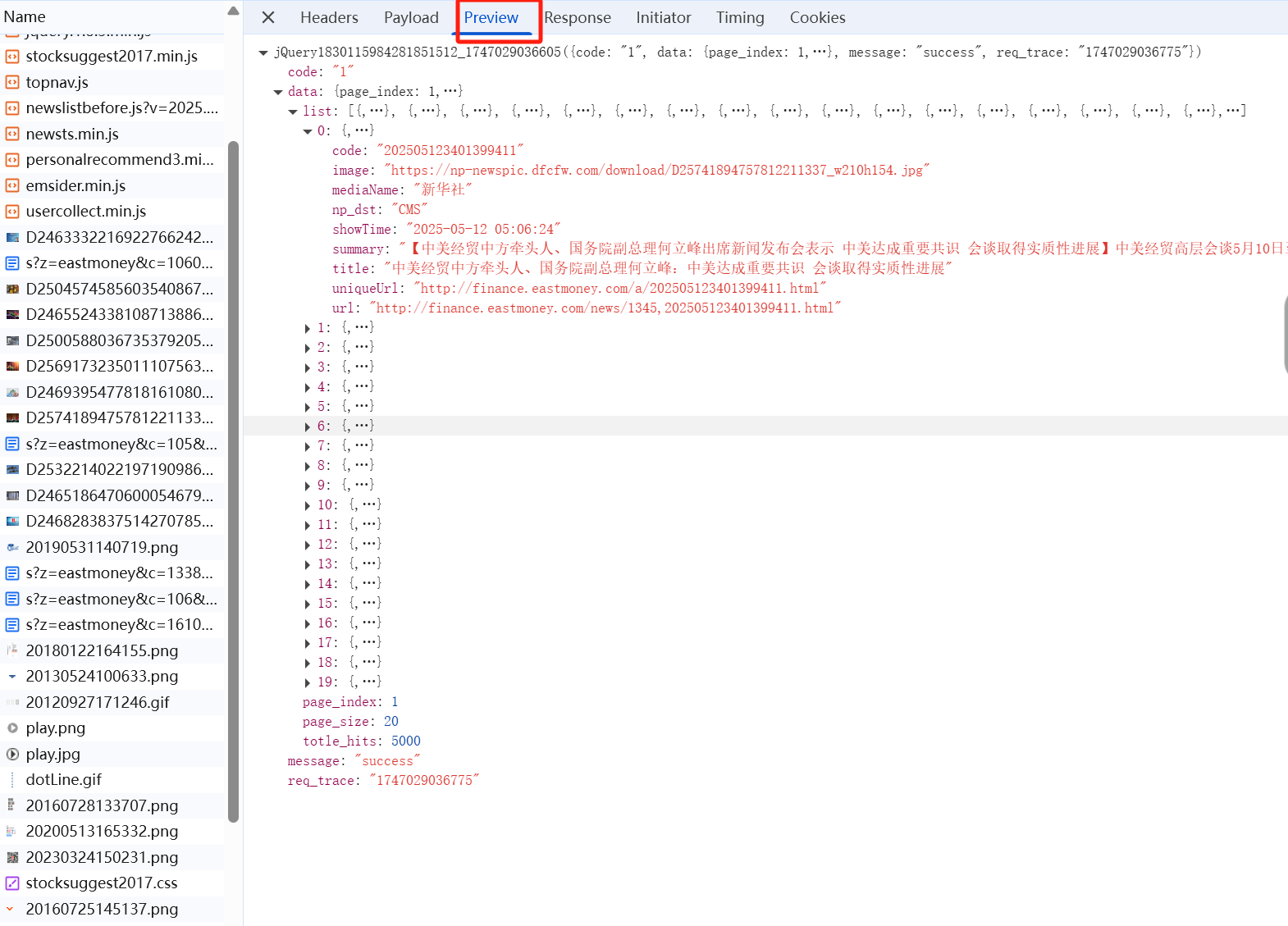
查看response
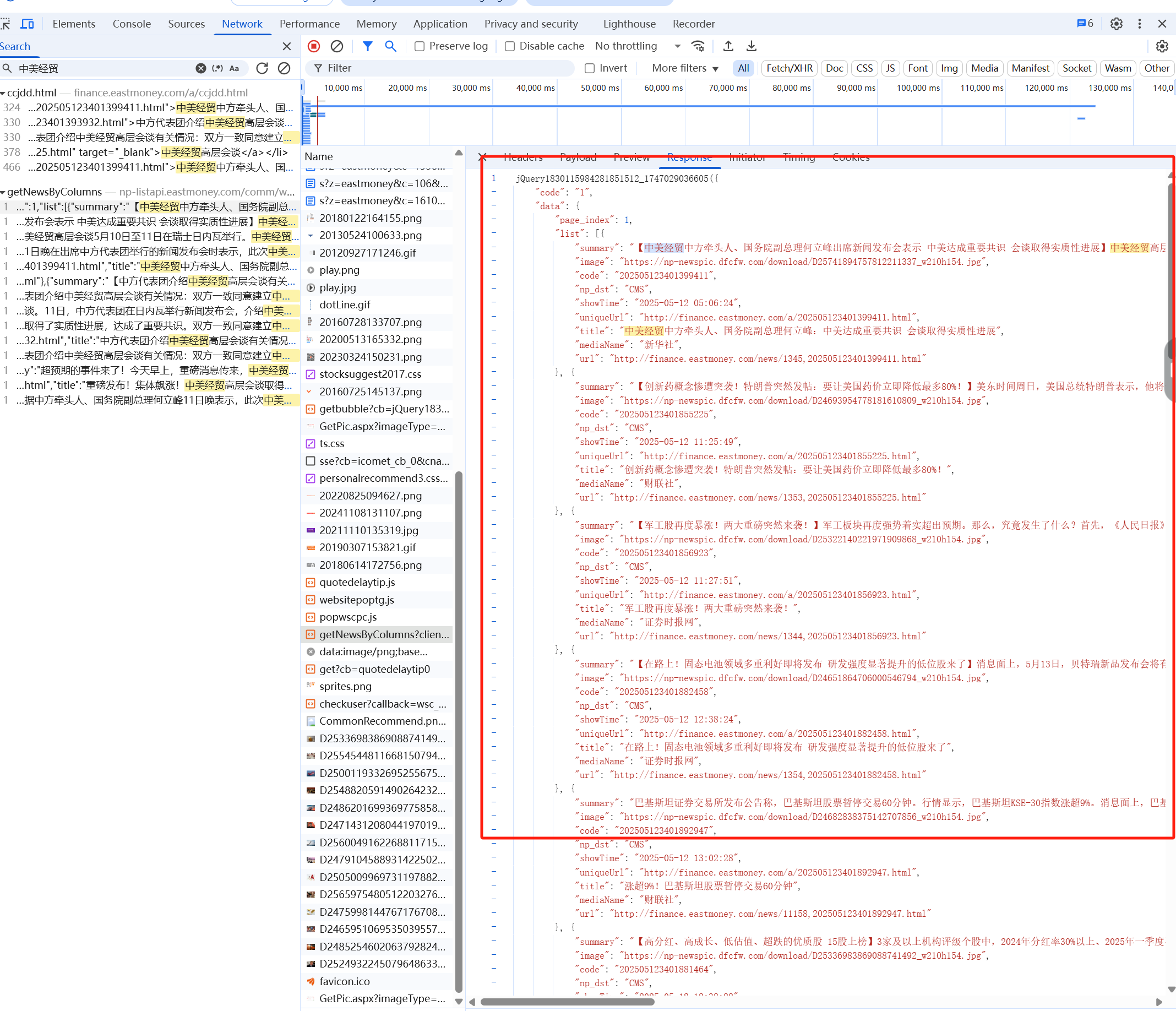
根据页面的呈现逻辑,可以分析出来每一页的列表数据是通过Ajax加载的。
数据通过 AJAX 加载 是指网页的内容(如列表、表格、动态更新的信息)不是直接写在初始 HTML 代码中,而是通过 JavaScript 异步请求(AJAX) 从服务器获取数据,再动态插入到页面中的技术。这种机制在现代网页(尤其是单页应用 SPA)中非常常见。
对应的爬取策略
-
静态页面:直接使用
requests + BeautifulSoup -
动态页面:使用
Selenium/Playwright或抓取API接口
2、开始项目(新建+Item)
首先新建一个Scrapy项目,名字叫做financeSpider,创建命令如下(在base环境中执行):
scrapy startproject financeSpider接下来进入项目,然后新建一个Spider,名称eastmoney_finance,命令如下:
cd ./financeSpider
scrapy genspider eastmoney_finance finance.eastmoney.com然后我们来定义一个Item,定义需要爬取的字段,在items.py里面定义一个FinancespiderItem,代码如下
class FinancespiderItem(scrapy.Item):
source=scrapy.Field()
source_url= scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
content = scrapy.Field()
update_time = scrapy.Field()mysql数据库操作,建表并给url列设为唯一,ddl命令如下
CREATE TABLE if not exists finance_news (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, -- ✅ 自增ID(无符号整数)
url VARCHAR(255) NOT NULL UNIQUE COMMENT '文章url', -- ✅ 唯一URL(
title VARCHAR(255) COMMENT '文章标题',
source VARCHAR(255) COMMENT '网站来源网站',
source_url VARCHAR(255) COMMENT '来源url',
content TEXT COMMENT '文章内容',
update_time VARCHAR(255) COMMENT '文章更新时间',
dt DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '数据写入时间', -- ✅ 时间戳(自动记录时间)
-- 可选:添加普通索引(根据查询需求)
INDEX idx_dt (dt) -- 如果经常按时间查询可加索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
# 加唯一索引
ALTER TABLE finance_news
ADD UNIQUE INDEX idx_unique_url (url);3、修改爬虫文件(Spiders)
其中timestamp,callback都是动态生成的。
在eastmoney_finance里面改写代码如下:
import scrapy
from financeSpider.items import FinancespiderItem
import requests
import json
import random
import time
import re
from bs4 import BeautifulSoup
# 爬取东方福利网财经导读前5页新闻,因为是动态渲染页面,选用更为高效的接口api解析
# scrapy genspider eastmoney_finance np-listapi.eastmoney.com scrapy crawl eastmoney_finance
class EastmoneyFinanceSpider(scrapy.Spider):
name = "eastmoney_finance"
#改成domain
allowed_domains = ["eastmoney.com"]
start_urls = ["https://np-listapi.eastmoney.com"]
def start_requests(self):
for page in range(1,2):
item = FinancespiderItem()
# 动态参数 自动生成callback和时间戳
random_str = '1' + ''.join(str(random.randint(0, 9)) for _ in range(19))
callback = f"jQuery{random_str}_{str(int(time.time() * 1000))}"
timestamp = str(int(time.time() * 1000))
item['source'] = '东方财富网'
item['source_url'] = f"https://finance.eastmoney.com/a/ccjdd_{page}.html"
#构造url
api_url = f'https://np-listapi.eastmoney.com/comm/web/getNewsByColumns?client=web&biz=web_news_col&column=345&order=1&needInteractData=0&page_index={page}&page_size=20&req_trace={timestamp}&fields=code,showTime,title,mediaName,summary,image,url,uniqueUrl,Np_dst&types=1,20&callback={callback}&_={timestamp}'
# print (api_url)
# print(source_url)
#返回请求,并把结果和数据传给下个方法
yield scrapy.Request(api_url,meta={"item":item},callback=self.parse)
# yield scrapy.Request(api_url, callback=self.parse)
def parse(self, response):
item = response.meta['item']
data = json.loads(response.text[41:-1]) # 处理JSONP响应 把不是json结构的字符去掉
# # 解析示例(需根据实际数据结构调整):
for d in data['data']['list']:
# 初始化
finance_item = FinancespiderItem()
finance_item['title'] = d['title']
finance_item['link'] = d['uniqueUrl']
# finance_item['link'] = d['url']
finance_item['source'] = item['source']
finance_item['source_url']=item['source_url']
# print (finance_item['source_url']+"\t"+ finance_item['link'])
#避免爬取太频繁,做了等待
time.sleep(0.5)
yield scrapy.Request(url=finance_item['link'], meta={"finance_item": finance_item}, callback=self.parse2)
def parse2(self, response):
#解析新闻文章页
finance_item = response.meta['finance_item']
time.sleep(1)
soup = BeautifulSoup(response.text, 'lxml')
print ("正在抓取内容")
finance_item["content"] = soup.find("div",id="ContentBody").text.strip()
dt= soup.find("div",class_="item").text.strip()
# 时间格式转换
finance_item["update_time"] = re.sub(r"(\d+)年(\d+)月(\d+)日",r"\1-\2-\3",dt)
content =finance_item['content']
link = finance_item['link']
# update_time = item['update_time']
# print (link+content)
#
# # # print (update_time)
#返回所有数据
yield finance_item
4、修改管道文件(Pipelines)
修改Pipeline文件,把数据写入mysql数据库
import pymysql
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class MySQLPipeline:
def __init__(self, host, port, user, password, db, charset):
self.host = host
self.port = port
self.user = user
self.password = password
self.db = db
self.charset = charset
self.connection = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
port=crawler.settings.get('MYSQL_PORT'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
db=crawler.settings.get('MYSQL_DATABASE'),
charset=crawler.settings.get('MYSQL_CHARSET')
)
def open_spider(self, spider):
"""连接数据库"""
self.connection = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.db,
charset=self.charset,
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.connection.cursor()
def close_spider(self, spider):
"""关闭连接"""
self.connection.close()
def process_item(self, item, spider):
"""处理Item"""
try:
# 构建SQL语句(根据你的表结构修改,按key值进行更新数据)
sql = """
INSERT INTO finance_news(
url,
title,
source,
source_url,
content,
update_time
) VALUES ( %s, %s, %s, %s, %s , %s )
ON DUPLICATE KEY UPDATE
title = VALUES(title),
source = VALUES(source),
source_url = VALUES(source_url),
content = VALUES(content),
update_time = VALUES(update_time);"""
params = (item["link"],item["title"],item["source"],item["source_url"],item["content"],item["update_time"])
# 从item提取数据(字段名需要对应)
self.cursor.execute(sql,params)
self.connection.commit()
except Exception as e:
self.connection.rollback()
raise DropItem(f"Error saving item to MySQL: {str(e)}")
return item
5、修改配置文件(settings)
BOT_NAME = "financeSpider"
SPIDER_MODULES = ["financeSpider.spiders"]
NEWSPIDER_MODULE = "financeSpider.spiders"
#修改请求头,可以弄得完整点,这个是全局配置,spider请求的时候不需要加
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
#mysql的配置参数根据自己的mysql地址修改
# mysql SETTING========
MYSQL_HOST='192.168.X.XX'
MYSQL_PORT=3306
MYSQL_USER='root'
MYSQL_PASSWORD='123456'
MYSQL_DATABASE = 'finance'
MYSQL_CHARSET='utf8mb4'
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# "financeSpider.pipelines.FinanceSpiderPipeline": 300,
#根据自己的管道文件名称修改
"financeSpider.pipelines.MySQLPipeline": 300,
}
#推荐加上的配置参数
ROBOTSTXT_OBEY = False
RETRY_HTTP_CODES = [401, 403, 500, 502, 503, 504]
CONCURRENT_REQUESTS = 10
下面解释一下推荐加上的参数参数。
-
ROBOTSTXT_OBEY:是否遵守 robots 协议,这里设置为 False,在爬取时不遵守 robots.txt 协议,可以免去最开始 robots.txt 的爬取步骤。
-
RETRY_HTTP_CODES:需要重试的状态码,这里设置为
[401, 403, 500, 502, 503, 504]。这样如果遇到这些状态码,该请求会重新发起,如果不进行这样的设置,该请求失败了就会被丢弃。 -
CONCURRENT_REQUESTS:并发量,这里设置为 10,稍微降低了并发数目,降低账号被封禁的概率。当然,如果账号和 IP 足够多,可以将该值调高。
6、运行测试
在base环境,写入命令
scrapy crawl eastmoney_finance运行结果如下:
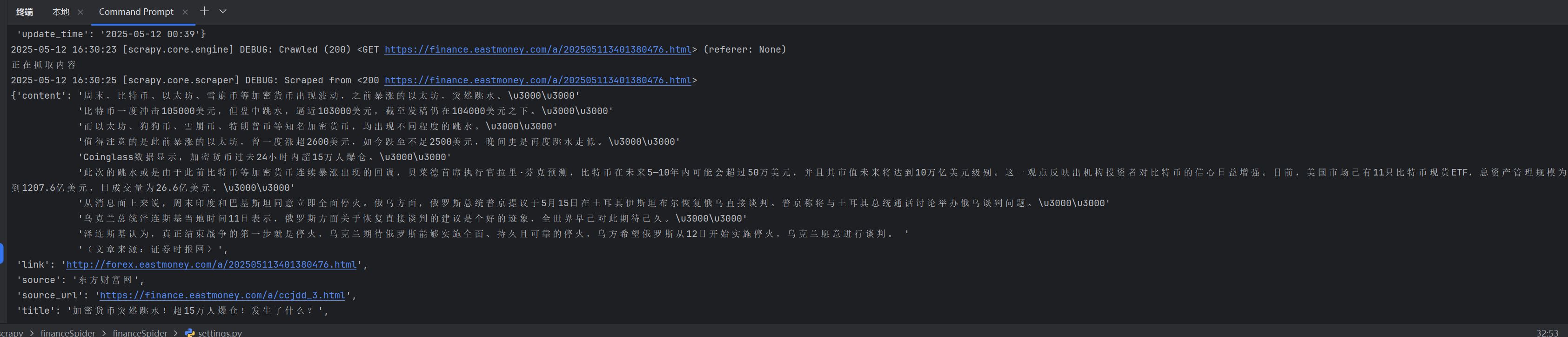
最后运行完的结果
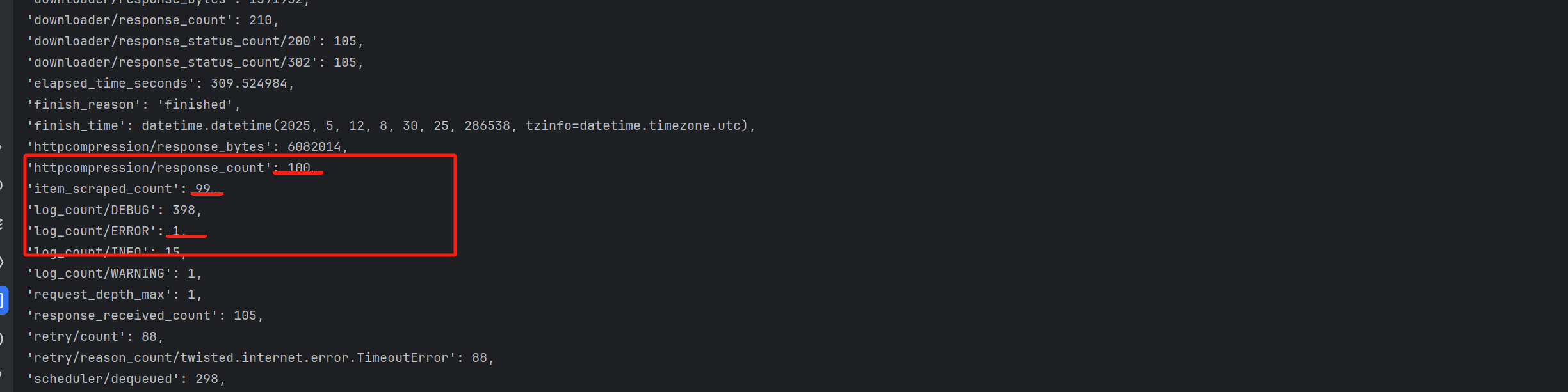
100条新闻成功爬取99条,一条因为文章解析不成功报错(可以忽略)
数据结果如下
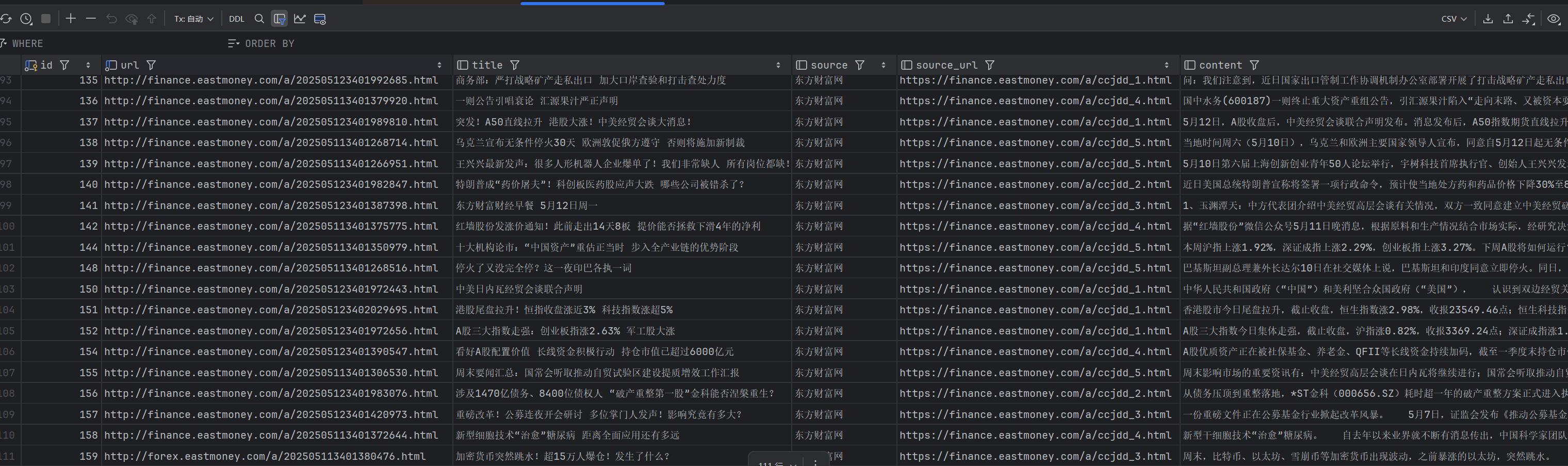
我们已经可以用scrapy成功爬取数据啦!
三、下载selenium和chromdriver以及部署
*这个项目没用上,但是后面的动态渲染页面可能就会用到,所以提前下载部署好!
Selenium 是一个浏览器自动化工具,可以模拟用户操作浏览器,通过模拟浏览器操作(如点击,滚动)触发JS渲染,获取完整的页面源码。,需要安装Selenium和对应的浏览器驱动(如chromdriver)。
1、下载Selenium
通过 pip 安装:
#直接pip install 因为是国外的资源直接下载超时报错,所以用了中科大的镜像(推荐)
pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ selenium2、下载安装chromdriver
用chrom浏览器的下载浏览器驱动,先查看浏览器的版本号
浏览器最右边点击帮助-关于google chrome
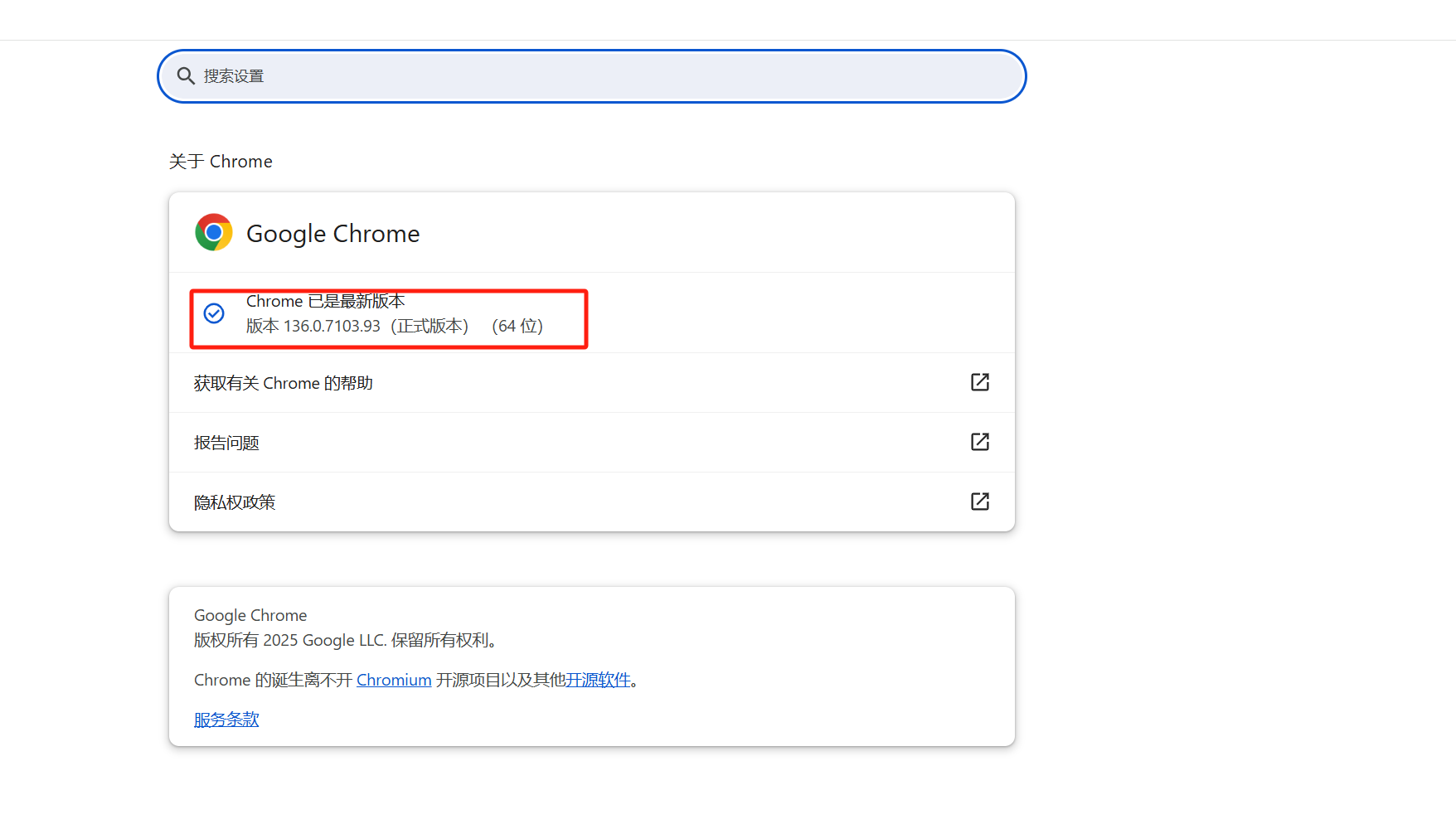
再去下载相对应的驱动,最新版本的驱动在这个地址
Chrome for Testing availability,根据自己的版本需求下载
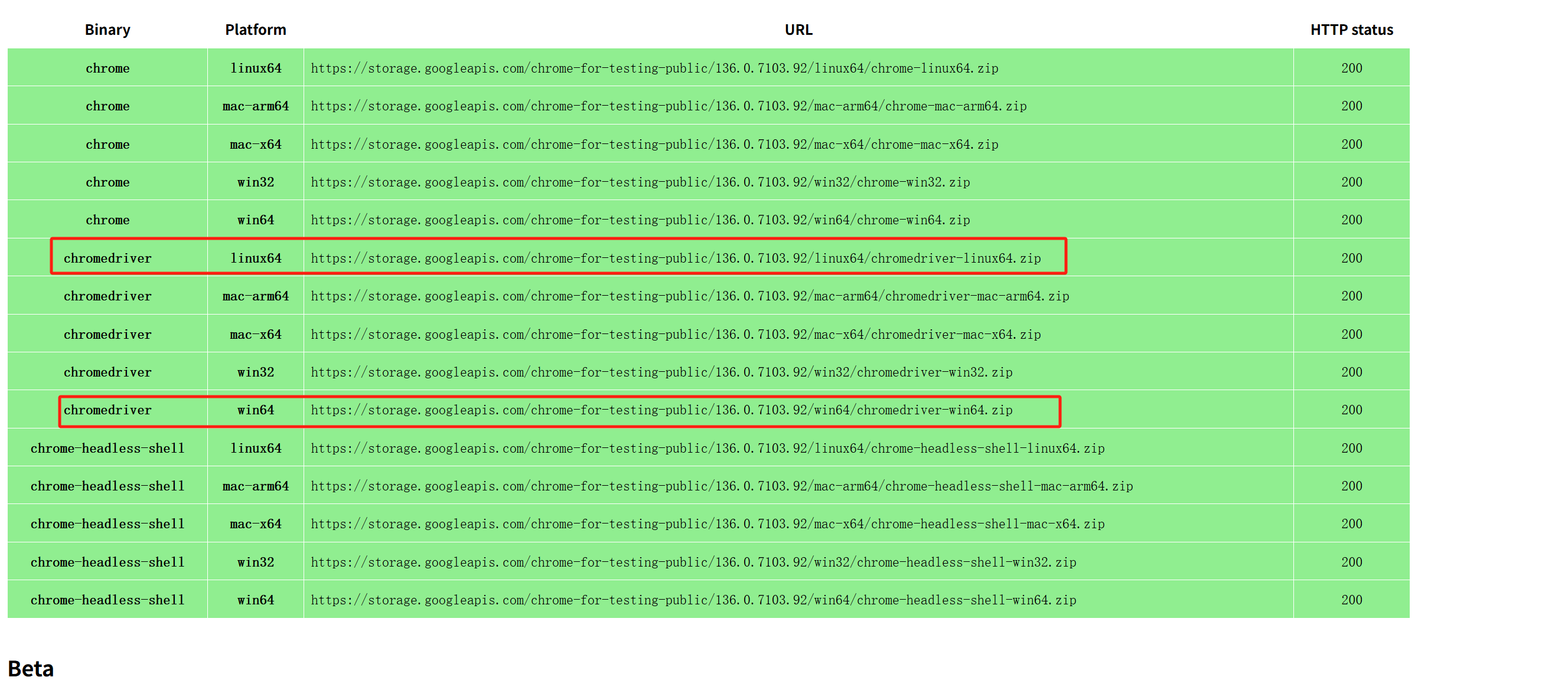
放置chromdriver.exe文件
python文件:解压zip文件后,把chromdriver.exe文件放在python的安装目录(有python.exe)下
anaconda文件:解压后放到anaconda3\Scripts下面
3、配置环境变量
环境变量的系统变量 path 编辑-新建,加入文件存放路径(如:D:\anaconda3\Scripts\chromdriver.exe)
3、运行测试
在python中执行
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.quit()自动跳出页面,部署成功!
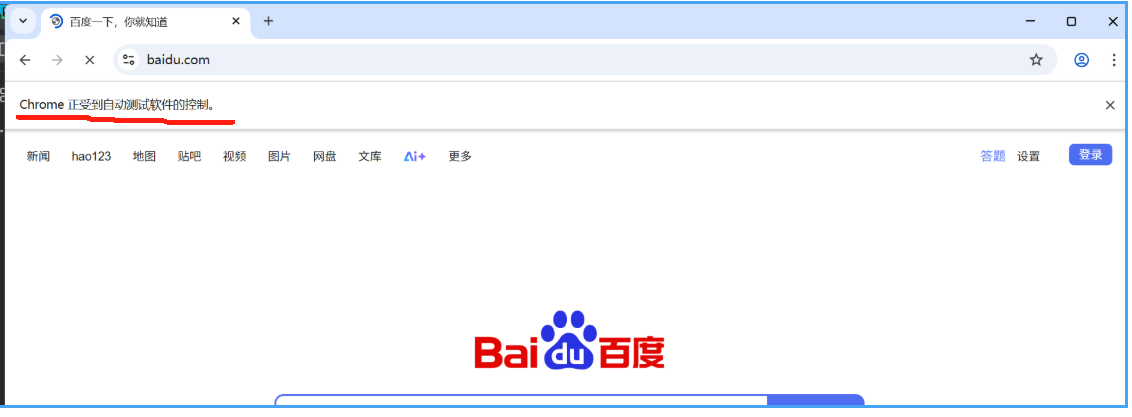


















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











