






SQL进阶笔记
文章目录
1、执行顺序
FROM>JOIN>WHERE>GROUP BY>HAVING>窗口函数>SELECT>DSITINCT>ORDER BY
2、窗口函数
2.1 概念
窗口函数一种特殊的分组函数,能够实现对数据分组,且分组以后不做聚合映射,而是针对分组后的每一个值去做单独映射。
mysql
SELECT * FROM sales ORDER BY country, year, product;
+------+---------+------------+--------+
| year | country | product | profit |
+------+---------+------------+--------+
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2001 | Finland | Phone | 10 |
| 2000 | India | Calculator | 75 |
| 2000 | India | Calculator | 75 |
| 2000 | India | Computer | 1200 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 1500 |
| 2001 | USA | Computer | 1200 |
| 2001 | USA | TV | 150 |
| 2001 | USA | TV | 100 |
+------+---------+------------+--------+
单独聚合:
mysql
SELECT SUM(profit) AS total_profit FROM sales;
+--------------+
| total_profit |
+--------------+
| 7535 |
+--------------+
SELECT country, SUM(profit) AS country_profit
FROM sales
GROUP BY country
ORDER BY country;
+---------+----------------+
| country | country_profit |
+---------+----------------+
| Finland | 1610 |
| India | 1350 |
| USA | 4575 |
+---------+----------------+
窗口函数的结果则是长这个样子:
mysql
SELECT year, country, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY country) AS country_profit
FROM sales
ORDER BY country, year, product, profit;
+------+---------+------------+--------+--------------+----------------+
| year | country | product | profit | total_profit | country_profit |
+------+---------+------------+--------+--------------+----------------+
| 2000 | Finland | Computer | 1500 | 7535 | 1610 |
| 2000 | Finland | Phone | 100 | 7535 | 1610 |
| 2001 | Finland | Phone | 10 | 7535 | 1610 |
| 2000 | India | Calculator | 75 | 7535 | 1350 |
| 2000 | India | Calculator | 75 | 7535 | 1350 |
| 2000 | India | Computer | 1200 | 7535 | 1350 |
| 2000 | USA | Calculator | 75 | 7535 | 4575 |
| 2000 | USA | Computer | 1500 | 7535 | 4575 |
| 2001 | USA | Calculator | 50 | 7535 | 4575 |
| 2001 | USA | Computer | 1200 | 7535 | 4575 |
| 2001 | USA | Computer | 1500 | 7535 | 4575 |
| 2001 | USA | TV | 100 | 7535 | 4575 |
| 2001 | USA | TV | 150 | 7535 | 4575 |
+------+---------+------------+--------+--------------+----------------+
2.2 窗口函数的形成
窗口函数的常见形式如下:
select
window_function() over(partition by col1 order by col2 frame clause)
from
table
1.window_function()代表可以用于窗口中的函数,如count(),sum(),row_number(),rank(),dense_rank()。
2.over()是函数的关键字,和window_function()一起构成必不可少项。也就是说一个窗口函数至少是rank() over()或者sum(profit) over()这种形式。over()中的内容则是可选项,可以有也可以没有。
3.partition by col1代表根据col1进行分组,order by col2代表根据col2对返回的结果排序。
4.frame clause是框架的意思,指窗口限定的范围,主要用于统计窗口范围内的值。常见语法形式如下:
select
window_function() over(rows between x and y)
from
table
举个例子:
mysql> SELECT
time, subject, val,
SUM(val) OVER (PARTITION BY subject ORDER BY time
ROWS UNBOUNDED PRECEDING) AS running_total, --根据subject分组,累积求和
AVG(val) OVER (PARTITION BY subject ORDER BY time
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS running_average --据当前数据的前一条和后一条以及当前数据求一个平均值。
FROM observations;
+----------+---------+------+---------------+-----------------+
| time | subject | val | running_total | running_average |
+----------+---------+------+---------------+-----------------+
| 07:00:00 | st113 | 10 | 10 | 9.5000 |
| 07:15:00 | st113 | 9 | 19 | 14.6667 |
| 07:30:00 | st113 | 25 | 44 | 18.0000 |
| 07:45:00 | st113 | 20 | 64 | 22.5000 |
| 07:00:00 | xh458 | 0 | 0 | 5.0000 |
| 07:15:00 | xh458 | 10 | 10 | 5.0000 |
| 07:30:00 | xh458 | 5 | 15 | 15.0000 |
| 07:45:00 | xh458 | 30 | 45 | 20.0000 |
| 08:00:00 | xh458 | 25 | 70 | 27.5000 |
+----------+---------+------+---------------+-----------------+
2.3 常用函数
2.3.1 排名函数
排名或者类似排名的问题,窗口函数的常用排名函数rank()/dense_rank()/row_number()就能很快的解决。
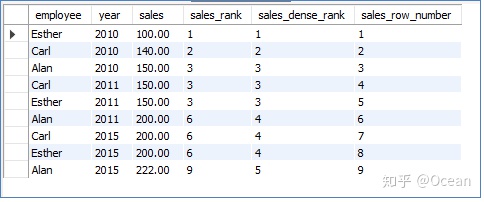
这里以员工销售量的排名为例,看一下排名函数区别:
rank():是跳跃排序,两个第二名下来就是第四名;
dense_rank():连续的排序,两个第二名仍然跟着第三名;
row_number():没有重复值的排序(即使两条记录相同,序号也不重复的),不会有同名次。
select
employee, year, sales,
RANK() over (order by salesasc) sales_rank,
DENSE_RANK() over (order by salesasc) sales_dense_rank,
row_number() over (order by salesasc) sales_row_number
from
sales;
结果如下:
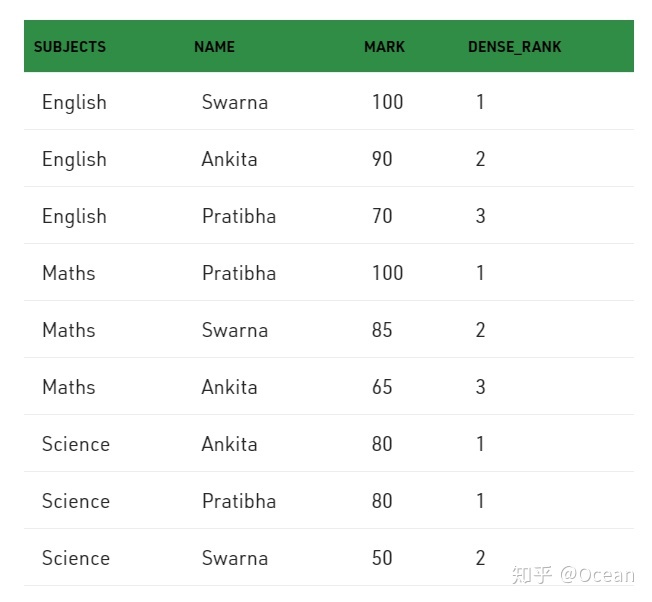
排名函数不仅可以求总的排名,还可以根据分组字段求组内的排名:
SELECT
subjects, s_name, mark,
dense_rank() OVER (partition by subjects order by mark desc) AS 'dense_rank'
FROM
result;
结果如下:
2.3.2 lag/lead前后窗口函数
求窗口内按一定顺序排好序后,一个值按此顺序的前N个值或后N个值。
lag ,lead 分别是向前,向后。lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值)
学生表student
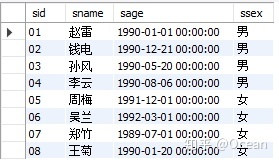
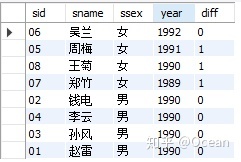
假设要求的是,按男女生分组,求男女生的出生年份按年份从小到大排序,每个人与前一个比他年纪小的人的年份的差值。代码如下:
select
sid,sname,ssex,year(sage) as 'year',
if(
lag(year(sage),1,0) over(partition by ssex order by sage desc)=0,0,
lag(year(sage),1,0) over(partition by ssex order by sage desc) - year(sage)
) as diff
from
student
;
结果如下:
2.3.3 nth_value分析窗口函数
-- 按部门 deptno 分组,查询每个部门的人员的薪资和该部门内排名第三的薪资金额的对比
-- 执行以下语句:
SELECT deptno
,ename
,sal
,nth_value(sal, 3)OVER (PARTITION BY deptno ORDER BY sal DESC rows BETWEEN unbounded preceding AND unbounded following) AS third_most_sal
FROM emp_msg
ORDER BY deptno,sal DESC;

SELECT deptno
,ename
,sal
,nth_value(sal, 3)OVER (PARTITION BY deptno ORDER BY sal DESC ) AS third_most_sal
FROM emp_msg ORDER BY deptno,sal DESC;

2.3.4 分布窗口函数
percent_rank() 函数
显示的结果,每行按照如下公式进行计算: (rank-1)/(rows-1)
rank 为 RANK() 函数产生的序号,rows 为当前窗口的记录总行数
对于重复值,取重复值的第一行记录的位置
cume_dist() 函数
显示的结果,每行按照如下公式进行计算:rank/rows
rank 为 RANK() 函数产生的序号,rows 为当前窗口的记录总行数
对于重复值,取重复值的最后一行记录的位置
2.3.5 头尾窗口函数
first_value(),last_value()
FIRST_value(指定字段) OVER(PARTITION BY 分区的字段 ORDER BY 排序的字段 DESC/ASC)
LAST_value(指定字段) OVER(PARTITION BY 分区字段 ORDER BY 排序的字段 DESC/ASC)
3、case when/if 函数
case when和if函数是做逻辑判断的函数,筛选符合特定规则的数据。这两个函数功能简单,但是使用起来的时候和其他函数进行搭配可以实现很多复杂功能。
2.1 等值替换/范围值替换
将符合规定的值转变为相应的另一个值,如下所示:
select
id, name, salary
(case when salary < 20000 then '初级打工人'
when salary < 40000 then '中级打工人'
else '高级打工人'
end) as type
from
table
这里实现的功能是根据salary的大小范围进行判断,然后在新的type字段赋值。一旦salary满足第一个条件,就不会再去后续的条件进行判断,所以条件的先后顺序要注意。
这个功能也可以用if来实现:
select
id, name, salary
if(salary<20000,'初级打工人',if(salary<40000,'中级打工人','高级打工人')) as type
from
table
if(expr,x,y)代表若expr成立,则输出x,否则输出y。这里用了一个嵌套的if来实现两个判断逻辑。一般来说,在只有一个判断逻辑的情况下,用if函数会比case when函数看上去更加简洁一些。
2.2 行转列功能
假设我们有一个学生的成绩表,如下所示:
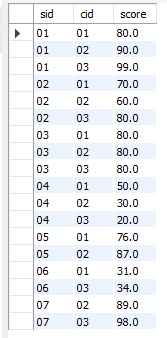
表中sid代表student_id,cid代表course_id,score代表学生对应课程的分数。现在我们想要看每个学生的cid所对应的成绩,那么就要把每个cid都转成列的形式。代码如下:
SELECT
sid,
SUM(IF(`cid`='01',score,0)) AS 语文,
SUM(IF(`cid`='02',score,0)) AS 数学,
SUM(IF(`cid`='03',score,0)) AS 英语,
SUM(score) AS TOTAL
FROM
sc
GROUP BY
sid
UNION
SELECT
'TOTAL',
SUM(IF(`cid`='01',score,0)) AS 语文,
SUM(IF(`cid`='02',score,0)) AS 数学,
SUM(IF(`cid`='03',score,0)) AS 英语,
SUM(score)
FROM
sc
;
结果如下:
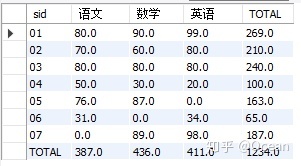
这个结果跟excel中的透视表非常相似。
2.3 其他妙用
- case when 形成新的field 可以直接在group by 或者where 后面过滤
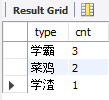
我们假设要设计一个新的分类,数学(cid='02')成绩大于85分的人是学霸,及格的是菜鸡,剩下的是学渣。根据这个三个值形成一个新的字段type,再根据type进行分类,求每个类别各有多少人。
代码如下:
select
case when score > 85 then '学霸'
when score > 59 then '菜鸡'
else '学渣' end as 'type',
count(1) cnt
from
sc
where
cid = '02'
group by
1;
代码中的group by 1就意味着根据第一个字段进行分类,这也是一个小技巧。代码结果如下:
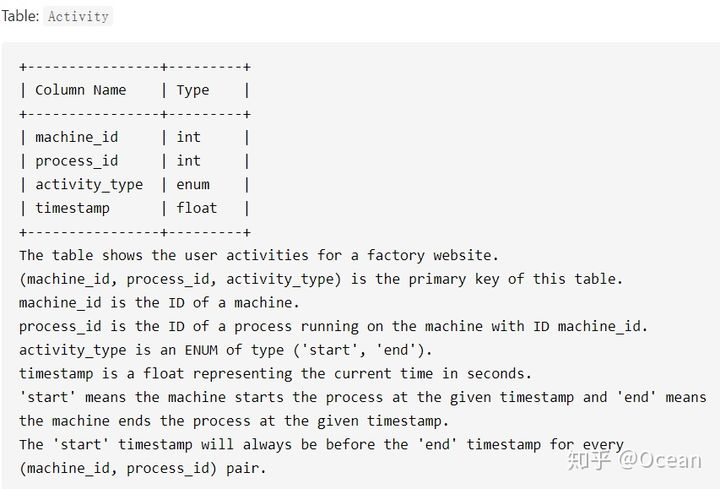
- 带条件的聚合
以leetcode的1661题为例,要求计算每台机器每个进程的平均时间。表如下:
代码如下:
select
machine_id,
round(sum(if(activity_type='start',-timestamp,timestamp))/
count(distinct process_id),3) processing_time
from
Activity
group by
machine_id
sum(if(expr,x,y))就是说expr成立时,加上x,否则加上y,题目要求计算结束进程减去开始进程的时间,所以这里的就是说activity为start时,加上一个负的time,否则就加上一个正的time,加上一个负的时间,就是减去这个时间,所以这就刚好是结束时间减去开始时间。
4、变量
变量就是一个可以反复调用的参数,一般用set和select对其进行赋值。我们为了以后调用方便,可以提前把一些需要反复输入的数值保存在变量中。
4.1 变量赋值
变量的赋值有set和select两种方式。
set的赋值方式:
mysql> SELECT c1 FROM t;
+----+
| c1 |
+----+
| 0 |
+----+
| 1 |
+----+
mysql> SET @col = "c1";
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @col FROM t;
+------+
| @col |
+------+
| c1 |
+------+
select的赋值方式:
mysql>SELECT @name := thing FROM limbs WHERE legs=0;--select使用`:=`的方式进行赋值,而set`=`和`:=`的方式都可以
+----------------+
| @name := thing |
+----------------+
| squid |
| octopus |
| fish |
|phonograph. |
+----------------+
mysql>SELECT @name; --变量不能取多个值,否则只返回多个值的最后一个值!
+--------------+
| @name |
+--------------+
| phonograph |
+--------------+
变量的使用场景非常广泛,如经常使用某个时间作为限制:
set @d1 = date('2020-12-12');
set @d2 = date('2020-11-11');
--两个子查询的表都需要做一些的时间上的限制,这个时候如果反复写一些相同的时间会看上去不太简洁,就可以用变量进行替代。
select
a.c1,c2,c3
from
(select c1,c2 from table_a where c1 between @d1 and @d2) a
left join
(select c1,c3 from table_b where c1 = @d2) b
on
a.c1 = b.c1
group by
1
4.2 其他用法
- 累计赋值
初始化两个变量type和num,然后用num在不同条件下进行赋值计算
set @type := '', @num := 1;
select type, variety,
@num := if(@type = type, @num + 1, 1) as row_number,
@type := type as dummy
from fruits
order by type, variety;
# output
+--------+------------+------------+--------+
| type | variety | row_number | dummy |
+--------+------------+------------+--------+
| apple | fuji | 1 | apple |
| apple | gala | 2 | apple |
| apple | limbertwig | 3 | apple |
| cherry | bing | 1 | cherry |
| cherry | chelan | 2 | cherry |
| orange | navel | 1 | orange |
| orange | valencia | 2 | orange |
| pear | bartlett | 1 | pear |
| pear | bradford | 2 | pear |
+--------+------------+------------+--------+
- 特殊场景生成辅助列
在LeetCode的1336. 每次访问的交易次数中,需要求出从0到每个交易次数的最大值。一般用分组求和然后表连接的方式就能解决,但这里比较刁钻的是要列出从0到最大交易次数的所有值,即便是频数为0的交易次数。所以在这种情况下就可以用变量的方式去生成这个从0到最大交易次数的数值辅助列。
代码如下:
with tmp as
(
select sum(amt>0) cnt
from
(
select user_id,visit_date dt,0 amt from Visits
union all
select user_id,transaction_date dt,amount amt from Transactions
) all_data
group by user_id,dt
)
select
floor(n) transactions_count,count(cnt) visits_count
from
(
select 0 as n
union all
# 用变量的方式列举出了从0到n的交易次数,在外层用where进行限制
select (@x := @x+1) as n from Transactions,(select @x := 0) num
) nums
left join
tmp on nums.n = tmp.cnt
where
n <= (select max(cnt) from tmp)
group by
n
5、CTE
CTE(Common Table Expression) 公用表表达式的语法,CTE是在单个语句的执行范围内定义的临时结果集,只在查询期间有效。它可以自引用,也可在同一查询中多次引用,实现了代码段的重复利用。
CTE可以看成是子查询或者是临时视图,它可以把一个子查询用with as的方法存到一个临时表中,方便在后面可以反复调用,代码看起来也会更加容易理解。优点是可读性强,优化了查询性能。
5.1 CTE的形式
创建tmp1,tmp2作为临时表,然后从临时表的笛卡尔积中查询所有的元素:
with
tmp1 as(select 1),
tmp2 as(select 2)
select * from tmp1,tmp2
用临时表的连接进行查询,这也是最常用到的情况之一:
WITH
cte1 AS (SELECT a, b FROM table1),
cte2 AS (SELECT c, d FROM table2)
SELECT b, d FROM cte1 JOIN cte2 WHERE cte1.a = cte2.c;
在某些特殊的情况下,需要用到临时表内的所有值,表内可以用union all,然后对每个column进行命名:
- 提前命名
WITH cte (col1, col2) AS
(
SELECT 1, 2
UNION ALL
SELECT 3, 4
)
SELECT col1, col2 FROM cte;
- 表内命名
WITH cte AS
(
SELECT 1 AS col1, 2 AS col2
UNION ALL
SELECT 3, 4
)
SELECT col1, col2 FROM cte;
5.2 递归
用with as的方法形成的递归其实就是不停地引用’自己’,代码如下:
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 5
)
SELECT * FROM cte;
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+------+
递归表的开头必须是with recursive,这是限定的语法。后面再接上表名cte和递归字段的名称n(字段名不加也无妨,可以写在表中)。
表中:
SELECT ... -- return initial row set 初始化
UNION ALL
SELECT ... -- return additional row sets 递归的规律
递归例子1:
n对自己进行递归,而p和q分别引用对方进行递归
WITH RECURSIVE cte AS
(
SELECT 1 AS n, 1 AS p, -1 AS q
UNION ALL
SELECT n + 1, q * 2, p * 2 FROM cte WHERE n < 5
)
SELECT * FROM cte;
+------+------+------+
| n | p | q |
+------+------+------+
| 1 | 1 | -1 |
| 2 | -2 | 2 |
| 3 | 4 | -4 |
| 4 | -8 | 8 |
| 5 | 16 | -16 |
+------+------+------+
递归例子2:
假设原始数据是这个样子:
mysql> SELECT * FROM sales ORDER BY date, price;
+------------+--------+
| date | price |
+------------+--------+
| 2017-01-03 | 100.00 |
| 2017-01-03 | 200.00 |
| 2017-01-06 | 50.00 |
| 2017-01-08 | 10.00 |
| 2017-01-08 | 20.00 |
| 2017-01-08 | 150.00 |
| 2017-01-10 | 5.00 |
+------------+--------+
我们现在要知道最小时间和最大时间内每天的总价格是多少,包括那些不在表中的时间,如2017年1月4日。这时候就可以用递归的方式生成3号到10号中的每一天作为时间表,然后再进行表连接即可。代码如下:
WITH RECURSIVE dates (date) AS
(
SELECT MIN(date) FROM sales
UNION ALL
SELECT date + INTERVAL 1 DAY FROM dates
WHERE date + INTERVAL 1 DAY <= (SELECT MAX(date) FROM sales)
)
SELECT dates.date, COALESCE(SUM(price), 0) AS sum_price
FROM dates LEFT JOIN sales ON dates.date = sales.date
GROUP BY dates.date
ORDER BY dates.date;
+------------+-----------+
| date | sum_price |
+------------+-----------+
| 2017-01-03 | 300.00 |
| 2017-01-04 | 0.00 |
| 2017-01-05 | 0.00 |
| 2017-01-06 | 50.00 |
| 2017-01-07 | 0.00 |
| 2017-01-08 | 180.00 |
| 2017-01-09 | 0.00 |
| 2017-01-10 | 5.00 |
+------------+-----------+
6、 group_concat 函数
6.1 概念
group_concat()函数是把groupby分组后的字段中的非null的值,用concat的方法连接起来,然后返回一个字符串。它的语法格式如下:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
# 写法
mysql> SELECT student_name,
GROUP_CONCAT(test_score)
FROM student
GROUP BY student_name;
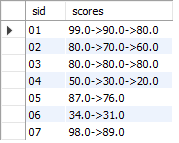
引用上面2.2行转列功能的学生成绩数据,我们求每一个学生的每一科目的成绩从大到小排序,要求放在一个字段中。代码如下:
select
sid,group_concat(score order by score desc separator '->') scores
from
sc
group by
sid;
结果如下:
6.2 其他用法
- 分组后的组间复杂比较
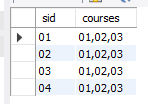
同样采样学生成绩的数据,我们要求出和cid为01的同学选了一模一样的课程的同学,代码如下:
with t as(
select sid,group_concat(cid order by cid) courses from sc group by sid
)
select
sid,courses
from
t
where
courses = (select courses from t where sid = '01');
也可以这样写:
select
sid,group_concat(cid order by cid) courses
from
sc
group by
sid
having
courses = (select group_concat(cid order by cid) from sc where sid='01');
两份代码返回的结果都是一样的:
7、SQL优化
SQL语句有时候写得太复杂会造成运算速度太慢,那么就需要对SQL语句进行优化。(如果数据库软件自带编译优化,那么其实SQL语句优化的空间并不大,只要无脑增加计算资源节点就好,只要资源足够强大,软件足够智能,就算SQL写得再烂也造成不了多大的影响,哪怕你写个笛卡尔积)。
但是大部分情况下,数据库软件是没有那么智能的,计算资源也是有限的,所以还是需要学习一下如何优化SQL语句。
优化的核心思想是:
- 提高计算性能
- 缩小查询范围
7.1 常见优化方法
-
确定列名,少用*号,确定性的column会减少资源的消耗
-
尽量避免嵌套子查询,子查询很消耗资源,尤其是in (subquery)
-
避免使用耗费资源的操作:
-
1)用group by代替distinct
-
2)少用order by,因为排序的计算复杂度很高
-
多表关联时要尽量过滤条件,可以减少笛卡尔积的大小
-
left join的时候,选择小表作为驱动表(小left join大)
-
用union all代替or操作,可以减少计算资源的消耗
7.2 针对索引的优化
7.2.1 执行计划
对索引进行优化时,我们首先要知道一个查询语句中,它的执行计划是怎样的,使用了哪一种类型的索引,查询的性能如何。而这些信息使用explain语句就能看到结果,如:
explain select * from table where age = '18'
返回的结果一般会如下图所示:

我们需要关注select_type,type,possible_keys,key,key_len,rows,Extra这几列的信息:
select_type: select查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询
simple:简单查询, 简单的select查询,查询中不包含子查询或者union查询
primary:主键查询, 查询中若包含任何复杂的子部分,最外层查询则被标记为primary
subquery:子查询, 在select或者where列表中包含子查询
derived:临时表, 在from表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放在零时表中
union:联合查询, 如果第二个select出现在union之后,则被标记为union查询.如果包含在from字句的查询中,外层select将被标记为derived
union result:联合查询中查询的结果,从union表获取结果的select查询
type : 查询所使用的类型,在表中找到所需行的方式,又称“访问类型”
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys: 可能使用的索引, 但不一定被查询实际使用
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。
key:实际使用的索引,如果为null,则没有使用索引
key_len:使用的索引长度,越短越好
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。如果键是NULL,长度就是NULL。文档提示特别注意这个值可以得出一个多重主键里实际使用了哪一部分。key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
rows: 这个数表示mysql要遍历多少数据才能找到
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,在innodb上可能是不准确的
Extra: 包含不适合在其他列中显示但十分重要的额外信息
\1. distinct: 在select部分使用了distinct关键字
\2. Using filesort: 当 Extra 中有 Using filesort 时, 表示需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
\3. Using index: “覆盖索引扫描”, 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错
\4. Using temporary: 查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化
7.2.2 索引的优化
针对索引的优化主要是基于explain语句的结果,即用explain语句查看执行计划,从而对症下药:
- 不要对索引列(一般是primary key)做函数操作,因为这样做会使得索引失效
- 对索引用通配符,!=, null, or, in等操作也会使得索引失效,导致查询变成全表扫描,效率很低
- 当用索引列做where的筛选field时,不要在操作符的左边做改动,如
# 错误写法
select * from table where age*2 = 36
# 正确写法
select * from table where age = 36/2
8、实战指路
level 1-1: 50道SQL经典练习题,刷完这50道SQL,水平差不多可以达到及格或以上。
level 1-2: 牛客网SQL练习题,刷完牛客网的SQL,水平就到了可以参加数据分析笔试的水准。
level 2-1: [LeetCode数据库专项练习](
SQL中常用的日期函数
1.getdate()返回当前系统日期
select getdate()
--2021-03-19 18:30:33.563
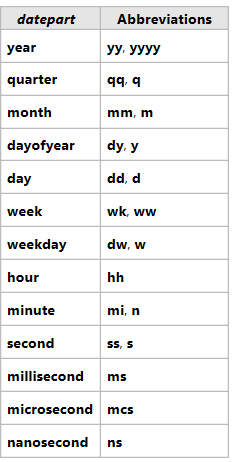
2.dateadd(日期部分,常数,日期)
返回将日期的指定日期部分加常数后的结果
datesub(日期部分,常数,日期)返回将日期的指定日期部分减去常数后的结果
日期部分可以写成:
select dateadd(yy,1,getdate())
--等同于select dateadd(year,1,getdate())
--2022-03-19 18:30:33.563
select dateadd(yy,-2,getdate())
--2019-03-19 18:30:33.563
--若常数为小数,直接舍去小数部分
select dateadd(yy,1.2,getdate())
--2022-03-19 18:30:33.563
3.datediff(日期部分,日期1,日期2)
返回两个日期之间的差值,日期部分(日期1-日期2)
日期1>日期2
select datediff(yy,'2011/01/01',getdate())
--10
4.datename()
返回指定日期的日期部分的字符串(返回字符串)
select datename(YY,getdate())
--2021
此时的+是连接符号
select datename(yy,getdate())+datename(qq,getdate())--qq是季节
--20213
5.datepart()
返回指定日期的日期部分的整数(返回整数)
select datepart(yy,getdate())
--2021
此时的+是加法符号
select datepart(yy,getdate())+datepart(qq,getdate())
--2022
6.day()
返回指定日期的日部分的整数
select day(getdate())
--19
7.month()
返回指定日期的月部分的整数
select month(getdate())
--3
8.year()
返回指定日期的年部分的整数
select year(getdate())
--2021
SQL中的取整函数
1 trunc(value,precision)按精度(precision)截取某个数字,不进行舍入操作。
2 round(value,precision)根据给定的精度(precision)输入数值。
3 ceil (value) 产生大于或等于指定值(value)的最小整数。
4 floor(value)与 ceil()相反,产生小于或等于指定值(value)的最小整数。
5 sign(value) 与绝对值函数ABS()相反。ABS()给出的是值的量而不是其符号,sign(value)则给出值的符号而不是量。














 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









