







Benchmark Analysis of Representative Deep Neural Network Architectures
ABSTRACT
- 这项工作对目前(2018)提出的用于图像识别的大多数深度神经网络(DNNs)进行了深入分析。(可直接看结论)
- 对每个DNN的多个性能指标进行了观察,如识别精度、模型复杂度、计算复杂度、内存使用和推理时间。本文分析和讨论了这些性能指标的行为以及它们的一些组合。为了测量这些指数,本文在两种不同的计算机架构上实验了DNN的使用,一种是配备了NVIDIA Titan X Pascal的工作站,另一种是基于NVIDIA Jetson TX1板的嵌入式系统。
- 这种实验可以直接比较在计算能力非常不同的机器上运行的DNN。这项研究对于研究人员来说非常有用,他们可以全面了解到目前为止已经探索过的解决方案,以及未来值得探索的研究方向;对于实践者来说,可以选择更适合实际部署和应用的资源限制的DNN架构。为了完成这项工作,所有的DNN以及用于分析的软件都可以[在线获得](CeLuigi/models-comparison.pytorch: Code for the paper Benchmark Analysis of Representative Deep Neural Network Architectures (github.com))。
- [论文](Benchmark Analysis of Representative Deep Neural Network Architectures | IEEE Journals & Magazine | IEEE Xplore)
INTRODUCTION
- 深度神经网络(DNNs)在许多计算机视觉任务中取得了显著的成果[1]。AlexNet是2012年文献中提出的第一个DNN,在1000个类别的ImageNet大规模视觉识别竞赛(ImageNet-1k)中,与传统方法相比,识别精度大幅提高(高出10%左右)。从那时起,各种论文研究既致力于设计更准确的网络,也致力于从计算成本的角度设计更有效的网络。
- 虽然有很多文献从层组成和识别性能的角度讨论了新的架构,但很少有论文分析与计算成本(内存使用、推理时间等)有关的方面,更重要的是计算成本如何影响识别的准确性。
- Canziani等人在2016年上半年提出了对一些DNN架构的综合分析,在基于NVIDIA Jetson TX1板的嵌入式系统上进行了实验。他们测量了精度、功耗、内存占用、参数数量和操作数,更重要的是他们分析了这些性能指标之间的关系。这是一项有价值的工作,但它只关注了有限数量(即14个)的DNN,更重要的是实验只在NVIDIA Jetson TX1板上进行了。
- 在文献[Speed/accuracy trade-offs for modern convolutional object detectors]中,通过重新实现一套受当前著名检测网络启发的元架构,探索了现代基于DNN的检测系统的速度/准确性权衡。结果包括英特尔至强CPU和NVIDIA Titan X GPU之间的性能比较。
- 这项工作的目的是对现有的用于图像识别的DNN进行更全面和完整的分析,最重要的是在两个计算能力截然不同的硬件平台上进行分析:一个配备了NVIDIA Titan X Pascal(通常被称为Titan Xp)的工作站和一个基于NVIDIA Jetson TX1的嵌入式系统。
- 为此,本文分析和比较了40多个最先进的DNN架构的计算成本和准确性。特别是,本文在ImageNet-1k挑战赛上对所选的DNN架构进行了实验,本文测量了:准确率、模型复杂性、内存使用量、计算复杂性和推理时间。
- 这些性能指标之间的差异,为以下方面提供了启示。
- 1)了解到目前为止已经探索了哪些解决方案,以及未来适合向哪个方向发展;
- 2)选择更适合实际部署和应用的资源限制的DNN架构。
- 最重要的发现是:
- i) 识别精度不会随着操作数的增加而增加;
- ii) 模型复杂度和精度之间没有线性关系;
- iii) 所需的吞吐量为可实现的精度设置了上限;
- iv) 并非所有的DNN模型都以相同的效率水平使用其参数;
- v) 几乎所有的模型都能在高端GPU上实现超实时性能,而只有部分模型能在嵌入式系统上保证;
- vi) 即使模型复杂度很低的DNN,其GPU内存占用量最小约为0.6GB。
BENCHMARKING
- 本文用Python实现了DNNs比较的基准框架。PyTorch软件包被用于神经网络处理,后端为cuDNN-v5.1和CUDA-v9.0。所有用于估计所采用的性能指数的代码以及所有考虑的DNN模型都是公开的。
- 本文在一台工作站和一个嵌入式系统上运行所有的实验。
- 该工作站配备了英特尔Core I7-7700 CPU @ 3.60GHZ,16GB DDR4 RAM 2400 MHz,NVIDIA Titan X Pascal GPU,拥有3840个CUDA核心(当时顶级消费级GPU)。操作系统是Ubuntu 16.04。
- 该嵌入式系统是一块英伟达Jetson TX1板,配备64位ARM®A57 CPU @ 2GHz,4GB LPDDR4 1600MHz,英伟达Maxwell GPU有256个CUDA内核。该板包括JetPack-2.3 SDK。
- 使用这两个不同的系统可以强调计算资源是多么关键,这取决于所采用的DNN模型,特别是在内存使用和推理时间方面。
ARCHITECTURES
-
本文简要地描述了所分析的网络结构。本文选择了不同的架构,其中一些被设计成在效果上更有表现力,而另一些被设计成更有效率,因此更适合于嵌入式视觉应用。在某些情况下,架构的名称后面有一个数字。这样的数字描述了包含要学习的参数的层数(即卷积层或全连接层)。
-
本文考虑以下网络。
- AlexNet 2012-NIPS;
- VGG架构系列(VGG-11、-13、-16和19)ICLR 2015,没有使用和使用批量规范化(BN)层;
- BN-Inception 2015-ICML;
- GoogLeNet 2015-CVPR;
- SqueezeNetv1.0和-v1. 1;
- ResNet-18, -34, -50, -101和-152 2016-CVPR;
- Inception-v3 2016-CVPR;
- Inception-v4和Inception-ResNetv2 2016-ICLR;
- DenseNet-121, -169和-201,增长率对应为32,以及DenseNet-161,增长率等于48 2017-CVPR。
- ResNeXt-101(32x4d)和ResNeXt-101(64x4d) 2017-CVPR,其中括号内的数字分别表示每个卷积层的组数和瓶颈宽度。
- Xception 2017-CVPR;
- DualPathNet68、-98和-131 2017-NIPS;
- SE-ResNet-50、SENet-154、SEResNet-101、SE-ResNet-152、SE-ResNeXt-50(32x4d)、SEResNeXt-101(32x4d) 2018-CVPR;
- NASNet-A-Large和NASNet-A-Mobile 2018-CVPR,其架构是直接学会的。
-
此外,本文还考虑了以下以效率为导向的模型。MobileNet-v1 2017-CVPR, MobileNet-v2 2018-CVPR , and ShuffleNet 2017-CVPR.
PERFORMANCE INDICES
- 为了进行直接和公平的比较,本文完全重现了相同的采样实验设置:本文直接收集用PyTorch框架训练的模型,或者收集用其他深度学习框架训练的模型,然后在PyTorch中转换。
- 所有的预训练模型都期望输入的图像以同样的方式归一化,即形状为3×H×W的小型批次的RGB图像,其中H和W是被设置为:
- NASNet-A-Large模型为331个像素。
- InceptionResNet-v2、Inception-v3、Inception-v4和Xception模型的229个像素。
- 所有其他考虑的模型都是224像素。
- 本文考虑对DNN模型的综合基准有用的多种性能指标。具体来说,衡量了:准确率、模型复杂性、内存使用、计算复杂性和推理时间。
ACCURACY RATE
- 本文在ImageNet-1k验证集上估计了图像分类任务的Top-1和Top-5准确性。预测是通过评估中央对象来计算的。考虑到来自多个对象(四个角加上中央作物和它们的水平翻转)的平均预测,可以取得略微更好的性能。
MODEL COMPLEXITY
- 本文通过计算可学习参数的总量来分析模型的复杂性。具体来说,本文收集所考虑的模型的参数文件的大小,以MB为单位。这一信息对于了解每个模型所需的最小GPU内存量非常有用。
MEMORY USAGE
- 本文评估了总的内存消耗,其中包括所有被分配的内存,即为网络模型分配的内存和处理批处理时需要的内存。本文测量了不同批量大小的内存使用情况。1、2、4、8、16、32和64。
COMPUTATIONAL COMPLEXITY
- 本文使用浮点运算(FLOPs)来衡量每个DNN模型的计算成本,如[Aggregated residual transformations for deep neural networks]中的乘加数。更详细地说,乘加运算被算作两个浮点运算,因为在许多最近的模型中,卷积是无偏置的,将乘加运算算作独立的浮点运算是有意义的。
INFERENCE TIME
- 本文报告了NVIDIA Titan X Pascal GPU和NVIDIA Jetson TX1的每个DNN模型的推理时间。本文以毫秒为单位衡量推理时间,并考虑相同批次大小。对于统计验证,报告的时间对应于10次运行的平均值。
RESULTS
ACCURACY-RATE VS COMPUTATIONAL COMPLEXITY VS MODEL COMPLEXITY
- 下图(a)和(b)中报告的球图显示了ImageNet-1k验证集的Top1和Top5准确率,与工作站和嵌入式板测量的单次前向传递的计算复杂度有关。
-

-
图一:Ball chart reporting the Top-1 and Top-5 accuracy vs. computational complexity.
-
报告了仅使用中心对象的Top-1和Top-5精度与单次前进所需的浮点运算(FLOPs)。每个球的大小对应于模型的复杂性。
- (a) Top-1;
- (b) Top-5。
-
- 从图中可以看出,达到最高Top-1和Top-5精度的DNN模型是NASNet-A-Large,也是计算复杂度最高的模型。 在 计 算 复 杂 度 最 低 的 模 型 中 ( 即 低 于 5 G − F L O P s ) \textcolor{blue}{在计算复杂度最低的模型中(即低于5G-FLOPs)} 在计算复杂度最低的模型中(即低于5G−FLOPs),SE-ResNeXt50(32x4d)是达到最高Top-1和Top5准确率的模型,同时显示出较低的模型复杂度,大约为2.76M-params。
- 总的来说, 计 算 复 杂 度 和 识 别 精 度 之 间 似 乎 没 有 关 系 \textcolor{red}{计算复杂度和识别精度之间似乎没有关系} 计算复杂度和识别精度之间似乎没有关系,例如,SENet-154需要的操作数是SE-ResNeXt-101(32x4d)的3倍,而精度几乎相同。此外,模型复杂度和识别精度之间似乎也没有关系:例如,VGG-13的模型复杂度(球的大小)比ResNet-18高得多,而精度几乎相同。
ACCURACY-RATE VS LEARNING POWER
- 众所周知,DNN在使用其全部学习能力方面效率不高(以相对于自由度的参数数量衡量)。虽然有许多论文利用这一特点产生了与原始模型相同精度的压缩DNN模型[Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding],但本文想在这里衡量每个模型对其参数的使用效率。
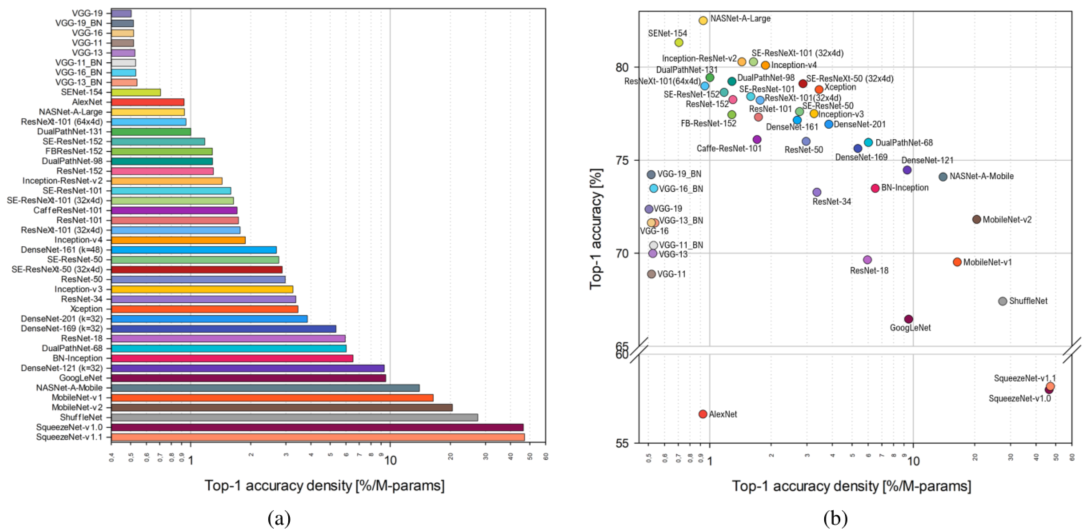
- 本文遵循[An analysis of deep neural network models for practical applications],用Top-1精度密度来衡量, 即 T o p − 1 精 度 除 以 参 数 数 量 。 该 值 越 高 , 效 率 越 高 \textcolor{green}{即Top-1精度除以参数数量。该值越高,效率越高} 即Top−1精度除以参数数量。该值越高,效率越高。
- 下图(a)报告了这一情况,可以看出,最有效地使用其参数的模型是SqueezeNets、ShuffleNet、MobileNets和NASNet-A-Mobile。为了关注密度信息,本文绘制了Top-1准确度与Top-1准确度密度的关系图(见下图(b)),这样可以更容易地找到所需的折衷方案。
-

-
图二:准确度密度衡量每个模型使用其参数的效率。
-
Top-1精度密度(a)
-
Top-1精度与Top-1精度密度(b)。
-
- 通过这种方式,本文可以很容易地看到,在最有效的模型中,NASNet-A-Mobile和MobileNet-v2是两个提供更高的Top1准确率的模型。在具有最高Top-1精确度的模型中(即高于80%),本文可以观察到更有效地使用其参数的模型是Inceptionv4和SE-ResNeXt-101(32x4d)。
INFERENCE TIME
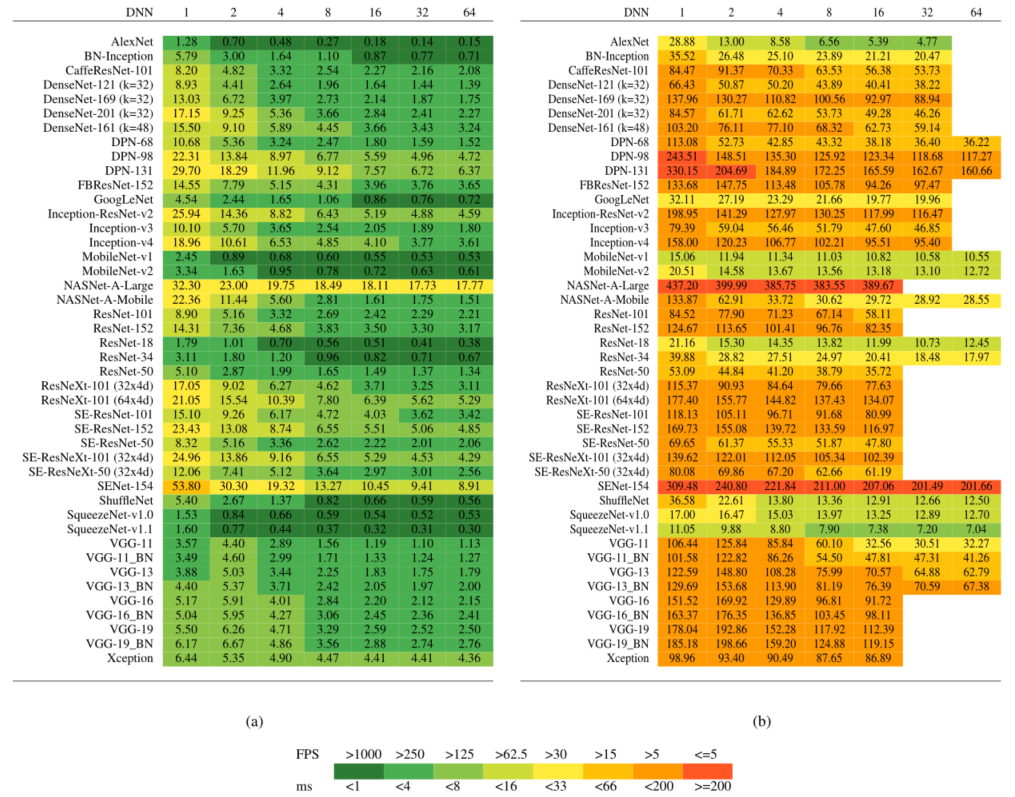
- 下表(a)和(b)报告了在Titan Xp和Jetson上运行所有DNN模型的10次平均每幅图像推理时间,批次大小等于1、2、4、8、16、32和64。推理时间以毫秒为单位,表(a)和(b)中的条目用颜色编码,以便于以每秒帧数(FPS)进行转换。
-

-
表一:推理时间与批次大小。Titan Xp(左)和Jetson TX1(右)的每张图片的推理时间是根据不同的批次大小估算的。缺少的数据是由于缺乏足够的系统内存来处理较大的批次。
-
- 从表中可以看出,所有考虑的DNN模型都能在Titan Xp上实现超实时性能,只有SENet154例外,当考虑批处理量为1时。相反,在Jetson上,只有少数模型在考虑批量大小为1时能够实现超实时性能,即:SqueezeNets、MobileNets、ResNet-18、GoogLeNet和AlexNet。缺少的测量结果是由于缺乏足够的系统内存来处理较大的批次。
ACCURACY-RATE VS INFERENCE TIME
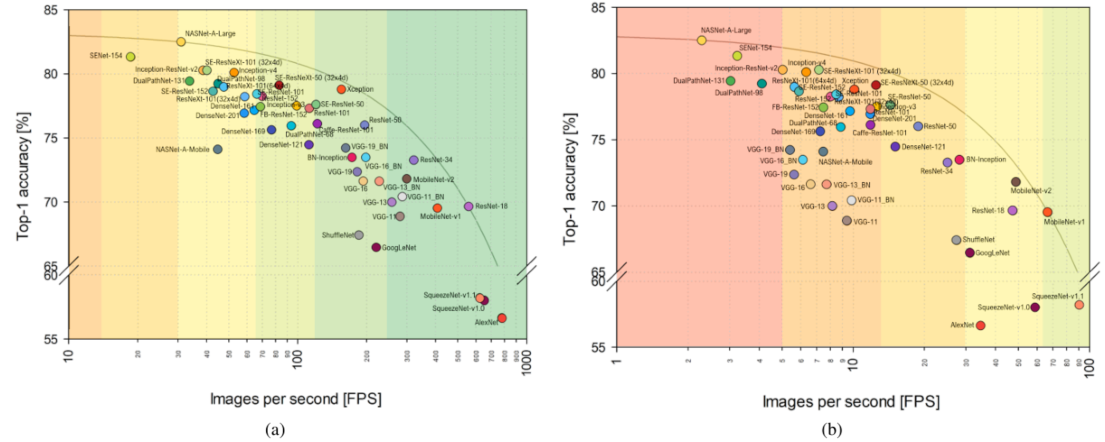
- 在下图(a)和(b)中,本文报告了在Titan Xp和Jetson TX1上,批量大小为1时,top-1的准确度与每秒处理的图像数(即每秒推断的数量)的关系图。在每张图上还报告了线性上界;两者的截距几乎相同(Titan Xp为≈83.3,Jetson TX1为≈83.0),但前者的斜率几乎比后者小8.3倍(-0.0244比-0.2025);
-

-
图三:使用Titan Xp(a)和Jetson TX1(b)每秒处理的图像数量(批量大小为1)的Top-1精度。
-
- 这些上界表明,Titan Xp保证在需要较大吞吐量时可实现最大精度的低衰减。请注意,由于每秒图像轴的对数比例,该界限在图中显示为一条曲线而不是直线。
- 从Titan Xp(a)图中可以看出,
- 如果目标吞吐量超过250 FPS,给出最高精度的模型是ResNet-34,有73.27%的Top-1精度;
- 目标超过125 FPS,给出最高精度的模型是Xception,有78.79%的Top-1精度;目标超过62. 5 FPS时,准确率最高的模型是SE-ResNeXt-50 (32x4d),有79.11%的最高准确率;
- 目标值超过30 FPS时,准确率最高的模型是NASNet-A-Large,有82.50%的最高准确率。这一分析表明,即使是目前最准确的模型,即NASNet-A-Large,也能够在Titan Xp上提供超实时性能(30.96 FPS)。
- 考虑到Jetson TX1(b)的情况,本文可以看到,
- 如果以超实时性能为目标,提供最高精度的模型是MobileNet-v2,其Top-1精度为71. 81%;
- 如果以大于75%的Top-1精度为目标,ResNet-50实现了最大的吞吐量(18,83 FPS);
- 以大于80%的Top-1精度为目标,SE-ResNeXt-101(32x4d)实现了最大的吞吐量(7,16 FPS);
- 以目前最高的Top-1精度为目标,可实现的吞吐量是2,29 FPS。
MEMORY USAGE
- 在下表中,本文分析了所有DNN模型在Titan Xp上不同批次规模的内存消耗。从报告的内存足迹可以看出,当批量大小为1时,大多数模型需要不到1GB的内存,但NASNet-ALarge、SE-ResNets、SE-ResNeXTs、SENet-154、VGGs和Xception除外。然而,在批处理量为1的情况下,它们中没有一个需要超过1.5GB。
-

-
表二:在Titan Xp上考虑的不同DNN模型在不同批次规模下的内存消耗。
-
MEMORY USAGE VS MODEL COMPLEXITY
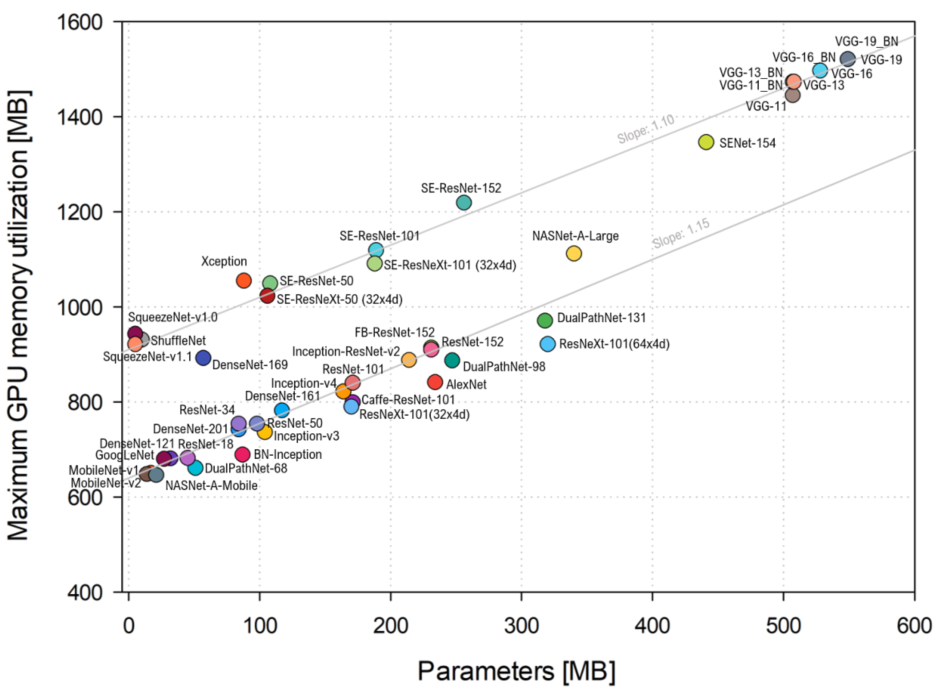
- 在下图中,本文分析了模型参数的初始静态分配(即模型的复杂性)与Titan Xp上批量大小为1的总内存利用率之间的关系。
-

-
图四:在Titan Xp上,模型参数的初始静态分配(即模型的复杂性)和批量大小为1的总内存利用率图。
-
- 可以看到,这种关系是线性的,并且遵循两条不同的直线,斜率大致相同(即1.10和1.15),截距不同(即分别为910和639)。这意味着模型的复杂性可以被用来可靠地估计总的内存利用率。
- 从图中可以观察到,一些模型家族属于同一条线,例如VGGs、SE-ResNets和SqueezeNets位于截距较高的线上,而ResNets、DualPathNets、DenseNets、Inception Nets和MobileNets则位于截距较低的线上。
- 特别是可以观察到复杂度最小的模型(即SqueezeNet-v1.0和SqueezeNet-v1.1都是5MB)有943MB和921MB的内存占用,而复杂度稍高的模型(即MobileNetv1和MobileNet-v2分别有17MB和14MB)有更小的内存占用,分别为650MB和648MB。
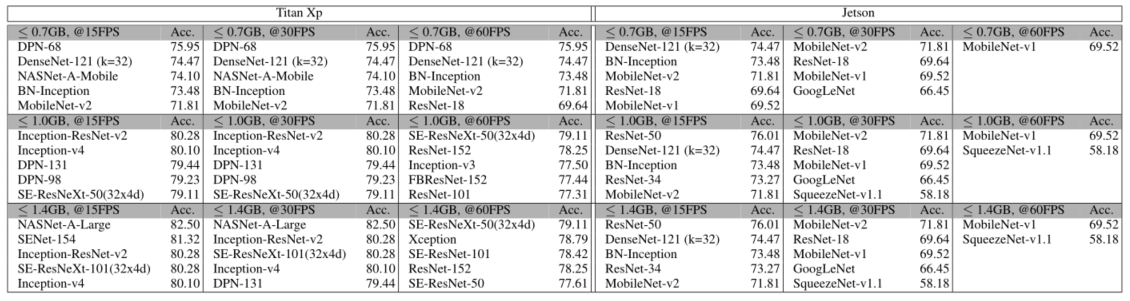
BEST DNN AT GIVEN CONSTRAINTS
-
下表显示了在给定具体硬件资源作为计算限制时,在识别精度方面的最佳DNN架构。
-

-
表三:在Titan Xp(a)和Jetson TX1(b)上满足内存消耗(≤0.7GB,≤1.0GB,≤1.4GB)和推理速度(≥15FPS,≥30FPS,≥60FPS)约束的前5个模型(按Top-1精度递减排序)。
-
-
这一分析是针对Titan Xp和Jetson TX1进行的。本文定义了以下约束条件。
- 内存用量:高(≤1.4GB)、中(≤1.0GB)和低(≤0.7GB)。
- 计算时间:半实时(@15FPS),实时(@30FPS),超实时(@60FPS)
-
Titan Xp在低内存使用率的限制下,通过使用DPN-68网络,实现了最多75.95%的识别精度,这与计算时间无关。拥有更多的资源,例如中等和高内存使用率,Titan Xp通过使用SE-ResNeXt-50(32x4d),以超实时的吞吐量实现了最多79.11%的识别精度。
-
在内存使用方面没有要求,Jetson TX1通过使用MobileNet-v1实现了最多69.52%的识别精度,这保证了超实时的吞吐量。要想让运行在Jetson上的DNN在识别精度上与运行在Titan Xp上的最佳DNN相媲美,至少需要1GB的内存大小。在这种情况下,性能最好的是ResNet-50,能够保证一半的实时吞吐量,识别精度为76.01%。
CONCLUSION
-
深度神经网络(DNN)的设计随着复杂性的增加能够提高ImageNet-1k竞赛的性能,在推动其他视觉任务的最先进水平方面起着核心作用。在这篇文章中,本文对不同的DNN进行了比较,以提供一个直接和全面的工具来指导选择适当的架构,以应对实际部署和应用中的资源限制。
-
具体来说,本文分析了在ImageNet-1k上训练的40多个最先进的DNN架构的准确性、参数数量、内存使用、计算复杂性和推理时间。
-
本文的主要结论如下。
- 识 别 精 度 并 不 随 着 操 作 数 的 增 加 而 增 加 \textcolor{yellow}{识别精度并不随着操作数的增加而增加} 识别精度并不随着操作数的增加而增加:事实上,有一些架构在操作数相对较少的情况下,如SE-ResNeXt-50(32x4d),就能达到非常高的精度。这一发现是独立于所实验的计算机架构的。(见图一a和b)
- 模 型 的 复 杂 性 和 准 确 性 之 间 并 不 存 在 线 性 关 系 \textcolor{pink}{模型的复杂性和准确性之间并不存在线性关系} 模型的复杂性和准确性之间并不存在线性关系。(见图一a和b)
- 并非所有的DNN模型都以相同的效率水平使用其参数。(见图二a和b)
- 所需的吞吐量(例如表示为每秒推断的数量)对可实现的准确性有一个上限。(见图三a和b)
- 模 型 的 复 杂 性 可 以 被 用 来 可 靠 地 估 计 总 的 内 存 利 用 率 \textcolor{purple}{模型的复杂性可以被用来可靠地估计总的内存利用率} 模型的复杂性可以被用来可靠地估计总的内存利用率。(见图四)
- 几乎所有的模型都能够在高端GPU上实现实时或超实时性能,而只有少数模型能够保证在嵌入式系统上实现。(见表一a和b)
- 即使是模型复杂度很低的DNN,其最小的GPU内存占用量也在0.6GB左右。(见表二)
-
所有考虑的DNN以及用于分析的软件都可以在网上找到[CeLuigi/models-comparison.pytorch: Code for the paper Benchmark Analysis of Representative Deep Neural Network Architectures (github.com)]。本文计划在资源库中增加互动图,让其他研究人员更好地探索这项研究的结果,更重要的是毫不费力地增加新的条目。
轻量级网络概述对比,可跳转到实验数据展示,[理工堆堆※](作者:理工堆堆星 https://www.bilibili.com/read/cv8801259 出处:bilibili)
- 常规的CNN推理,由于需要很大的计算量,很难应用在移动端,终端等资源受限的场景中。只有通过复杂的裁剪,量化才有可能勉强部署到移动端。
- 从Squeezenet,MobileNet v1开始,CNN的设计开始关注资源受限场景中的效率问题。经过几年的发展,目前比较成熟的轻量级网络有:google的MobileNet系列,EfficientNet Lite系列,旷世的ShuffleNet系列,华为的GhostNet等。
- MobileNet v1 最大的成就在于提出了depthwise卷积(DW)+pointwise卷积(PW)。
- MobileNet v2借鉴了resnet的残差结构,引入了inverted resdual模块(倒置残差模块),进一步提升了MobileNet的性能。
- DW卷积或者分组卷积虽然能够有效的降低计算量,但是 缺 少 通 道 间 的 信 息 交 互 与 整 合 \textcolor{red}{缺少通道间的信息交互与整合} 缺少通道间的信息交互与整合,势必会影响网络的特征提取能力,MobileNet中使用PW卷积来解决这个问题,但是PW卷积的计算量比较大(相对dw卷积),大约是dw卷积的$ C_{out} / K^2 $倍。假设C_out=128, k=3, 那么pw卷积的计算量是dw卷积的14倍!所以MobileNet的计算量主要集中在point wise卷积上面。ShuffleNet v1使用了一种更加经济的方式,channel shuffe,使得不需要逐点卷积操作,也能实现不同通道间的信息融合。
- ShuffleNet v2从轻量级网络的本质出发,提出不应该只看计算量,而需要同时兼顾MAC(内存访问代价),并提出了4条轻量级网络设计的准则:
- 相等的通道宽度使内存访问成本最小化(memory access cost,MAC)。
- 过量使用组卷积会增加MAC 。
- 网络碎片化会降低并行度。
- 不能忽略元素级操作所带来的计算量。
- GhostNet通过对传统卷积得到的特征图进行观察,发现有很多相似的特征图。那么是否可以通过改造让卷积这种算力消耗大的操作只生成一些具有高度差异性的特征图,然后基于这些特征图,再用一些廉价的操作(相对于卷积,如线性变换)进行变换,得到传统卷积中的那些相似特征图。
















 7386
7386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}