







1 现状
因为遇到了数据不均衡问题,正在重新对数据进行分析以及修改模型。整个框架见 油田生产数据选取问题3
2 数据问题
2.1 统计
| 统计项 | 数量 |
|---|---|
| 时间跨度 | 3425 天 |
| 产液量计量 | 734 天 |
| 未选用产液计量 | 108 天 |
| 包含信息较丰富(在已有规则中且至少满足两项)的备注 | 181 天 |
| 油嘴尺寸变化 | 24 次 |
| 泵频率变化 | 16 次 |
2.2 分布视图
2.2.1 计量与时间
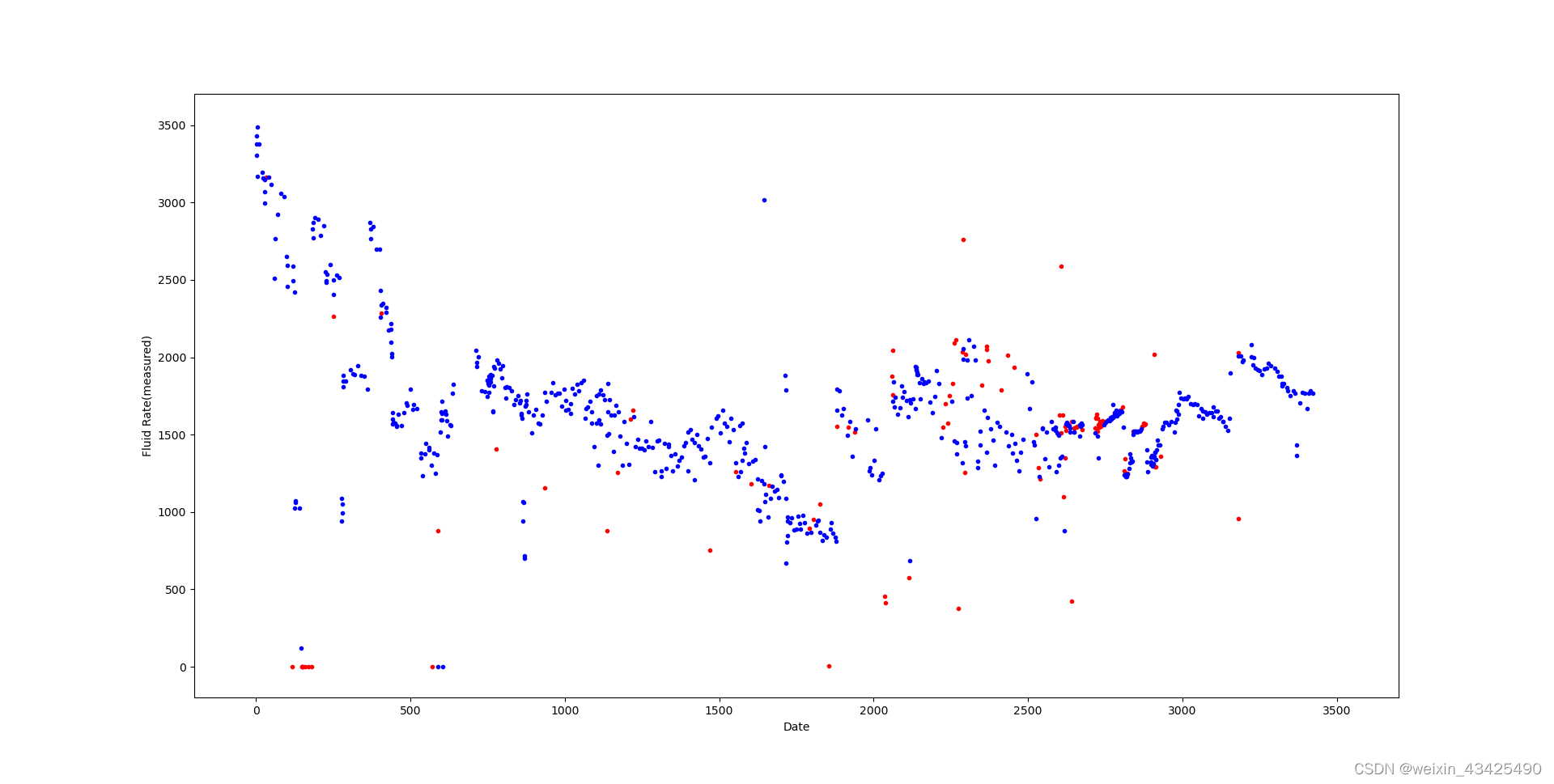
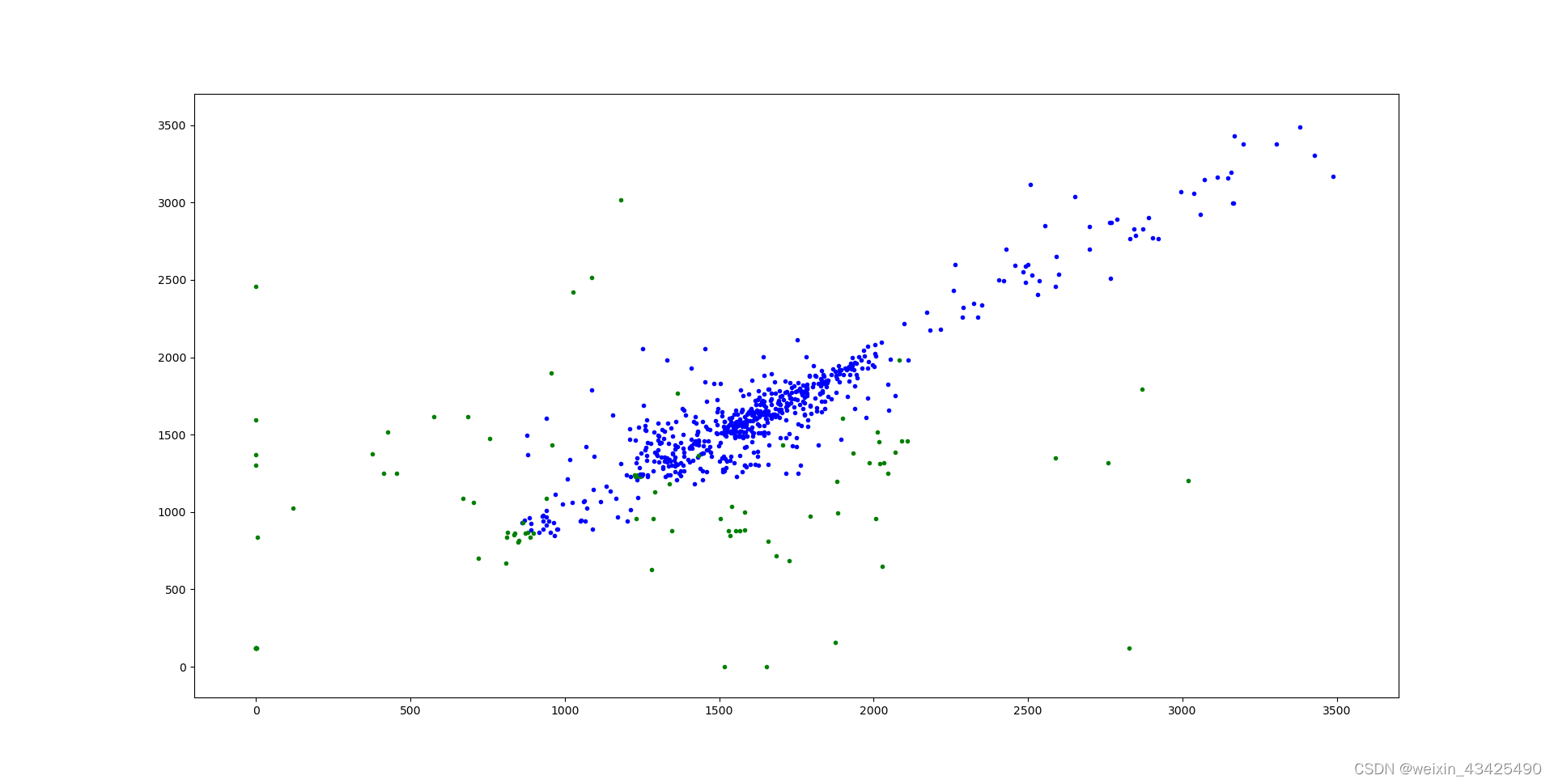
横轴为日期,纵轴为产液量计量值,蓝色点为正类 选用,红色点为负类 未选用。可以看出选用的计量值有一定的时序关系,可能在局部存在一定的线性关系。
局部关系与产量预测比较有意思的论文
(待阅读)
[1] Ada B , Ar A , Im A , et al. Oil production forecast models based on sliding window regression[J]. Journal of Petroleum Science and Engineering, 2020.
2.2.2 计量与选用
为了降低复杂度观察模型训练效果,采用了最笨的方法,减少数据的维度,选取对影响最大的产液量计量值与选用值,时间。
产液量波动的规则为使用频率最高的规则,绘图观察计量值与选用值的数据分布。
本行以下的所有散点图,
横轴为 当前数据项 计量值,纵轴为 前一数据项 选用值。

负类的分布确实不容易看出。中间部分负类数据有问题,其信息不充分,虽然按照规则可选用,但是未选用。
2.3 总结
模型表现不佳的原因可能来自于数据采集过程(如噪声,缺失值)、或者来自于数据集的特性(如类别重叠,庞大的数据规模)、也可能来自于采用的机器学习模型的特性(如模型容量过小/过大)和任务本身(如类别分布不平衡)
目前数据集有以下问题:
1)未选用的负类数据太少。
2)数据所包含的信息不够丰富。比如油嘴尺寸变化、泵频率变化情况太少。
3)低质量数据。原数据的部分数据可以采用,但是被分为负类。
…
2.4 考虑方法
考虑了基本的过采样与欠采样k邻近算法,但是仅仅在原本数据的基础上修改不足以丰富数据集的信息。从分布来说 k邻近 也会影响正类的分布。考虑了对负类样本增加loss的权重,但对提升负类的查准率与查全率的效果不明显。
(待阅读)
极端类别不平衡数据下的分类问题
[1] Liu Z , Cao W , Gao Z , et al. Self-paced Ensemble for Highly Imbalanced Massive Data Classification[J]. 2019.
从梯度的角度出发来解决样本不均衡的问题
[2] Li B , Liu Y , Wang X . Gradient Harmonized Single-Stage Detector[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33:8577-8584.
3 数据生成方法
根据规则,生成数据项,目的是解决数据不均衡,信息不丰富的问题。因为有规则的存在,所以代价比较小。
产液量:
主要依靠产液量波动规则。假设计量值(measuring)服从正态分布,以当天选用值为均值。方差暂时手动设置。
同时与油嘴尺寸、泵频率成线性正相关,(动态调整对产量影响有延迟性)。系数手动设置。
含水率:
主要依靠含水率波动规则。假设采样值(sampling)服从正态分布,以当天选用值为均值。方差暂时手动设置。
油压与温度非强相关,未纳入考虑。
对于如何获取以上提到的系数和方差,除手动以外,可能的方法:
根据数据做统计,计算方差、系数?对于产液量,虽然假设计量值服从正态分布,但是在不同的产液量水准上,方差可能都不同,且每次只有一个计量值。可先按照规则分为两部分,以 1000 产液量作为统计的划分。含水率同理。
获取产液量方差公式如下:
| 符号 | 意义 |
|---|---|
| f r n {fr}_n frn | 第 n 项数据产液量计量值 |
| f r ‾ n \overline {fr}_n frn | 第 n 项数据选用产液量 |
| f r ^ n \hat {fr}_{n} fr^n | 第 n 项数据推导选用产液量 |
| C n C_n Cn | 第 n 项数据油嘴尺寸 |
| F r e n Fre_n Fren | 第 n 项数据泵频率 |
| w c w_c wc | 油嘴尺寸影响系数 |
| w f w_f wf | 泵频率影响系数 |
产液量大部分情况下依靠前一项数据选用值,仅对最近一次控制修改做出变化。生成带控制变化的数据:
f
r
n
^
=
{
f
r
‾
n
−
1
+
w
c
(
C
n
−
1
−
C
n
−
2
)
2
+
w
f
(
F
r
e
n
−
1
−
F
r
e
n
−
2
)
0
,
"
w
e
l
l
s
h
u
t
i
n
"
i
n
k
e
y
w
o
r
d
s
(1)
\hat{fr_n} = \left\{ \begin{aligned} &\overline{fr}_{n-1} + w_c (C_{n - 1} - C_{n - 2})^2 + w_f(Fre_{n - 1} - Fre_{n - 2}) &\\ &0, \mathrm {"well\ shut\ in"\ in\ keywords}\\ \end{aligned} \right.\tag{1}
frn^={frn−1+wc(Cn−1−Cn−2)2+wf(Fren−1−Fren−2)0,"well shut in" in keywords(1)
实际判断时(是否会出现fre、choke同时调整但是一正一负的情况?),则只需要判断
w
c
,
w
f
w_c, w_f
wc,wf 的正负。
对方差的获取方式仍有问题。
假设计量当天存在
m
m
m 次计量,计量集合为
M
n
\mathbf {M_n}
Mn,
m
f
r
i
∈
M
n
,
1
≤
i
≤
m
mfr_i \in \mathbf {M_n}, 1\le i \le m
mfri∈Mn,1≤i≤m:
M
n
∼
N
(
f
r
‾
n
,
σ
n
2
)
\mathbf {M_n} \sim{N(\overline {fr}_{n}, \sigma_n ^2)}
Mn∼N(frn,σn2)
σ n 2 = { ∑ f r ‾ i − 1 < 1000 ( f r i − f r ‾ i − 1 ) 2 m 1 , f r ‾ i − 1 < 1000 ∑ f r ‾ i − 1 ≥ 1000 ( f r i − f r ‾ i − 1 ) 2 m 2 , f r ‾ i − 1 ≥ 1000 (2) \sigma_n ^2 = \left\{ \begin{aligned} &\frac {\sum_{\overline {fr}_{i-1} < 1000} (fr_i - \overline {fr}_{i-1})^2}{m_1}, &\overline {fr}_{i-1} <1000\\ &\frac {\sum_{\overline {fr}_{i-1} \ge 1000} (fr_i - \overline {fr}_{i-1})^2}{m_2}, &\overline {fr}_{i-1} \ge 1000\\ \end{aligned} \right.\tag{2} σn2=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧m1∑fri−1<1000(fri−fri−1)2,m2∑fri−1≥1000(fri−fri−1)2,fri−1<1000fri−1≥1000(2)
其中:
m
1
+
m
2
=
m
m_1 + m_2 = m
m1+m2=m
这样的方法就类似状态转移方程,但是每次生成数据的出发点都是现有真实数据。可参考之前在论文中见到的卡尔曼滤波。
4 模型
模型
网络:ANN 人工神经网络
损失函数:CrossEntropy 交叉熵
优化器:SGD 梯度下降
5 实验
5.1 生成数据

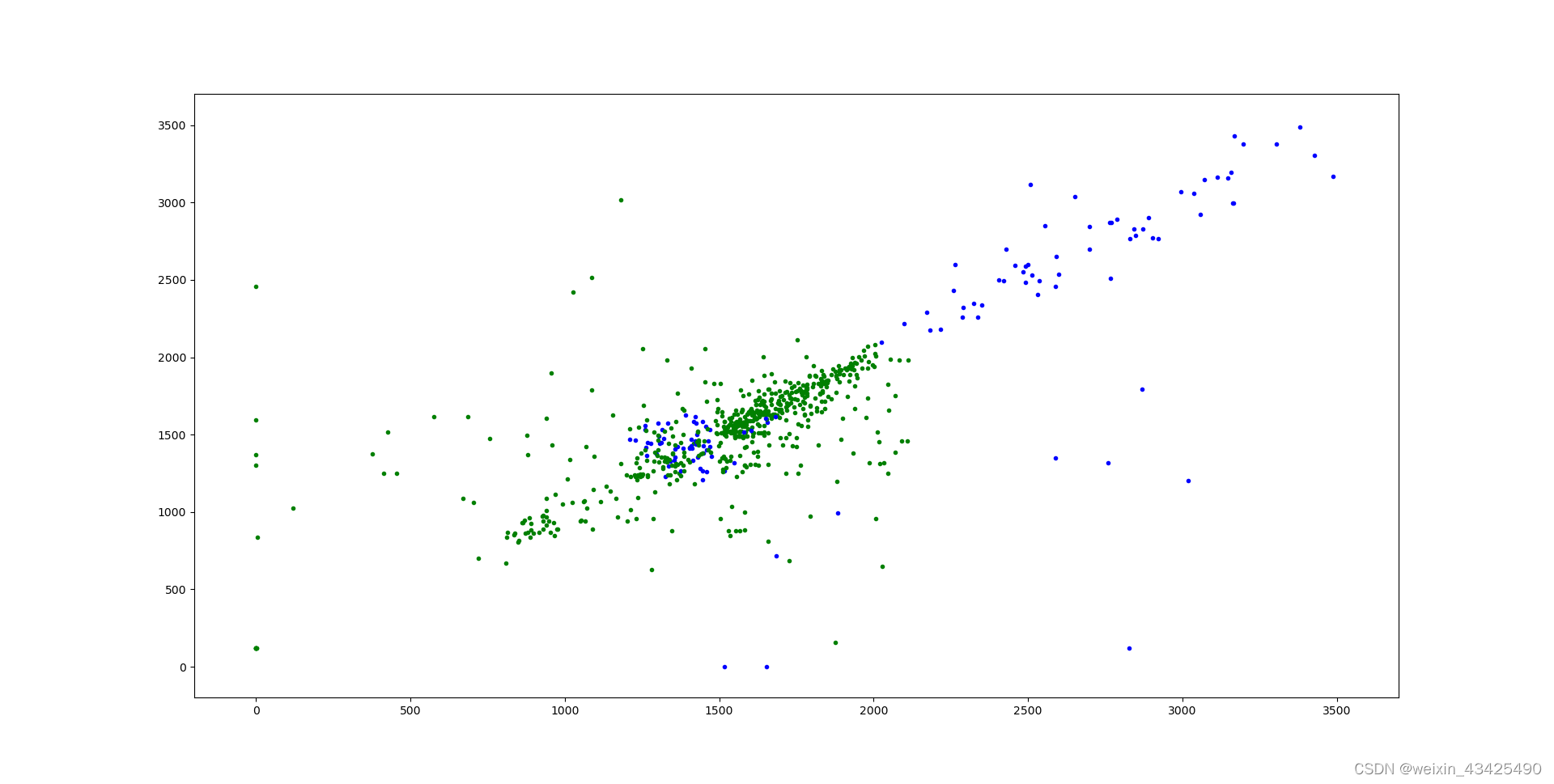
绿色的点为按照规则生成的负类数据。
5.2 拟合效果
为了降低建立模型、数据分析的难度,目前只选取了时间、产液量计量值、产液量选用值来做训练。
只完成了训练集上的训练与测试。运气好的话…在训练集的结果分布上来说还可以入眼。模型在训练集的效果稳定且良好时,加入测试集(在训练集上稳定且良好时),新的维度(在训练集上效果稳定,但是差)。
以下是学习后,在训练集中的分类效果指标,以及分类的分布:
| 训练轮次 | 正确率 | 负类查准率 | 负类查全率 | 损失 |
|---|---|---|---|---|
| 6 | 77.38% | 32.10% | 48.15% | 0.5609 |
| 11 | 81.20% | 37.70% | 42.59% | 0.5554 |
| 16 | 82.15% | 38.61% | 36.11% | 0.5613 |
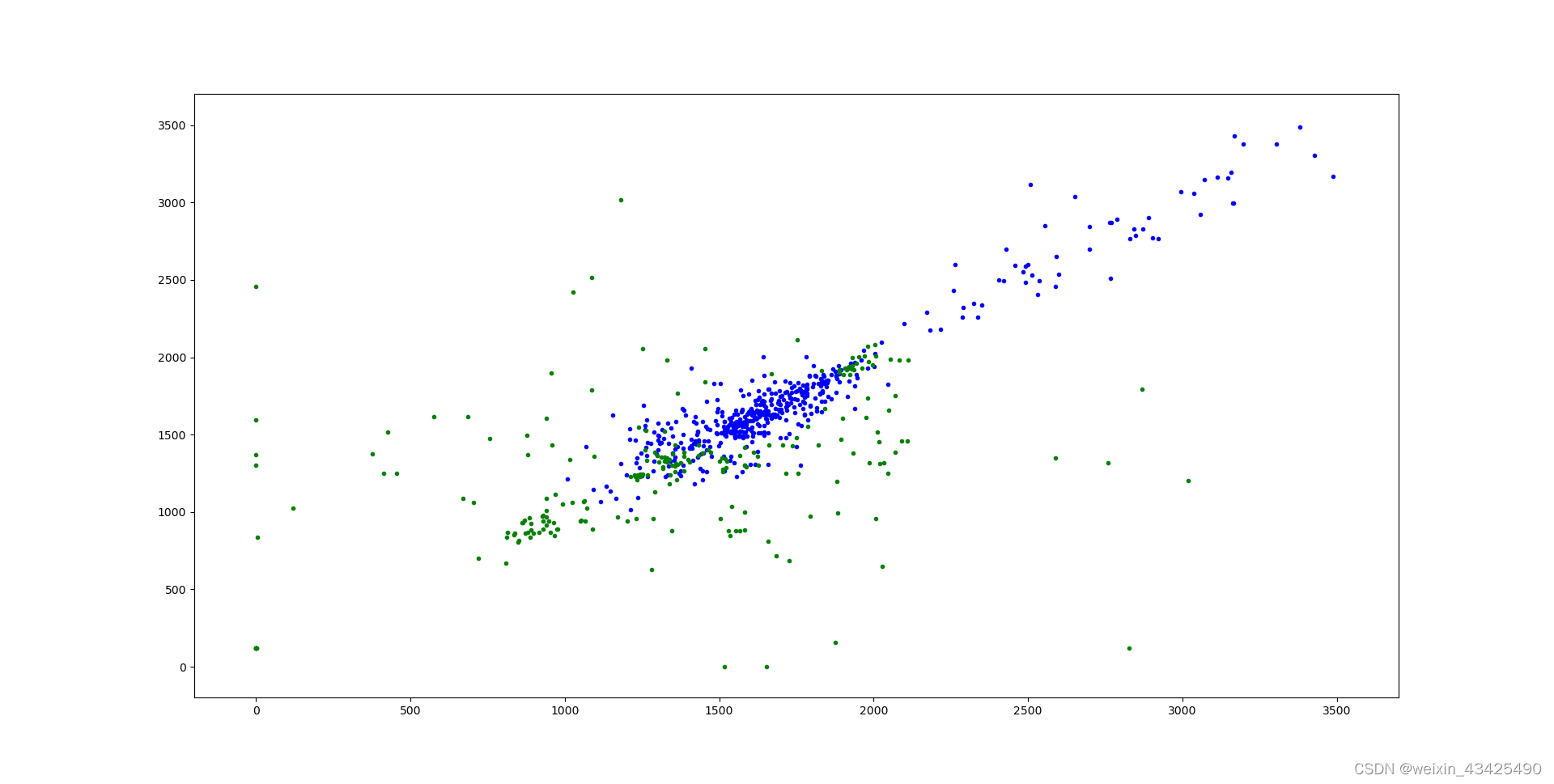 第6轮训练 第6轮训练
|
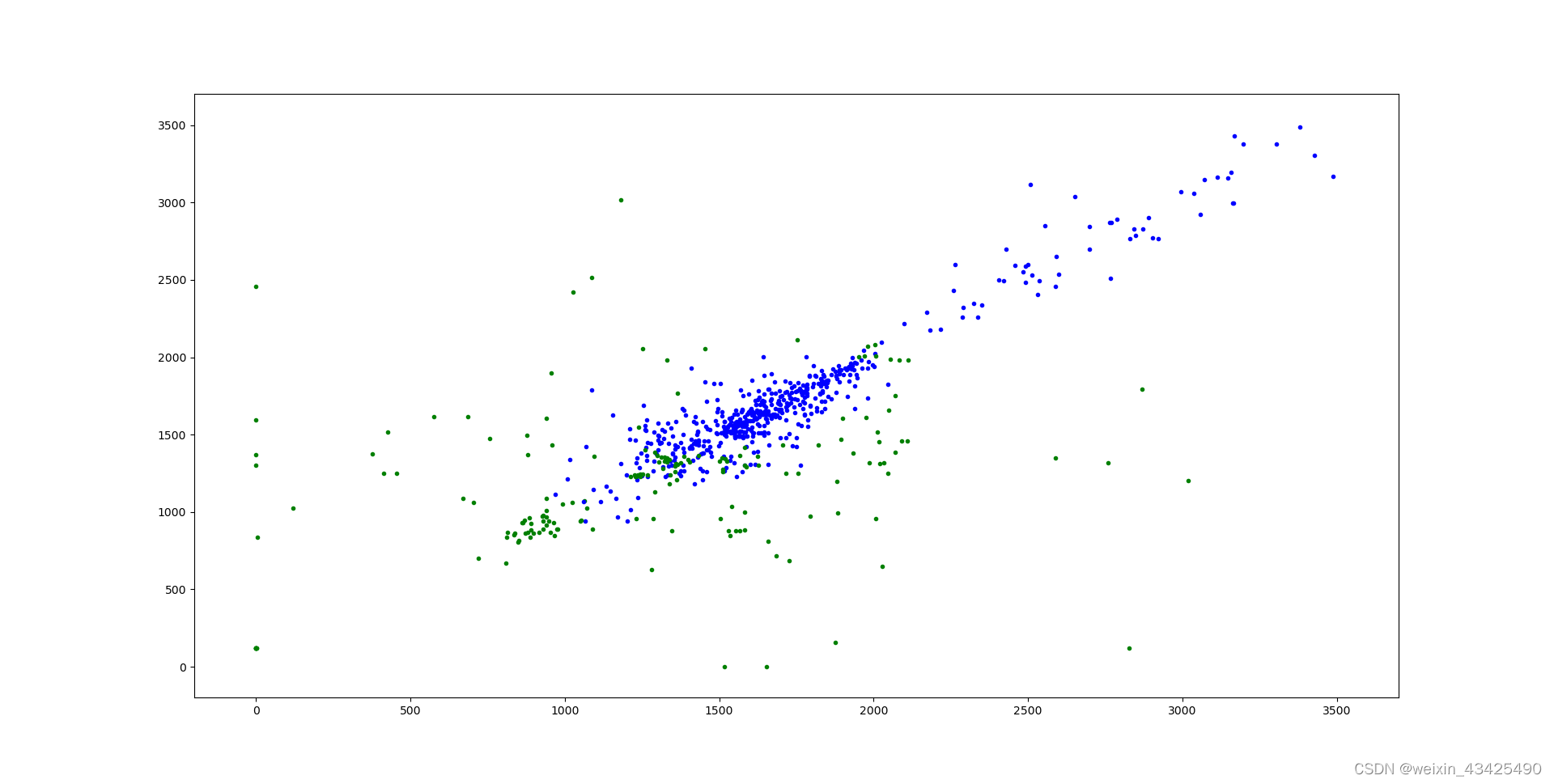 第11轮训练 第11轮训练
|
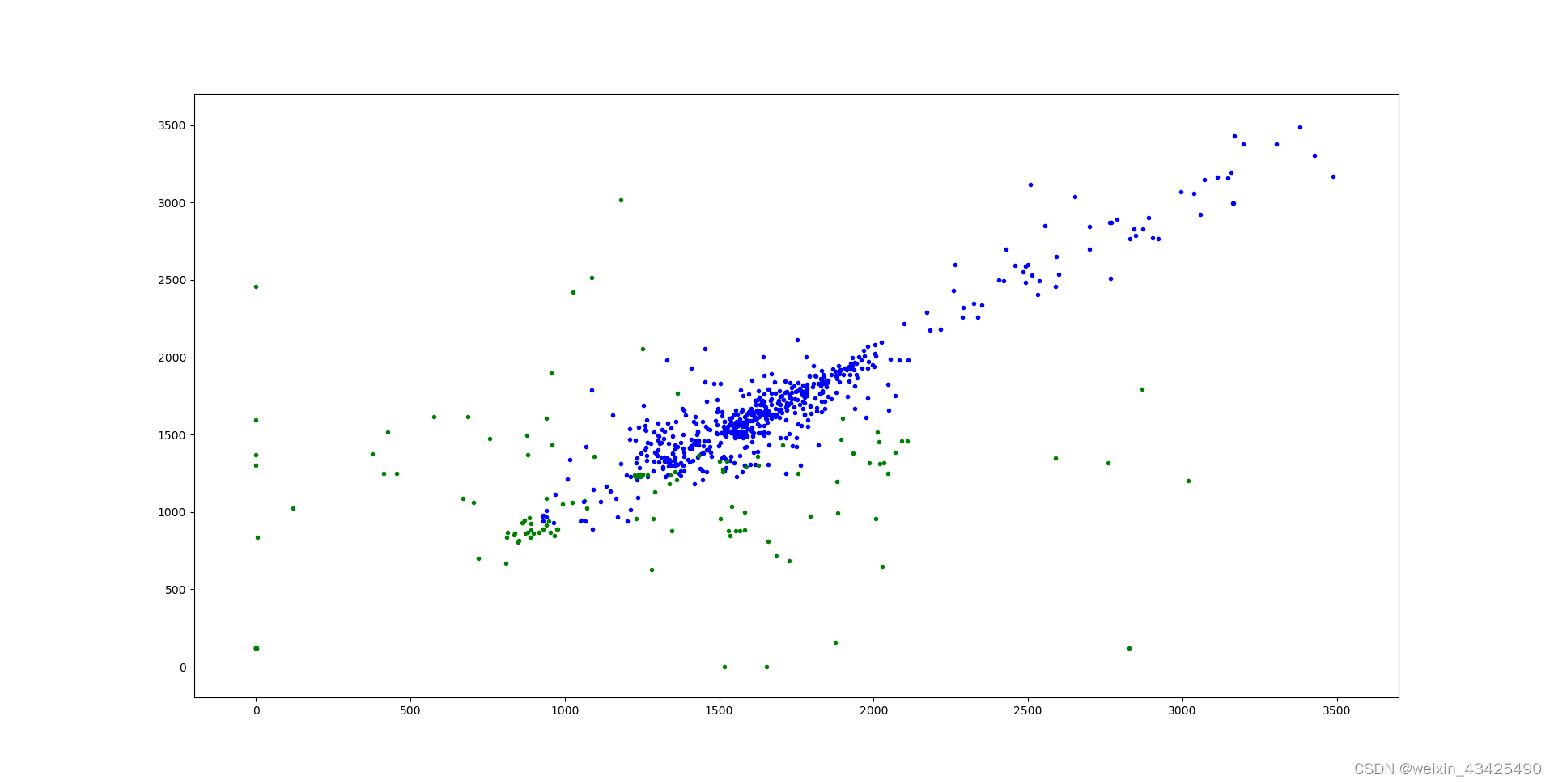 第16轮训练 第16轮训练
|
 第21轮训练 第21轮训练
|
训练越往后,虽然 loss 趋于稳定,但是对负类的划分效果则越差,查准虽然提高,但查全降低明显。
更清晰的图像见 附录。
5.3 模型评价
我个人期望是当前模型能正确将超出波动范围的数据划分出来。但模型目前对数据拟合能力差,少数情况下能学习到数据的大概分布。
6 评价指标
F1-score
F2-score
待定,可设计特定的评价指标,比如认为对负类的正确划分更重要,按正负类占比,加入非线性函数以划分权重。
附录
老板的笔记
-
现有问题
1.1 数据不均衡.
正、负样本比例.
1.2 数据不丰富.
不同的情况,不同的取值.
1.3 因果不够明确.
用数据本身不容易直接判断类别 (是否选用).
1.4 噪音数据.
错误标注 1: 不该选用的选用了.
1.5 未选用的原因不明.
错误标注 2: 该选用的没用.
1.6 预测的时候仅根据网络
样本复杂度 -
解决方案
2.1 过采样、欠采样
2.2 根据规则自动生成
2.3 规则的可信度究竟有多大?
2.4 去噪, 最好是人机交互干预, 可以极大地提升数据的可用性
把异常点挑出来. 这是我们的优势.
2.5 未选用可以当作缺值 (暂不考虑)
参见推荐系统的隐式反馈
未选用有可能是数据质量不合格,也可能是其它的原因如前后已经有些选用了
2.6 根据规则生成大量的数据 (10^5)
越复杂的模型, 越高的精度要求, 需要的训练样本越多. PAC 理论.
如果样本不够多, 还不如规则集合准确率高. 需要做比较: 规则集与网络.
目标依次是: 超过规则集、超过人类.
假设:规则的可信度高、已有标签的质量好、因果关系稳定,那么就容易获得好的预测模型。















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









