






导读
本期将实现用Python进行豆瓣图片的爬取,并用软件快速生成马赛克拼图。
软件获取方式:微信公众号后台回复:千图成像
微信公众号:

简介
千图成像即马赛克拼图。马赛克拼图主要运用于抽象艺术图像的表达,利用图片像素的原理,将图像的每个色彩点,用不同的马赛克原石(图片)拼贴出来。


本系列教程
Part1:Python实现图片爬取+软件快速体验马赛克拼图
part2:马赛克拼图实现原理+代码实现
part3:如何实现多样式的马赛克拼图
照片爬取
#请求头信息与链接
headers = { 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36" }
url = 'https://movie.douban.com/celebrity/1048000/photos/?type=C&start=' + str(page * 30) + '&sortby=like&size=a&subtype=a'# -*- utf-8 -*-
import os
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
def GetHtmlText(url):
try:
r = requests.get(url, headers=headers)
#print(url)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def main(pages):
FilePath = os.getcwd() + '\jay\\'
if not os.path.exists(FilePath):
os.makedirs(FilePath)
TempPage = pages
FileNum = 1
for page in range(pages):
url = 'https://movie.douban.com/celebrity/1048000/photos/?type=C&start=' + str(page * 30) + '&sortby=like&size=a&subtype=a'
html = GetHtmlText(url)
soup = BeautifulSoup(html, 'html.parser')
#print(str(page * 30))
uls = soup.find_all('ul', {"class": "poster-col3 clearfix"})
print(html)
for ul in uls:
imgs = ul.find_all('img')
for img in imgs:
imgurl = img['src']
imgcontent = requests.get(imgurl).content
filename = str(FileNum) + '.jpg'
with open(os.getcwd() + '/jay/' + filename, 'wb') as wf:
wf.write(imgcontent)
FileNum += 1
if __name__ == '__main__':
main(10)
运行结果如下。值得一说的是,在进行爬取时默认保存的图片格式为jpg,而豆瓣图片储存格式并非完全为jpg格式,所以会出现部分图片无法读取与查看。但并不影响后续的操作。
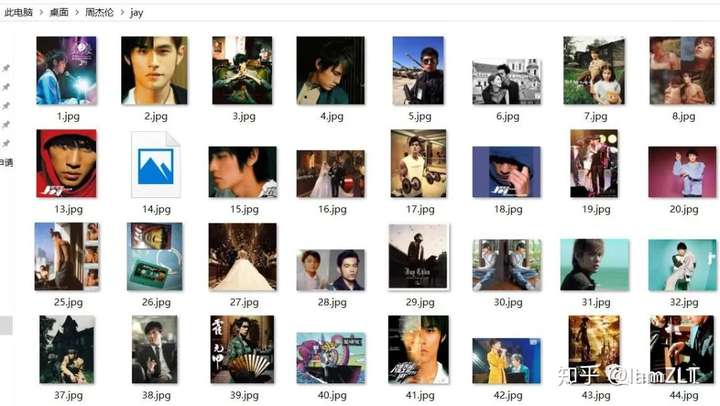
软件生成马赛克拼图
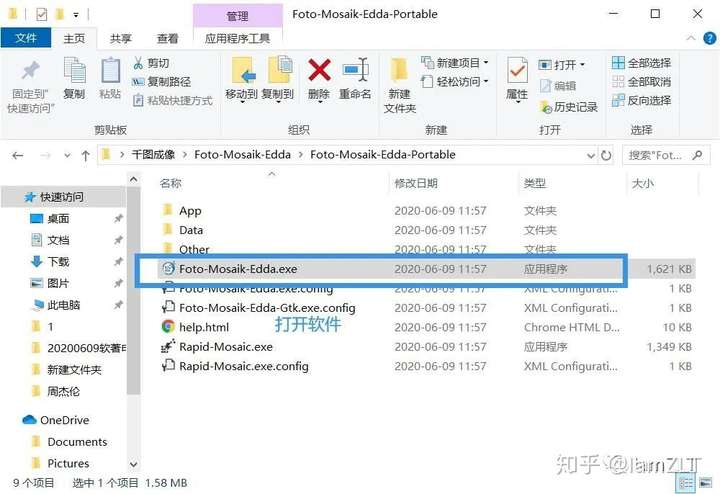
Foto-Mosaik-Edda是一个简单易用的向导程序,软件大小为1.47MB,用户可以使用它自己的照片,轻松的创建出由很多张图片组成的马赛克拼图
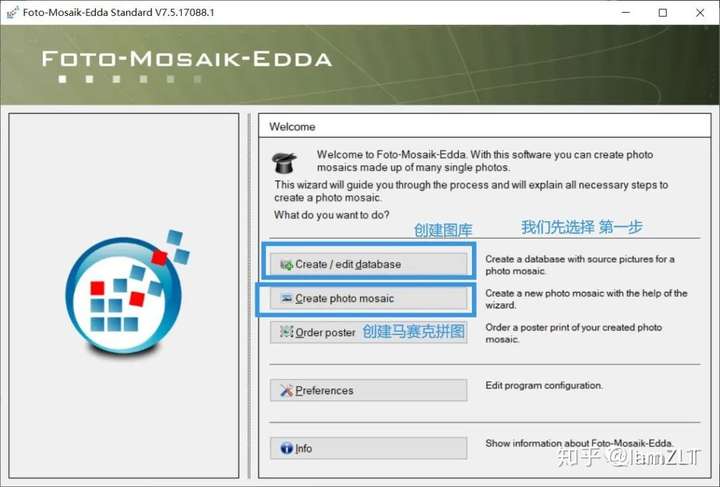
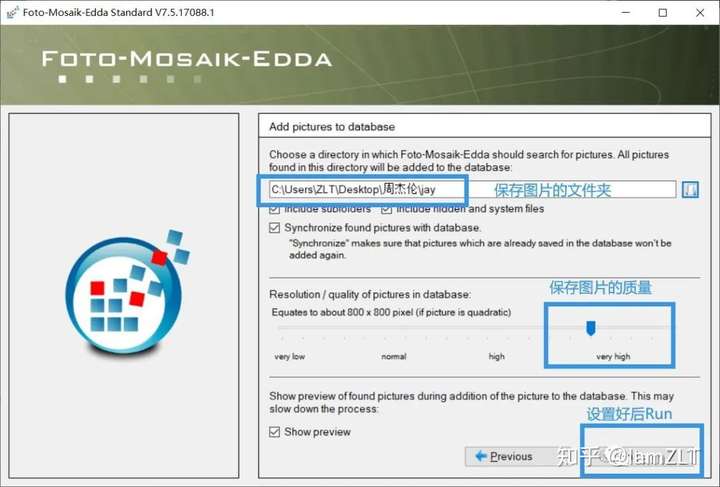
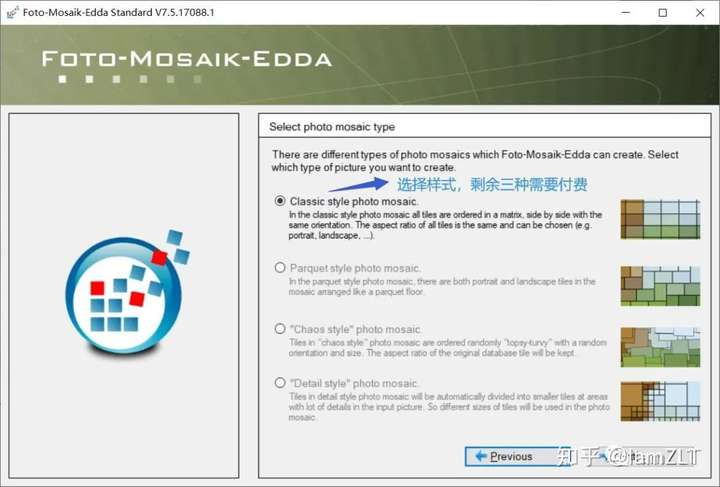
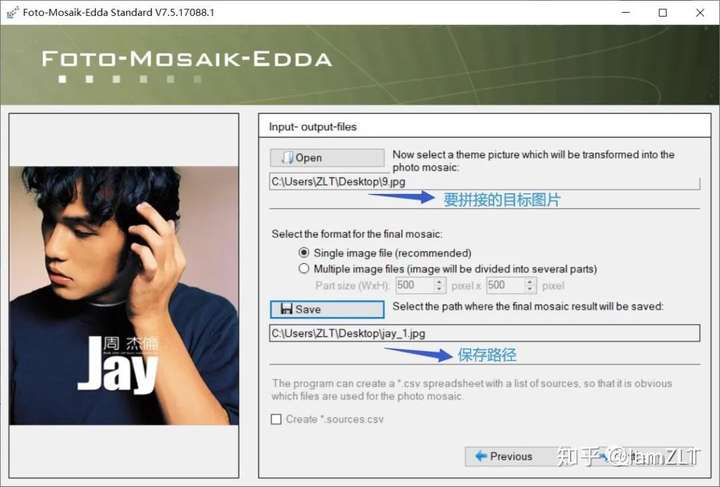
1.创建图库
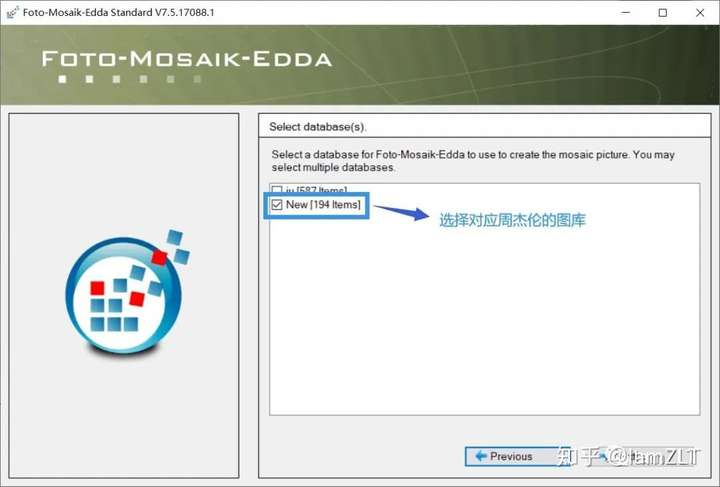
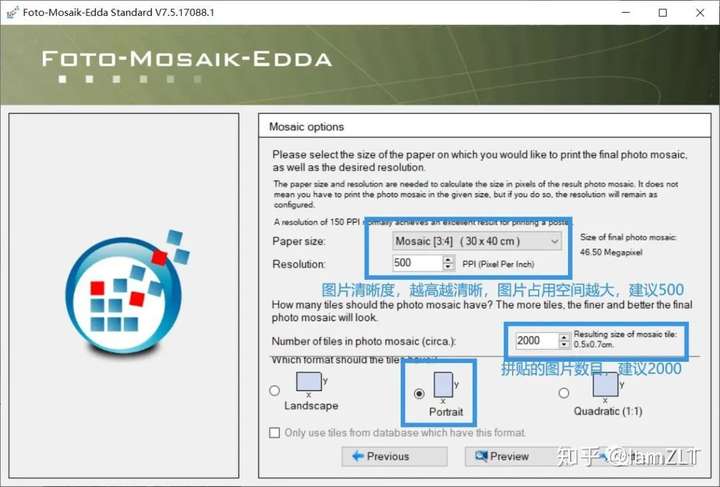
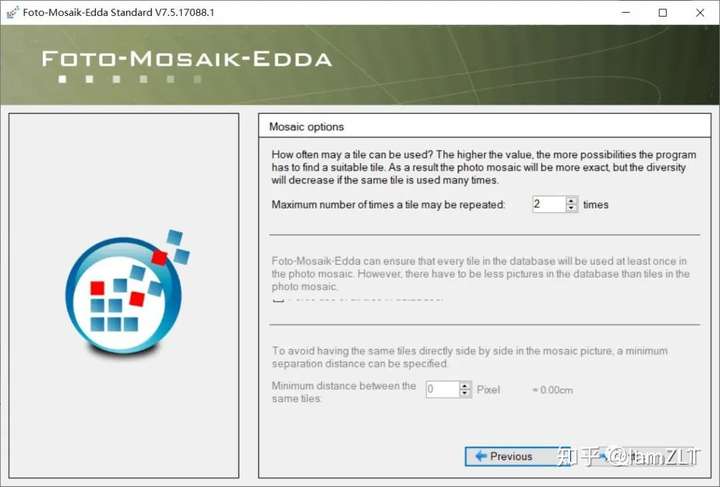
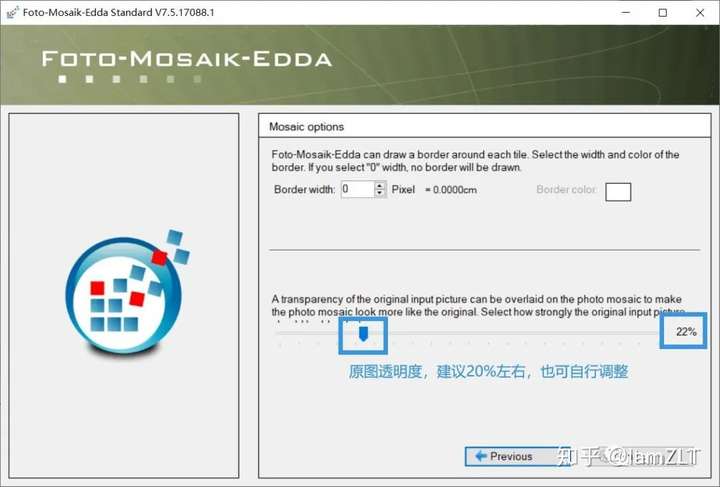
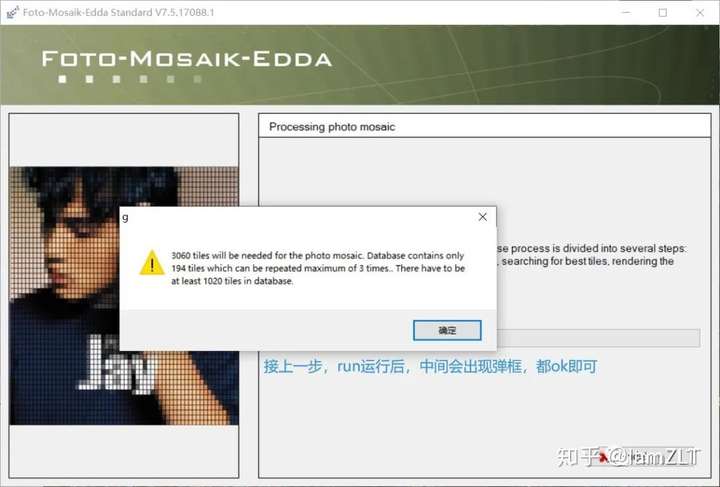
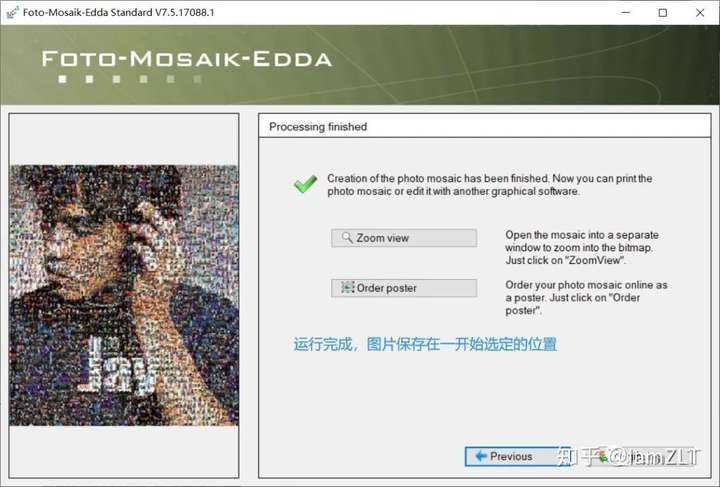
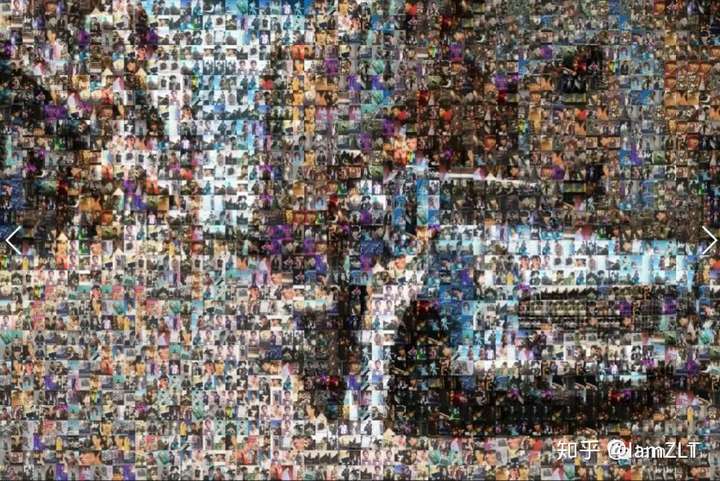


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









