






导读
如果想要自己做一套字体,无论是电脑软件FontCreator还是网站flexifont都为我们带来了极大的便利。

但是最低的国标字体数量近7000个,若采用传统的方法则需要手写相同数量的汉字,这个过程费时耗力。那有没有办法可以快速生成自己的手写字体?本文将介绍开源项目zi2zi,只需要你的部分手写字体样本便可生成完整字库。教你用深度学习的方式打开制作手写字体的大门。
本系列文章Part1:导读与相关介绍part2:程序化或将与手写模拟器擦出火花
zi2zi
zi2zi是作者Rewrite项目的后续工作,其为处理类似中文字体转化的问题。Rewrite项目获得了相当多的关注和兴趣,但是项目结果不佳。仍然存在一些严重的问题:
-
生成的图像通常是模糊的
-
无法使用更多风格的字体
-
限于一次仅学习和输出一种目标字体样式
为了解决上述问题,zi2zi诞生了。本项目的论文中是将之前的三篇paper合在一起又加入了作者的构想形成的一个条件生成对抗网络。

zi2zi模型和其名字一样,来源于pix2pix模型并有所改进。其网络结构如下:
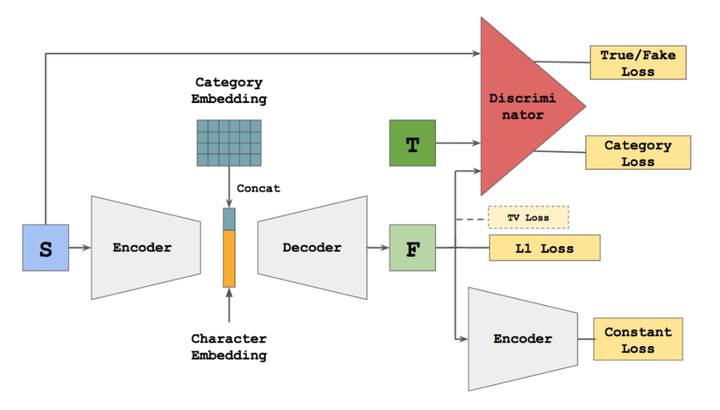
我们可以知道,现实世界中的设计师需要经过多年的培训,起码了解字母/字符的结构和基本原理才能自行设计字体。基于此,其重要的是使模型不仅意识到自己的样式,而且也能意识到其他字体的样式。因此,使模型能够同时学习多种字体样式是极为重要的。同时对多种样式建模有两个主要好处:
-
编码器能接触更多字符,不仅仅限于目标字体,也包括所有组合的字体;
-
解码器还可以学习从其他字体写相同的部首的不同方法。
通过一起训练多个字体,它可以强制模型从每个字体中学习,然后利用所学的经验来改善其他字体。

现在有一问题是同一个汉字会出现在多种字体当中。作者受《谷歌的多语言神经机器翻译系统》的启发,想出了「类别嵌入」,将不可训练的高斯噪声作为风格嵌入与汉字嵌入串联起来,之后再一并进入解码器。这样,解码器仍旧将同一个汉字映射为同一个向量,但是,解码器会同时考虑汉字和风格两个嵌入来生成目标汉字。
有了类别嵌入,现在就有了一个能够同时处理多种风格的GAN。但作者发现又出现了一个新的问题:模型开始将各种风格弄混淆并且混合在一起,生成的汉字什么也不像了。于是,他又借鉴了 AC-GAN模型中的 multi-class category loss,把这个 loss 加到判别器上,一旦出现混淆或者风格混合,就“惩罚”判别器。

上图为zi2zi 生成中文字体的实际效果。共有5列,左边是源字符,右边是系统自动生成的。可以看到,生成的汉字不会“花”,对于某些字来说,系统生成的和真实文字几乎一样。同时也能处理更多样、更复杂的字体风格。
此外,通过具有连续的嵌入,我们可以在不同样式之间进行插值,并得到介于两个字体之间的状态:

下面是多对字体之间过渡的动画,这些演示了在更动态的上下文中的插值过程:

使用方法
运行环境可参考链接内给出的条件。
Github:github.com/kaonashi-tyc/zi2zi/
软件地址:「IamZLT」开发中
为了避免IO瓶颈,必须进行预处理,以将数据转化为二进制数据并在训练期间保留在内存中。首先运行以下命令将字体文件转化为数据集:
python font2img.py --src_font=src.ttf
--dst_font=tgt.otf
--charset=CN
--sample_count=1000
--sample_dir=dir
--label=0
--filter=1
--shuffle=1
之后会生成一一对照的图片,其中左边为希望系统生成的目标字体,右边为系统参照字体,可以使用网上字体较全的字体库。

如果你的目标字体没有ttf格式文件的话,也可以使用图片编辑软件来拼接图片,以达到以上的效果。然后通过以下命令进行封装,转换为二进制格式。
python font2img.py --src_font=src.ttf
--dst_font=tgt.otf
--charset=CN
--sample_count=1000
--sample_dir=dir
--label=0
--filter=1
--shuffle=1
运行此命令后,将在save_dir下找到两个对象train.obj和val.obj,分别用于训练和验证。然后便可以开始训练。需运行以下命令:
>python train.py --experiment_dir=experiment
--experiment_id=0
--batch_size=16
--lr=0.001
--epoch=40
--sample_steps=50
--schedule=20
--L1_penalty=100
--Lconst_penalty=15
经过长时间训练,最后会生成矢量SVG文件,导入FontCreator等软件中便可生成自己的字库。


















 2533
2533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









