







在系统里面,权限的设计是一个非常重要的概念,最典型的就是开发者权限和管理员权限,还有普通客户管理员权限就需要分离。这样开发者在开发某个功能的时候,不至于让使用者误点或者迷惑。
在没有形成定势的权限设计概念之前。回想我们自己设计一个简单的图书管理权限。图书管理员可以新增/修改/查阅/删除图书,而读者只能查阅图书信息。我们最简单的设计思路就是,每次我们获取到管理员的UID,我们就允许做全部操作,不是读者就只能查看图书信息。这样不需要任何权限表,就完成了我们最简单的目标。在这种简单的模式下,我们是不需要做任何权限表设计的。
然后增加一个复杂一点的情况,图书馆扩大,又来了俩个图书管理员,他们也要录入书籍信息,所以这个时候,又要分配给他们俩个账号,如果到代码里面,uid的判断就变成了需要判断uid是不是归属于那三个uid,否则就能进行开发。这种情况,我们仍然不需要引入复杂的权限,在代码进行简单的用户判断,只是这样,会导致我们需要去修改代码,在早期简单的能用就行系统里面,就是这样考虑不周全。
但是新来了一个馆长,他觉得每个管理员都只能管理归属他们自己的图书,而且馆长拥有最高权限,能管理他们三个人,同时可能图书馆还要再增加三个管理员还有N个副管理员,而副管理员只能修改图书信息,不能删除。这个时候,会发现这次的变动很大,如果按照之前思考方法,很棘手,你要不断的写if/else来判断登录的uid身份。这个时候,你为了不频繁改代码,决定新增一个除了用户表之外的表,就是用户权限表,每次新增一个用户的时候,将其uid写入到权限表里面去,你对每个新增的user用户,都绑定了一个简单的权限操作CURD里面的一个,只要读取到数据表里面他有这个权限,就放行,能进行对应操作。这样你就不用再频繁的去代码里面写if/else 只需要让代码读取权限表然后做逻辑判断即可。这是你新增的第二张数据表权限表。
然后图书馆规模继续扩大,工种也越来越多,有管理杂志的/有报刊的/有书籍的/有电子网络的,而且每个工种都有十几个人,还有好几个分馆,然后还有这些人的权限不停的在变化,有的离职,有的调岗。这个时候,你会发现,你要花费巨量的时间,来维护你的user_rule数据表,不停的给他们删权限加权限,可能上百号人,每天都有权限的变动。于是这个时候,你考虑到新增一个专门的权限组来隔离用户与权限的直接接触,这样用户调岗/离职/新增 你只需要将用户分配到对应的组别即可。这就是RBAC的优势。从这里可以看出,RBAC非常适合动态复杂的用户信息频繁更动的管理。
Web领域里面,所有入门的基础都是理解RBAC,所有的订单,都可以建立在某个admin框架上进行二次开发完成。掌握RBAC是理解所有项目的基础,掌握之后,有三个巨大的用处——1.理解主流后台管理的逻辑关系链 2.理解树递归的实战概念3.设计会员类似系统有巨大的参考作用。
RBAC权限的设计主要好处:
RBAC模型通过角色将用户和权限解耦,简化了权限管理。
角色可以灵活地分配给多个用户,便于权限的统一管理和调整。
通过角色继承,可以创建具有不同权限级别的角色层次结构
开始设计定义RBAC相关设计基础表,这里只是实现权限逻辑,在真实的业务代码层面需要考虑到风控,用户详细信息,权限组相关备注等
首先我们需要定义一张user的用户信息基础表,当然如果你是开发后台,可以定义其为admin数据表。一般主要由
id ID编号
name 登录用户名
nickname 昵称
passwd 密码
create_time 创建时间
基础信息,主要就是记录用户的基础信息。然后再建立一张组别信息数据表,分组表的设计是每个权限所属的组别。
Group 表 我们可以定义任意个组,其中组是可以用上一级
id ID编号
pid 所属组别,如果是最大的组,对应的是0
Pname 每组别的名字
Rules 每个组别储存好的权限。
我们在用户表和权限表之间额外新增了一个组别权限表。其中pid是其上级的id,这样我们可以构建一个N级菜单之类的权限表。而再用一张group_access数据表关联user表和group数据表即可。
Uid
Group_id
当用户登录之后,我们读取group_access数据表,获取用户所在的组别,然后根据用户的全部组别,分别从rules表里面读取到全部的权限,访问对应的路由的时候,直接通过rules权限检测,如果检测到权限存在,就正常访问,否则不给正常访问。
然后我们再设计一个rules数据表:
id ID
Pid 父权限
Aname 权限节点名字
Allow_auth 允许的权限路由
这样就完成了一个最基础的RBAC权限数据表设计,通过组别与权限关联,再通过组别与用户关联,完成了一个用户精细化控制任意权限的搭配。这个在之前的设计里面,user和rules,user_rule三张表情况下,是实现的非常麻烦,在未使用RBAC的系统中,控制权限通过额外的权限表,也就是每次读取用户是不是拥有某个权限,拥有就直接通过,没有就表示未通过,在系统比较小的时候,问题不大,但是当系统用户多了很多之后,而且很多同级角色,会发现user_rule会有大量的权限冗余,于是额外增加了一张组别表,这样当某个角色拥有N个角色的时候,其实只要增加user表即可,每次将对应的user数据指向对应的group组别。
流程访问的实现:(用户权限的检查,每次用户访问对应的链接,都通过权限检测公共方法。)
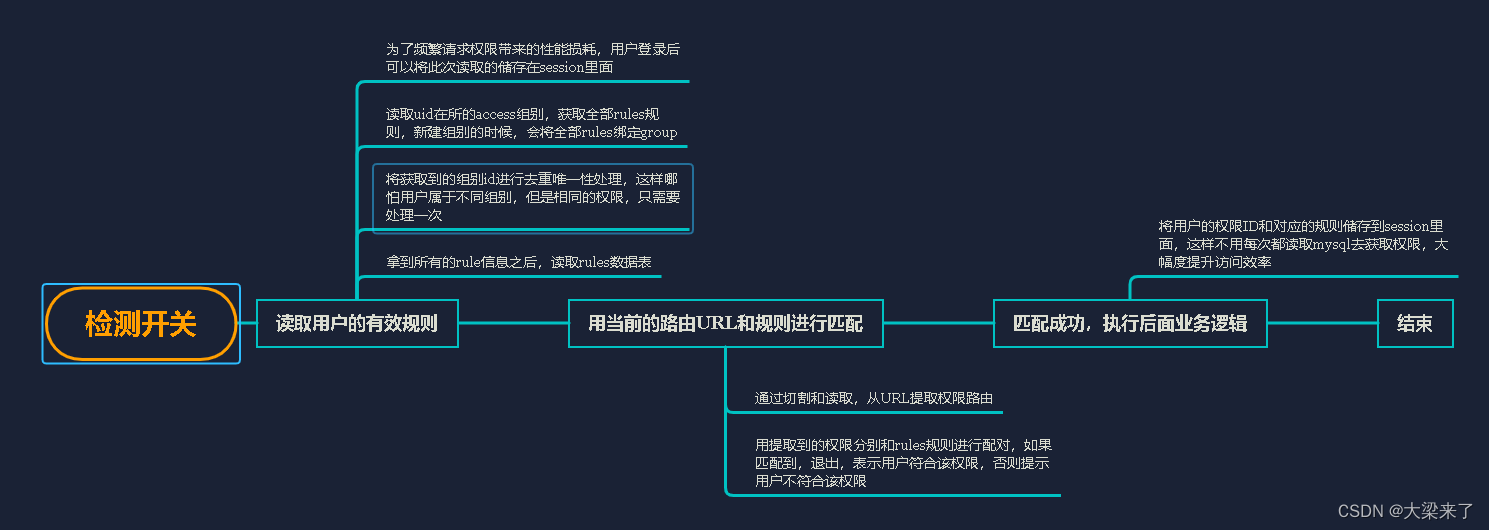
大纲文字版本说明:
读取用户的有效规则
读取uid在所的access组别,获取全部rules规则,新建组别的时候,会将全部rules绑定group
将获取到的组别id进行去重唯一性处理,这样哪怕用户属于不同组别,但是相同的权限,只需要处理一次
拿到所有的rule信息之后,读取rules数据表
用当前的路由URL和规则进行匹配
通过切割和读取,从URL提取权限路由
用提取到的权限分别和rules规则进行配对,如果匹配到,退出,表示用户符合该权限,否则提示用户不符合该权限
匹配成功,执行后面业务逻辑
将用户的权限ID和对应的规则储存到session里面,这样不用每次都读取mysql去获取权限,大幅度提升访问效率
















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











