







前言
使用了很多的python 三方库来做图片文字的识别,发现不尽人意,最后的最后还是不得不安装Tesseract来配合python
一、安装Tesseract
下载地址:选择自己需要的和适合的版本下载
注意:
在安装的过程中可以选择自己需要的语言包,比如中文等。(也可以本地配置语言包,根据自己的需求来编写)
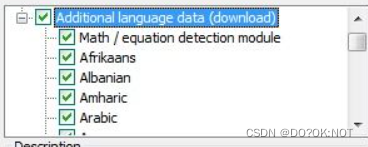
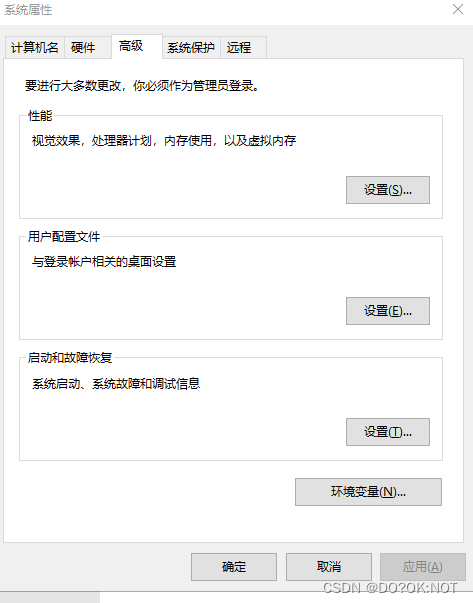
还需要把安装的目录配置到环境变量,如图:
二、python 库的安装
需要安装两个库;
pip install pytesseract -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
1.示例代码。
代码如下(示例):
import os
import pytesseract
from PIL import Image
# 列出支持的语言
print(pytesseract.get_languages(config=''))
print(pytesseract.image_to_string(Image.open(r"C:\Users\Administrator\Desktop\95db25e4060f12ac18ed264f55d41b9.jpg"), lang='chi_sim+eng'))
2.异常处理
运行起来的时候出现异常:
tesseract is not installed or it's not in your path
需要修改源代码的 pytesseract.py 文件
tesseract_cmd = r'tesseract.exe' # 原来的
tesseract_cmd = r'E:\app_install\pyocr\tesseract.exe' # 修改为你的地址
总结
有疑问!请留言!!!!!尽力回复!!!!!














 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









