







1.介绍
pytesseract是一个用于文本识别的Python库,它提供了方便的接口和功能,使得对图像中的文本进行识别变得简单和高效,pytesseract的特点和优势如下:
- 功能强大:pytesseract可以识别各种图像格式,如JPEG、PNG、BMP等,并且支持多语言识别。它使用Tesseract
- OCR引擎,该引擎在图像和OCR方面具有领先的技术和准确性。
- 简单易用:pytesseract提供了简单的API接口,使得开发者可以轻松地在其上进行图像文本识别。它还支持使用OCR引擎进行训练和自定义,从而满足特定的需求。
- 灵活性:pytesseract支持多种操作系统和环境,包括Windows、Linux、macOS等,并且可以在不同的开发环境中使用,如Jupyter、Notebook、PyCharm等。
- 高效性:pytesseract使用了多线程和GPU加速技术,可以快速地处理大量图像数据,提高识别效率。
2. 安装步骤
获取安装包
直接上链接:https://digi.bib.uni-mannheim.de/tesseract/
根据自己的要求选择版本

安装界面
- 选择语言,默认选英文就好

- 一直点击下一步就好
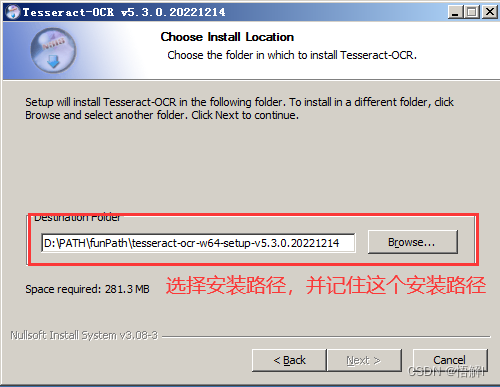
- 选择安装路径
- 安装完成
配置环境

检查安装成功
- 快捷键win + R,输入
cmd进入命令行。 - 输入:
tesseract -v回车

3. 使用
使用命令行运行
-
准备图片,在
E:test目录下有一张名为img.png的图片。

-
在命令行中 先进入图片所在文件夹,输入
tesseract 图片名 文件名,如下:

-
结果如下:

使用python代码运行
-
下载python环境和安装 pytesseract 包,这里不做过多讲解。
-
在
python解释器地址\Lib\site-packages\pytesseract中找到pytesseract,py文件

-
编写代码
from PIL import Image import pytesseract # 加载图像文件 img = Image.open('img.png') # 进行文本识别 text = pytesseract.image_to_string(img) # 输出识别结果 print(text) -
运行结果如下:



















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











