






目录
用一句话来概括传统的强化学习就是:通过计算最大累计 reward 的方式来寻找最优的 policy
然而,在多步决策(squential decision)的过程中,奖励 reward 无法在每一步动作之后都可以获得(有些行动短期内可能无法见到回报),并且在多步决策(squential decision)中,这种基于比较累计奖励的方式需要搜索数量巨大的可能性。
强化学习的大佬们
强化学习的一个代表人物,Sutton 教授采取的更多的是 value-based 的一些方法。
强化学习与有监督学习的区别
1. 有监督学习的数据为独立同分布,而强化学习是序列分布的数据
2. 有监督学习可以被告知标签是什么,而强化学习并不知道正确的行为应当是什么(没有立即的反馈也是其困难的原因)
3. 强化学习要有一个 trail and error的探索,还要考虑 exploration & exploitation 的权衡
4. 强化学习没有一个 supervisor 去指导,而且奖励信号延迟
强化学习的特征
1. trail and error exploration
2. 延迟的奖励
3. 序列的数据
4. agent 与环境的交互改变了它获得的数据
为什么要关注强化学习
监督学习的上限由人的标定结果来决定,但是强化学习是自己探索可以超越人类(AlphaGo)
当前强化学习很火的原因
1. GPU 牛皮了,可以做很多 trail-and-error 的 rollout
2. 有了端到端的方法,可以使得特征提取和策略估计在最后一起优化
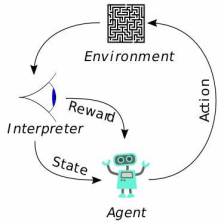
Agent 与环境的关系
1. Agent 给环境的是它的动作 a
2. 环境给 Agent 的是新的状态 s 和奖励函数 r(其实这里的环境应该是被广义化了)
RL Agent 的组成结构
1. 策略 policy function 被用于选取下一步的动作,往往用 π 表示
确定性策略:给出动作
随机性策略:给出动作的分布
2. 值函数 value function 对于当前的状态或者动作进行估价
定义:基于某一特定的策略 π 下的折扣的未来的奖励的加和
v(s) 即为 value function,值函数
q(s,a) 即为 Q-function,Q函数,强化学习要学这个Q函数,进入某状态后最优的行为就是由Q函数得到
3. 模型 就是 agent 对于整个环境的理解
模型包括两个大的部分
一是状态转移函数,即依据当前状态和采取的动作预测下一个状态
二是奖励函数,要给你多大的奖励
RL Agent 的分类
1. Value-based agent:直接学习值函数,依据值函数推导 policy
2. Policy-based agent:直接学习 policy
3. Actor-Critic agent:两者的结合,学习了策略函数和值函数















 5826
5826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









