






之前看过2遍西瓜书的强化学习部分,尽管看了2遍,但是你问我看懂了什么,我还是一头雾水。发现一个问题,你给了Q-learning或者DQN的伪代码,去做一个实战,确实可以复现,但是就是对背后的原理理解的很模糊。后来又去网上找了一些资料,比如知乎上对DQN的理解,看了之后对于DRL理解更进一步了,但还是有一些不理解的地方,因此后来我决定重新再来,去找李宏毅老师的DRL课程从头开始学,接下来是我的笔记部分。2020/11/21
# 理论部分学习李宏毅笔记(github版)+叶强pdf、Morvan
# 实践部分学习叶强gym编写+Q-learning、Sarsa、DQN、DDQN的实战、Morvan
# PER、Duling 学习刘建平博客园、Morvan

DLR发展现状及展望:https://www.xianjichina.com/special/detail_440829.html
Part 1:RL简介
1.1、监督学习与强化学习
机器学习分为监督学习、无监督学习、版监督学习、强化学习四大类(有的也认为是三大类),他们之间各有区别,各有联系。
1.1.1、监督学习的特点:
1、输入的样本服从独立同分布,即样本之间无关联,否则输出结果的稳定性很差。关于这里,我的理解是,由于输入样本之间若有关联性,那么学习器可能会学习到这个特性,将这个特性当成一种特征,那么当一批无关联的样本进行预测时,由于没有这个特征,因此就会有错误的预测结果,导致识别率很低。一批有关联的样本进行预测,则又会有正确的预测结果,导致识别率很高。而我们实际用于训练和测试的样本是不一样的。测试的样本往往是无关联的,那么训练好的学习器就会做出错误的判断。
2、监督学习有监督信号(即标签),它能通过loss fuction来及时调整学习器的参数,从而纠正预测值,理论上最终预测值能被纠正到接近标签的效果,因为由于大部分学习器模型比较复杂,无法求出解析解,因此只能通过有限次迭代来降低损失函数的值,这样的解为数值解,而解析解就是模型比较简单时,我们可以直接求出损失函数最小值时的参数解。
1.1.2、强化学习的特点:
1、输入样本之间具有时间连续性,其是一系列的序列<sj,sj',r,a>,相邻样本在时间上有连续性。
2、强化学习任务并没有监督信号,只有奖励信号。有时候奖励只有到最终时刻才会得到,拿Agent寻宝宫而言,只有最终寻到宝藏才会有奖励,因此之前的过程Agent得不到任何反馈去调整,去试错。在最终拿到宝藏,获得奖励后,才会去反省自己,进行调整,在下一次试验时,努力缩短寻宝的时间。因此RL可以看成是具有“延迟标签信号”的监督学习问题。
3、强化学习中Agent的试错是一个探索(exploration)和利用(exploitation)。探索就是说把试验的机会平均分配给每一种动作,这样做的好处就是可能可以探索到最高的奖励,坏处就是也可能探索到无奖励、负奖励。利用就是选择当下Agent所知道的动作中,能带来最高奖励的动作,这样做的好处就是一定可以带来稳定的较不错的收入,坏处就是Agent并没有获取最高的奖励。显然探索和利用是矛盾的,因此我们在探索和利用中进行折中,以一定概率进行探索,另一份概率进行利用。举个例子,比如Agent想选择一加奶茶店喝奶茶,假设全国所有奶茶每杯10元,一共6种奶茶店(一点点、蜜雪冰城、茶百道、古茗、阿姨奶茶、大台北),但Agent不知道有几家。然后Agent有60元,想买个6杯。纯探索就是Agent把6家奶茶店都逛了一遍,都喝一遍,然后就知道了哪家是最好喝的,比如一点点最好喝,茶百道最难喝(只是比如)。纯利用就是说,Agent只知道大台北和古茗的味道如何,比如大台北比古茗更好喝,所以Agent将60元全部给了大台北,买了它家的6杯奶茶。事实上,纯利用虽然喝到了还不错的奶茶,但并没有享受到一点点最好喝的待遇,;而纯探索虽然喝到了很难喝的茶百道,但是他心中有了一个口感质量的排序。那么想要拥有最大享受的花法,就是一部分用于探索,一部分用于利用,这就是-贪心策略,
是一个0-1之间的值,一般设置为0.1,即10%的概率随机选择一家奶茶店,90%的概率选择当前最好的奶茶店。通过不断试错,Agent才能慢慢理解这个环境。
1.1.3、强化学习的优势:
前面也说了,强化学习的标签是延迟的,也就是说无法获取及时的调整,因此很难训练出好的结果。既然这么难,为何还要研究呢?监督学习不是更香吗?
监督学习的标签是人为设定的,这就决定了学习器不可能超越人类。而强化学习会在环境中不断探索,一步步走向最优,升级自己,他有超越人类的潜质,比如家喻户晓的Alphago战胜围棋大师等传奇故事。
1.2、强化学习的基本结构:
1.2.1、基本结构:
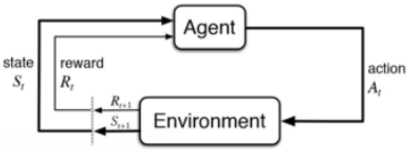
如上图所示:
step1:智能体Agent在环境Environment中获取状态St:。
step2:Agent依据决策policy做出相应动作At,接下来环境做出反馈:1、提供下一个状态S'。2、提供转移到S‘后对应的当前奖励Rt+1。
step3:Agent收下奖励,并更新到指定状态S’。
step4:回到step2。
Note:
1、Agent存在的目的就是最大化期望累计奖赏。为什么要最大化期望累积奖赏呢?因为对于我们要达到的最终状态,我们一定会设置最高的奖励,而其余状态我们一般不设置奖励或者较低的奖励甚至是负奖励。累积奖励代表着当前奖励和对未来将达到状态的奖励的预测,期望累积奖励则能更加准确描述这个值,值函数就是用来描述当前状态的期望累积奖励,这一点我们也可以从值函数与未来状态值函数的贝尔曼等式关系中得出,说明值函数是有一定预测未来的能力的。
那么我们站在任意一个状态上,Agent就会开始思考:为了达到最终目标,即最大那个奖励,我们的状态值函数一定要越大越好,因为值函数定义中,当前奖励是固定的,状态值函数越大,那么也就是对未来的预期值越大,而由于只有最终状态才会有大的奖励,其余状态都是负奖励,因此在负奖励状态中徘徊反倒会减小奖励的预期值,故只有尽快到达最终状态才会使得预期值增大,等价于当前状态可以更快到达最终目标。
那么当状态值函数达到最大的时候,意味着在到达最终目的地获取最大奖励的同时,这一路上获取的负奖励一定要最小,即最优路径的概念就出来了。当每个状态的值函数都达到最大时,将Agent放在任意一个状态,他都能找到最佳路径,实现目标。
2、Environment 跟 Reward 不是我们可以控制的,Environment 跟 Reward是在开始学习之前,就已经事先给定的。我们唯一能做的事情是调整policy,使得Agent可以得到最大的Reward。policy 决定了Agent的行为。Policy 就是给一个外界的输入,然后它会输出Agent现在应该要执行的动作。
3、“一开始,我对于RL的目的是为了让Agent获取更多的奖励”,这句话不理解,后来在悬崖寻路中,设置每一个格子奖励为-1,终点为0,我发现有的路径完成整个序列的奖赏-256、-50等等,而最大的值是-12,而这个最大值对应的就是最优路径,就是我们RL任务的目的----就是要找出这样-12的路径,而这个-12、-256、-50是起始点处开始跑到终点获取的,因此我们的目标就是让这个起始点处获取的这个奖励为-12,即最大累计奖赏,当这个点求出的奖赏为-12,那我们就知道他一定走了最优路径。那就要做2件事,一是要求出每个点能获取的奖励是多少,2是让这个奖励最大化。
对于强化学习任务,我们的目的是最大化累计奖赏(无衰减),也就是说我们要寻找一个最优策略policy,去最大化Agent拿到的奖赏。但是呢,一个Agent放在任意一个状态上,想要寻找到底最终目的路线,我们一开始是不知道的,因此最大化累计奖赏无法实现,那我们将目标转移到最大化期望累计奖赏,这个期望累计奖赏的设计需要满足2个条件,第一个是这是一个估计值,因此用期望E来估计,因为实际上奖励并不只是一个标量,奖励其实是一个随机变量。G其实是一个随机变量,因为Agent在给定同样的状态会做什么样的行为,这件事情是有随机性的。环境在给定同样的观测要采取什么样的动作,要产生什么样的观测,本身也是有随机性的,所以G 是一个随机变量。你能够计算的是 G的期望值来估计G。第二个是这个值需要有一定预测未来奖励的能力(依靠γ衰减)。
那么RL的目标就变成了2个小目标:第一个是如何去尽量精确的估计出这个期望累计奖赏,第二个是如何最大化这个期望累计奖赏。
前者就是规划的预测问题,也叫策略评估,我们用值函数表示,在model-based中,我们采用贝尔曼公式,用动态规划去求解,在model-free中,我们采用矩估计的思想,通过一步步逼近累计奖赏(衰减)来估计出期望累计奖赏的真实值。
后者就是规划的控制问题,目的在于得出最佳策略与最大值函数,在model-based中,我们采用贪心策略改善策略的方式完成策略迭代求出最优策略,或者求解贝尔曼最优等式的方法迭代出最大值函数,然后求解出最优策略。model-free中,MC通过贪心策略加以改善,从而求出最优策略;TD通过将行为策略和目标策略无限逼近的方式得出最优策略。
通过完成这2个小目标,最后求出RL的最优策略。
1.2.2、实际流程:
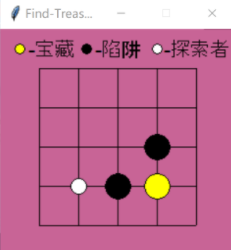
上图是我用Q-learning(暂时忽略这个,暂时理解为一个RL的算法)算法实现的Agent探宝游戏(具体可见:https://blog.csdn.net/MR_kdcon/article/details/109612413)。Agent落入陷进得-1分,找到宝藏+1分,其余不得分,踩入陷阱或者找到宝藏游戏结束。Agent刚开始是个“瞎子”,不知道干嘛。于是开始一次次的实验,一次次的试错。每一个格点都是一个观测值observation。Agent可以执行4个动作(上下左右)。前几次实验,Agent从左上角开始,一步步前进,但他也没有反馈信号,也不知道走的对不对,当落入陷进或者找到宝藏后,拿到了延迟的监督信号,然后开始反思,下一次实验想要最大化奖赏,就要避开陷进,寻找宝藏。比如上图这个局面,Agent上次实验可能会选择向右走,导致奖励为-1,那么当这次来到同样的地方,为了最大化奖赏,他就不会选择向右的动作,这就是Agent慢慢提升能力的地方。通过多次这样的试错,他就会慢慢理解这个环境,最终不仅完美避开陷阱,还以最短路径找到宝藏。这个最短路径就Agent通过训练学习到的最优策略。
1.3、强化学习中的角色:
1.3.1、动作空间Action、状态空间State:
Agent和环境的交互过程中,Agent根据当前观测值会做出某个动作a(所有动作的集合为动作空间Action),每一步都会获得reward、新的观测值observation(观测值的集合就是状态空间State),因此强化学习过程就是个时间序列,即<s0,a0,r1,s1,a1,r2......>,这样的一个序列为一次实验或一条轨迹。Agent就是要在多条轨迹中,为了最大化奖赏而学习到最优策略。
1.3.2、奖励Reward:
奖赏Reward分为当前奖赏(即上图中环境及时给出的Rt+1)和期望累计奖赏(有T步累计奖赏![]() 和
和折扣累计奖赏
![]() )。事实上,Agent的目的,或者说做出下一步决策的依据就是最大化期望累计奖赏,其实就和我们人类思维一样,你的下一步决策一定会考虑我这么做之后,长期的收益应该要最大化,而RL的目的就是让Agent学习人类的思维方式并超越人类。以
)。事实上,Agent的目的,或者说做出下一步决策的依据就是最大化期望累计奖赏,其实就和我们人类思维一样,你的下一步决策一定会考虑我这么做之后,长期的收益应该要最大化,而RL的目的就是让Agent学习人类的思维方式并超越人类。以折扣奖赏为例,可以看到越是未来,其比重越低,这其实就和我们认知的一样,当前的奖励自然要更加注重一些,但长远的奖励也不能不考虑。
Note:在RL的实践中,算法大同小异,一个可以施展身手的就是奖励的设定。我把奖励设置为4种:
①:真终点奖励,即想要诱导至终点的那份奖励,一般设为大于等于0即可。
②:无奖励,即起点走向终点过程中的路程段,一般设为0。有一种RL任务会设置障碍,那么障碍处的奖励也一般设为无奖励。
③:渐进式奖励,比如像经典RL游戏,Moutaincar中,为了诱导小车快速上坡,可以从低到高设定奖励逐级递增。
④:伪终点奖励,即陷阱、悬崖,为了让Agent避免走入某个区域,可以把这个区域的奖励设成负数即可。
1.3.3、智能体Agent:
一个Agent由以下1个或多个组成:决策函数、价值函数、模型
1.3.3.1、决策函数:
决策函数的自变量是当前状态,输出是下一个动作。policy function分为随机性策略和确定性策略,RL一般采用前者。
1.3.3.1.1、随机性策略:
(a | s)=P[At=a | St=s] 。当你输入一个状态s的时候,输出是一个概率。这个概率就是你所有行为的一个概率,然后你可以进一步对这个概率分布进行采样,得到真实的你采取的行为。比如50%采取动作a1,40%采取动作a2,10%采取动作a3。
1.3.3.1.2、确定性策略:
![]() ,无论状态如何,都一律采取最大化策略所对应的动作,比如上面这个50%采取动作a1,40%采取动作a2,10%采取动作a3,确定性策略就会直接采取a1。
,无论状态如何,都一律采取最大化策略所对应的动作,比如上面这个50%采取动作a1,40%采取动作a2,10%采取动作a3,确定性策略就会直接采取a1。
1.3.3.2、价值函数:
在当前已知的策略下的期望累计奖赏。
1.3.3.2.1、状态值函数:
![]() 用于衡量状态s时,在策略
用于衡量状态s时,在策略下的期望累计奖赏,等价于当前状态s的好坏(即状态值函数越大,表明当前状态更好,反之,状态很差)
1.3.3.2.2、动作-状态值函数(Q函数):
![]() 比状态值函数多了一个动作,用于衡量在当前状态s执行动作a后,在策略
比状态值函数多了一个动作,用于衡量在当前状态s执行动作a后,在策略下的期望累积奖赏。Q函数常用于算法中,因为从Q中我们能更好地提炼出最优动作a。
为什么要用累计奖赏来评估状态的价值或者在状态s执行动作a的价值呢?而不是用当前奖励来评估?
举个例子,如下图所示:

在路口这个状态时,如果执行闯红灯这个动作,如果用当前奖赏的话,就是-1.如图救护车,如果闯了红灯,但是闯了之后,由于病人得到了及时的救助,最后终止状态获得+1000的奖励,那么真正能表达这个状态动作对价值的应该是这个当前收益和未来收益的总和,这是因为现实中,奖赏是有延迟的。这就是为什么我们在评估当前状态(或状态动作对)时要用累计奖赏的原因。
在累计奖赏中引入折扣因子的原因:

1.3.3.3、模型:
RL根据有无模型,可分为model-based和model-free两类
1.3.3.3.1、有模型:
当状态s,动作a确定后,下个状态以及奖励也就确定了
1.3.3.3.2、无模型:典型的如Q-learning、Sarsa算法
1.4、强化学习的分类:

1.4.1、第一种分类方式policy-based、value-based、actor-critic:
1.4.1.1、policy-based
基于策略的方法,输入是状态,输出是执行下个动作的概率(a | s),因此他直接学习到的就是策略。
1.4.1.2、value-based
基于值函数的方法,输入是状态,输出是值函数的大小,然后选择值函数最大对应的动作为下个动作,因此他直接学习到的是值函数,间接学习策略。
1.4.1.3、actor-critic
这种方式是上面2种方式的结合。
来看一下基于策略和基于价值的区别:


左图是policy-based训练后的结果,箭头arrow代表当前状态的策略;当Agent处于某个observation,会直接输出下个动作的概率,然后执行。
右图是value-based训练后的结果,数值代表当前状态的价值大小或状态好坏。当Agent处于某个observation,如-15,他会将上下2个值函数的大小进行比较,选择最大那个值对应的动作(因为我们要最大化期望累计奖赏,故要去选择价值函数大的那个状态),然后执行。
1.4.2、model-based和model-free:
RL可以用马尔科夫四元组<S A P R>表示,S表示状态空间,R表示动作空间,P表示在observation执行动作a后,到下个状态observation'的概率,R表示在observation执行动作a后,到下个状态的奖励。
1.4.2.1、model-based:
基于模型的方式对四元组是确定的,因此可以对值函数用动态规划去求解贝尔曼等式,最后得出每个状态下的值函数大小,这成为策略评估。然后通过策略迭代和值迭代可以求出最优策略。其伪代码如下所示:


策略迭代是用贝尔曼等式用动态规划不断进行评估获取每个状态的值函数大小,然后进行改进,获取第一代版本的策略,然后以相同的方式不断迭代,当策略变换不大的时候,输出为最优策略,这个过程中不需要去和环境互动,不需要去试错,就能获得每个状态的最优策略,然后根据最优策略去执行动作,相当于对环境建了模,在模拟环境中不断学习,提升策略,最终得到最优策略。
值迭代是直接求取最优贝尔曼等式,用动态规划求解每个状态的最优值函数,当值函数变化不大的时候,输出最优值函数。和策略迭代一样,这个过程不需要和环境互动,就能获得最优策略,然后根据最优策略(即建立好的模型)在环境中执行最优动作。
1.4.2.2、model-free:
基于模型的方式对四元组中P、R是未知的,因此不能使用动态规划求解其贝尔曼等式,只能通过多次试验,不断与环境交互,不断试错,每次都要等待获取下个状态及奖励,不断去优化策略。
1.4.2.3、总结:
可以看出model-based不需要多次试验,直接进行建模,然后利用训练好的模型在真实环境中实现,model-free需要多次试验,多次采集样本进行不断更新策略。因此model-based有利于解决数据匮乏下的强化学习任务,但模型毕竟不是真实世界,存在一定的误差,从伪代码也可以看出,迭代停止的条件是变化很小,因此不一定能收敛到全局最小,而可能是局部最小,而model-free却可以不断更新策略,通过训练不断接近全局最小。
1.5、近几年强化学习发展的原因:
1、算力(GPU、TPU)的提升,我们可以更快地做更多的 trial-and-error 的尝试来使得Agent在Environment里面获得很多信息,取得更大的Reward。
2、我们有了深度强化学习(DRL)这样一个端到端的训练方法,可以把特征提取和价值估计或者决策一起优化,这样就可以得到一个更强的决策网络。(DRL就是不需要手工设计特征,仅需要输入State让系统直接输出Action的一个end-to-end training的强化学习方法。通常使用神经网络来拟合 value function 或者 policy network。)
Part2:马尔科夫决策过程(MDP):
2.1、马尔科夫性质:
MDP基于马尔科夫性质:未来只取决于当前,或者说物体下一个时刻的状态仅仅取决于当前的状态和动作。

Note:
这里的状态时完全可观察的(即上帝视角)。具体来说,我们的人眼就是不完全可观察的,我们并不能观测眼前的车子出于什么物理位置,其速度是多少,因此不知道下一个时刻它的位置及状态,而上帝视角呢?它是完全可观察的,他明确知道所有物体的状态,包括位置、速度等,因此他知道车子下一时刻的具体位置和速度是多少。
举个例子:
铅球从手中释放,接下来我们知道他会做自由落体(忽略空气阻力)运动,我们知道落地前任意时刻的速度是v,位置是h,那么根据公式,我们就知道下个时刻他的位置及速度,这就是简单的马尔科夫过程。
强化学习中Agent与环境交互的过程就可以用MDP来描述,MDP是RL的基本框架,但实际上环境中的状态都是不完全可观测的,但那个部分可观测的也可以用MDP来描述。
马尔科夫过程(或马尔科夫链)、马尔科夫奖励过程是MDP的基础,因此理解MDP之前需要理解这两块内容:
2.2、马尔科夫过程(MP):
可以用一个二元tuple表示(S,P)
S是状态空间
P是状态转移矩阵
2.2.1、马尔科夫链:

如上图所示就是马尔科夫链,表示了一个状态之间转移的过程。比如s1状态时候,10%概率会转移到自身,20%的概率会转移到s2,70%的概率会转移到s4。
通过对这条链进行采样,就会得到许多条轨迹。
比如从s1开始:
s1->s4->s2->s1
s1->s2->s1
s1->s4->s3->s2
这就是采样过程,当轨迹的最后一个状态是中止状态时,我们称这段序列为完整序列。
2.2.2、状态转移矩阵:
这个转移的概率可以用一个状态转移矩阵表示,如下图所示:

Note:每一行加起来为1.
2.3、马尔科夫奖励过程(MRP):
用一个四元tuple表示(S,P,R,)

MRP=马尔科夫链 + 期望累积奖赏

如上图所示, 上面部分是马尔科夫链,下面文字部分说明了即时奖励的大小,因为状态有限,所以用一个vector来表示。
特别要注意一下奖赏的定义:表示当我到达当前状态s后(或离开当前状态时,也就是说到达状态s后,不会立即获得奖励,而是离开的时候获得环境对该状态的奖励),获取的奖励。如下图所示:这里的r表示离开状态s时获取环境对状态s的奖励。
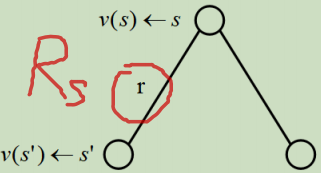
比如S7的奖赏R7=10,根据定义,他表示当我到达S7的时候,我下一个时刻获得的奖赏是10。
为了更好地描述MRP的过程,需要知道几个概念:期望累计奖励、状态值函数、贝尔曼等式、动态规划
2.3.1、期望累计奖励:
收获(return)定义:![]()
Note:
1、从某个状态开始,直到中止状态过程中获得的奖励之和。
2、期望累积奖赏:对收获求期望E。
3、收获中包含了对未来的预测。
其中是折扣因子(一般取0.9),从期望累计奖赏可以看出:
1、的设计既注重当下利益,又不失长远目光。这就像我们人类思考问题的方式一样。数学上看,可以避免收获的获取因陷入循环而无法求解。
2、关于折扣因子,越往后,折扣因子越小,那是因为我们对未来的估计不一定准确,因此需要削减得厉害一点。而前面时间步的折扣因子大,那是因为当下的奖励更重要,毕竟Rt+1是直接拿到手的。
3、当=0时,只注重当下利益,属于“短见”;当
=1,可以看到长远的利益,属于“远见”,实际中设计者可以自行设计
的值。
2.3.2、状态值函数:
定义: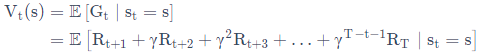

状态值函数V(s)用于衡量状态s的好坏,代表状态s的价值,其值代表了在状态s的期望累积奖赏。值越大,表明状态s越好,能获得一个很好的长远收益。就像我们人类的思考方式一样,都要考虑状态的价值是否符合我的要求。
从上图最后一句话可以看出,这就是为什么值函数定义为收获的期望而非单纯收获。,因为前者能更准确的反映状态的价值。
举个例子:

我们需要考量S4的价值高低,以便我们做出动作去选择它。我们可以这么做,在马尔科夫链中采样多条轨迹,比如图中采样了3条轨迹,获得了3次的累计奖赏,但是如何计算V(S4)呢? 所以接下来要引入计算值函数的方法:
1、动态规划
2、蒙特卡洛采样
3、时序差分方法(TD)
2.3.3、贝尔曼等式:
贝尔曼等式:他是根据值函数的定义推导出来的,第一部分是到达状态s后获取的即时奖励,第二部分是用状态转移矩阵乘以状态s的下个状态的值函数大小,最后再乘以折扣因子进行衰减。s'可以看出是未来任意一种状态。
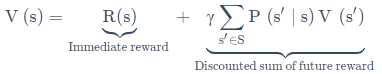
贝尔曼等式表明:当前状态值函数取决于当前奖励与未来状态的值函数。表示了状态之间的迭代关系。
MRP贝尔曼等式的推导:(注意这里需要用到全期望公式)

关于数学期望:数学期望简介
关于条件期望:条件期望简介
关于条件概率密度:条件概率密度简介
条件期望补充:
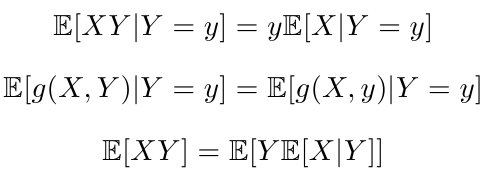
举例子:

比如我们要用值函数来衡量S1的好坏,可以看出S1未来有三个状态可以去,因此用S1、S2、S4的价值乘以状态转移向量,用它们的和加上即时奖励,就是状态S1的价值。
如果用矩阵来表示值函数的话:

通过基础的线性代数知识,我们可以获得V(s)的解析解:
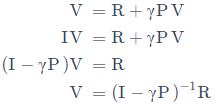
但是矩阵求逆会产生O(N^3)的复杂度,即状态越多,计算量会很大,因此解析解只能适用于小规模的MRP。
2.3.4、蒙特卡洛采样法:
Note:蒙特卡洛采样不需要贝尔曼等式,要用到矩估计法(EX=X平均)。
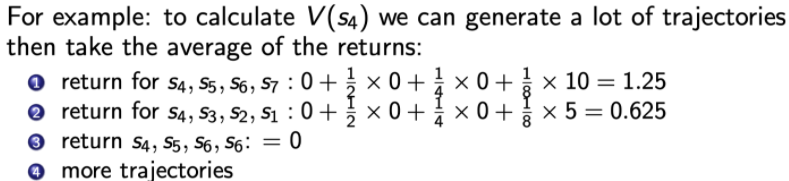
就像之前那样,对马尔科夫链多次采样,比如如上图所示,我们想要衡量S4的价值,因此对于每一条轨迹,计算它的累计奖励,最后对这么多条从S4开始的轨迹产生的结果求取平均来估计期望累计奖励,该估计值就代表了V(S4),这就是蒙特卡洛采样法。
2.3.4、动态规划:
状态的值函数亦可以通过用动态规划去求解贝尔曼等式来做,其伪代码如下:

首先需要对每个状态进行初始化为0。然后就是对贝尔曼等式进行有限次的迭代过程 ,直到某一次计算出来的值函数和上一次计算出来的值函数相差不大,比如差距小于我们预先定义的某个值。
1、动态规划需要遍历每个状态。
2、值函数的更新需要用的上个时间段的未来状态的值。用估计值估计估计值的方式叫bootstrapping(拔靴自助) 。
2.3.4、时序差分法(TD):
TD方法是蒙特卡洛采样法与动态规划法的结合,这个之后再介绍
2.4、马尔科夫决策过程(MDP):

特别需要注意的是,在MRP中我们需要选择哪个状态具有更高的价值,而在MDP中,我们需要选择哪个行为更具有价值。
可以用一个五元tuple来表示:(S,P,R,A ,)。

这里的奖励R(s,a)表示,当我在状态s执行动作a后,获取环境对我这个状态动作对的奖励,比如下图中的r就表示R(s,a):

举个例子,比如格子世界中(除了中止状态,其余状态奖励都是-1),下个状态是中止状态,那么Rt+1=0。
上图表明:
1、在MDP中,下一时刻的状态,不仅仅像MRP和MP一样,取决于当前状态 ,还取决于动作(或者该状态的决策).。
2、在MDP中,下一时刻的即时奖励,不仅仅像MRP一样,取决于当前状态,还取决于动作(或者该状态的决策)。
3、在MDP中,状态拥有可以在行为集中选择一个动作的权力,而选择动作后,状态的转移则由环境决定。
4、可以看出,MDP比MRP仅仅多了一个动作空间A,直接会影响到状态转移矩阵P和即时奖赏R
5、MP->MRP->MDP:(S,P)->(S,P,R ,)->(S,P,R,A ,
)
2.4.1、Policy function
状态从行为集中选择某个动作的依据称为策略。
此外,MDP中用一个policy function(简称策略)来描述这个动作空间A,如下所示:
![]()
1、策略产生的动作仅有当前状态有关,而与历史状态无关。
2、这个policy function表示一个概率(随机性策略),即当前状态为s时,输出动作a的概率。比如60%的概率往左走,40%概率往右走。
3、还有另外一种表示法(确定性策略): a = (s) ,表明当前状态为s时,直接输出一个决策动作a。比如当前处于位置s=s5时,向上走。
4、对于同一个状态,依据相同的策略,也能产生不同的动作。
5、我们通常所说的策略,大的来说,是一个完整Episode中,统计所有遍历过的状态的动作合集;小的来说,就是当前状态下,依据这个合集应该采取的动作。
2.4.2、MDP与MRP的转换
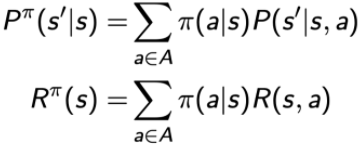
这里要用到全概率公式。
这2个公式告诉我们,在MDP中,一个策略对应一个MRP过程,一个MP过程。不同的策略会产生不同的MRP,从而产生不同的状态值函数V(s),因此MDP需要重新定义值函数。
2.4.3、MP(或MRP)与MDP的不同解析:

如上图所示:左图是马尔科夫过程,或者也可以看成马尔科夫奖励过程,右边是MDP
MP在已知当前状态会直接输出下个状态的概率。
MDP多了一层决策层,当前状态和下个状态之间需要经过决策。通过对决策函数进行第一次采样采样(决策函数也是个概率分布),输出一个动作。动作和下个状态之间又是一个概率分布,因此需要进行第二次采样来获取下个状态。总之,和MRP不同,输入状态和输出状态之间需要求决策过程Decition progress。
第一个过程是由决策函数决定的,是可以人为调整的;第二个过程是环境决定的。或者说,状态拥有可以在行为集中选择一个动作的权力,而选择动作后,状态的转移则由环境决定。
2.4.4、状态值函数与动作-状态值函数:
与MRP不同,MDP中对于状态值函数进行了更改,以及引入了动作-状态值函数(或者叫Q函数)。
2.4.4.1、状态值函数:![]()
定义:![]()
回忆MRP中的状态值函数,没有上标π,。表示在状态s所获得的收获的期望值。
那么在MDP中呢,如定义一样,除了多了上标π以及一层决策层以外,其余原理都和MRP一样。
在MDP中,状态价值函数表明在策略π下,从状态s开始,所获得的收获的期望。
2.4.4.2、状态-动作值函数:
为了衡量同一状态下不同动作的价值,引入Q函数。
定义:![]()
这里的状态值函数表示在策略π下,状态s执行动作a,所获得的收获的期望值。
Note:
状态值函数多用于单纯表示基于状态的价值大小。
2.4.5、贝尔曼等式:
①:
![]()
②:
![]()
④:
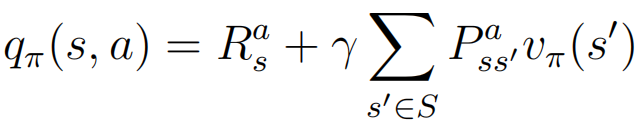
一般来说,q代表了执行动作a的价值,q越大表示执行该动作后所到达的状态的价值更大。
⑤:
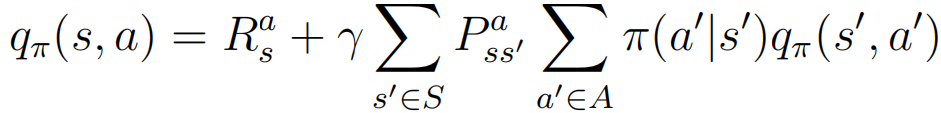
⑥:
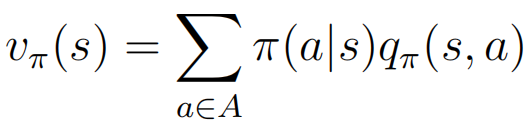
⑦:
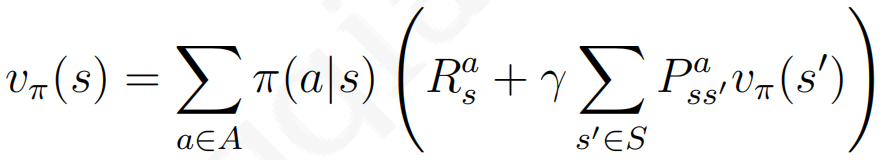
下图5个公式是MDP中有关贝尔曼等式的基本公式,推导如下(其中还加入了参考Sutton强化学习P62的简便推导):

2.4.6、值函数的求解:
2.4.6.1、![]() 的求解:
的求解:
有了贝尔曼方程这个工具,我们就可以通过不断迭代来求取某个状态的价值![]() ,以及某个状态动作对的价值
,以及某个状态动作对的价值![]() 。
。

如上图所示,空心点为状态s,s',实心点为状态动作对(s,a),![]() 衡量了状态s的价值。
衡量了状态s的价值。
那么![]() 是如何计算的呢?
是如何计算的呢?
A = B+ C
其中B:公式⑥所示->
其中C:公式④所示->
其中A为公式④带入⑥的叠加:公式⑦所示->
这个backup过程揭示了状态s的价值与未来状态s'的价值是迭代的关系。
举个例子:
下图是学生上课的MDP,策略函数是每个动作均有50%的概率被选中,=1。

然后来求解最右边空心点的状态值函数 ![]() ,看看他的价值有多少?
,看看他的价值有多少?
根据公式⑦所示:
![]() = 0.5 * (1 + (0.2 * -1.3 + 0.4 * 2.7 + 0.4 * 7.4)) + 0.5 * 10 = 7.4
= 0.5 * (1 + (0.2 * -1.3 + 0.4 * 2.7 + 0.4 * 7.4)) + 0.5 * 10 = 7.4
2.4.6.2、![]() 的求解:
的求解:

如上图所示,空心点为状态s',实心点为状态动作对(s,a),![]() 衡量了状态s的价值。
衡量了状态s的价值。
那么![]() 是如何计算的呢?
是如何计算的呢?
A = B + C
其中B:公式④所示->![]()
其中C:公式⑥所示->![]()
其中A:公式⑥带入④:公式⑤所示->![]()
这个backup过程揭示了状态动作对的价值与未来状态状态动作对的价值是迭代的关系。
2.4.7、动态规划:
2.4.7.1、定义:
规划的定义:

动态规划的定义:

动态规划需要满足2个结构:
1、最优子结构:
在 Bellman equation 里面,我们可以把它分解成一个递归的结构。当我们把它分解成一个递归的结构的时候,如果我们的子问题子状态能得到一个值,那么它的未来状态因为跟子状态是直接相连的,那我们也可以继续推算出来。
2、重叠子问题:
贝尔曼等式的解就是值函数,因此值函数存储了子问题的解。
Note:动态规划应用于 MDP 的规划问题(planning)而不是学习问题(learning),我们必须对环境是完全已知的(Model-Based),才能做动态规划,直观的说,就是状态转移概率P和对应的奖赏R是已知的。
MDP中,预测和控制是规划的两个核心问题。
预测:给定MDP、策略π,去求解每一个状态的值函数。
控制:不同的策略会输出不同的值函数,因此控制contorl就是给定MDP,去求解最优值函数V*和最优策略π*。
求解方式:动态规划
举个例子:

上图就是个预测过程,给定的策略π是随机采样,即上下左右各25%的概率被选中。图(b)是各个状态的的价值函数,通过求取价值函数的过程就是预测。

上图就是个控制过程,控制过程没有像预测过程那样有个固定的策略,而是将预测作为一个子过程,通过比较不同策略带来的每一个状态的值函数,并找出每个状态最大值函数作为最优值函数。而最优策略产生的值函数比任何策略产生的值函数都高。
2.4.7.2、预测(策略评估):
策略评估:计算一个策略π下产生的状态价值函数的过程。就是规划中的预测问题。
可以使用同步迭代+动态规划(即同步动态规划)的方法求解:从任意一个状态开始,利用贝尔曼公式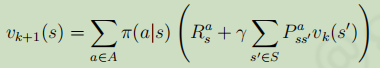 ,对k+1步的每一个状态值函数用第k步的状态转移函数值去计算(符合马尔科夫性质),如下图所示。
,对k+1步的每一个状态值函数用第k步的状态转移函数值去计算(符合马尔科夫性质),如下图所示。
直至收敛,得到该策略下的最终的状态价值函数。且可以确保能收敛到一个稳定的值。我们也可以迭代到对任意状态的值函数,与上个时间步的状态值函数相差很小时,认为其收敛完成。
Note:
1、同步迭代:每一次迭代,都需要更新所有的状态。异步迭代:通过某种方式,每次迭代只更新一部分状态,节省了许多计算资源。
2、之前有说过,一个策略函数对应了一个MRP、MP,因此当π确定时,MDP可以简化成MRP,即去掉动作a,改掉奖励与状态转移矩阵P:![]()
例1:如下图所示,假设我们现在有一个4*4的方格世界,1号和16号为终止状态,到达终止状态奖励为0,其余状态奖励为-1:,初始化16个状态的状态值函数为0,动作空间为上下左右:

规定初始策略为均一策略,即各有25%概率选择其中一个动作,每次迭代都需要利用上述贝尔曼公式对16个状态值同步进行更新。
容易想到:
1、最终到一定程度会稳定下来后。此外,每个状态的值函数都是不同的,如下图所示:

2、每个状态的值都反映了该状态的价值,或者说是Agent对这个环境的理解。
3、越是中间地带,其值函数越低,因为中间地带一直在扣分,只有2个角落分数高(不扣分其实也是反向加分)
例2:为了更好地描述出k=0到k=inf,格子世界状态值函数的变化,使用斯坦福大学的一个网站:GridWorld: Dynamic Programming Demo 去模拟这个过程:
初始状态:每个状态(格子)都标注了奖励值R,可执行方向、状态值函数的值![]()

k=1:根据上述贝尔曼等式,可以容易口算出:

k=2:
重点关注下黄色的值,为啥会有值呢,他不是奖励为0吗,那是因为他的右边这个状态值函数非0,即![]() 非0,通过
非0,通过![]() ,可以至少推断出,黄色状态必小于0:
,可以至少推断出,黄色状态必小于0:

Note:从这里也可以看出值函数是如何扩散的。
k=10:

k=20:
如下图所示,随着迭代加深,在均一策略下,非0值的状态在扩散。奖励为-1的状态其状态值函数始终比奖励为0的状态值函数低很多,同时,所有状态值函数都在随着迭代加深而不断降低。

k=30:
当k在30之后,状态值函数开始稳定了,这样符合我们之前的结论:

k=inf的话,读者自己去玩吧。。。。。
2.4.7.3、控制
最优值函数定义:由于不同策略会得到不同的值函数,因此所有策略中,产生最高值函数即为最优值函数:![]() 、
、![]() 。
。
最优值函数可以由最优动作值函数求得:公式⑧:![]() ,他表示状态s的最优值函数是该状态下所有动作对应的最优状态动作值函数中的最大值。
,他表示状态s的最优值函数是该状态下所有动作对应的最优状态动作值函数中的最大值。
最优策略定义:输出最优值函数的那个策略为最优策略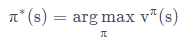 ,最优策略使得每个状态的值函数最大,每个状态动作对的值函数最大。
,最优策略使得每个状态的值函数最大,每个状态动作对的值函数最大。
如下图所示,最优策略可通过最大化最优状态动作值函数所对应的的动作求得:

这意味着:
1、若知道最优状态动作值函数,就知道了最优策略。因此求解强化学习的问题就转变成了寻求最优状态动作值函数的问题。
2、最优策略是确定性策略。
补充:

举个栗子:这里的值函数是经过预测后的,意味着已经是稳定的值。

如上图所示,假设我们需要求状态S1的最优值函数、以及(s1,a1)(s1,a2)(s1,a3)的最优状态动作值函数,and最优策略。
Note:
1、最后求得在s1下的最优策略是100%执行动作a2,可见强化学习任务最终的策略将会被更新为执行最优动作。
2、要想求得最优策略,必须先求出当前状态每个动作的最优状态动作值函数,然后通过取argmax来找到当前状态的最优策略,接下来对每个状态都这样做来达到目标。
那么如何搜寻最优状态动作值函数呢?

Note:
1、穷举法就是根据最优策略的定义![]() 而来的,即搜寻一种策略π,让每一个状态的值函数最大。比如会输出下图这种策略:
而来的,即搜寻一种策略π,让每一个状态的值函数最大。比如会输出下图这种策略:

2、这种方式毫无效率,因此常用策略迭代和值迭代。
2.4.9.4、策略迭代:
经过策略评估后,每个状态都有了稳定的值函数,接下来可以利用这个值去调整自己的策略。
回忆下,RL任务设计的初衷是想最大化期望累计奖励来诱导Agent完成目标,而期望累计奖励用值函数来表示,因此我们的目标就是去选择前往值函数最大的那个状态。于是就有了贪心策略(![]() )。
)。
贪心策略(策略改善):
1、选择所有能到达的状态中价值最大的那个状态。我们在每一次策略评估完成后(达到收敛),得到了状态值函数,
2、然后利用状态值函数求取状态动作值函数,即公式④:。
3、使用贪心策略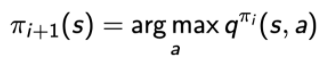 ,这里可以把Q函数看成Q表(类似下图所示),贪心策略就是在状态s时,执行最大值时对应的动作a。
,这里可以把Q函数看成Q表(类似下图所示),贪心策略就是在状态s时,执行最大值时对应的动作a。
4、基于贪心策略又会产生新的状态值函数,如此循环下去,最终就会获得最优价值函数和最优策略π*。
5、贪心策略是确定性策略。

如下图所示,在完成第一次策略评估后,使用贪心策略:

可以看出,在使用贪心策略后,Agent的靠近两边的行为更加接近目标,因此这是一个策略改善的过程。策略在不断迭代过程中进行改善,这就是策略迭代过程。
Note:
1、除了初始策略外,迭代过程中的策略均为基于状态价值函数的贪心策略π'。
2、要把贪心策略和区分开来,后者是用于求取某个状态的最优策略。
如下图所示策略迭代就是策略评估和策略改善不断交替进行的过程:

整个策略迭代过程:
1、首先从一个初始策略π出发,计算一次完整(直到收敛为止)的策略评估,获取每个状态的值函数。
2、对每个状态值函数求取状态动作值函数,并基于贪心策略更改为π'。
3、基于新策略π',再次进行完整的策略评估,获取每个状态的值函数。
4、对每个状态值函数求取状态动作值函数,并基于贪心策略更改为π''。
5、重复3、4,直至收敛为止。
如下图所示,这是策略迭代产生的最优策略,可以看出,对每个状态,最优策略都指出了通往目标的最优动作,这是因为设计时,我们将最优策略指向的目标价值最大的状态。
左图是最优策略,右图为非最优策略:可以看出,最优策略使得每个状态的值函数达到最大。

策略迭代的伪代码:
为什么一直迭代下去就能得到最优策略呢?证明如下:(这个证明还没看明白,以后有时间再看)


从这个证明可以看出:策略每次改善,每个状态的值函数都在单调递增。
2.4.9.5、值迭代
在介绍值迭代之前,先说下最优贝尔曼等式:
其实也简单,最优贝尔曼方程就是在贝尔曼方程的基础上将值函数替换成了最优值函数:
根据公式④:进行改编->公式⑨: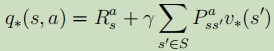
又因为公式⑧![]() ,所以,
,所以,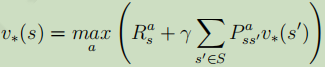 ,
,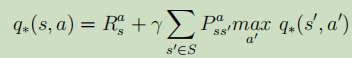
Note:贝尔曼等式的解是值函数,那么最优贝尔曼等式的解就是最优值函数。
举个栗子:

红线就是最优策略,那么如何得到这条红线呢?
最优值函数均已求得,我们来验证下,选择最右边那个状态C2、C3来说明:
它有2个动作,分别是学习和泡吧。为了得到最优策略,我们要先得到最优状态动作值函数q*。
根据最优状态动作值函数的定义,需要比较q(C3,泡吧)和q(C3,学习)的大小
根据公式⑨:
假设=1:
q*(C3,泡吧)= 1 + (0.2 * 6 + 0.4 * 8 + 0.4 * 10) = 9.4
q*(C3,学习)= 10
q*(C2,学习)= -2 + 10 = 8
q*(C2,退出学习)= 0
根据,显然10>9.4,故状态C3的最优策略是执行学习,即右上角粗虚红线部分。
显然8>0,故状态C2的最优策略是执行学习。
根据![]() ,显然C3状态的最优状态值函数是10,C2的最优状态值函数是8。
,显然C3状态的最优状态值函数是10,C2的最优状态值函数是8。
值迭代过程:
首先需要理解一个结论:
最优化策略<==>当一个策略使当前状态s获得最高价值当且仅当该策略同样获得状态s之后的任意状态s“的最优价值。
值迭代过程需要用到最优贝尔曼等式的一个公式:
从该公式可以推断出:
1、如果我们知道最终状态的价值和奖励函数,我们就能知道其前一个状态s'的最优价值。由于一般我们不知道最终状态是哪一个,故需要对每个状态进行更新。
2、值迭代的目标是为了寻找最优策略,通过最优贝尔曼等式,根据前一步的最优值函数推出当前时间步的最优值函数。
不断迭代至收敛后,通过公式,输出状态动作值函数Q,此时的Q其实是个最优值函数,然后对这个状态动作值函数使用一次贪心策略argmaxQ,来输出最优策略。
值迭代的伪代码:
举个栗子:

说明:最终状态为左上角(Agent并不知道这个位置),奖励为0,其余为-1,初始化状态值函数为0。=1
step1:根据公式,我们从最终状态的最优值函数0推出V2所示的各个状态的值函数。
step2:根据公式![]() ,我们从最终状态的最优值函数0推出V3所示的各个状态的值函数。
,我们从最终状态的最优值函数0推出V3所示的各个状态的值函数。
step3:根据公式![]() ,我们从最终状态的最优值函数0推出V4所示的各个状态的值函数。
,我们从最终状态的最优值函数0推出V4所示的各个状态的值函数。
step4:根据公式![]() ,我们从最终状态的最优值函数0推出V5所示的各个状态的值函数。
,我们从最终状态的最优值函数0推出V5所示的各个状态的值函数。
step5:根据公式![]() ,我们从最终状态的最优值函数0推出V6所示的各个状态的值函数。
,我们从最终状态的最优值函数0推出V6所示的各个状态的值函数。
step6:根据公式![]() ,我们从最终状态的最优值函数0推出V7所示的各个状态的值函数。
,我们从最终状态的最优值函数0推出V7所示的各个状态的值函数。
step7:根据公式,求出最优Q表,然后使用贪心策略输出最优策略。
至此,值迭代的整个过程就结束了。
栗2:同样是斯坦福那个例子,此次值迭代的最终生成的最优策略和策略迭代的结果是一样的,如下图所示,左图是值迭代,右图是策略迭代:

Note:以上的动态规划算法属于同步动态规划,对所有状态同步更新,但是比较浪费计算资源,而异步动态规划则根据一定原则有选择性的更新部分状态。
2.4.9.5、MDP总结:
通过一个例子来总结下MDP的整个过程:




Part3、Model-free的规划
model-free是不基于模型的RL方法,其可以认为是MDP,但却不掌握MDP的具体信息,如状态转移矩阵P和奖励函数R。通过Agent与环境的交互来进行策略评估和策略
还是以熊的例子:


3.1、model-free的预测问题(重点放在MC、Sarsa、TD(0)):
3.1.1、蒙特卡洛学习(MC):
MC学习中的策略评估本质是利用了状态值函数的定义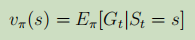 ,其中G为收获
,其中G为收获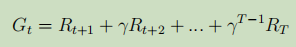 。根据概率论中矩估计的概念,随机变量的期望用随机变量的平均来估计,因此状态值函数可以用该状态的多个收获通过取平均来估计,可以通过Agent与环境多次采样来实现同个状态的多个收获值,理论上根据大数定律(大数定律通俗一点来讲,就是样本数量很大的时候,样本均值和真实均值充分接近),采样次数越多,结果越精确。每一条的采样轨迹如下:
。根据概率论中矩估计的概念,随机变量的期望用随机变量的平均来估计,因此状态值函数可以用该状态的多个收获通过取平均来估计,可以通过Agent与环境多次采样来实现同个状态的多个收获值,理论上根据大数定律(大数定律通俗一点来讲,就是样本数量很大的时候,样本均值和真实均值充分接近),采样次数越多,结果越精确。每一条的采样轨迹如下:
![]()
MC学习中,轨迹必须是完整的序列,即不要求起始状态一致,但是必须都达到终止状态。
这就是MC的策略评估,显然MC不需要像model-based一样,依赖状态转移概率P去评估策略,而是通过不断与环境交流,通过对同一状态的多个收获取平均来估计。
在MC的策略评估中,还有个小技巧,即对均值进行增量式学习:具体如下

如上图所示,累进更新平均值从原来需要存储k个收获,到现在只需存储当前轨迹的收获以及轨迹条数2个变量,所以存储量大大减少。
或者,更为简洁的表示:
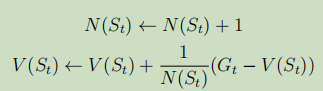
对于一些实时或者轨迹条数难以准确估计的情况下,可以将(1/k)用一个系数来代替,这个
就叫学习率。
![]()
增量式计算表明:这是个软更新过程,即V通过学习率,一点一点靠近目标G的过程。而V本身就是G的估计值,因此轨迹条数越多,V的估计结果越精确。
另外要补充一点:我们发现,也许一条轨迹中同一个状态会多次出现,那么根据收获的定义,其值和另一个同轨迹的同状态的收获不一致。根据要不要将同轨迹同状态的多个收获加入到均值计算中,MC的策略评估学习分为首次访问MC评估和每次访问MC评估。
3.1.2、时序差分学习(TD):
物理意义:


TD学习中的策略评估是指在序列不完整的情况下,通过引导,先估计序列完整时的收获,然后通过不断采样,每一次采样完后就用上述累进更新平均值的方式更新状态的值函数。
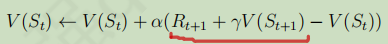
如上图所示,就是TD学习的策略评估,TD用![]() 去代替了MC学习中的收获。其中
去代替了MC学习中的收获。其中![]() 称为TD目标值,
称为TD目标值,![]() 称为TD误差。
称为TD误差。
根据增量式学习,每次只需记录当前轨迹的TD目标值。
引导:用TD目标值代替收获的过程。
小结:MC和TD学习中策略评估都是根据采样的一系列轨迹来更新状态值函数。
MC和DP的差别:


小结:
1、DP每次都要更新所有状态,MC每完成一条轨迹后更新轨迹中出现的状态,当状态数很多时,DP相对更加耗时。
2、DP是model-based,MC是model-free。
MC和TD的差别:

小结:
1、MC将当前轨迹的收获Gt当做目标值,在完成一条轨迹后,计算真实的收获来更新状态价值。
2、TD每走一步就更新一下状态价值。
3、TD可以在知道结果之前就学习,而MC要在知道结果后才学习,因此TD学习更加快速。
接下来用2个例子来进一步加深理解MC和TD的差别:
例1:
假如Agent要下班回家,在回家途中会遇到6种不同的状态,要经过取车、高速、非高速、街区路面等路况。正常情况下,Agent估计30mins就能回家;取车时下雨,道路湿滑,Agent根据过往的经验,估计再过35mins就能回家;驶离高速的时候,路上很顺畅,Agent估计再过15mins就能回家;来到非高速路面,被卡车挡在了前面,Agent估计还要10mins才能到家;开到家附近的时候,Agent估计再过3mins就能到家;最后是终于到家了。下表是Agent根据往常的轨迹得出来的各个状态的价值,为了对各个状态的预估时间更加精确,Agent还需要继续尝试各种路况来更新各个状态的价值,即各个状态下的仍需耗时。接下里分别采用MC和DT进行策略评估(即求值函数)。
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | ||||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
MC&TD:
MC的更新方式,是经过完整的序列之后,再更新每个状态的值函数,即回到家才会进行更新,为了表现这个过程,每个状态的更新我都用一张表来表示:
TD的更新方式,是每经过一个状态,都会用后一个状态的耗时来更新当前状态的耗时,为了表现这个过程,每个状态的更新我都用一张表来表示:
当离开办公室的时候,按照既往经验估计,状态值函数表如下:
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | ||||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
TD按照既往经验对下个状态的估计开始更新当前状态的价值。
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
当取车时下雨:
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | ||||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取车时下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
驶离高速:
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | ||||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取车时下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 驶离高速 | 20 | 15 | 35 | 20 | 40 | ||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
跟在卡车后:
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | ||||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取车时下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 驶离高速 | 20 | 15 | 35 | 20 | 40 | ||||
| 跟在卡车后 | 30 | 10 | 40 | 13 | 43 | ||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
家在附近街区:
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | ||||||
| 取车时下雨 | 5 | 35 | 40 | ||||||
| 驶离高速 | 20 | 15 | 35 | ||||||
| 跟在卡车后 | 30 | 10 | 40 | ||||||
| 家在附近街区 | 40 | 3 | 43 | ||||||
| 返回家中 | 43 | 0 | 43 | ||||||
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | 40 | 40 | ||||
| 取车时下雨 | 5 | 35 | 40 | 30 | 35 | ||||
| 驶离高速 | 20 | 15 | 35 | 20 | 40 | ||||
| 跟在卡车后 | 30 | 10 | 40 | 13 | 43 | ||||
| 家在附近街区 | 40 | 3 | 43 | 3 | 43 | ||||
| 返回家中 | 43 | 0 | 43 | ||||||
返回家中,可见MC是在整个流程结束之后再更新各个状态的价值,最后的结果基本上相差不大:
| 状态 | 已耗时(mins) | 既往经验预计 | MC更新(α=1) | TD更新(α=1) | |||||
| 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | 仍需耗时 | 总耗时 | ||||
| 离开办公室 | 0 | 30 | 30 | 43 | 43 | 40 | 40 | ||
| 取车时下雨 | 5 | 35 | 40 | 38 | 43 | 30 | 35 | ||
| 驶离高速 | 20 | 15 | 35 | 23 | 43 | 20 | 40 | ||
| 跟在卡车后 | 30 | 10 | 40 | 13 | 43 | 13 | 43 | ||
| 家在附近街区 | 40 | 3 | 43 | 3 | 43 | 3 | 43 | ||
| 返回家中 | 43 | 0 | 43 | 0 | 43 | 0 | 43 | ||
小结:
1、从这个例子我们可以得出,TD在策略评估时,每经过一个状态,都会用下个状态的预估计值来更新当前状态的值函数。而MC则不同,它是在一个完整状态序列结束后,再去更新各个状态的值函数。
2、可见TD的更新速度更快。
3、TD可以在不知道结果下学习,或没有结果下学习,还可以在持续进行的状态中学习。
4、TD学习是用TD目标值,即离开当前状态时的奖励+下个状态的预估价值V(s')来代替当前状态在序列结束时可能的收获,TD目标值的样本均值是当前状态价值的有偏估计(有偏估计是因为TD目标值中下个状态的预估计值使用的也是后续状态的待评估值)。而MC是用真实收获来作为目标值,真实收获的样本均值是当前状态价值的无偏估计。(估计量的期望等于总体的期望(总体的均值),则估计量为总体期望的无偏估计,如样本均值就是总体期望EX(总体均值)的无偏估计)

关于有偏无偏估计,可参考:什么是无偏估计? - 知乎 (zhihu.com)
5、TD学习比MC学习有更低的方差。期望就是平均值,我们可以用样本均值来估计期望,即约等于,且样本数N越多,样本均值越接近于平均值(大数定律)。样本均值是总体的无偏估计。
6、value-based方法的值函数主要用TD 或 MC 来估计。用 TD 比较稳,用 MC 比较精确。
MC比较精确是因为稳定MC直接使用衰减G为Q估计值的更新目标。而TD用的是G的替代版r+Q(s'),当迭代次数无限大的时候,两者才相等,否则只能说接近G。
TD比较稳是因为TD的方差小,MC的方差大。因为MC使用G为目标,而G这个值是不稳定的,对同一个s,采用动作a,产生轨迹的G=100,有时候G=-10。故Q的更新是不稳定的。为了解决这个问题,可采用G的期望来解决,G的均值相对而言会减小这种方差大的不稳定性,而恰好Q就是G的期望。而我们当初在做TD的时候,把G=r+γ*Gt+1中的Gt+1换成Q(s')这个操作使得MC不稳定(方差大)的问题得到了解决。
7、TD结合MC和DP,使用MC的增量式格式,使用动态规划方法来提高采样的效率,即从状态 s 开始的总回报可以通过当前动作的即时奖励 r(s,a,s') 和下一个状态 s's的值函数来近似估计。
例2:

如上图所示,目前采样了8条完整序列,除了第一条有2个状态的转移以外,其余7条均只有1个状态。求A、B的值函数(本例假设忽略策略、动作):

从题目中可知,状态A一定会转移到B,且状态B有75%的概率会获得奖励1,25%概率获得奖励0,因此TD相当于构建了一个MDP过程,如下图所示:

TD算法试图构建一个MDP过程(S A P R ),使得这个MD尽可能符合当前的采样序列。具体的,TD会根据采样序列得出状态转移概率P和奖励函数R:

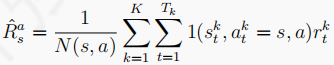
然后计算该MDP的状态值函数。
而MC是根据真实收获来计算状态值函数,通过不断缩小真目标与状态值函数的差来达到目标。
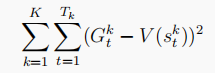
小结:TD算法适用于马尔科夫环境下,MC不限于马尔科夫环境下。
DP、MC、TD三者差别:

Note:bootstrapping(拔靴自助):就是用估计去估计另一个估计值。



上图三者分别是DP、MC、TD的更新价值函数的方式,DP是广度的极端,MC是深度的极端,TD是介于DP与MC之间的方式。

上图说明了DP、MC、TD、穷举四种方式的关系:
TD在广度上扩展就是DP,TD在深度上扩展就是MC,TD同时在深度和广度上扩展就是穷举。
3.1.3、
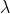 时序差分学习TD():
时序差分学习TD():
一般的时序差分学习是每走一步,就更新价值函数,即TD(0),那么我们还可以推广到1步、2步。。。。。


如上图所示,当步伐为inf时,TD就变成了MC,当n=1时候,TD就变成了TD(0),那么是否存在一个n,使得其兼具TD和MC的优点呢?
这个n是个超参数,需要根据不同问题去制定这个值。
为了综合考量不同步的收获,引入参数,定义
收获为(
是个介于0-1之间的数):
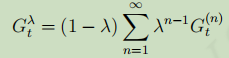 ,对应的更新公式为:
,对应的更新公式为: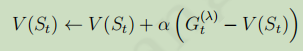
n步收获的权重为:

下图这是TD()的权重分配的示意图,图中横坐标是n,每个横坐标值代表着ni步,对应着第ni步收获的权重,他这里呈现的是将步连续化了,而实际上步是离散的,因此每一步的权重是面积,而不是单个纵坐标的值,显然所有面积之和就是1(可证明该无穷级数收敛至1)。当n=T的时候,这时候的TD(
)就是MC,为了保证收敛至1,那么剩余的那些未分配的权重将会继续以MC的方式呈现,但后续的MC权重会继续按指数衰减并且最终奖励值前的γ值也会衰减。

前向TD(

可以看出,前向TD就是我们上述所说的TD()
反向TD()是通过引入效用迹ES来实现单步更新。
首先引入效用的概念,效用E表示该状态对后续状态的影响,所有状态的效用E总称为效用迹ES
定义:(1为真值表达式)

从定义中看出:
①:当前时间t状态s的效用取决于上个时间段状态s的效用以及当前经历的状态是否为状态s。
②:不管当前经历的状态是谁,每个状态都会进行更新。
③:最小值为0。
E的性质分析:


反向TD()就是将效用加入到值函数更新中去:
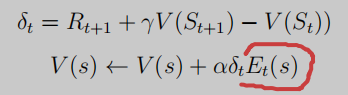

上述是对于V而言的,那么对于Q值呢?其实也是一样的,TD目标值可以用V表示,也可以用Q来表示,故前向反向的TD算法只是换个值函数罢了,但由于Q值仅仅比V多了个动作,故效用计算那里的真值判断需要多个动作a。

有了关于Q的反向TD,我们就可以导出Sarsa()算法:划红线得是比前向Sarsa(0)增加的地方,其余并无差别。

需要注意的是,每次更新都要回去遍历并更新每个状态动作对的值函数以及E值,这里就很明显感受到了反向的思想。但是TD error还是用到本回合的(S,A),注意大小写的区别。
Sarsa和Sarsa(
联系:都是步进更新的on-policy算法
区别:Sarsa是TD(0)算法,每次只更新当前动作对(S,A)的Q值,只根据后一个值函数进行更新。
而反向Sarsa是TD(
每次都会对当前动作对(S,A)以及序列遍历过的动作值函数进行同时更新。其次,反向TD存在E表,他相当于是一个记忆库,整个E表就是效用迹,记录了曾经某个经历的(S,A)对后续动作值函数的影响。其结合频率启发与就近启发的作用。(频率启发就是当前的状态取决于过去发生次数多的因素。就近启发是当前的状态受最近几次发生的影响。)
Sarsa(另外新的eipisode开始的时候,Q还是存在,E却要清零,根据两者的定义,这也是可以理解的。
3.2、model-free的控制问题(重点放在MC、Sarasa、TD):
在model-based中,我们采用策略迭代和值迭代的方式去寻优:
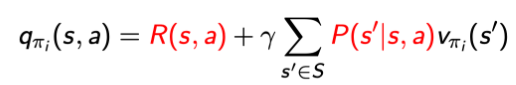
但MC和TD是基于model-free的方式,即不知道环境中的P和R,因此不能使用上述方法去求解。
model-based中的贪心策略也无法再使用,为什么呢?
因为MC、TD算法都是在采样有限次下、遍历状态数有限下进行的策略评估,因此会有存在一些实际存在高价值得状态但未被搜寻到的,以及一些低价值的,因为遍历次数少,所以价值估计不准确。如果仍采用贪婪策略,那么这两种情况的状态将被忽视,低价值遍历少的那些状态将无法被提高(最优策略下每个状态的值函数必定达到最高),因此就无法形成最优策略。model-based可以使用贪婪策略是因为动态规划考虑到了所有的状态。
因此,还需要引入-greedy策略,就是之前提过的奶茶店的例子,在这里我们重新再说明一下,如下图所示:

这个策略就是贪心策略和均一策略的一个trade-off,其中这个是用于选择均一策略的概率,在一开始的时候,Q表被初始化为全0,因此需要较大的探索,即
较大,随着采样的进行,各个状态动作对的价值也摸得差不多了,就逐渐减小
,更加注重利用。
如下图所示,当使用MC和-greedy策略时,和DP中一样,我们确保值函数是单调递增的,证明如下:

还有一个关于on-policy和off-policy的概念:

那么MC和TD用什么方式去解决控制问题呢?
在说明之前,由于DP中最后求出最优策略都需要用状态值函数转换成Q函数,然后得出最优动作,那是因为有P和R,而MC和TD没有直接用于转换的P和R,因此在TD和MC中我们直接采用动作状态值函数(以下简称Q函数),而不再使用V去更新价值。
现实策略MC中策略迭代的伪代码如下:

与DP中类似,只是换了一种方式更新值函数,同理,MC学习可以收敛至最优,获取最优状态动作值函数。
MC策略迭代出最优策略,必须要满足GLIE条件(Greedy in the limit with the infinite exploration),即:
1、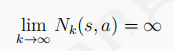 :每个状态动作对都被无限次访问到,意味着采样次数多,那么Q和目标target就能无限接近。
:每个状态动作对都被无限次访问到,意味着采样次数多,那么Q和目标target就能无限接近。
2、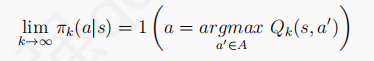 :策略最终趋向于贪婪策略,借鉴MDP中最优策略的产生是使用了纯贪婪策略,当探索到一定的时候,
:策略最终趋向于贪婪策略,借鉴MDP中最优策略的产生是使用了纯贪婪策略,当探索到一定的时候,最好为0以保持纯贪婪策略。
满足GLIE条件,MC才能收敛至最优策略: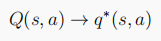
在MC的控制问题中,Q同样也不是单调递增的,例如,根据MC算法,s状态是走向终点经过的一个状态,从Q(s,)开始,走到终点,最后计算G1,Q(s,a1)通过软更新靠近G1=100,由于ε=1/k,接下来策略改变了。比如说从Q(s,)开始,走到终点,最后计算G2,Q(s,a2)通过软更新靠近G2=10。本来在状态s,他会随机性探索每个动作,当贪心策略出现的时候,他就会选择动作a1,因为a1产生的G更大。但就算是从a1这个方向走出去,在通向终点的路上也会出现岔路口,就会出现不同的G(由于这时候不同的G可能相差很大,即方差很大,所以Q(s,a1)的更新就会不稳定)。这时候贪心策略的出现就会摆脱Q(s,a1)跑来跑去的状况,他会选择G最大的那个岔路口,然后让Q(s,a1)慢慢一步步增大至最大那个G。这就是贪心策略增大Q值的原因。不过这只是局部最大,当探索足够深的话,最终会找到全局最大,也就是属于Q(s,a1)的最优值函数。
Sarsa算法:on-policy TD算法:
Sarsa算法就是将TD(0)中的状态值函数改成了Q函数。

如何理解这个公式呢?
用后一个状态动作值函数来更新当前的状态动作值函数。
为什么用R(s,a) + * Q(s',a')来作为目标值呢?
TD算法结合了MC和动态规划的思想。在MC中,我们用G的样本均值去估计Q,用Q去逼近G,这在TD中行不通,那是因为TD基于不完整序列,他并不知道未来收获具体值,因此G是未知的。那怎么办呢?那就得找人代替G的位置。我们的初衷是想让G的样本均值去估计TD的Q(s,a),然后以软更新的方式让Q(s,a)去逼近G,接下来我去就要去找新目标T,这个T虽然不完全等于G,但也逼近于G。接下去仔细看G=R(s,a) + * G'这个式子,R(s,a)是环境给的,我们动不了,那只能动G’了。想一想我们的最终目标是让Q(s,a)去逼近G,那Q(s',a')不就逼近G'了吗,那只需要把G‘改成Q(s',a')不就行了吗。因此G的替代品就是R(s,a) +
* Q(s',a'),但由于一般Q表初始化均为0,故刚开始R(s,a) +
* Q(s',a')并不能准确代替G的大小,也就是说R(s,a) +
* Q(s',a')的样本均值是Q(s,a)的有偏估计,有偏bias是不好的。
那如何才能变成无偏呢?或者说R(s,a) + * Q(s',a')啥时候较为准确的能代表G呢?
想一下,当某一次探索走到最终状态,只有终止状态前的最后一个状态的R(s,a) + * Q(s',a')才是准确的,因为终止状态的R(s,a) +
* Q(s',a')就是它本身的收获R(s,a),而中止状态的G就是R(s,a),这个值一定是准确的,那么倒退回去,终止状态前的最后一个状态的R(s,a) +
* Q(s',a')也就是准确的,通过软更新来拉近不准确Q与目标的差距,此时的Q也算得上是个比较准确的评估值,然后接下来的episode中,可以将刚才那个状态看成终止状态,以类似的方法得出,到达这个“终止状态”前的Q也算得上是个比较准确的评估值了。然后用这种方式慢慢倒退回去,经过许多许多个epoch之后,每一个状态的Q都算得上比较准确的评估值了,那么他当别的状态的Q(s',a')的时候。其实这个是动态过程,每个状态的Q在从后往前不断成为更加准确的评估值的同时,后面那些很早就到达一定准确度的Q又通过软更新的方式不断精确化自身,向着G逼近,意图完全代替G的位置。显然,到达一定的程度,这些Q的值就会收敛到稳定的值,即R(s,a) +
* Q(s',a')的样本均值最终成为Q(s,a)真实值的无偏估计,Q(s,a)也接近它的真实值。这就是一整个策略评估过程。
Note:
1、我们这里最后算出来的Q(s,a)并不是Q的真实值,我们只能通过软更新无限逼近TD目标值,而TD目标值在最后收敛的时候是Q真实值的无偏估计,因此我们实际算出来的Q只能说无限接近Q真实值。另外Q本身的定义就是收获的期望值,是一个估计值,不完全等于收获,是收获的均值。
2、到了DDQN的时候,该论文的作者就会提出,在Q-learning中,其实最后稳定的Q(s,a)并不是像我们理论上接近R(s,a) + * Q(s',a'),而是高于它,即过估计。
3、就是因为GILE的原因,才会出现上述Q(s,a)越来越靠近真值的现象,Q(s,a)由小慢慢变大至收敛到最优,为什么能收敛呢?因为Q = EGt<EGt(无衰减)=Gt(无衰减),Gt(无衰减)是个常数,因此值函数是有上限的,不会倒无穷大。
4、从上面的分析也可以看出:TD算法其实是基于值迭代的方式求出最优路径,而MC是基于策略迭代的方式。理论上,值迭代会让每一个状态的值直接到达最大,但是TD对环境陌生,需要用随机性策略去探索,Q-lerning是用2个策略相互靠近的方式达到确定性策略,确定性策略本身在值迭代过程中是最为最后一步去求出最优策略的,并不适用于加大值函数,但是在TD中,由于TD是以学习率α慢慢靠近的,用确定性策略可以加大Q值,从而加快收敛到最大值的速度,即加快了收敛,具体来说,如下图所示:
 ,在TD中,显然对于S'下的几个动作状态值函数都已经接近了最大值(因为离终点很近),根据确定性策略即一般说的贪心策略,Q(s,向下)就会采用S'的几个最大值中的最大值+r来作为靠近的对象,最终Q(s,向下)就会达到他的最大值,即最优值函数。要是不用贪心策略,那么Q(s,向下)至少没这么快到达最优值函数。
,在TD中,显然对于S'下的几个动作状态值函数都已经接近了最大值(因为离终点很近),根据确定性策略即一般说的贪心策略,Q(s,向下)就会采用S'的几个最大值中的最大值+r来作为靠近的对象,最终Q(s,向下)就会达到他的最大值,即最优值函数。要是不用贪心策略,那么Q(s,向下)至少没这么快到达最优值函数。
5、对于Q值,不能像V值一样保证单调递增,但是随着探索的加深,遍历状态越来越多,到达终点次数越来越多的时候,Q值就会越来越接近其执行动作a(这里指的是状态s的所有动作)后能取得的价值Gt(带γ的)。
6、在一个策略π下,Gt的平均值是Q真实值的无偏估计,随着值迭代,导致策略逐渐优化成最优策略的过程中,策略π虽然一直在改变,但是Gt的平均值是Q真实值的无偏估计这句话一直是对的,Gt的平均值造就了Q真实值,这个值不一定是最优Q真实值,随着Gt的逐渐max化以及单一化,Q真实值也就成了最优Q真实值,也就是Q估计值的最终目标。唯一改变的就是方差,且最优策略的方差更小。
7、Q值不一定单调递增,也不一定总体递增。得看具体环境,但是最终会稳定下来是确定的。寻路问题,他就是总体先下降然后再上升。比如其他环境,上图的6种游戏,那它就是逐渐上升。此外,最终的最优Q值不一定从头到尾都是几个动作中的最大。
8、一定要分清楚,哪怕ε-greedy中含有贪心策略,但他只是用于探索,而不是将Q值增大化。Q值的增大(优化)来源于其目标策略。

Note:
1、由于值函数的更新需要用到当前状态s,执行动作a,然后获取奖励r,下一个状态s',下一个状态的执行动作a',因此连起来可叫Sarsa。
2、可以看出行为策略和目标策略是一个策略,因此Sarsa是on-policy的。
Sarsa算法伪代码如下图:

Sarsa收敛至最优策略的条件:满足GILE条件,并且学习率α满足:
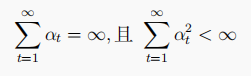
Sarsa()算法:

Sarsa()伪代码如下:

Q-learning算法,off-policy算法:

借鉴策略就是我们的目标策略,在Q-learning中就是贪心策略。这个比值(重要性采样权重)的作用就是,比如说,我们行为策略和我要借鉴学习的目标策略不符(Q-learning中不符就是小于1),说明此时还没收敛,那么就少更新点,且越大,我们更新越多。
但是我们的Q-learning不需要重要性采样。具体见https://www.zhihu.com/question/302634995
为什么V-learning需要importance sampling,而Q-learning不需要?关于IS,具体可见我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/112134708
我的分析如下:
首先,importance-sampling是针对于2个不同策略分布而言的,即适用于off-policy算法,
因为V对于动作的选择是不确定的,如上图公式所示,行为策略在状态S选择了动作A,在更新的时候,如果像Q-learning更新公式那样不用IS修正因子的话,V值的更新不一定正确,
因为V值是无法选择动作的,即按照行为策略的分布的话,估计出来V的值会造成很大的bias(其实这个更新公式可以看成是TD目标值的样本均值来估计V)。因此必须要引入新的分布,即目标策略
来加以修正,具体如上分析所示,如果修正因子大于1,说明动作A得到了目标策略的支持,那么就朝着这个方向做出正确的更新,confidently!,如果小于1,说明当前动作并不符合目标策略的
支持,那么就少更新点,少犯点错。
然后再谈为啥Q-learning避免了重要性采样呢?
Q-learning算法在行为策略选择了动作A,这和V-learning一样,这里没问题。接下来,更新的时候,Q-learning会用贪婪策略,即目标策略来选择正确的动作,让Q值向着这个最优动作方向更新
因此,不用担心更新的方向会出现错误,即不用修正了。
其中off-policy的代表就是Q-learning算法。
Q-learning和Sarsa不同,这是一种借鉴策略学习算法,其行为策略为-greedy策略,用于与环境交互产生动作,目标策略为贪婪策略,用于更新Q表实现最优策略。
Q-learning算法的Q表按如下更新: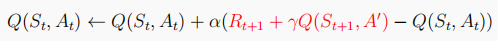 ,
,
其中A'来自于贪婪策略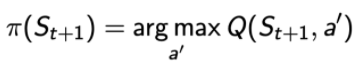
将上面个式子合成一个式子:
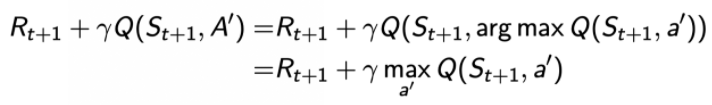 ,
,
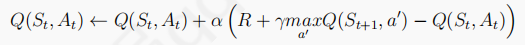
Q-learning算法的伪代码如下:(这部分更完整的分析在我的另一篇实战中:https://blog.csdn.net/MR_kdcon/article/details/110648885)
从上述代码中我们可以得出Sarsa月Q-learning的不同之处:
1、Sarsa产生的A'在优化完成后的下一步一定也会被执行,而Q-learning用于更新Q表的A'在下一个step不一定会被执行,因此执行策略是
-greedy策略,可能会产生随机动作。
2、Sarsa用同一个策略产生了样本<s,a,r,s',a'>,然后用s'和a'去更新Q表,而Q-learning只需要知道<s,a,r,s'>,不需要知道a'是什么,只要取argmaxQ(s')那个动作来更新Q表。
3、在寻找最优路径中上,Q-learning可以表现的比Sarsa更好,或者说Q-learning比Sarsa更快找到最佳路径,以悬崖寻路问题为例,掉进悬崖奖赏-100分,到达终点0分,其余每一步-1分,如下图所示,当
分析:
如上图所示,我截取了前面几个状态来分析Sarsa和Q-learning在选择路径上的不同之处。(α=-0.5,
=1)
首先对于Sarsa:
如上图伪代码所示:
1、在S0时,根据
2、获得s'=S2,R=-1,根据
3、获得s'=end,R=-100,更新Q(S2,向下)=0+1/2*(-100+0-0)=-50,s=end,重新启动。
4、在S0时,根据
5、获得s'=S2,R=-1,根据
。。。
换一种探索方式:
6、在S0时,根据
7、获得s'=S3,R=-1,根据
其次对于Q-learning:
1、S0,根据
2、根据
3、根据
4、S0,根据
5、根据
换一种探索方式:
6、S0,根据
7、根据
.。。。重新启动
8、S0,根据
9、根据
从上面段分析我们可以得出:
1、Q-learning,在已知Q(S2,向下)很小的情况下,在S1时,若选到了向右动作a(行为policy),和环境交互产生s'和R,然后呢目标policy将根据s'产生具有最大动作值函数对应的动作a',而a与a‘并没有直接关系,即目标policy和行为policy独立,Q(S2,向下)这个糟糕的值(很小)一定不会影响到Q(S1,向右)。
2、而Sarsa,在已知Q(S2,向下)很小的情况下,在S1时,执行向右(行为policy),由于行为policy和目标policy是一体的,若接下来行为policy在S2选中向下,则目标policy跟着完蛋,即行为策略要是不好,会直接导致目标策略不好,从而使得值函数的评估出现问题,比如此时Q(S2,向下)会直接影响到Q(S1,向右)大幅下降。Q(S1,向右)大幅下降,直接导致了Q(S1,向上)>Q(S1,向右),因此只有在
3、同理,对于后续情况,Sarsa还是会采取避开悬崖边的方案。



Q-learning较于Sarsa的好处:
1、能更快速的找到最优策略。
2、行为策略是用于探索环境,采集状态,理解环境的策略,因为Q-learning的行为策略和目标策略独立,行为策略并不影响目标策略,因此只要某个行为策略可以用于探索环境,则都可以充当Q-learning的行为策略,故Q-learning可以学习别的Agent的行为、老的策略产生的轨迹(探索过程需要很多计算资源,这样可以节省资源)。
3、随着的逐渐减小,双方都收敛至算法层面的最优策略,但显然Q-learning的才是真的最优策略,所以Q-learning更符号RL的目标。
Q-learning收敛的条件:
1、根据![]() 可知,St根据行为策略确定的行为价值将朝着S'状态下贪婪策略确定的最大行为价值的方向做一定比例的更新,因此行为策略将逐渐靠近目标策略。但在实际操作过程中,比如ε-greedy策略,我们还是要手动去衰减ε的值,让2个策略相互靠近。
可知,St根据行为策略确定的行为价值将朝着S'状态下贪婪策略确定的最大行为价值的方向做一定比例的更新,因此行为策略将逐渐靠近目标策略。但在实际操作过程中,比如ε-greedy策略,我们还是要手动去衰减ε的值,让2个策略相互靠近。
2、其次,该算法也可以遍历足够多的状态。
3、学习率α满足
综合1、2、3,Q-learning满足GILE条件与学习率条件时,必定收敛至最优策略及最优值函数。
Part4、值函数近似
前面part3中我们用Q表来实现model-free中规划问题的预测和控制,将Q函数定义成一张Q表,用二维数组来存储,index是状态,column是动作。这种Q表最大的局限性就是当RL问题的状态行为数过多或者动作连续的时候,就失效了,尤其当状态数贼多的时候,Q表的存储空间以及搜索速度都是欠考虑的,因此必须要引入值函数近似来代替Q表。
值函数近似:就是引入参数W,选取特征,通过构建一个线性(或非线性)函数去近似求出状态(状态动作)值函数。这样一来,规划的预测和控制问题都将转变成参数的优化求解问题。
常用值函数近似:线性拟合、神经网络
基本原理:采用梯度下降法最小化误差: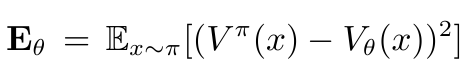
基于单样本的更新: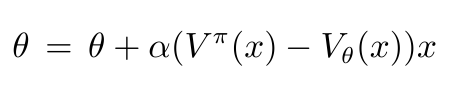 (目标函数是期望,因此多样本的更新可通过采样多个样本x,用MSEloss实现)
(目标函数是期望,因此多样本的更新可通过采样多个样本x,用MSEloss实现)
三种求解价值函数的架构:

TD中价值更新:
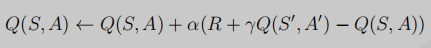
值函数近似中价值更新:
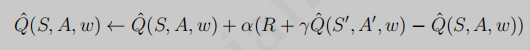
但上述值函数近似很难实现,但我们可以通过定义loss function,然后通过梯度下降完成策略评估。
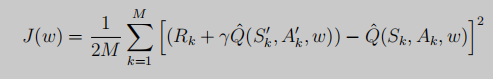
用Q-target来表示:
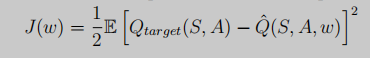
Part5、DQN:
DQN(Deep Q-Network) 是强化学习与深度学习的一个结合,即将Q-learning算法与深度网络进行联合,从而让智能体agent进行学习。DL为agent提供学习的大脑,RL提供了计算机制,从而达到真的AI。
5.1、DQN提出的原因:
Q-learning算法,使用Q表来存储动作状态值函数,通过不断尝试来更新Q表,最终达到收敛,找到了最优策略。但是其缺陷在于Q表的容量和搜索范围,当一个任务的状态数目贼多,比如围棋、图像,那么对Q表的存储量是个考验,此外,搜索也是个问题。另一方面,若任务的状态值是个连续值,比如接下去的小车位置、速度,Q表是不够用的。因此需要用值函数近似的方法,用一个非线性函数去拟合动作状态值函数,达到升级版Q表的角色。拟合这件事neual network就很擅长,输入是个状态,输出则是状态对应的各个动作的值,这不就相当于是Q表了吗,这就是通过nn来做值函数近似,并且nn不怕你输入繁多的状态,也不怕你输入是连续值,故Q-learning将Q值存储的方式改成神经网络,那么DQN初步就形成了。当然DQN强大的原因,并不在于此。
5.2、DQN算法(Nature DQN):
5.2.1、算法:
首先来一波论文率先提出的伪代码:(下图是2013年提出的第一代NIPS DQN,2015年在原有基础上增加了Target-Q-network,就是下面翻译部分)

翻译一下:(2015年Nature DQN算法)
1、初始化参数N(记忆库),学习率lr,贪心策略中的
,衰减参数
,更新步伐C
2、初始化记忆库D
3、初始化网络Net(本实验选择一个2层的网络,其中隐藏层为50个神经元的FC层),将参数W和W_指定为服从均值为0,方差为0.01高斯分布,并例化出2个相同的网络eval_net(以下简称Q1)和target_net(以下简称Q2)。
4、for episode in range(M):
5、 初始化状态observation
6、 for step in range(T):
7、 通过贪心策略选中下个动作action,其中Q(s, a)来自于eval_net的前向推理。
8、 通过环境的反馈获得observation'以及奖励值reward。
9、 将observation、observation'、action、reward打包存入记忆库D中。
10、 当记忆库存满之后,抽取batch个大小的数据(sj, sj', aj, rj)送入2个网络中
11、 以损失函数L = *
( rj +
* max(Q2(sj';W_)) - Q1(sj,aj;W))^2 进行训练
12、 每隔C步,更新target_net的参数W_ = W
下面这张博主画的图可以很好实现上述的伪代码过程:

Note:
1、target_net是不需要参加训练的,其参数的更新来源于eval_net的复制。
2、探索率要随着迭代进程不断减小,以到达收敛至最优策略的效果。
5.2.2、DQN强大的原因:
5.2.2.1、引入经验池:就是用一个二维数组将过去的样本存储起来,这个过去的样本包括不同不同episode的样本,包括不同策略的样本(ε一直在变),供之后网络训练用,具体来说,经验池的引入:
a、首先Q-learning为off-policy算法(异策略算法,Sarsa为同策略,on-policy算法),也就是说,其生成样本<s,s_,r,a>的策略值函数更新的策略不一样,生成策略是-greedy 策略,值函数更新的策略为原始策略。故可以学习以往的、当前的、别人的样本。而经验池放的就是过去的样本,或者说过去的经验、记忆。一方面,和人类学习知识依靠于过去以往的记忆相吻合,另一方面,随机加入过去的经验会让nn更加有效率。
b、其实在做RL的时候,往往最花时间的 step 是在跟环境做互动,train network 反而是比较快的。因为你用 GPU train 其实很快, 真正花时间的往往是在跟环境做互动。用 replay buffer 可以减少跟环境做互动的次数,因为在做 training 的时候,你的 experience 不需要通通来自于某一个policy。一些过去的 policy 所得到的 experience 可以放在 buffer 里面被使用很多次,被反复的再利用。
c、在训练nn的时候,其实我们希望一个 batch 里面的 data 越分散越好。如果你的 batch 里面的 data 都是同样性质的,这样的训练是容易坏掉的。如果 batch 里面都是一样的 data,训练的时候,performance 会比较差。我们希望 batch data 越 diverse 越好。那如果 经验池里面的那些 experience 通通来自于不同的 policy ,那你 sample 到的一个 batch 里面的 data 会是比较分散的 。
d、打乱样本之间的时间相关性。回顾nn中输入样本之间是无关的(除了RNN比较特殊),随机性抽取有利于消除输出结果对时间连续的偏好。
e、每次抽取batch个数据正适合nn的前向和后向传播。
5.2.2.2、引入Target-Q-network
a、这个网络的输出通过取max,乘以,加上reward,作为标签y。这是由于Q-learning是值迭代算法,r +
* max(Q2(s_,a')是target Q,与Q-learning一样,DQN用这个作为标签,让Q(s,a)去无限接近标签,从而找到最优策略。
b、延迟更新网络。第一代的NIPS DQN是和Q(s,a)同时更新的,这就使得算法的稳定性降低,Q值可能一直就靠近不了target Q。就如猫捉老鼠的栗子一样:



但也不能不变,比如Target-Q-network刚初始化后,其产生的Q(s',a')是不准确的,就像Q-learning中Q(s',a')由于刚开始时候,也不住准确,都是0,但接下去会不断更新Q表,一段时间后,下一尝试同一个Q(s',a')出现时,此时Q(s',a')已经更新了,从第0次尝试->收敛过程中,Q(s',a')一定是在不断更新,从0到最优值。因此Target-Q-network中的网络参数不能一尘不变,一段时间后,也需要更新。
c、另外,回顾下监督学习中,标签是个不随网路参数W变动的值,因此,一定时间内,需要维持不变,既为了稳定,又为了符合监督学习的特性。
5.3、DDQN:
用于解决Q-learning和DQN中Q值被过高估计的问题。
5.3.1、DDQN提出的原因:

如上图所示,提出DDQN的作者发现DQN算法会导致Q-eval-net的结果Q值被过度估计,也就是说通过这个网络出来的Q值比真实Q值要高出很多。
上图是论文中基于游戏Atari的实验:
1、用训练好的policy在游戏中不断积累R,然后求取平均值来计算DQN和DDQN的Q(s,a)真实值true value(而且是最优值函数)。
2、2条不同颜色的曲线是DQN和DDQN在训练时,从Q_eval网路中输出的Q值,不断变高是因为随着迭代加深,策略在优化,值函数在变大,最后趋于平稳说明达到收敛。
3、如果没有过高估计的话,训练到收敛之后,Q(s,a)应该是和真实值true value是无限接近的。

如上图所示,Wizard of Wor和Asterix这两个游戏中,DQN的结果比较不稳定。也表明过高估计会影响到学习的性能的稳定性(DDQN打电动显然更强)。因此不稳定的问题的本质原因还是对Q值的过高估计。
5.3.2、产生过估计的原因:

根本原因就是从Q-learning延续到DQN一直存在的->TD目标值中取max操作:
TD目标值:![]()
Q-learning(DQN):![]()
以DQN为例,如上图所示,假设Q表中Q(s',a')的四个值相等,对比DQN采用值函数近似,TD目标值的产生是通过Target-neural-network产生的,因此其值会上下有所波动,通过取max操作后,DQN的目标值变成了过大的那个柱子。
根据公式 ,Q(s,a)通过软更新靠近TD目标值,而TD目标值现在已经偏大,故Q(s,a)的结果也会偏高。
,Q(s,a)通过软更新靠近TD目标值,而TD目标值现在已经偏大,故Q(s,a)的结果也会偏高。
5.3.3、DDQN算法的改进:
DDQN在DQN的基础上,仅仅只是改变了Q-target的计算方式,其余均没有改变。
DQN:

DDQN:

即:
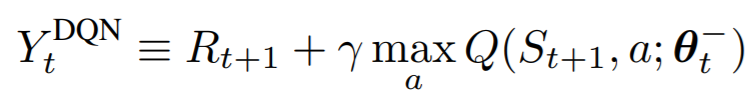
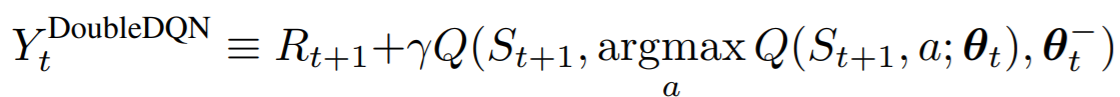
可见DDQN的好处在于:
1、当Q_eval高估了,只要Target Q不高估,结果就正常。
2、当Target Q高估了,只要Q_eval不选那个动作,结果就正常。
5.3.4、DDQN算法:
和DQN的伪代码一样,区别仅仅在第11步
1、初始化参数N(记忆库),学习率lr,贪心策略中的
,衰减参数
,更新步伐C
2、初始化记忆库D
3、初始化网络Net(本实验选择一个2层的网络,其中隐藏层为50个神经元的FC层),将参数W和W_指定为服从均值为0,方差为0.01高斯分布,并例化出2个相同的网络eval_net(以下简称Q1)和target_net(以下简称Q2)。
4、for episode in range(M):
5、 初始化状态observation
6、 for step in range(T):
7、 通过-贪心策略选中下个动作action,其中Q(s, a)来自于eval_net的前向推理。
8、 通过环境的反馈获得observation'以及奖励值reward。
9、 将observation、observation'、action、reward打包存入记忆库D中。
10、 当记忆库存满之后,抽取batch个大小的数据(sj, sj', aj, rj)送入2个网络中
11、 以损失函数L = *
( rj +
* max(Q2(sj',argmax(Q1(sj',aj';W));W_)) - Q1(sj,aj;W)) ^2 进行训练
12、 每隔C步,更新target_net的参数W_ = W
论文地址:https://arxiv.org/pdf/1509.06461.pdf
参考:https://blog.csdn.net/ygp12345/article/details/109113322
参考:https://www.cnblogs.com/pinard/p/9778063.html
参考:https://zhuanlan.zhihu.com/p/97853300
更详细的内容见我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/111245496
5.4、Prioritized experience replay:
对DQN(或DDQN)经验回放部分按权重采样来做优化。原则上采样那些TD误差值大的样本,放弃TD误差小的样本,加速网络的学习,从而加快RL收敛。
主要思想:
1、改变经验回放池的采样方式,引入SumTree(一种树结构)。
2、改变损失函数。
3、其余结构都与DQN类似。
参考:https://www.cnblogs.com/pinard/p/9797695.html
更详细的内容见我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/111245496
5.5、Dueling DQN:
目标:优化神经网络结构来优化目标。

5.5.1、主要思想:
1、将Q网络分解成价值函数子网络+优势函数子网络。价值函数子网络输出只关于输入特征(状态)的标量(对不同的状态都有一个值),因为只和状态有关,所以叫V(S);优势函数子网络输出格式和之前的Q一样(对不同状态动作对都有一个值),换个写法叫A(s,a)。
2、Q网络的输出由价格函数网络的输出和优势函数网络的输出线性组合得到: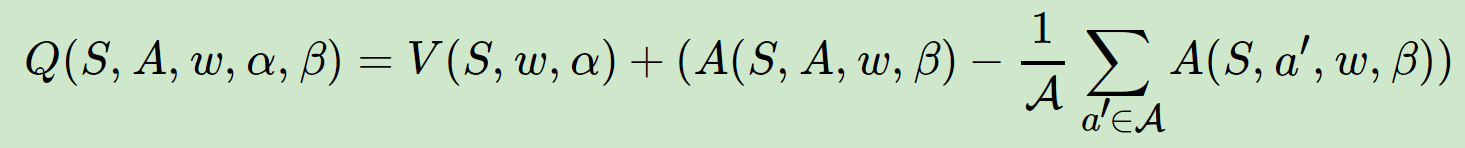
3、仅仅改变了网络结构,其余均和DQN一样,不要动。
5.5.2、Dueling DQN带来的好处:

如上图所示,假设我们将net的输出看成是一张Q表的话,Dueling DQN的网络输出端就是这么计算的。

如上图所示,假如某一次从经验池中取出来的数据只有<s1,s1',r,a0>、<s1,s2',r,a1>,而并没有采样到<s1,s2',r,a2>,根据L = *
( rj +
* max(Q2(sj';W_)) - Q1(sj,aj;W))^2 (Q2指Target网络,Q1指eval网络),只有A(s1,a0)、A(s1,a1)被训练到了,A(s1,a2)由于没有被采样故不会被训练,这是原本DQN的算法。那么Dueling的改进在哪呢?在A(s,a)的基础上增加V(S)。我们通过训练V(S),即使A(s1,a2)没有被训练,而由于V(S1)的存在,Q(s1,a2)就会有值的更新,这样其实就相当于<s1,s2',r,a2>也被采样了。其实在做RL的时候,往往最花时间的 step 是在跟环境做互动(即采样)。通过这种方式,一定程度上增加了RL的效率。那我这是只举了3个动作,当动作很多的时候,而采样的个数又不充分,那么这种只要一改所有的值就会跟着改的特性,就会是一个比较有效率的方法。
5.5.3、中心化处理
实际上的输出结构并不是像5.5.2中的简单相加,而是,这是为什么呢?
因为有一种情况下,V(S)一直都是0,那么Dueling就和DQN一样了,毫无优势可言,为了避免这种case,我们需要A进行限制。
如何限制呢?
就和上面这个绿色公式一样,将A做中心化处理,就是让A减去他的平均值,这样一来,你会发现,经过中心化后,A的每一行(即某个状态的所有动作值函数)之和为0,如下图所示:

然后你根据上图绿色公式,就会发现V的值就是Q每一行的平均值,也就是说这个平均值加上A,就是Q。
所以假设要让整个一行一起被更新。你就不会想要更新A的某一行,因为你不会想要update A,因为 A 的每一行的和都要是 0,所以你没有办法说,让这边的值,通通都+1,这件事是做不到的。因为它的 constrain 就是你的和永远都是要 0。所以不可以都 +1,这时候就会强迫network去更新 V 的值,然后让你可以用比较有效率的方法,去使用你的 data。
举个栗子:

如上图所示,原来A(s,a) = (7 3 2),先来个中心化->A(s,a) = (3 -1 -2),然后加上V=1,最后的Q就是Q=(4 0 -1)
参考:https://www.cnblogs.com/pinard/p/9923859.html
参考:第七章 Q 学习 (进阶技巧) (datawhalechina.github.io)
更详细的内容见我的另一篇:https://blog.csdn.net/MR_kdcon/article/details/111245496
5.6、还有一些可以改进的小技巧:
比如Noisy-net、Distributional Q-function、Rainbow
具体可参考:第七章 Q 学习 (进阶技巧) (datawhalechina.github.io)
实战演练6篇:
1、Q-learning实现一维二维迷宫探宝:
https://blog.csdn.net/MR_kdcon/article/details/109612413
2、Q-learning、Sarsa实现悬崖寻路问题
https://blog.csdn.net/MR_kdcon/article/details/110648885
3、Q-learning实现 gym 的有风格子世界及个体
https://blog.csdn.net/MR_kdcon/article/details/110600819
4、DQN实现平衡车立杆、小车爬坡(Pytorch):
https://blog.csdn.net/MR_kdcon/article/details/109699297
https://blog.csdn.net/MR_kdcon/article/details/111245496(这篇更完善)
5、基于 PyTorch 实现 DQN 求解 PuckWorld 问题
https://blog.csdn.net/MR_kdcon/article/details/110871917
6、Dueling DQN、Prioritized experience reply实现CartPole-v0、MoutainCar:
https://blog.csdn.net/MR_kdcon/article/details/111245496
总结:从实战效果来看,对于离散状态、动作问题,Q-learning比DQN系列的更好;对于连续状态、离散动作可采用DQN系列算法。















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









