






0.标签函数
标签函数 l : V → S l:V\rightarrow S l:V→S,表示对 G G G无序节点 V V V的一种排序,得到有序的节点序列 S S S,排序函数 r : V → { 1 , . . . , ∣ V ∣ } r:V\rightarrow \{1,...,|V |\} r:V→{1,...,∣V∣},表示对无需节点的一种编号方式。且满足:在通过 l l l得到的有序节点集合在 S S S中,排序 l ( v ) l(v) l(v)在 l ( u ) l(u) l(u)前面时,编号 r ( v ) < r ( u ) r(v)<r(u) r(v)<r(u)。
1.节点序列选择
1)根据选定的图标注函数
l
l
l对图中的节点进行排序,得到有序节点集合
V
_
s
o
r
t
V\_sort
V_sort。
2)根据
V
_
s
o
r
t
V\_sort
V_sort,以
s
s
s为步长等间隔取出
w
w
w个节点,当节点数量
∣
V
_
s
o
r
t
∣
|V\_sort|
∣V_sort∣不足以取出
w
w
w个节点时,则创建感受野值为
0
0
0作为填充。得到
w
w
w个节点的序列。
伪代码:Algorithm 1 SELNODESEQ: Select Node Sequence
2.节点邻域
1)对于选出的节点序列中的每一个节点
v
v
v,取它的
1
1
1邻域,如果自身和
1
−
1-
1−邻域的节点数目
∣
N
∣
≥
k
|N|\geq k
∣N∣≥k,则得到
v
v
v的感受野的候选,否则继续取它的
2
−
2-
2−领域等等,直到满足
∣
N
∣
≥
k
|N|\geq k
∣N∣≥k。对所有选定节点进行上述操作。
伪代码:Algorithm 2 NEIGHASSEMB: Neighborhood Assembly
3.图归一化
可以认为节点
v
v
v和它的邻域候选节点构成原图
G
G
G的子图
U
U
U,如果邻域候选节点的数目
∣
U
∣
>
k
|U|>k
∣U∣>k,则利用再次图标注函数
l
l
l对子图进行节点排序,在图归一化这个步骤中节点排序都必须满足约束:对于
∀
u
,
w
∈
U
\forall u,w \in U
∀u,w∈U, 当
d
(
u
,
v
)
<
d
(
w
,
v
)
d(u,v) < d(w,v)
d(u,v)<d(w,v)时,满足
r
(
u
)
<
r
(
w
)
r(u) < r(w)
r(u)<r(w),然后取前
k
k
k个节点作为
v
v
v真正的的邻域,并得到新的新的子图
U
′
U^{'}
U′,并对新的子图进行节点排序用来形成邻接矩阵
A
l
(
U
′
)
A^{l}(U^{'})
Al(U′);如果邻域候选节点的数目
∣
U
∣
<
k
|U|<k
∣U∣<k,则添加未连接的假节点使得
∣
U
∣
=
k
|U|=k
∣U∣=k,并对新的子图
U
′
U^{'}
U′进行节点排序用来形成邻接矩阵
A
l
(
U
′
)
A^{l}(U^{'})
Al(U′)。
伪代码:Algorithm 4 NORMALIZEGRAPH: Graph Normalization
4.求解标签函数 l l l
现在的问题是怎么得到需要的标签函数
l
l
l,标记时需要满足条件:当且仅当两个图的结构相似时,两个不同图的节点被分配到各自邻接矩阵中的相对位置相似。
可以通过最小化式(1)得到最优解
l
l
l:
l
^
=
a
r
g
m
i
n
l
E
G
[
∣
d
A
(
A
l
(
G
)
,
A
l
(
G
′
)
)
−
d
G
(
G
,
G
′
)
∣
]
(1)
\hat{l}=argmin_{l}E_{G}[|d_A(A^l(G),A^l(G^{'}))-d_G(G,G^{'})|]\tag1
l^=argminlEG[∣dA(Al(G),Al(G′))−dG(G,G′)∣](1)
但是求解式(1)是
N
P
−
h
a
r
d
NP-hard
NP−hard问题,所以通过以下方式进行简化求近似解:
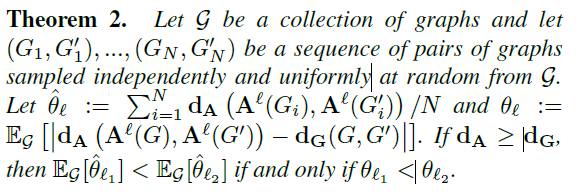
5.提取特征
设 a n a_n an为顶点特征维度, a m a_m am为边特征维度。对于每个输入图G,进行上述1~3的步骤,得到一个 ( w , k , a n ) (w,k,a_n) (w,k,an)顶点特征的张量和 ( w ; k ; k ; a m ) (w;k;k;a_m) (w;k;k;am)边特征的张量(图中 k = 4 k=4 k=4)。这些可以被重塑为一个 ( w ∗ k ; a n ) (w*k;a_n) (w∗k;an)和 ( w ∗ k ∗ k ; a m ) (w*k*k;a_m) (w∗k∗k;am)的张量。注意, a n , a m a_n,a_m an,am是输入通道的数量。现在可以用一维的卷积层,它的步幅和接受域大小是 k k k(对顶点的张量)和 k 2 k^2 k2(对边的张量)。
下图为得到的顶点和边的特征张量:

下图为对顶点张量的卷积:

6.论文中伪代码:
#Algorithm 1 SELNODESEQ: Select Node Sequence
def SEL_NODE_SEQ(graph labeling procedure l, graph G = (V,E), stride s, width w, receptive field size k):
V_sort =rank the vertices of V according to l #这里我认为是所有节点排序后的集合,不是前w个节点。
i=1,j=1
while j < w do
if i<=|V_sort|then
f = RECEPTIVEFIELD(V_sort[i])
else
f = ZERORECEPTIVEFIELD()
apply f to each input channel
i = i + s, j = j + 1
#Algorithm 3 RECEPTIVEFIELD: Create Receptive Field
def RECEPTIVEFIELD(vertex v, graph labeling l, receptive field size k):
N = NEIGHASSEMB(v; k)
G_norm = NORMALIZEGRAPH(N,v,l,k)
return G_norm
#Algorithm 2 NEIGHASSEMB: Neighborhood Assembly
def NEIGHASSEMB(vertex v,receptive field size k)
N = [v]
L = [v]
while |N| < k and |L| > 0 do
L = Union of all N_1(v_i) for v_i in L
S = Union of N and L
return the set of vertices N
#Algorithm 4 NORMALIZEGRAPH: Graph Normalization
def NORMALIZEGRAPH(subset of vertices U from original graph G, vertex v,graph labeling l, receptive field size k)
compute ranking r of U using l, subject to any u,w in U : r(u) < r(w) when d(u,v) < d(w,v)
if |U| > k then
N = top k vertices in U according to r
compute ranking r of N using l, subject to any u,w in U : r(u) < r(w) when d(u,v) < d(w,v)
else if |V| < k then
N = U and k - |U| dummy nodes
else
N = U
construct the subgraph G[N] for the vertices N
canonicalize G[N], respecting the prior coloring r
return G[N]















 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









