






网站链接
aHR0cHM6Ly92aXNhLnZmc2dsb2JhbC5jb20vY2huL3poL2RldS9sb2dpbg==
(base64解密后可见)
正文
抓包堆栈分析
首先抓登录包,密码字段是加密的。

搜下关键词,会发现有很多,可疑的位置都打上断点,再重新登录,但是发现都断不到。
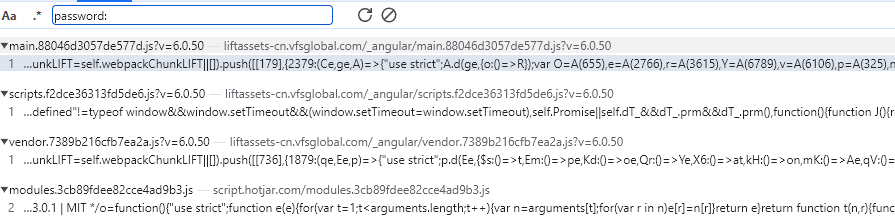
那就换种方法,这里有点可疑,就从这里开始吧。
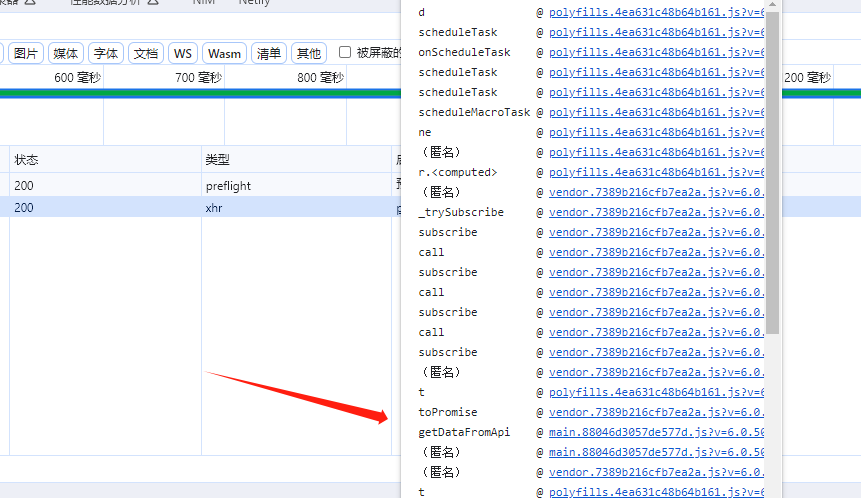
一通操作,跟调堆栈,这里应该是没跑了。
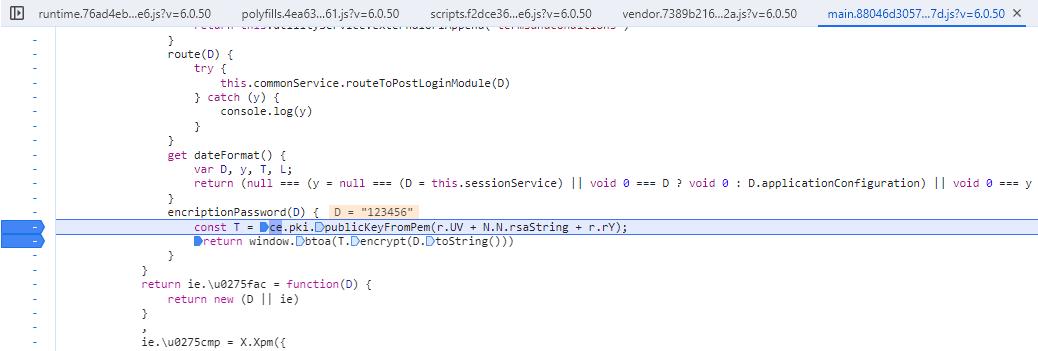
RSA?

看到了关键词,RSA标准算法,应该没跑了。
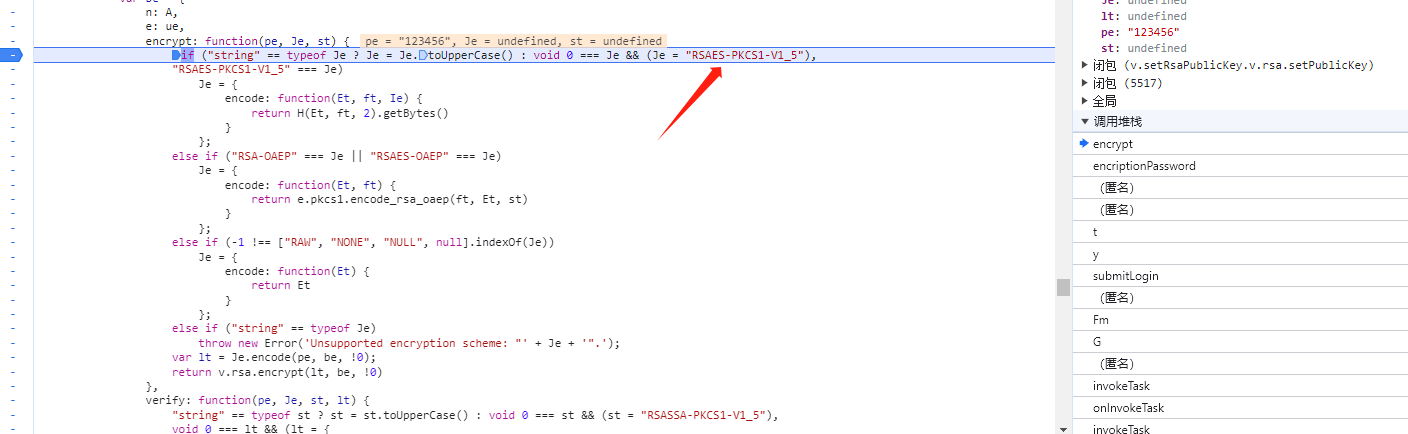
直接py套库,如果没有什么意外的话,意外就发生了,返回403,难道不是标准算法?魔改了?那就执行js的加密代码试试吧。
导出js加密代码
因为代码是webpack打包的,老方法,用ast导出webpack。不过要注意,上面分析分析的js都属于函数模块,加载器都不在里面,第一步,先找到加载器的js在哪里,这个可以自己看看在哪,这里就不说了,至于特征就是,!function开头,且包含.call和exports关键词的js,抓包就能找到,然后根据下面的方法,导出js就好。
https://blog.csdn.net/zjq592767809/article/details/122355530?spm=1001.2014.3001.5502
然后执行导出后的代码,嗯?报错了。
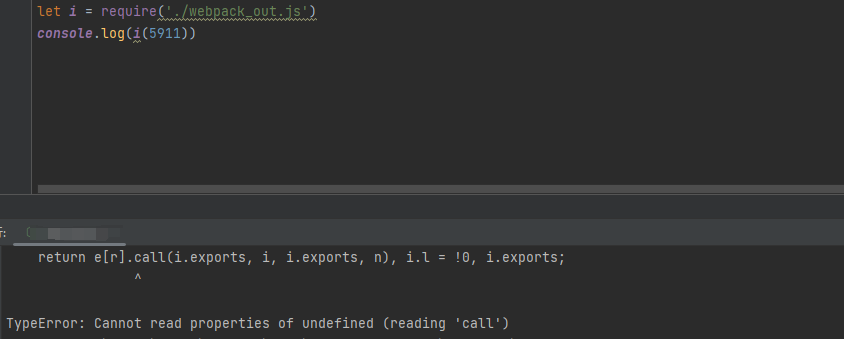
分析后发现,原来是检测了node,把所有isNode带判断的地方,都改成false即可,然后运行会报缺少window,补上就好。
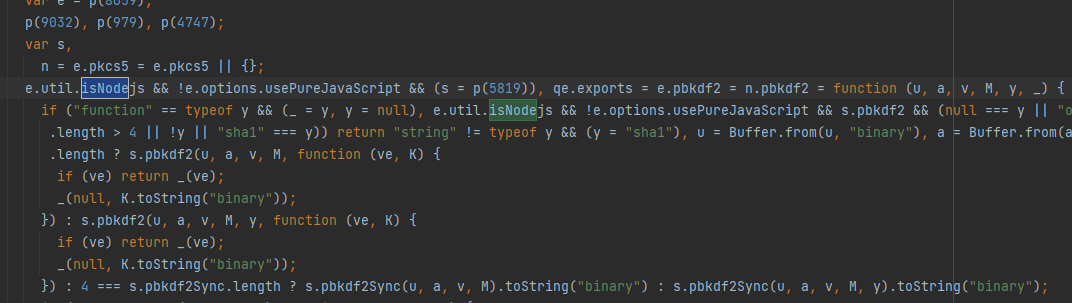
然后补补环境执行,就没啥问题了。

最后再次登录,嘿,还是403。好家伙。
请教了鱼哥,原来响应头里的set-cookie里有个__cf_bm是检测tls的,我还以为没用呢,因为请求头里没有带cookie。行吧,知道了就开干。
tls
尝试的方法如下:
- 用httpx的http2去请求,失败
- 根据网上的代码修改requests指纹,失败
- 尝试了用go去请求,失败
- 用了curl_cffi去请求,成功
curl_cffi,直接用pip install curl_cffi即可,使用的话和requests差不多,可以无痛上手。
from curl_cffi import requests
r = requests.post(url, data=data, headers=headers, impersonate="chrome101")
最后请求结果如下,成功。

小结
其实RSA是标准算法,饶了一圈,最后不管是py的RSA套库,还是调用网站js代码的加密结果,只要过了tls检测都能请求成功。
















 6506
6506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











