







数据增强的13种方法:
1)rectangular:在同个batch里面做rectangle宽高等比变换,加快训练(同一个batch里面拥有自己单独的宽高比)
2)色调,饱和度,曝光度调整,三者调整最终得到一个综合的结果
3)旋转缩放retate_scale通过一个变换矩阵进行变化
变换矩阵的(0,0)(1,1)控制缩放的程度;(0,1)(1,0)控制旋转的程度,当他俩互为相反数的时候就是顶角对应平行旋转;
4)平移translate
5)错切
6)透视变换;
7)翻转,上下翻转,左右翻转;
8)四图拼接mosaic
9)图像互相融合mixup
10)分割填补:












yolov5-网路模块:


YOLO-v3
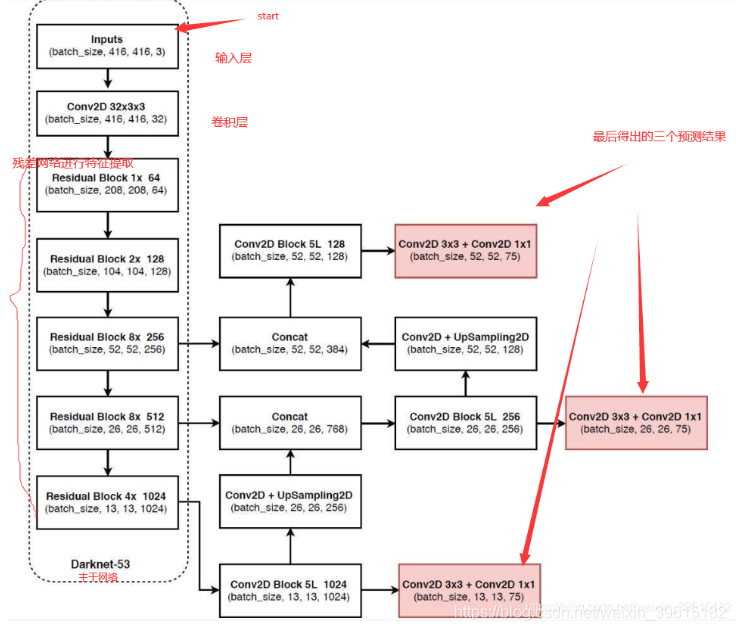
上图三个蓝色方框内表示Yolov3的三个基本组件:
(1)CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
(2)Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
(3)ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。其他基础操作:
(1)Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。Concat和cfg文件中的route功能一样。
(2)Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。add和cfg文件中的shortcut功能一样。Backbone中卷积层的数量:
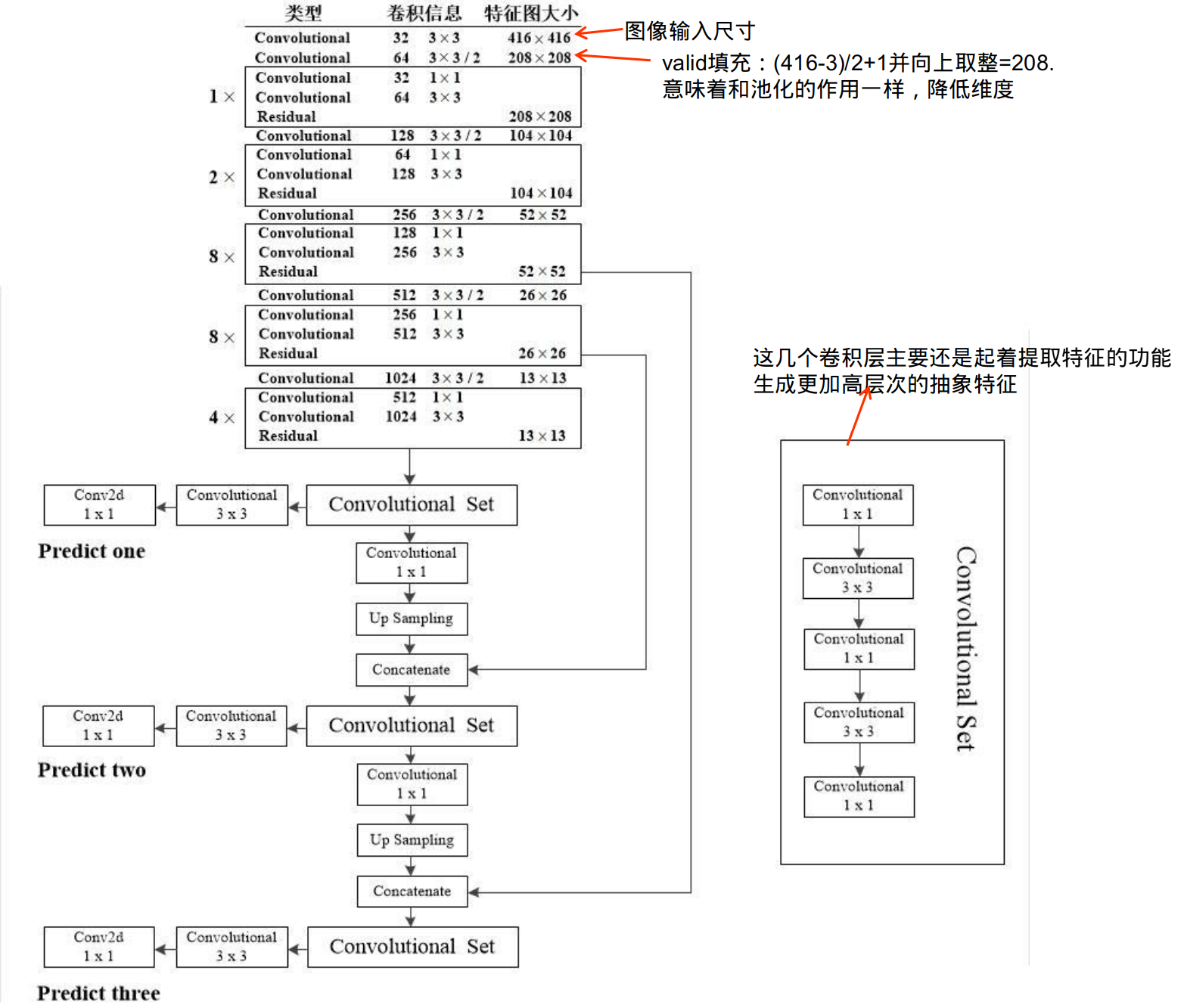
每个ResX中包含1+2×X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2×1)+(1+2×2)+(1+2×8)+(1+2×8)+(1+2×4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。第一步:从特征获取预测结果
1、yolov3提取多特征层进行目标检测,一共提取三个特征层,三个特征层位于主干特征提取网络darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024),这三个特征层后面用于与上采样后的其他特征层堆叠拼接(Concat)2、第三个特征层(13,13,1024)进行5次卷积处理(为了特征提取),处理完后一部分用于卷积+上采样UpSampling,另一部分用于输出对应的预测结果(13,13,75),Conv2D 3×3和Conv2D1×1两个卷积起通道调整的作用,调整成输出需要的大小。
3、卷积+上采样后得到(26,26,256)的特征层,然后与Darknet53网络中的特征层(26,26,512)进行拼接,得到的shape为(26,26,768),再进行5次卷积,处理完后一部分用于卷积上采样,另一部分用于输出对应的预测结果(26,26,75),Conv2D 3×3和Conv2D1×1同上为通道调整
4、之后再将3中卷积+上采样的特征层与shape为(52,52,256)的特征层拼接(Concat),再进行卷积得到shape为(52,52,128)的特征层,最后再Conv2D 3×3和Conv2D1×1两个卷积,得到(52,52,75)特征层
最后图中有三个红框原因就是有些物体相对在图中较大,就用13×13检测,物体在图中比较小,就会归为52×52来检测
第二步:预测结果的解码
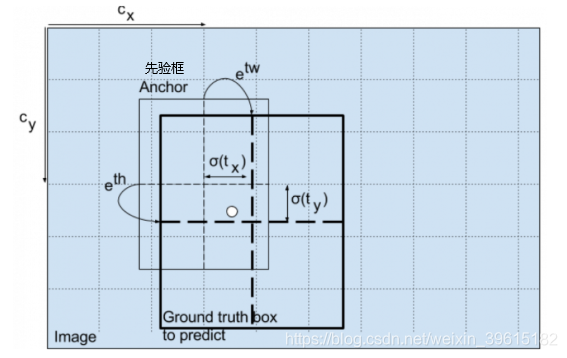
预测结果解码原因:预测结果(红框)并不对应着最终的预测框在图片上的位置,还需要解码)yolov3的预测原理是分别将整幅图分为13x13、26x26、52x52的网格,每个网络点负责一个区域的检测。解码过程就是计算得出最后显示的边界框的坐标bx,by,以及宽高bw,bh,这样就得出了边界框的位置,计算过程如图(b–为bounding box 缩写)
(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
σ:激活函数,论文作者用的是sigmoid函数,[0,1]之间概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值 ,图解如下注:最终得到的边框坐标值是bx,by,bw,bh.而网络学习目标是tx,ty,tw,th。
另外cy向下此处为正向
第三步:对预测出的边界框得分排序与非极大抑制筛选


YOLO-v4
1. CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
2. CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
3. Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
4. CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concat组成。
5. SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。其他基础操作:
1. Concat:张量拼接,维度会扩充,和Yolov3中的解释一样,对应于cfg文件中的route操作。
2. Add:张量相加,不会扩充维度,对应于cfg文件中的shortcut操作。Backbone中卷积层的数量:
和Yolov3一样,再来数一下Backbone里面的卷积层数量。
每个CSPX中包含5+2×X个卷积层,因此整个主干网络Backbone中一共包含1+(5+2×1)+(5+2×2)+(5+2×8)+(5+2×8)+(5+2×4)=72。
目标检测算法YOLOv4详解_智能算法的博客-CSDN博客一句话总结:速度差不多的精度碾压,精度差不多的速度碾压!YOLOv4是精度速度最优平衡, 各种调优手段是真香,本文主要从以下几个方面进行阐述:YOLOv4介绍YOLOv4框架原理Back...https://blog.csdn.net/x454045816/article/details/109759989?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164908271716780264029288%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164908271716780264029288&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-3-109759989.142%5Ev5%5Epc_search_result_cache,157%5Ev4%5Econtrol&utm_term=yolov4&spm=1018.2226.3001.4187
2.SPP结构
SPP-Net结构我们之前也有学过,SPP-Net全称Spatial Pyramid Pooling Networks,当时主要是用来解决不同尺寸的特征图如何进入全连接层的,直接看下图,下图中对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
如上图,以3个尺寸的池化为例,对特征图进行一个最大值池化,即一张特征图得取其最大值,得到1*d(d是特征图的维度)个特征;对特征图进行网格划分为2x2的网格,然后对每个网格进行最大值池化,那么得到4*d个特征;同样,对特征图进行网格划分为4x4个网格,对每个网格进行最大值池化,得到16*d个特征。 接着将每个池化得到的特征合起来即得到3.BackBone训练策略
这里我们主要从数据增强,DropBlock正则化,类标签平滑方面来学习下BackBone训练策略。3.1 数据增强
CutMixYOLOv4选择用CutMix的增强方式,CutMix的处理方式也比较简单,同样也是对一对图片做操作,简单讲就是随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,ground truth标签会根据patch的面积按比例进行调整,比如0.6像狗,0.4像猫,计算损失时同样采用加权求和的方式进行求解。
Mosaic
3.2 正则化方法之DropBlock
(a)原始输入图像
(b)绿色部分表示激活的特征单元,b图表示了随机dropout激活单元,但是这样dropout后,网络还会从drouout掉的激活单元附近学习到同样的信息
(c)绿色部分表示激活的特征单元,c图表示本文的DropBlock,通过dropout掉一部分相邻的整片的区域(比如头和脚),网络就会去注重学习狗的别的部位的特征,来实现正确分类,从而表现出更好的泛化。
3.3类标签平滑4.BackBone推理策略
这里主要从
Mish激活函数,MiWRC策略方面进行阐述BackBone推理策略。4.1 Mish激活函数
对激活函数的研究一直没有停止过,
ReLU还是统治着深度学习的激活函数,不过,这种情况有可能会被Mish改变。Mish是另一个与ReLU和Swish非常相似的激活函数。正如论文所宣称的那样,Mish可以在不同数据集的许多深度网络中胜过它们。公式如下:
5.1 CIoU-loss
5.2 CmBN策略
BN:无论每个batch被分割为多少个mini batch,其算法就是在每个mini batch前向传播后统计当前的BN数据(即每个神经元的期望和方差)并进行Nomalization,BN数据与其他mini batch的数据无关。CBN:每次iteration中的BN数据是其之前n次数据和当前数据的和(对非当前batch统计的数据进行了补偿再参与计算),用该累加值对当前的batch进行Nomalization。好处在于每个batch可以设置较小的size。CmBN:只在每个Batch内部使用CBN的方法,个人理解如果每个Batch被分割为一个mini batch,则其效果与BN一致;若分割为多个mini batch,则与CBN类似,只是把mini batch当作batch进行计算,其区别在于权重更新时间点不同,同一个batch内权重参数一样,因此计算不需要进行补偿。
5.4 消除网格敏感度
Self-Adversarial Training是在一定程度上抵抗对抗攻击的数据增强技术。CNN计算出Loss, 然后通过反向传播改变图片信息,形成图片上没有目标的假象,然后对修改后的图像进行正常的目标检测。需要注意的是在SAT的反向传播的过程中,是不需要改变网络权值的。 使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。5.6 余弦模拟退火
余弦调度会根据一个余弦函数来调整学习率。首先,较大的学习率会以较慢的速度减小。然后在中途时,学习的减小速度会变快,最后学习率的减小速度又会变得很慢。
6.检测头推理策略
6.1 SAM模块
注意力机制在
DL设计中被广泛采用。在SAM中,最大值池化和平均池化分别用于输入feature map,创建两组feature map。结果被输入到一个卷积层,接着是一个Sigmoid函数来创建空间注意力。在
YOLOv4中,使用修改后的SAM而不应用最大值池化和平均池化。
6.2 DIoU-NMS
NMS过滤掉预测相同对象的其他边界框,并保留具有最高可信度的边界框。
DIoU(前面讨论过的) 被用作非最大值抑制(NMS)的一个因素。该方法在抑制冗余框的同时,采用IoU和两个边界盒中心点之间的距离。这使得它在有遮挡的情况下更加健壮。




















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









