






参考来源:
动手深度学习(第二版)
一、多层感知机回归基本步骤和原理
1、引言
虽然我们已经掌握了线性回归与Softmax回归两种基本模型,但他们只适用于特定的问题,在更广泛的问题处理上,会出现很多问题。例如,我们想要根据体温预测死亡率。 对体温高于37摄氏度的人来说,温度越高风险越大。 然而,对体温低于37摄氏度的人来说,温度越高风险就越低。
又比如如何对猫和狗的图像进行分类呢? 增加位置(13,17)处像素的强度是否总是增加(或降低)图像描绘狗的似然? 对线性模型的依赖对应于一个隐含的假设, 即区分猫和狗的唯一要求是评估单个像素的强度。 在一个倒置图像后依然保留类别的世界里,这种方法注定会失败。
单纯的线性模型很难适用于所有问题。
2、多层感知机回归的优缺点
优点:
- 非线性映射能力:MLP可以很好地表示和拟合非线性关系。它可以有效地解决一些传统算法难以解决的问题。
- 分类和回归任务:MLP可以用于分类和回归任务,适用范围广泛。
- 自动特征提取:MLP可以自动从原始数据中学习出有效的特征表示,不需要手动设计特征工程。
- 并行计算:MLP的计算过程可以高度并行化,从而大幅提升训练速度和性能。
- 可扩展性:MLP具有良好的可扩展性,可以通过增加隐藏层数量、改变每层节点数量等方法来调整网络结构,以便适应不同复杂度的问题。
缺点:
- 容易过拟合:MLP具有较强的模型拟合能力,容易导致过拟合现象。为了防止过拟合,需要采用正则化、早停等策略。
- 训练时间:当多层感知机中的层数和神经元数量较多时,训练时间可能会较长。
- 梯度消失问题:在深层的多层感知机中,梯度可能在反向传播过程中逐渐变小,从而导致训练困难。这个问题可以通过使用ReLU激活函数、批量归一化等技术来缓解。
- 需要大量数据:MLP通常需要大量数据进行训练以避免过拟合,同时保证模型的泛化性能。
- 可解释性差:与一些简单的线性模型相比,MLP的内部结构和参数较难直接解释,可解释性较差。
3、基本步骤
-
输入层:将输入数据传递给第一个隐藏层。
-
隐藏层:对输入数据进行线性组合与激活函数得到中间输出结果,并将其传递到下一层。
-
输出层:含有一个或多个神经元,计算并输出我们需要的最终结果。
-
训练过程:使用反向传播算法来更新权重参数,从而最小化损失函数并提高模型的预测准确度。
以简单的分类问题为例,如区分猫和狗图片。假设每张图片包含 28\times2828×28 个像素点,我们可以将其展开成 784,784 维向量作为输入特征。然后,对这些特征进行加权组合,并通过一个ReLU等激活函数来非线性映射到隐藏层。之后,再次对隐藏层输出进行线性组合和激活函数处理,输出相应的分类概率。
进行训练时,我们将数据集输入模型并计算损失,根据反向传播算法更新参数,并重新计算预测误差。重复执行该过程直到损失函数收敛,模型达到稳定的预测效果。
总而言之,多层感知机是一种常见、高效的人工神经网络模型,可以用于许多任务。它的基本思想是将输入数据通过多次线性组合和非线性变换映射到输出结果。
4、在神经网络中加入隐藏层
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前L−1层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。

这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 因此,这个多层感知机中的层数为2。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
5、从线性到非线性
我们通过矩阵X∈R(n×d) 来表示n个样本的小批量, 其中每个样本具有d个输入特征。 对于具有h个隐藏单元的单隐藏层多层感知机, 用H∈R(n×h)表示隐藏层的输出, 称为隐藏表示(hidden representations)。 在数学或代码中,H也被称为隐藏层变量(hidden-layer variable) 或隐藏变量(hidden variable)。 因为隐藏层和输出层都是全连接的, 所以我们有隐藏层权重W(1)∈R(d×h) 和隐藏层偏置b(1)∈R(1×h) 以及输出层权重W(2)∈R(h×q) 和输出层偏置b(2)∈R(1×q)。 形式上,我们按如下方式计算单隐藏层多层感知机的输出 O∈R(n×q):

如上图两式,我们就在直接从输入到输出的线性变换基础上,多了一步隐藏层的变换。但是上式隐藏层的变换仍是一个线性变换,对输入进行多少步线性变换,得到的结果仍是线性变换结果。等价于只作一次线性变换。
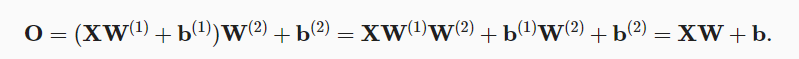
为了实现非线性变换,及为了满足非线性的需求。我们需要一个额外的关键要素: 在仿射变换之后对每个隐藏单元应用非线性的激活函数(activation function)σ。 激活函数的输出(例如,σ(⋅))被称为活性值(activations)。加上激活函数后的隐藏层变换就变成了如下:
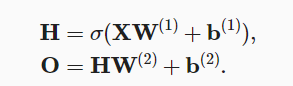
我们可以继续增加隐藏层数目,实现更加复杂的非线性变化:

6、激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。 由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
(1)ReLU函数
给定元素x,ReLU函数被定义为该元素与0的最大值,通俗地说,ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。
![]()
代码视图如下:
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))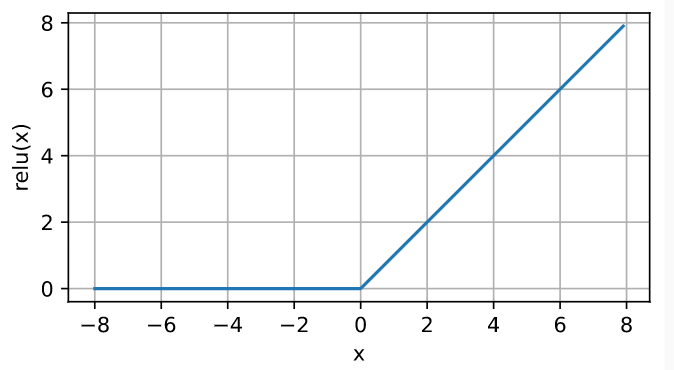
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。 注意,当输入值精确等于0时,ReLU函数不可导。 在此时,我们默认使用左侧的导数,即当输入为0时导数为0。
y.backward(torch.ones_like(x), retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))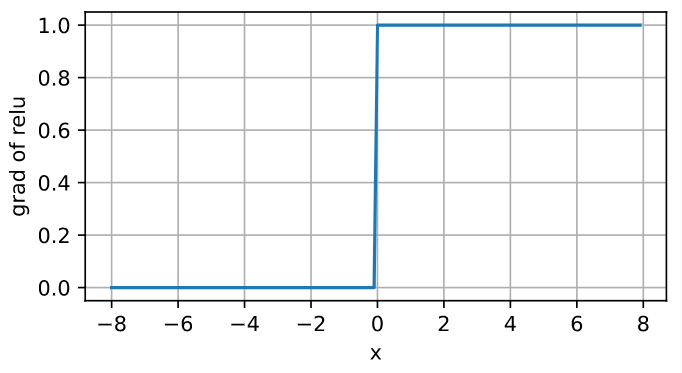
(2)sigmoid函数
对于一个定义域在R中的输入, sigmoid函数将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
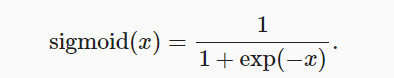
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5)) 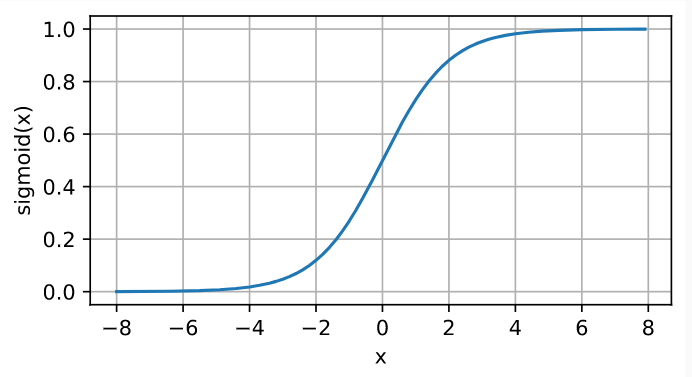
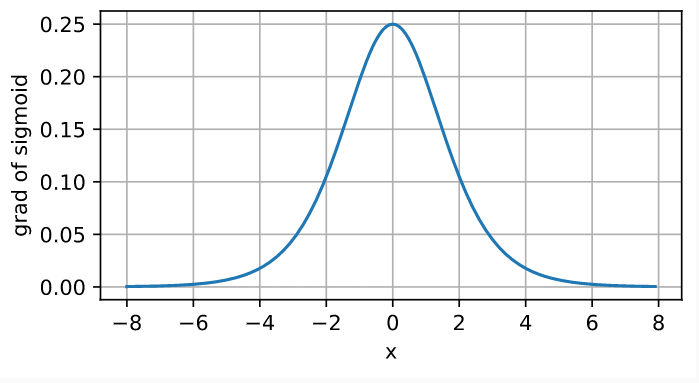
sigmoid函数的导数为下面的公式:

注意,当输入为0时,sigmoid函数的导数达到最大值0.25; 而输入在任一方向上越远离0点时,导数越接近0。
(3) tanh函数
与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。 tanh函数的公式如下:
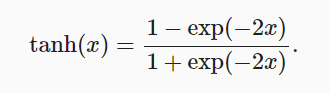
下面我们绘制tanh函数。 注意,当输入在0附近时,tanh函数接近线性变换。 函数的形状类似于sigmoid函数, 不同的是tanh函数关于坐标系原点中心对称。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))
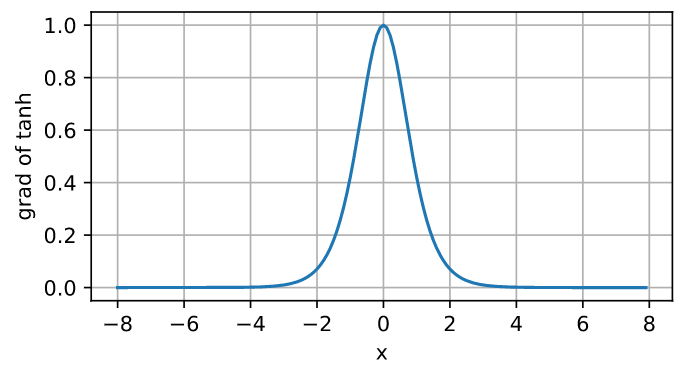
tanh函数的导数是:

tanh函数的导数图像如下所示。 当输入接近0时,tanh函数的导数接近最大值1。 与我们在sigmoid函数图像中看到的类似, 输入在任一方向上越远离0点,导数越接近0。
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of tanh', figsize=(5, 2.5))
一般情况下,使用Relu函数的次数比较多
二、代码实现
复杂版:
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.predict_ch3(net, test_iter)简单版:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











