









文章目录
基于Text-CNN情感分析
大家都知道,CNN(Convolutional Neural Network) 是深度学习中十分重要的一种神经网络,一般用于图像的处理。
但是也存在一种 CNN 的变体 Text-CNN 用来处理文本信息,本次我们将基于 Text-CNN 实现来实现评论情感分析(文本分类),本次实验属于评论三分类(好中差评)研究,数据集共有17万多条京东的手机评论数据,经过实验发现基于Text-CNN模型三分类的效果在测试集的准确度可达到77%左右。
卷积的基本概念
在实现情感分类之前,我们先来了解下一维卷积是如何工作的。需要注意的是,这只是基于互相关运算的二维卷积的特例。

如上图所示,在一维情况下,卷积窗口在输入张量上从左向右滑动。在滑动期间,卷积窗口中某个位置包含的输入子张量(例如上图的 0 0 0 和 1 1 1)和核张量(例如上图中的 1 1 1 和 2 2 2)按元素相乘。这些乘法的总和在输出张量的相应位置给出单个标量值(例如上图中的 0 × 1 + 1 × 2 = 2 0 \times 1 + 1 \times 2 = 2 0×1+1×2=2)。
对于任何具有多个通道的一维输入,卷积核需要具有相同数量的输入通道。然后,对于每个通道,对输入的一维张量和卷积核的一维张量执行互相关运算,将所有通道上的结果相加以产生一维输出张量。 下图演示了具有3个输入通道的一维互相关操作。
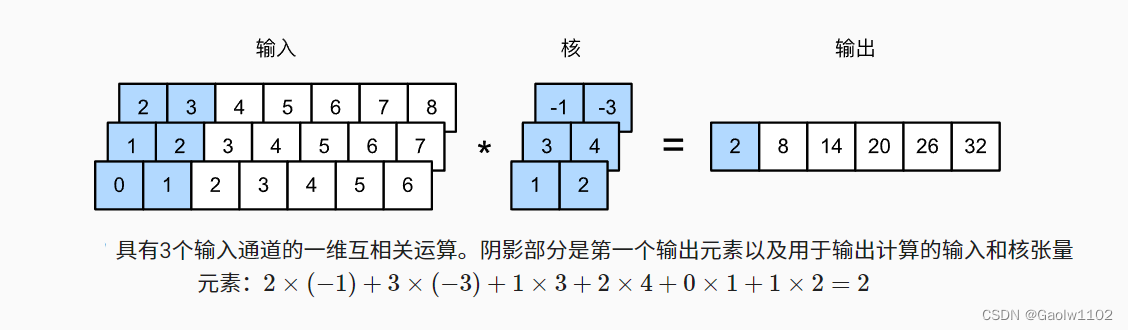
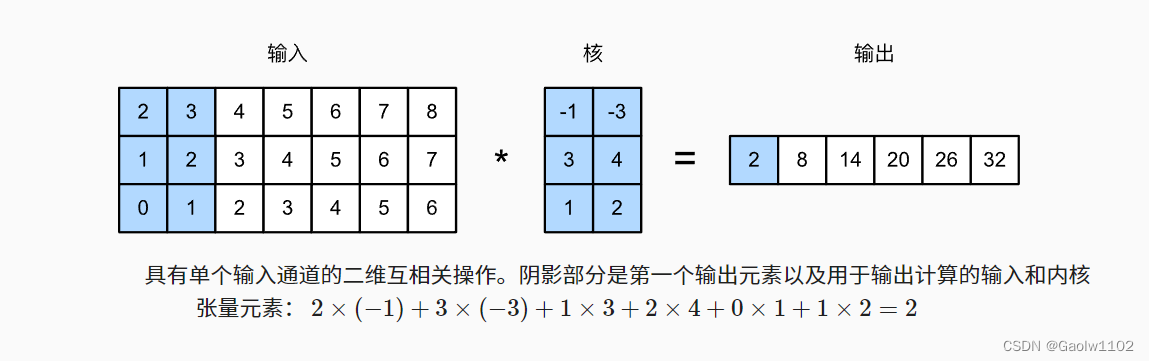
这里需要注意,多输入通道的一维互相关等同于单输入通道的二维互相关。 如下图:
Text-CNN的核心思想
Text-CNN模型继承了CNN模型的思想,继续使用卷积操作和最大时间汇聚。其中卷积操作是为了捕获不同数目的相邻词元之间的局部特征,最大时间汇聚是为了对采取的特征进行压缩操作。
Text-CNN定义了多个卷积层操作,用以不同程度提取词元序列中的信息,最后将所有汇聚层输出的标量连结为向量,再使用全连接层将连结后的向量转换为输出类别。
其中,对于具有由 d d d 维向量表示的 n n n 个词元的单个文本序列,输入张量的宽度、高度和通道数分别为 n 、 1 、 d n、1、d n、1、d。模型运行图如下:
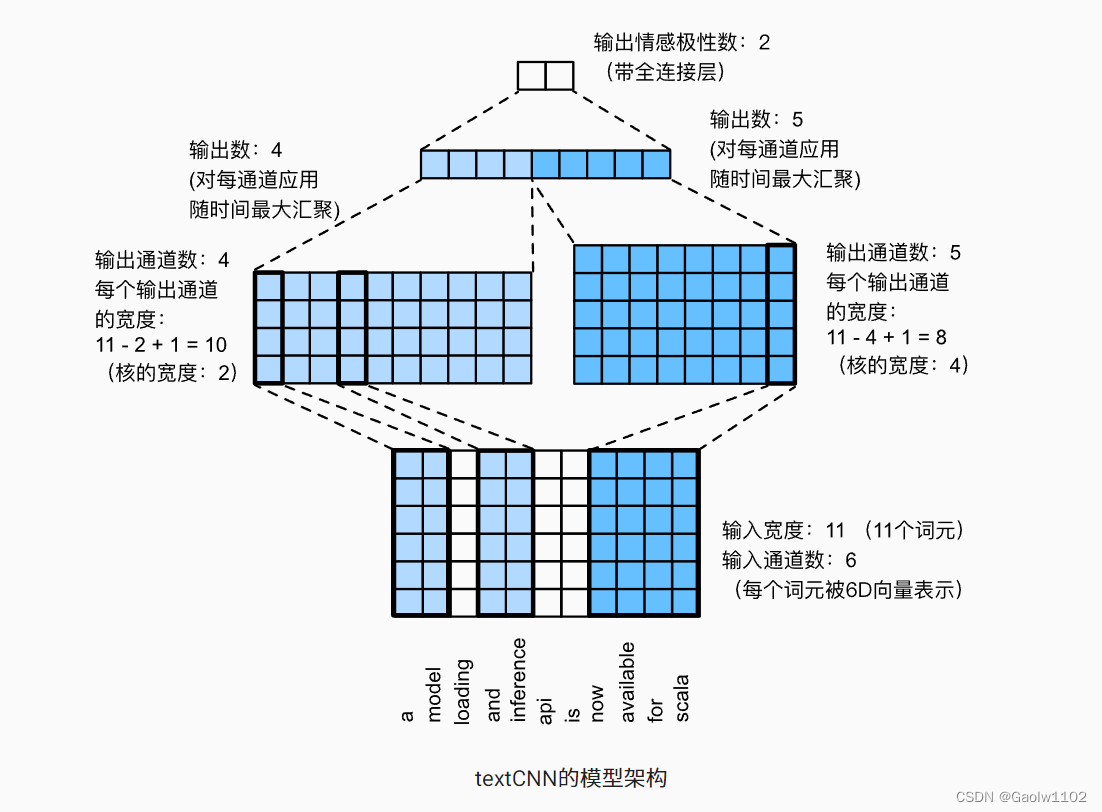
上图通过一个具体的例子说明了Text-CNN的模型架构。输入是具有11个词元的句子,其中每个词元由6维向量表示。因此,我们有一个宽度为11的6通道输入。定义两个宽度为2和4的一维卷积核,分别具有4个和5个输出通道。它们产生4个宽度为 11 − 2 + 1 = 10 11 - 2 + 1 = 10 11−2+1=10 的输出通道和5个宽度为 11 − 4 + 1 = 8 11 - 4 + 1 = 8 11−4+1=8的输出通道。尽管这9个通道的宽度不同,但最大时间汇聚层给出了一个连结的9维向量,该向量最终被转换为用于二元情感预测的2维输出向量。
实现
接下来我们将会一步步实现Text-CNN实现的文本分类模型。
数据预处理
首先导入一些必要的库包。
from d2l import torch as d2l
import csv
import torch
from torch import nn
import pandas as pd
from gensim.models import Word2Vec
from collections import Counter
from tqdm import tqdm
读取评论文件,并返回tokens评论语句和labels标签信息。
def read_file(file_name):
all_data = None
with open(file_name, 'r', encoding='UTF-8') as f:
reader = csv.reader(f)
# 读取分词后的评论信息和对应的标签
all_data = [[comment[2], int(comment[1])] for comment in reader]
# 打乱数据集信息
random.shuffle(all_data)
# 去重操作
pd_data = pd.DataFrame(all_data)
same_comment_sum = pd_data.duplicated().sum()
if same_comment_sum > 0:
pd_data = pd_data.drop_duplicates()
all_data = pd_data.values.tolist() # 再次转化为列表数据
tokens = [sentence[0].strip().split(' ') for sentence in all_data ]
labels = [sentence[1] for sentence in all_data]
# tokens列表(二维数组,每个元素为一个列表(句子分词后的词元列表))
# labels列表,代表评价信息
return tokens, labels
读取tokens和labels信息。
tokens, labels = read_file('./file/comments.csv')
现在输出我们本次测试的数据集大小(大约17万评论数据)
print('tokens num:', len(tokens), '\tlabels num:', len(labels))
tokens num: 171946 labels num: 171946
输出前10个评论信息和对应的标签信息。
print(tokens[:10], labels[:10])
[['发热', '特别', '摄像头', '苹果', '带套', '都', '烫', '看', '摄像头', '位置', '发热', '玩游戏', '真', '想象'], ['一段时间', '正品', '新机', '开机', '速度', '运行', '速度', '都', '不错', '看中', '麒麟', '芯片', '买', '照相', '效果', '拍', '美美', '哒'], ['拍照', '效果', '系列', '感觉', '真实', '画质', '真实', '特色', '屏幕', '不错', '触感', '很棒', '待机时间', '充电', '待机', '时', '长', '够用', '外形', '外观', '光圈', '看起来', '有点', '土', '屏幕', '音效', '满意', '运行', '速度', '不错'], ['拿到', '手机', '没', '来得及', '评价', '不错', '外观', '内在', '都', '特别', '棒', '喜欢', '款', '手机', '舒服', '不错', '快递', '小哥', '特别', '给力', '京东', '购物', '服务', '都', '特别', '棒', '需要'], ['快充', '假', '还', '另配', '充电器'], ['外形', '外观', '比米', '轻薄', '手感', '不错', '运行', '速度', '骁龙', '旗舰', '中', '旗舰', '大核', '速度', '提升', '很大', '屏幕', '音效', '屏幕', '最', '吸引', '购买', '显示', '效果', '细腻', '赫兹', '太丝', '滑', '完美'], ['提前', '买', '没', '优惠', '还', '送', '耳机', '非常', '不开森'], ['京东', '最差', '购物', '体验', '京东', '自营', '买', '离着', '几十公里', '都', '没能', '预计', '送达', '时间', '送到', '物流配送', '真不知道', '京东', '自营', '买', '都', '预计', '时间', '当天', '送到', '现在', '物流配送', '差', '物流配送', '想', '说', '差', '差差'], ['拍照', '效果', '清楚', '外形', '外观', '漂亮', '待机时间', '目前', '还', '知道', '挺久', '回来', '充了', '电', '目前', '正常', '特色', '手感', '不错'], ['外形', '外观', '差差', '屏幕', '音效', '差差', '拍照', '效果', '差差', '运行', '速度', '差差', '待机时间', '差差', '客服', '态度恶劣']] [0, 2, 2, 2, 1, 2, 0, 1, 2, 0]
批量处理操作–填充与截断
为什么要对一些句子进行填充和截断的操作呢?
因为在深度学习中,为了提高模型的训练速度,所以要经常进行批量的数据操作,此时需要保证每个评论语句的长度一致,此时需要对句子进行填充或截断操作,使其达到一致的长度。
现在,我们来统计最常出现的评论长度。
# 获取所有评论长度的频率统计
counter = Counter([len(sentence) for sentence in tokens])
# 对句子长度出现的频率进行排序
counter_freq_dec = sorted(counter.items(), key=lambda x:x[1], reverse=True)
# 输出评论语句长度频率最高的前20个长度
print(counter_freq_dec[:20])
[(5, 9633), (6, 9499), (7, 8957), (4, 8287), (8, 7821), (9, 7086), (10, 6455), (11, 6117), (12, 5714), (13, 5361), (3, 5165), (14, 4986), (15, 4813), (16, 4595), (17, 4326), (18, 4194), (20, 4172), (19, 4111), (21, 3969), (22, 3729)]
从以上我们可以看出,短句子出现的频率非常高,所以我们不能填充过多,所以这里选取填充到64个长度。
"""
填充或截断操作函数:
tokens---->需要进行处理的评论语句
padding_token---->需要填充的tokens,一般为 '<pad>'
length---->所有评论语句的长度
"""
def truncation_and_padding(tokens, padding_token, length):
for i in range(len(tokens)):
if len(tokens[i]) < length:
# 若长度未能达到length长度时,进行填充操作
tokens[i] += (length - len(tokens[i])) * [padding_token]
else:
# 若长度超出length长度,进行截断操作
tokens[i] = tokens[i][:length]
# 返回填充或截取后的tokens信息
return tokens
# 调用函数,填充或截断tokens信息
padding_token = truncation_and_padding(tokens, '<pad>', 64)
现在我们输出前两个句子,如下
print(padding_token[:2])
[['发热', '特别', '摄像头', '苹果', '带套', '都', '烫', '看', '摄像头', '位置', '发热', '玩游戏', '真', '想象', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>'], ['一段时间', '正品', '新机', '开机', '速度', '运行', '速度', '都', '不错', '看中', '麒麟', '芯片', '买', '照相', '效果', '拍', '美美', '哒', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>', '<pad>']]
使用word2vec对所有的词元信息进行编码操作,生成词嵌入矩阵。
word2vec = Word2Vec(padding_token, min_count=1) # 生成的词嵌入模型词最小频率为1
将tokens列表转化为词嵌入字典中下标信息。
def corpus(padding_token, word2vec):
corpus_tokens = []
# 将所有的tokens信息转化为在 词嵌入字典中对应的 下标信息(索引信息)
for sentence in padding_token:
corpus_tokens.append([word2vec.wv.get_index(token) for token in sentence])
# 返回corpus_tokens词元索引的评论信息
return corpus_tokens
# 进行转化操作
corpus_tokens = corpus(padding_token, word2vec)
输出前2个corpus_tokens信息,即前两条由词元索引组成的评论信息
print(corpus_tokens[:2])
[[57, 30, 86, 39, 6650, 7, 209, 48, 86, 943, 57, 78, 120, 282, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [178, 164, 200, 159, 6, 9, 6, 7, 11, 935, 617, 369, 4, 298, 12, 93, 1285, 580, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
拆分训练集与测试集
现在我们以 6:4 比例划分训练集与测试集,分别用于对模型进行训练与测试。
split_len = int(len(corpus_tokens) * 0.6) # 设定切分线
# 划分训练集和测试集的评论信息和标签信息
train_comments, train_labels = corpus_tokens[:split_len], labels[:split_len]
test_comments, test_labels = corpus_tokens[split_len:], labels[split_len:]
print('train_set_len:', len(train_comments), '\t', len(train_labels))
print('test_set_len:', len(test_comments), '\t', len(test_labels))
train_set_len: 103167 103167
test_set_len: 68779 68779
定义Text-CNN模型
"""
定义Text-CNN模型
"""
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_size, kernel_sizes, num_channels, embed, **kwargs):
super(TextCNN, self).__init__(**kwargs)
# 定义embedding词嵌入模型,并将word2vec生成的词向量嵌入进来
self.embedding = nn.Embedding(vocab_size, embed_size)
self.embedding.from_pretrained(torch.tensor(embed))
# 此嵌入层同上
self.constant_embedding = nn.Embedding(vocab_size, embed_size)
self.constant_embedding.from_pretrained(torch.tensor(embed))
# 暂退法减少模型复杂度,并定义全连接层decoder
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels), 3)
# 最大时间汇聚层没有参数,因此可以共享此实例
self.pool = nn.AdaptiveAvgPool1d(1)
self.relu = nn.ReLU()
# 创建多个一维卷积层
self.convs = nn.ModuleList()
# 追加多个一维卷积层,用以提取文本的不同特征信息
for c, k in zip(num_channels, kernel_sizes):
# 输入通道数为 2 * embed_size, 输出通道数为 c, 卷积核为 k
self.convs.append(nn.Conv1d(2 * embed_size, c, k))
def forward(self, inputs):
# 沿着向量维度将两个嵌入层连结起来,
# 每个嵌入层的输出形状都是(批量大小,词元数量,词元向量维度)连结起来
embeddings = torch.cat((
self.embedding(inputs), self.constant_embedding(inputs)), dim=2)
# 根据一维卷积层的输入格式,重新排列张量,以便通道作为第2维
embeddings = embeddings.permute(0, 2, 1)
# 每个一维卷积层在最大时间汇聚层合并后,获得的张量形状是(批量大小,通道数,1)
# 删除最后一个维度并沿通道维度连结
encoding = torch.cat([
torch.squeeze(self.relu(self.pool(conv(embeddings))), dim=-1)
for conv in self.convs], dim=1)
# 使用全连接层输出概率分布,并返回概率结果
outputs = self.decoder(self.dropout(encoding))
return outputs
设计模型定义与训练参数
设计初始化模型参数。
# 词嵌入维度为100,卷积核为[3, 4, 5], 输出通道数为[100, 100, 100]
embed_size, kernel_sizes, nums_channels = 100, [3, 4, 5], [100, 100, 100]
# 使用GPU进行训练
devices = d2l.try_gpu()
# 定义text-cnn网络模型,并存入GPU,并初始化模型参数
net = TextCNN(len(word2vec.wv.vectors), embed_size, kernel_sizes, nums_channels, word2vec.wv.vectors)
net = net.to(device=devices)
def init_weights(m):
if type(m) in (nn.Linear, nn.Conv1d):
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
TextCNN(
(embedding): Embedding(63332, 100)
(constant_embedding): Embedding(63332, 100)
(dropout): Dropout(p=0.5, inplace=False)
(decoder): Linear(in_features=300, out_features=3, bias=True)
(pool): AdaptiveAvgPool1d(output_size=1)
(relu): ReLU()
(convs): ModuleList(
(0): Conv1d(200, 100, kernel_size=(3,), stride=(1,))
(1): Conv1d(200, 100, kernel_size=(4,), stride=(1,))
(2): Conv1d(200, 100, kernel_size=(5,), stride=(1,))
)
)
定义模型训练的学习率,迭代次数,Adam优化器,交叉熵损失函数。
# 定义学习率与迭代次数
lr, num_epochs = 0.0001, 20
trainer = torch.optim.Adam(net.parameters(), lr=lr) # 优化器
loss = nn.CrossEntropyLoss(reduction="none") # 损失函数
训练并评估模型
定义评估模型与训练模型的函数,可视化训练过程。
"""
评估函数,用以评估数据集在神经网络下的精确度
"""
def evaluate(net, comments_data, labels_data):
sum_correct, i = 0, 0
while i <= len(comments_data):
# 批量计算正确率,一次计算64个评论信息
comments = comments_data[i: min(i + 64, len(comments_data))]
tokens_X = torch.tensor(comments).to(device=devices)
res = net(tokens_X) # 获得到预测结果
y = torch.tensor(labels_data[i: min(i + 64, len(comments_data))]).reshape(-1).to(device=devices)
sum_correct += (res.argmax(axis=1) == y).sum() # 累加预测正确的结果
i += 64
return sum_correct/len(comments_data) # 返回(总正确结果/所有样本),精确率
"""
训练函数:用以训练模型,并保存最好结果时的模型参数
"""
def train(net, trainer, loss, train_comments, train_labels, test_comments, test_lables,
num_epochs, devices):
max_value = 0.5 # 初始化模型预测最大精度
# 多次迭代训练模型
for epoch in tqdm(range(num_epochs)):
sum_loss, i = 0, 0 # 定义模型损失总和为 sum_loss, 变量 i
while i < len(train_comments):
# 批量64个数据训练模型
comments = train_comments[i: min(i+64, len(train_comments))]
# X 转化为 tensor
inputs_X = torch.tensor(comments).to(device=devices)
# Y 转化为 tensor
y = torch.tensor(train_labels[i: min(i+64, len(train_comments))]).to(device=devices)
# 将X放入模型,得到概率分布预测结果
res = net(inputs_X)
l = loss(res, y) # 计算预测结果与真实结果损失
trainer.zero_grad() # 清空优化器梯度
l.sum().backward() # 后向传播
trainer.step() # 更新模型参数信息
sum_loss += l.sum() # 累加损失
i += 16
print('loss:\t', sum_loss/len(train_comments))
# 计算训练集与测试集的精度
train_acc = evaluate(net, train_comments, train_labels)
test_acc = evaluate(net, test_comments, test_labels)
# 保存下模型跑出最好的结果
if test_acc >= max_value:
max_value = test_acc
torch.save(net.state_dict(), 'text_cnn.parameters')
# 输出训练信息
print('-epoch:\t', epoch+1,
'\t-loss:\t', sum_loss / len(train_comments),
'\ttrain-acc:', train_acc,
'\ttest-acc:', test_acc)
开始训练模型
train(net, trainer, loss, train_comments, train_labels, test_comments, test_labels, num_epochs, devices)
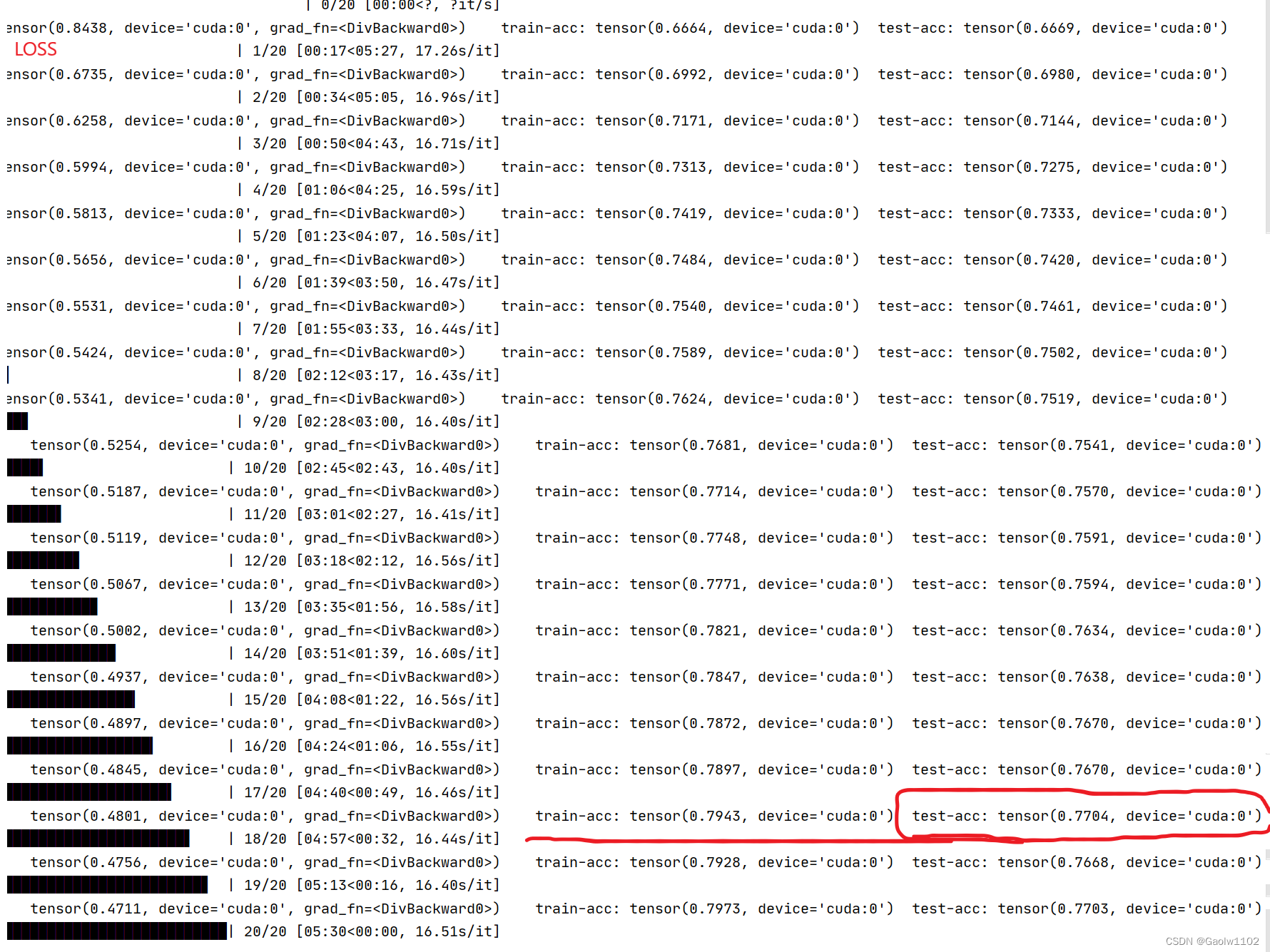
训练结果如上图,可见在测试集上能够达到77%的精确度。
结语
最近有些懈怠,混了些日子,有些自责,不过希望慢慢调整过来,充实起来。
靡不有初,鲜克有终。
加油!
















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











