







仿百度每日搜索关键字词频统计案例
hadoop
一、将网页产生的日志存放至linux
1.在linux系统上配置Apache-tomcat服务
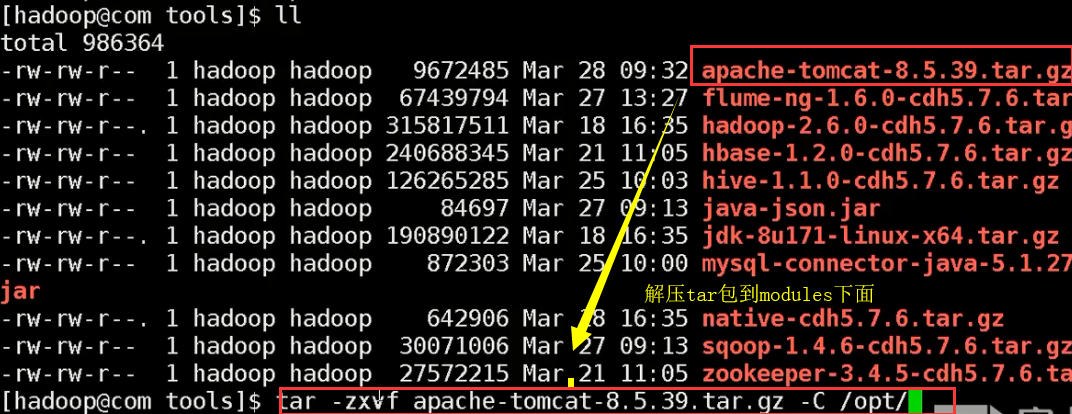
cd opt/modules/apache-tomcat-8.5.39.tar.gz
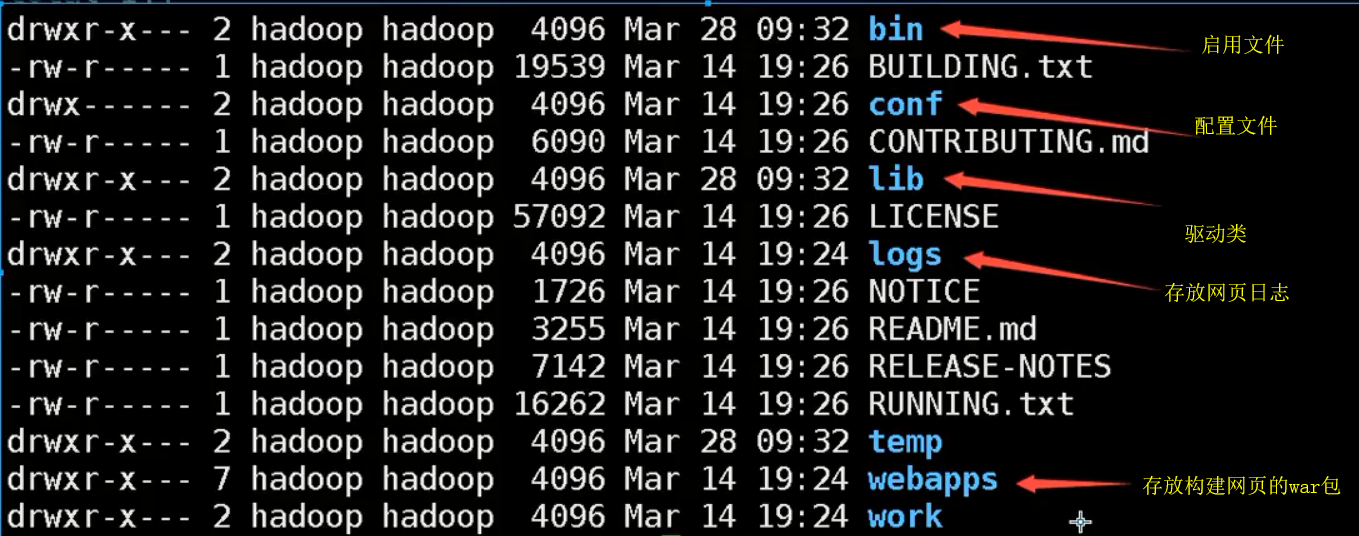
2.将war包放置opt/apache-tomcat-8.5.39.tar.gz/下
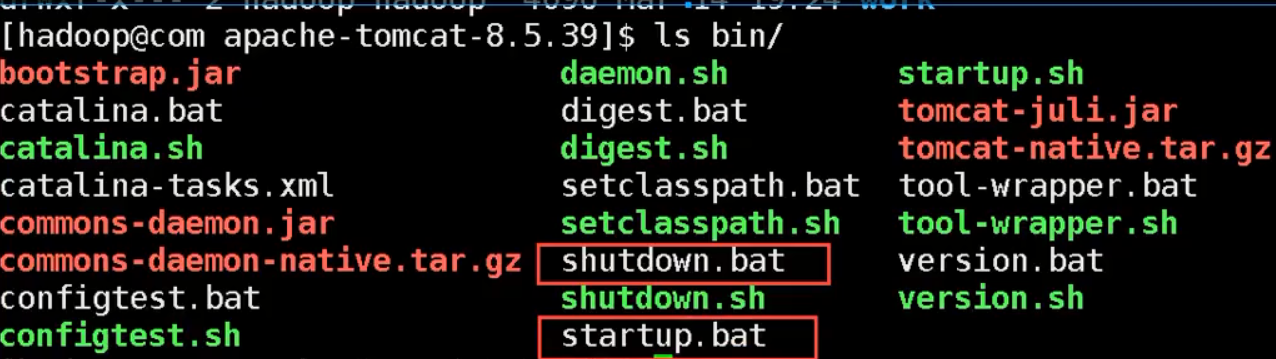
3.启动服务
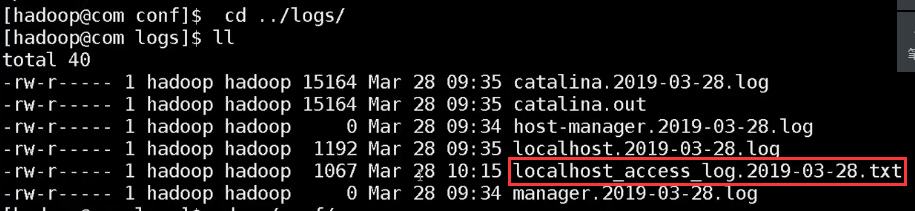
4.在网页上输入关键词搜索,生成日志文件,在logs文件夹下可以查看

日志格式的设置文件:

一般的web server有两部分日志:
一是运行的日志,它主要记录运行的一些信息,尤其是一些异常错误日志信息
二是访问日志信息,他是记录的访问的时间,ip,url,sessionId等信息。
下面来介绍使用tomcat记录访问日志的使用,这个是在tomcat/conf/server.xml文件,需要配置如下的配置:
访问记录配置
有的版本肯能默认不开启记录,只需要把这解注释就好了,记录的文件放在/tomcat/logs/filename,默认是每天产生一个文件,产生的文件如图所示
日志文件
日志文件里面的内容
<!-- Access log processes all example.
Documentation at: /docs/config/valve.html
Note: The pattern used is equivalent to using pattern="common" -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" pattern="%h %l %u %t "%r" %s %b" #日志的设置格式 prefix="localhost_access_log" suffix=".txt"/>
<Context docBase="C:\Program Files\Apache Software Foundation\Tomcat 8.5\wtpwebapps\Web06" path="/Web06" reloadable="true" source="org.eclipse.jst.jee.server:Web06"/></Host>
</Engine>
</Service>
</Server>
日志详情
如果想自己定义书写的文件的格式可以对上面的pattern里面的内容进行修改,可以修改的参数有以下数据
具体的日志产生样式说明如下(从官方文档中摘录):
%a - 远端IP地址
%A - 本地IP地址
%b - 发送的字节数,不包括HTTP头,如果为0,使用"-"
%B - 发送的字节数,不包括HTTP头
%h - 远端主机名(如果resolveHost=false,远端的IP地址)
%H - 请求协议
%l - 从identd返回的远端逻辑用户名(总是返回 '-')
%m - 请求的方法(GET,POST,等)
%p - 收到请求的本地端口号
%q - 查询字符串(如果存在,以 '?'开始)
%r - 请求的第一行,包含了请求的方法和URI
%s - 响应的状态码
%S - 用户的session ID
%t - 日志和时间,使用通常的Log格式
%u - 认证以后的远端用户(如果存在的话,否则为'-')
%U - 请求的URI路径
%v - 本地服务器的名称
%D - 处理请求的时间,以毫秒为单位
%T - 处理请求的时间,以秒为单位
另外还可以将cookie, 客户端请求中带的HTTP头(incoming header), 会话(session)或是ServletRequest中的数据都写到Tomcat的访问日志中,你可以用下面的语法来引用。
%{xxx}i – 记录客户端请求中带的HTTP头xxx(incoming headers)
%{xxx}c – 记录特定的cookie xxx
%{xxx}r – 记录ServletRequest中的xxx属性(attribute)
%{xxx}s – 记录HttpSession中的xxx属性(attribute)
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b %S" />
设置结束后,重启apache!!!
Apache的端口号是:8080
二,Hadoop运行,集群开启
1.
2.进入flume

3、进入case编辑flume的配置文件,将Apache下面的logs文件上传至集群
vim 配置文件的名称

4.运行
Hadoop集群端口号:50070
5.在Hadoop下可以查看上传到集群的数据是否成功
三、数据处理mapreduce阶段
此过程要先把flume关闭,当flume打开的过程中I/O流被霸占不能进行操作
在 eclipse下创建maven工程
写完清洗的过程之后,将Jar包导入之Linux上,
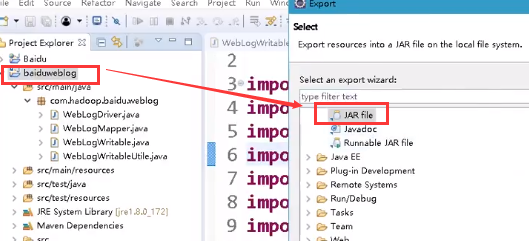
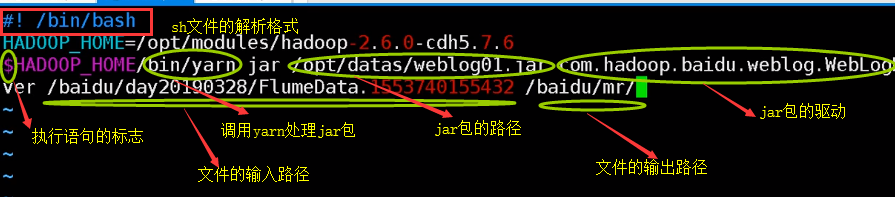
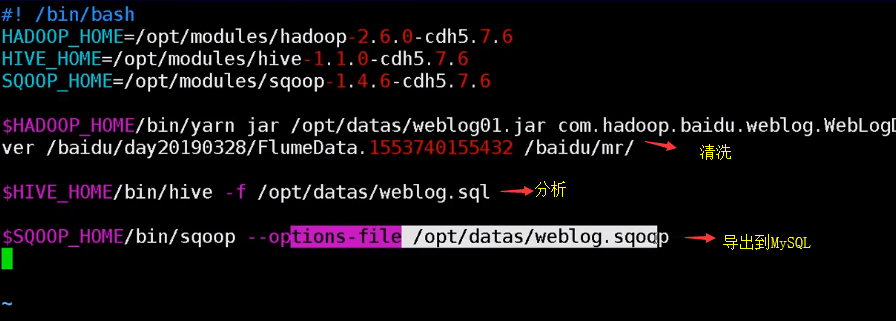
因要多次调用,所以可以写一个执行jar包的脚本

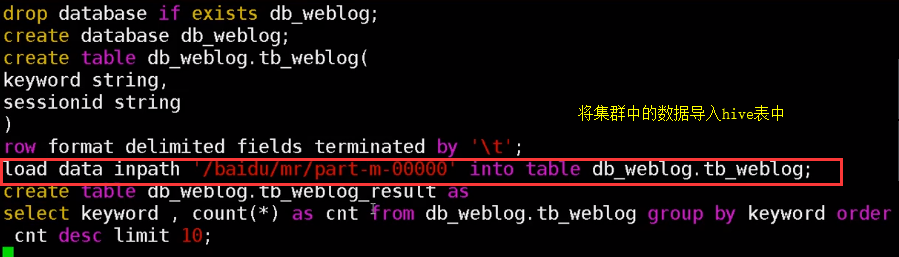
四、进入hive对清洗好的数据进行分析并存入数据库
此过程要先开启MySQL的服务(在root权限下)
1.进入MySQL间数据库,
2.在这个数据库下建立数据表
3.编写hive-sql数据分析的脚本
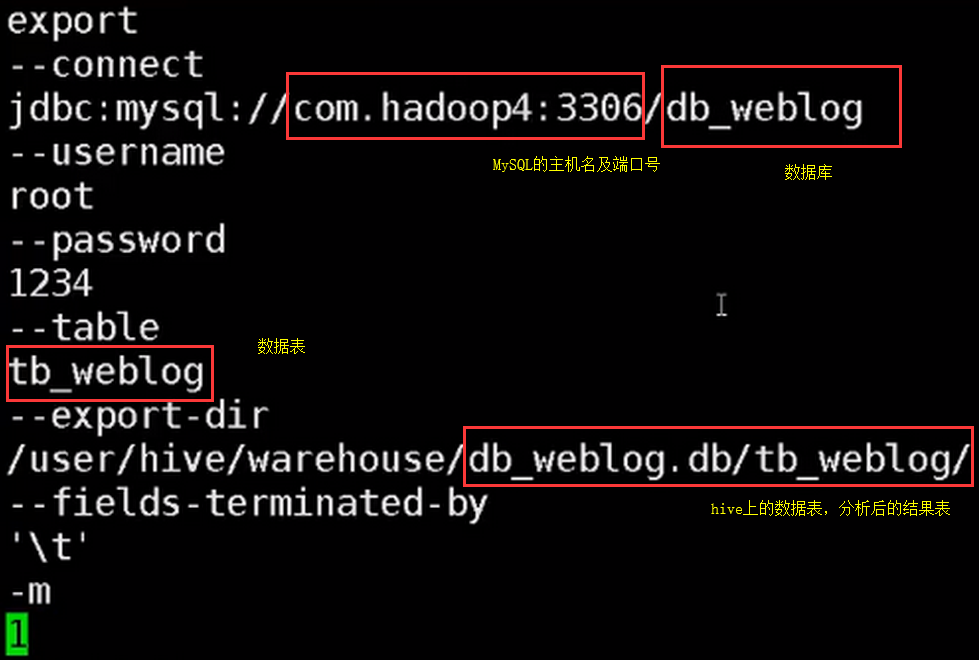
4.编写sqoop将hive中的数据结果导入到MySQL的脚本
5.在执行文件weblog.sh里编写执行的脚本















 5004
5004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









