







目录
01 学习目标
采用梯度下降法自动优化线性回归模型的参数
02 实现工具
(1)代码运行环境
Python语言,Jupyter notebook平台
(2)所需模块
math,copy,numpy
03 问题描述
问题需求为:根据二手房交易平台已成交的既有数据,建立线性回归模型。
我们的任务:采用梯度下降法得到线性回归模型的参数。
04 算法原理及函数定义
(1)算法原理
首先,写出我们最终的线性回归模型:
然后,写出线性回归模型的成本函数:
接着,让成本函数分别对参数w和b求偏导数(即梯度):
现在,我们可以写出梯度下降法的式子如下:
上式中,为学习率(为正值),每次计算都会根据上次的参数值和偏导数值对w和b参数进行更新,迭代出符合精度的回归模型即可停止计算。梯度下降法的几何意义如下图:
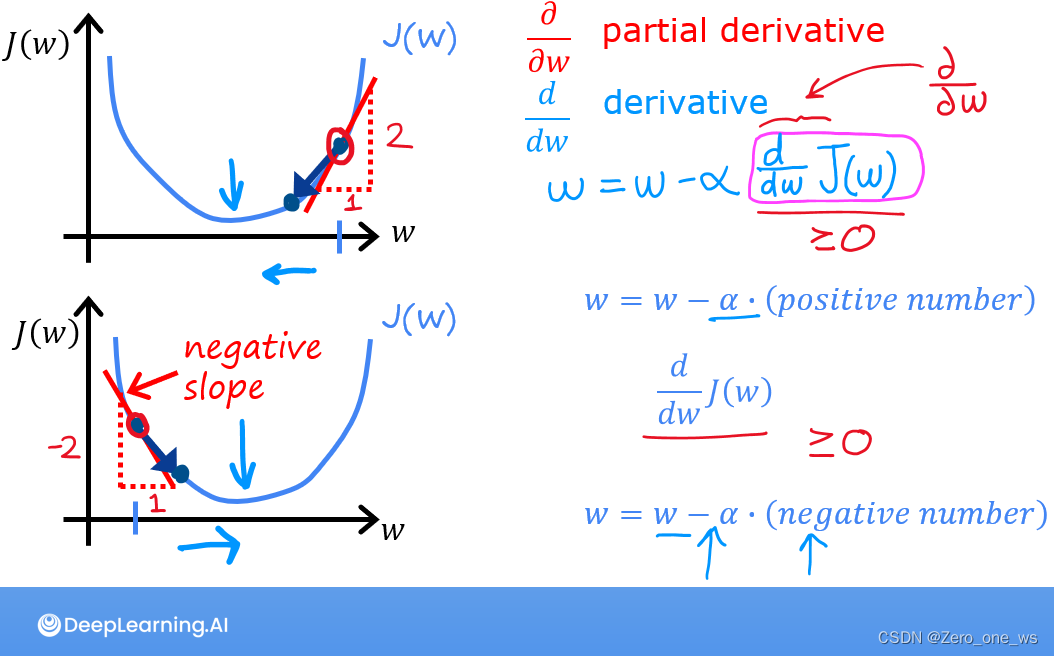
由上图,成本函数有最小值(或极小值),为正值,当计算点
的成本值在最小值左侧时偏导数(斜率)为负,
,逼近最小值;当计算点
的成本值在最小值右侧时偏导数(斜率)为正,
,逼近最小值。因此,每次计算都会距离成本函数的最小值更近一步。
(2)函数定义
导入所需模块
import math, copy
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('./deeplearning.mplstyle')
from lab_utils_uni import plt_house_x, plt_contour_wgrad, plt_divergence, plt_gradients定义成本函数:
def compute_cost(x, y, w, b):
m = x.shape[0]
cost = 0
for i in range(m):
f_wb = w * x[i] + b
cost = cost + (f_wb - y[i])**2
total_cost = 1 / (2 * m) * cost
return total_cost定义梯度函数:
def compute_gradient(x, y, w, b):
m = x.shape[0]
dj_dw = 0
dj_db = 0
for i in range(m):
f_wb = w * x[i] + b
dj_dw_i = (f_wb - y[i]) * x[i]
dj_db_i = f_wb - y[i]
dj_db += dj_db_i
dj_dw += dj_dw_i
dj_dw = dj_dw / m
dj_db = dj_db / m
return dj_dw, dj_db定义梯度下降函数:
def gradient_descent(x, y, w_in, b_in, alpha, num_iters, cost_function, gradient_function):
"""
函数用于求解最优回归模型参数w,b.
参数:
x (ndarray (m,)) : 输入数据
y (ndarray (m,)) : 目标值
w_in,b_in (scalar): 模型初始参数值
alpha (float): 学习率
num_iters (int): 总迭代步数
cost_function: 成本函数
gradient_function: 梯度函数
返回:
w (scalar): 参数w计算结果
b (scalar): 参数b计算结果
J_history (List): 计算过程中的成本历史值
p_history (list): 计算过程中的w,b历史值
"""
w = copy.deepcopy(w_in) # 深拷贝以避免修改全局w_in
# 采用列表储存每一步迭代的成本值、w值、b值
J_history = []
p_history = []
b = b_in
w = w_in
for i in range(num_iters):
# 计算梯度并更新梯度值
dj_dw, dj_db = gradient_function(x, y, w , b)
# 梯度下降更新参数值
b = b - alpha * dj_db
w = w - alpha * dj_dw
# 每一步迭代中保存成本值
if i<100000: # 停止迭代的条件
J_history.append(cost_function(x, y, w , b))
p_history.append([w,b])
# 每迭代10次打印一次成本
if i% math.ceil(num_iters/10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]:0.2e} ",
f"dj_dw: {dj_dw: 0.3e}, dj_db: {dj_db: 0.3e} ",
f"w: {w: 0.3e}, b:{b: 0.5e}")
return w, b, J_history, p_history(注意:梯度下降函数中调用了成本函数和梯度函数)
05 梯度下降法优化参数
(1)读取“数据集”
(这里,避免后续计算过程中数值过大,将房子面积()和成交价(万元)数值除以100)
# 导入特征和目标值
x_train = np.array([1.00, 1.70, 2.00, 2.50, 3.00, 3.20]) #房子面积
y_train = np.array([2.50, 3.00, 4.80, 4.30, 6.30, 7.30]) #房子成交价(2)设置合适的迭代步数、学习率,即可执行梯度下降法得到理想的参数,代码如下:
# 参数初始化
w_init = 0
b_init = 0
# 设置迭代步数和学习率
iterations = 10000
tmp_alpha = 1.0e-2
# 执行梯度下降
w_final, b_final, J_hist, p_hist = gradient_descent(x_train ,y_train, w_init, b_init, tmp_alpha,
iterations, compute_cost, compute_gradient)
print(f"(w,b) found by gradient descent: ({w_final:8.4f},{b_final:8.4f})")运行以上代码,结果如下:
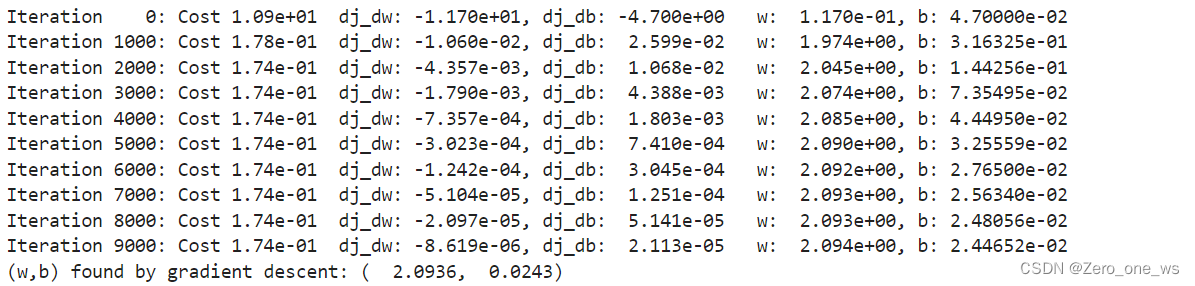
由于“训练数据集”中数值缩放了100倍,故得到参数值为w=2.09、b=2.43。
06 总结
(1)梯度即为成本函数对各参数的偏导数,利用梯度迭代即可实现成本值不断下降,成本达到最小值(或极小值)时的参数即为最优参数(或局部最优参数)。
(2)梯度下降法中学习率设置过大可能导致计算不收敛,得不到最优参数;而学习率设置过小则会增加计算时间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









