







目录
01 学习目标
(1)理解人工神经网络的实现原理
(2)掌握基于tensorflow构建简单的人工神经网络
02 实现工具
(1)代码运行环境
Python语言,Jupyter notebook平台
(2)所需模块
numpy,matplotlib,tensorflow,lab_coffee_utils,logging
(lab_coffee_utils是吴恩达老师编写的用于读取数据和绘图的包)
03 问题陈述
咖啡豆的烘焙与烘焙温度和时间有关,烘焙结果可分为两种情况:烘焙成功和烘焙失败。烘焙数据为随机生成,为200×3的张量格式,数据如下:

数据中,第1列为烘焙温度,第二列为烘焙时间,第3列为烘焙结果:成功为1、失败为0.。
需求是:根据现有数据构建一个人工神经网络,预测咖啡豆烘焙组合为(190,13)和(200,17)的结果。
04 人工神经网络
4.1 人工神经网络原理
(1)人工神经网络是一种模仿生物神经网络的计算模型。
两个要素:人工神经元(节点)和连接。
节点负责对接收的信息进行计算,连接负责将节点计算结果传递给下个节点。人工神经网络中人为地将节点进行了分层,每1层包含若干节点。如下图,3个中间层称为隐藏层,最后1层称为输出层。
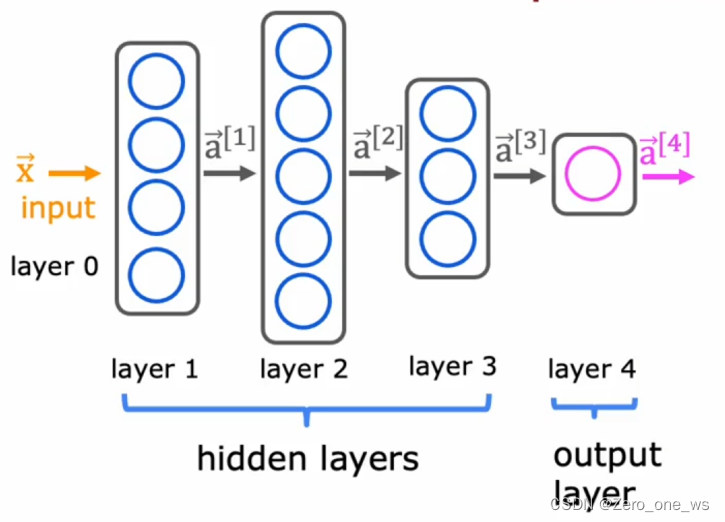
(2)结构:每1个节点都是1个回归模型,同1层中n个节点就有n个模型。输入的信息进入该层会交给n个节点进行计算,同一层内采用同类算法(称为激活函数),如下图所示。神经网络的整体行为不取决于单个节点或单层的特征,而是由整个系统决定。
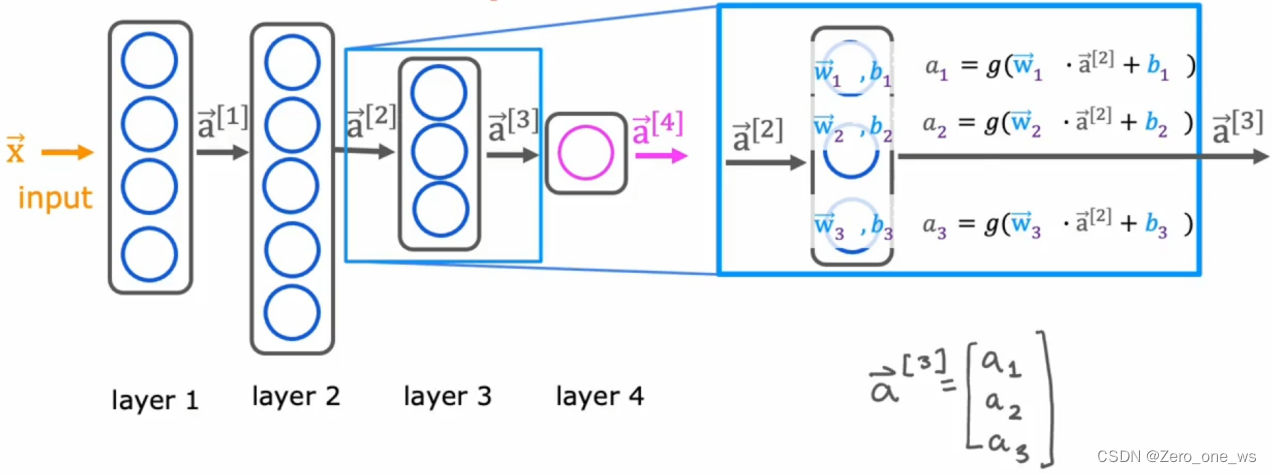
(以上为人工神经网络的基本结构,即前馈神经网络,同一层内不同节点间通常没有直接连接。而一些复杂的神经网络结构允许层内神经元之间进行连接,如递归神经网络和卷积神经网络等)
(3) 两个核心过程:前向传播和反向传播。
前向传播:基于网络结构,逐层计算数据得到预测结果和误差、并正向传递。反向传播:基于链式法则,反向逐层计算各层参数梯度误差,调整更新神经网络参数。两者相互作用,构成循环。
(4)应用:神经网络具有自适应、自组织和自学习能力,能够处理各种变化的信息,具有智能特性。应用领域包括模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等。
4.2 基于tensorflow构建人工神经网络
(1)导入所需模块
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('./deeplearning.mplstyle')
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from lab_coffee_utils import load_coffee_data, plt_roast, plt_prob, plt_layer, plt_network, plt_output_unit
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.autograph.set_verbosity(0)(上面最后2行代码是设置只显示error信息,不显示警告等其他信息)
(2)导入(生成)训练数据并绘制
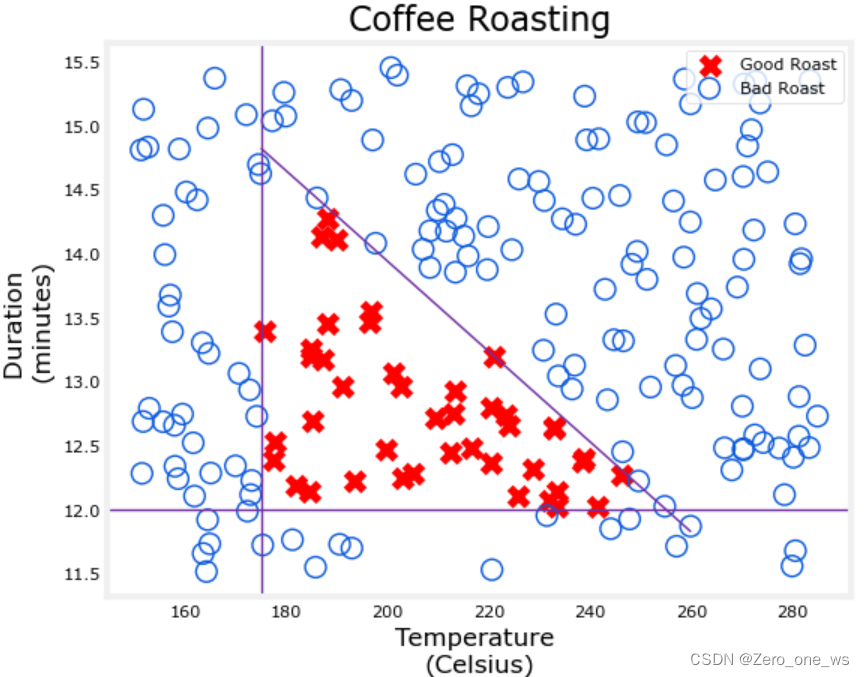
X,Y = load_coffee_data()
plt_roast(X,Y)(X为200×2数据,第1列温度、第2列时间,Y为200×1数据,内容为0或1.)
运行以上代码,结果如下(图中×为1、○为0):
(3)数据预处理(正则化)
norm_l = tf.keras.layers.Normalization(axis=-1)
norm_l.adapt(X) # 计算均值和方差
Xn = norm_l(X)
print(Xn)运行以上代码,结果如下:

(4)构建人工神经网络
# 设置随机种子以确保每次运行的权重相同
tf.random.set_seed(1234)
# 定义神经网络模型框架
model = Sequential(
[
tf.keras.Input(shape=(2,)),
Dense(3, activation='sigmoid', name = 'layer1'),
Dense(1, activation='sigmoid', name = 'layer2')
]
)
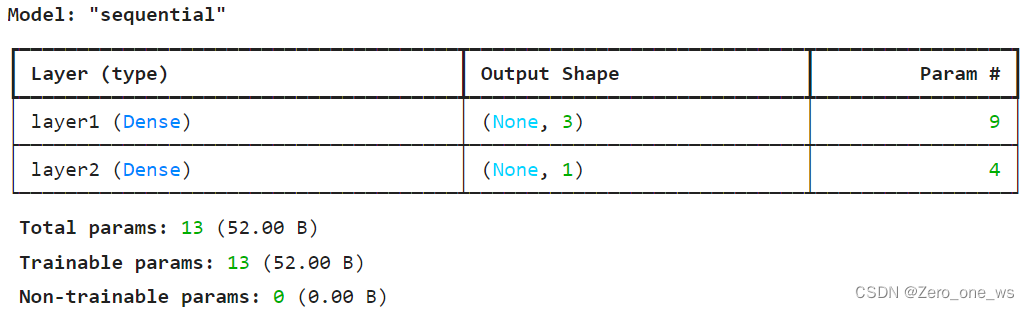
# 打印网络框架模型参数
model.summary()
# 编译模型
model.compile(
loss = tf.keras.losses.BinaryCrossentropy(),
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01),
)
# 用训练数据拟合模型,计算权重
model.fit(
Xn,Y,
epochs=10,
)
# 读取打印训练后的权重
W1, b1 = model.get_layer("layer1").get_weights()
W2, b2 = model.get_layer("layer2").get_weights()
print("W1:\n", W1, "\nb1:", b1)
print("W2:\n", W2, "\nb2:", b2)(创建了1个包含3个神经元、激活函数用sigmoid的隐藏层,损失函数(losses)用BinaryCrossentropy,优化器(optimizers)用Adam,训练次数(epochs)为10次)
运行以上代码,结果如下:

(5)数据预测
# 读取需预测的数据
X_test = np.array([
[190,13],
[200,17]])
# 数据正则化
X_testn = norm_l(X_test)
# 结果预测
predictions = model.predict(X_testn)
# 将计算结果转化为0/1显示
yhat = (predictions >= 0.5).astype(int)
print(f"decisions = \n{yhat}")运行以上代码,结果如下:
decisions =
[[0]
[0]]
05 总结
(1)人工神经网络实质上是个复杂的自动化回归模型,由若干算法组合而成、可以循环计算、自动更新权重和学习率等参数。
(2) 人工神经网络构建步骤:定义框架>编译模型>训练模型,训练模型的核心工作是前向传播(计算预测值和损失)和反向传播(计算梯度并更新权重)。















 5518
5518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









