







目录
01 学习目标
(1)掌握多项式回归模型的求解和优化
(2)掌握神经网络模型的训练和优化
(3)理解模型优劣影响因素和判别标准
02 导入计算所需模块
import numpy as np
%matplotlib widget
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.activations import relu,linear
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.optimizers import Adam
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
from public_tests_a1 import *
tf.keras.backend.set_floatx('float64')
from assigment_utils import *
tf.autograph.set_verbosity(0)03 多项式回归模型进阶
3.1 数据集划分
当我们拿到一份数据,并依此采用机器学习方法训练出一个漂亮的(cost≈0)多项式回归模型,准备用它预测新数据时,可能预测效果并不尽如人意,如下图:
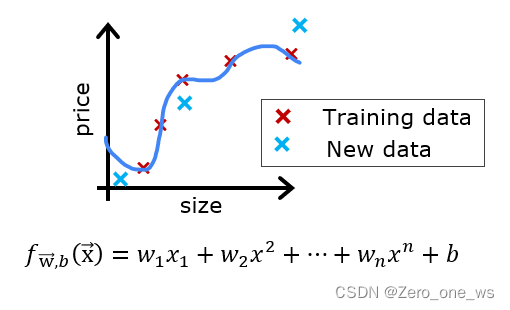
看来模型并不好!那我们怎么在它投入使用前就对model进行评价,知道它好与不好呢?
解决办法就是:将数据集一拆为三!——60%作为“训练集(training set)”、20%作为“交叉验证集(cross-validation set)”、20%作为“测试集(test set)”.。训练集用来训练模型参数w和b、交叉验证集用来训练多项式的自由度(最高次幂数)、测试集用来测试模型好与不好。
(Example)数据生成、set划分:
# 生成数据
X,y, x_ideal,y_ideal = gen_data(40, 5, 0.7)
# 划分数据集
X_train, X_, y_train, y_ = train_test_split(X,y,test_size=0.40, random_state=1)
X_cv, X_test, y_cv, y_test = train_test_split(X_,y_,test_size=0.50, random_state=1)
# 数据可视化
fig, ax = plt.subplots(1,1,figsize=(4,4))
ax.scatter(X_train, y_train, color = "red", label="train")
ax.scatter(X_cv, y_cv, color = dlc["dlorange"], label="cv")
ax.scatter(X_test, y_test, color = dlc["dlblue"], label="test")
ax.legend(loc='upper left')
plt.show()运行以上代码,结果如下:

3.2 寻找最优解
如下图所示,当按6:2:2划分为3个数据集后,随多项式最高次幂增大,训练集的成本逐渐减小而交叉验证集的成本先减后增,交叉验证集成本最小处的次幂数即是最优解。

(Example)采用sklearn进行多项式回归:
max_degree = 9
err_train = np.zeros(max_degree)
err_cv = np.zeros(max_degree)
x = np.linspace(0,int(X.max()),100)
y_pred = np.zeros((100,max_degree)) #columns are lines to plot
# 计算1次幂至9次幂,结果保存至y_pred
for degree in range(max_degree):
lmodel = lin_model(degree+1)
lmodel.fit(X_train, y_train)
yhat = lmodel.predict(X_train)
err_train[degree] = lmodel.mse(y_train, yhat)
yhat = lmodel.predict(X_cv)
err_cv[degree] = lmodel.mse(y_cv, yhat)
y_pred[:,degree] = lmodel.predict(x)
# 最优次幂
optimal_degree = np.argmin(err_cv)+1
# 结果可视化,示出所有次幂拟合结果
plt.close("all")
plt_optimal_degree(X_train, y_train, X_cv, y_cv, x, y_pred, x_ideal, y_ideal,
err_train, err_cv, optimal_degree, max_degree)运行以上代码,结果如下:
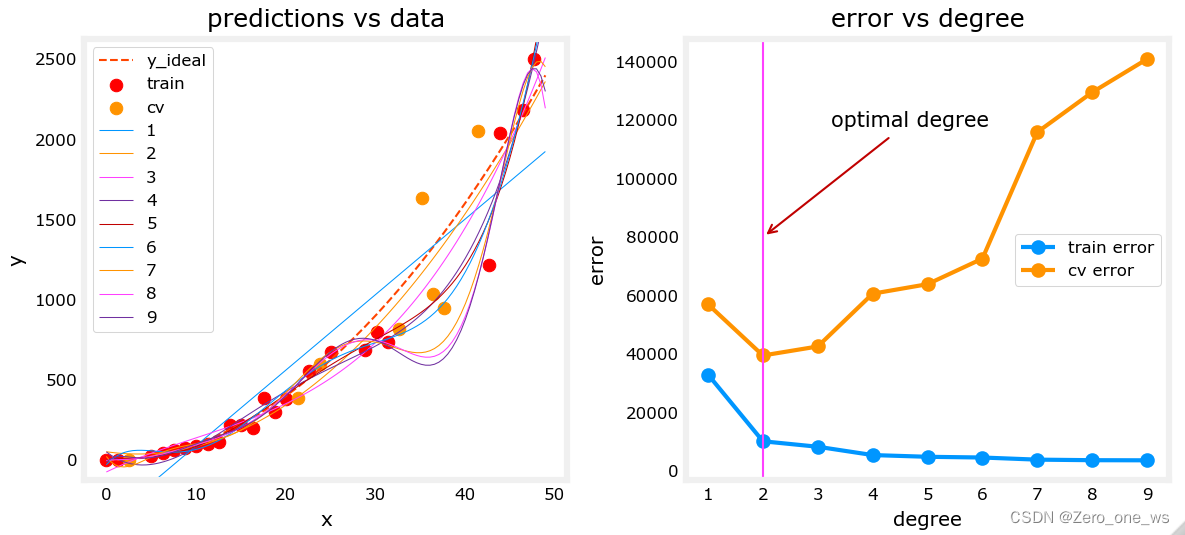
原理: 方差和偏差是机器学习中评估模型性能的两个重要方面。偏差是预测值与真实值之间的差距,方差是每个样本值与全体样本值的平均数之差的平方值的平均数。偏差描述了模型预测的平均误差,而方差描述了在不同训练集上模型预测结果的波动程度。degree(次幂数)很小时,模型存在较高的偏差(high bias),degree很大时,模型存在较高的方差(high variance)。因此,在大小不同的数据集上均稳定表现且成本较小的模型,同时具有较小的偏差和方差,当然也就是最优模型。
3.3 正则优化
模型的不好还有两种表现:过拟合和欠拟合。如果最优次幂是3次幂,我们训练的模型为2次幂时,此时为欠拟合,具有较高的偏差;若我们训练的模型为5次幂时,此时为过拟合,具有较高的方差。两种情况均不能很好地预测新数据。
通过对成本正则化处理可以解决过拟合(高次幂)问题,关键是找到合适的正则参数λ。
(Example)针对上述数据进行10次幂拟合,并正则化处理:
lambda_range = np.array([0.0, 1e-6, 1e-5, 1e-4,1e-3,1e-2, 1e-1,1,10,100])
num_steps = len(lambda_range)
degree = 10
err_train = np.zeros(num_steps)
err_cv = np.zeros(num_steps)
x = np.linspace(0,int(X.max()),100)
y_pred = np.zeros((100,num_steps)) #columns are lines to plot
# lin_model为自定义的类,用于多项式拟合
for i in range(num_steps):
lambda_= lambda_range[i]
lmodel = lin_model(degree, regularization=True, lambda_=lambda_)
lmodel.fit(X_train, y_train)
yhat = lmodel.predict(X_train)
err_train[i] = lmodel.mse(y_train, yhat)
yhat = lmodel.predict(X_cv)
err_cv[i] = lmodel.mse(y_cv, yhat)
y_pred[:,i] = lmodel.predict(x)
optimal_reg_idx = np.argmin(err_cv)
# 可视化,plt_tune_regularization是自定义的函数
plt.close("all")
plt_tune_regularization(X_train, y_train, X_cv, y_cv, x, y_pred, err_train, err_cv, optimal_reg_idx, lambda_range)运行以上代码,结果如下:
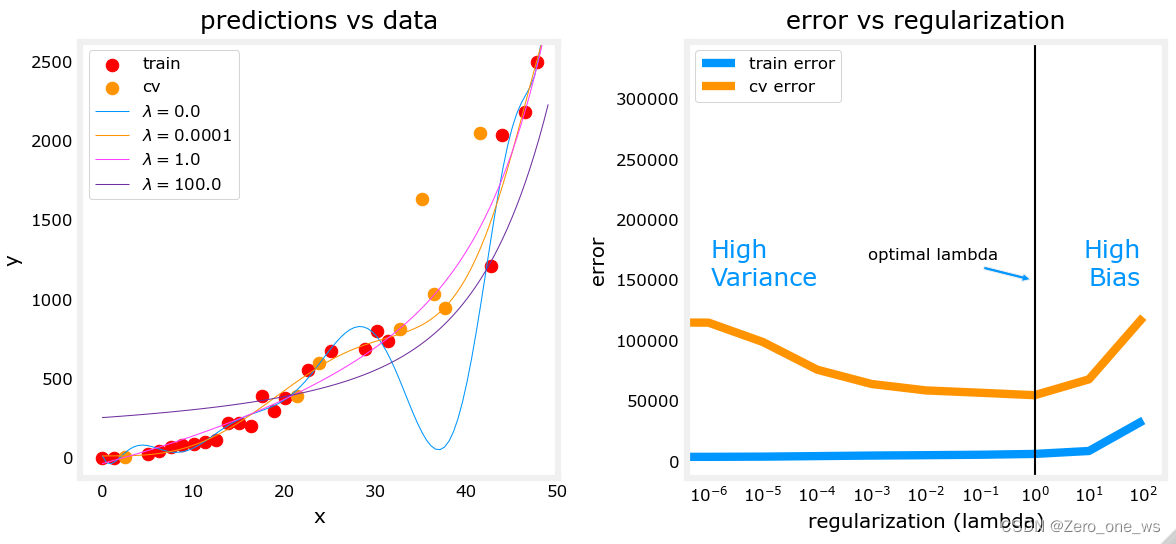
注意到,λ=1时,10次幂的模型表现与2次幂模型非常接近,在训练集和交叉验证集上较为准确地拟合到了大部分点。
原理:正则化处理即是在训练集的成本函数后增加一个正则项,用于对模型权重进行惩罚,其中参数λ用来控制正则强度。如下式:
增加正则项实际增大了训练集的成本,为减小成本就需减小相应的权重,因此,正则优化的本质是减小了高次幂特征项的权重来降低复杂度(比如)。
3.4 增大数据量
以上仅采用40个数据点,拟合的多项式最优次幂数为2次,我们尝试增大数据量看下16次幂模型的表现:
# tune_m和plt_tune_m是吴恩达老师定义好的函数
X_train, y_train, X_cv, y_cv, x, y_pred, err_train, err_cv, m_range,degree = tune_m()
plt_tune_m(X_train, y_train, X_cv, y_cv, x, y_pred, err_train, err_cv, m_range, degree)运行以上代码,结果如下:
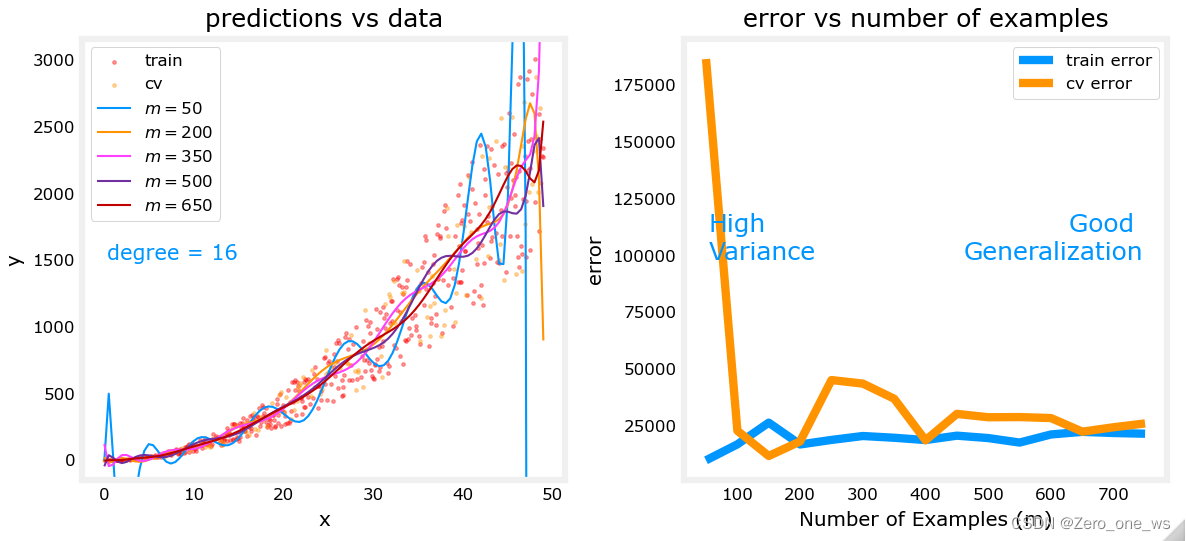
注意到,增大数据量可以降低方差,解决过拟合问题;但实际上,增大数据量并不能解决高偏差也就是欠拟合问题。
04 神经网络模型进阶
4.1 数据准备
(Example)以多分类问题为例,生成6类数据点,并划分为train、cv、test三个数据集:
# 数据生成并划分数据集
X, y, centers, classes, std = gen_blobs()
# split the data. Large CV population for demonstration
X_train, X_, y_train, y_ = train_test_split(X,y,test_size=0.50, random_state=1)
X_cv, X_test, y_cv, y_test = train_test_split(X_,y_,test_size=0.20, random_state=1)
print("X_train.shape:", X_train.shape, "X_cv.shape:", X_cv.shape, "X_test.shape:", X_test.shape)
# 数据可视化
plt_train_eq_dist(X_train, y_train,classes, X_cv, y_cv, centers, std)运行以上代码,结果如下:
![]()
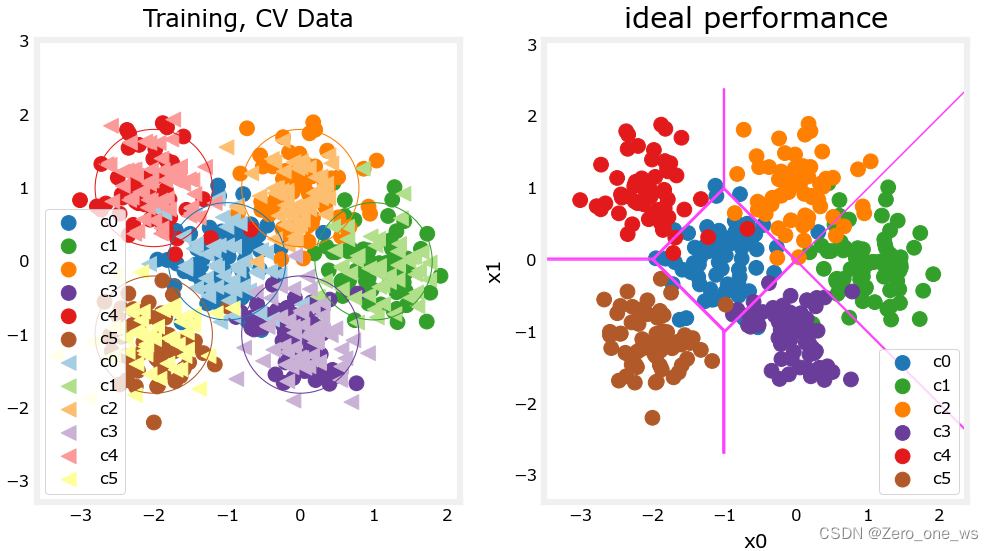
上面示例我们生成了800个数据点,以该数据训练人工神经网络模型,我们理想的模型应该如右图,即类与类之间存在清楚的分界线,而不是左图那样,有的数据既属于A类又属于B类。
4.2 模型复杂度
我们在拿到一份的数据后,可能没有足够的经验确定神经网络的隐藏层数和其中的神经元个数,那我们下面拿一个“复杂模型”和一个“简单模型”分别对上面的数据进行训练,看下复杂度对模型的影响。
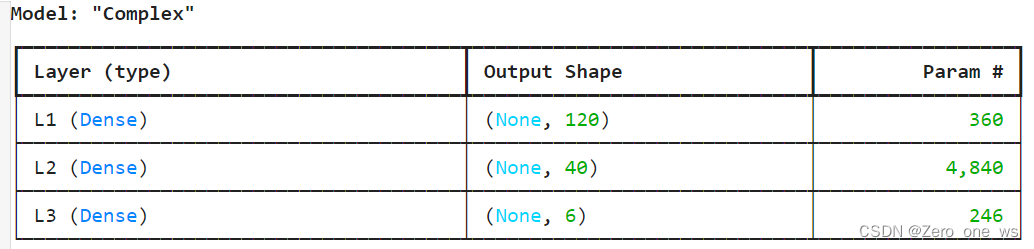
(Example)具有2个隐藏层、160个神经元的复杂模型:
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.random.set_seed(1234)
model = Sequential(
[
Dense(120, activation = 'relu', name = 'L1'),
Dense(40, activation = 'relu', name = 'L2'),
Dense(6, activation = 'linear', name = 'L3')
], name="Complex"
)
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(0.01),
)
model.fit(
X_train, y_train,
epochs=1000
)
model.summary()
# 训练结果可视化
model_predict = lambda Xl: np.argmax(tf.nn.softmax(model.predict(Xl)).numpy(),axis=1)
plt_nn(model_predict,X_train,y_train, classes, X_cv, y_cv, suptitle="Complex Model")运行以上代码,结果如下:
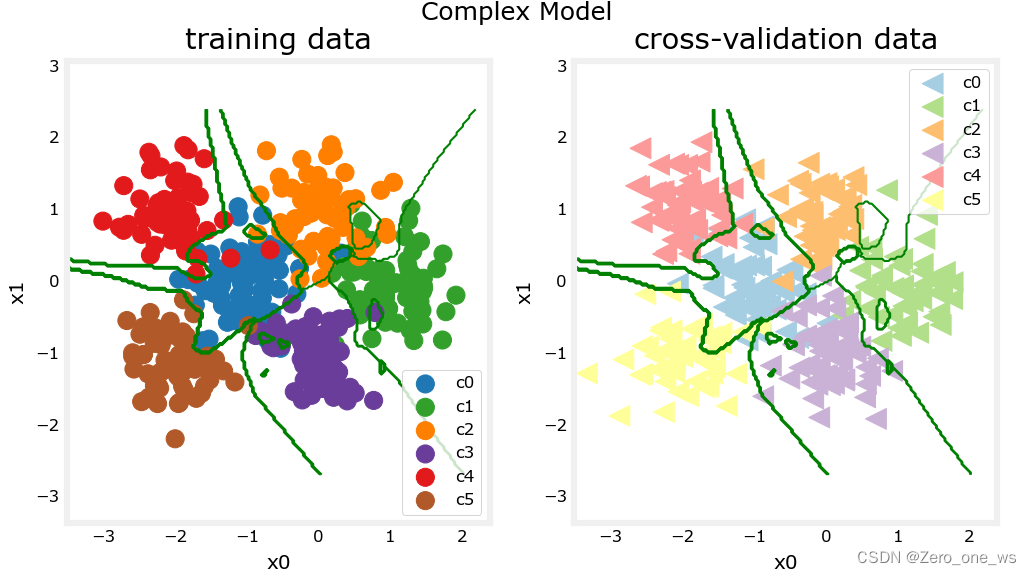
注意到, 模型在训练集上准确地识别到了所有的点,成本为0.020;而在交叉验证集上却出现不少识别错误的情况,成本为0.113;类与类之间边界曲折复杂。
(Example)具有1个隐藏层、6个神经元的简单模型:
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.random.set_seed(1234)
model_s = Sequential(
[
Dense(6, activation = 'relu', name = 'L1'),
Dense(6, activation = 'linear', name = 'L2')
], name = "Simple"
)
model_s.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(0.01),
)
model_s.fit(
X_train,y_train,
epochs=1000
)
model.summary()
# 训练结果可视化
model_predict_s = lambda Xl: np.argmax(tf.nn.softmax(model_s.predict(Xl)).numpy(),axis=1)
plt_nn(model_predict_s,X_train,y_train, classes, X_cv, y_cv, suptitle="Simple Model")运行以上代码,结果如下:

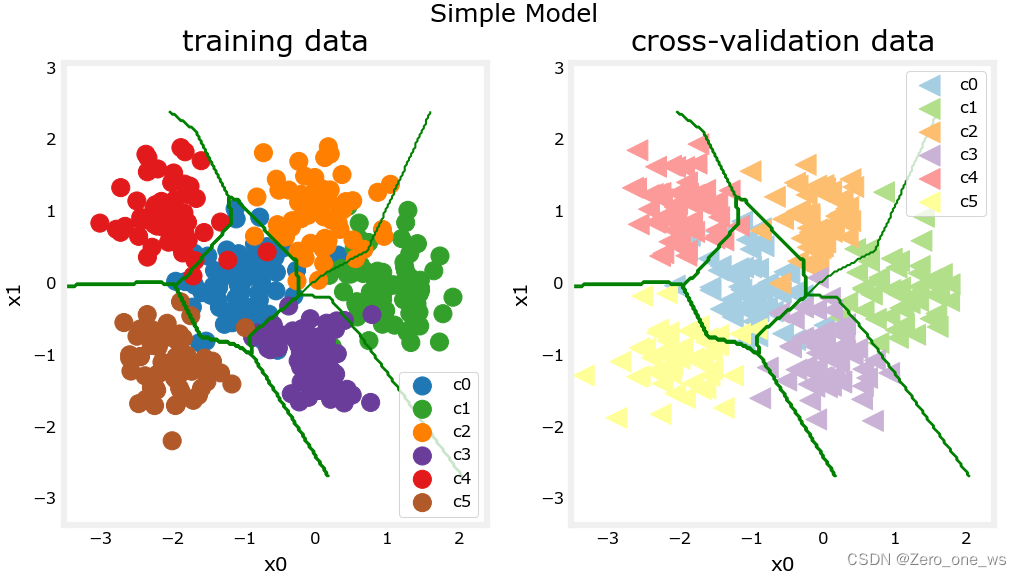
注意到,模型在训练集上较为准确地识别到了大部分点,成本为0.068;在交叉验证集上的情况也差不多、识别错误较少,成本为0.072;类与类之间边界简单清晰明了。
4.3 正则优化
与多项式回归模型的正则优化类似,神经网络模型同样可以采用正则优化。正则化有L1正则化和L2正则化两种(正则项分别取L1、L2范数),L1使部分权重系数为零、矩阵稀疏,L2避免某些权重系数过大造成模型过拟合、权重平滑连续。在前述多项式回归模型的成本函数中,采用的是L2正则化。
(Example)以前述“复杂模型”为例,采用L2正则化、λ=0.1:
tf.random.set_seed(1234)
model_r = Sequential(
[
Dense(120, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.1), name = 'L1'),
Dense(40, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.1), name = 'L2'),
Dense(6, activation = 'linear', name = 'L3'),
], name= 'Regul'
)
model_r.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(0.01),
)
model_r.fit(
X_train, y_train,
epochs=1000
)
# 训练结果可视化
model_predict_r = lambda Xl: np.argmax(tf.nn.softmax(model_r.predict(Xl)).numpy(),axis=1)
plt_nn(model_predict_r, X_train,y_train, classes, X_cv, y_cv, suptitle="Regularized")运行以上代码,结果如下:
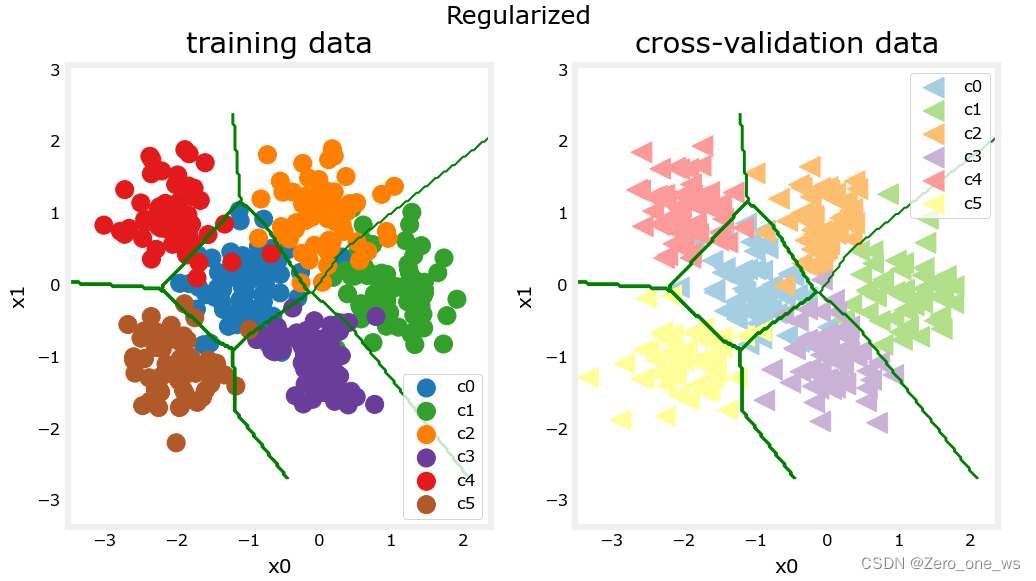
注意到,经过正则优化的模型在训练集上较为准确地识别到了大部分点,成本为0.075;在交叉验证集上的情况也差不多、识别错误较少,成本为0.069;类与类之间边界简单清晰明了。
05 总结
(1)机器学习的模型好与不好可归咎于偏差与方差问题,模型高偏差:J_train高、J_cv高;模型高方差: J_train低、J_cv高;理想的模型:J_train低、J_cv低。
(2)高偏差处理方法:①增加特征数②增加最高次幂(多项式)③减小正则参数λ;高方差处理方法:①增加数据量②减少特征数③增大正则参数λ。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









