







ImagePipeline的使用
今天我学习了scrapy框架中的ImagePipeline,因此我用ImagePipeline来下载图片,我下载的是SOL(中关村)桌面壁纸图片
 1. 找到要下载图片的url
1. 找到要下载图片的url

2. 创建一个图片项目
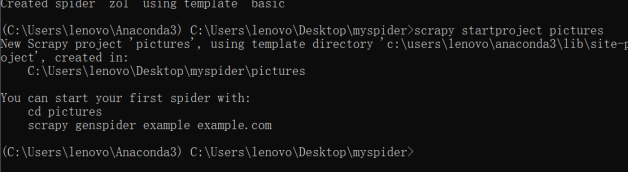
3. 创建一个爬虫文件
4. 在zol.py中写入图片的网址和名称
# -*- coding: utf-8 -*-
import scrapy
class ZolSpider(scrapy.Spider):
name = 'zol'
allowed_domains = ['zol.com.cn']
start_urls = ['http://desk.zol.com.cn/bizhi/8886_109251_2.html']
def parse(self, response):
image_url=response.xpath('//img[@id="bigImg"]//@src').extract()
image_name=response.xpath('string(//h3)').extract_first()
yield {
"image_urls":image_url,
"image_name":image_name
}
next_url=response.xpath('//a[@id="pageNext"]/@href').extract_first()
if next_url.find('.html')!=-1:
yield scrapy.Request(response.urljoin(next_url),callback=self.parse)-
在Pipelines.py中导入from scrapy.pipelines.images import ImagesPipeline和
import scrapy -
在Pipelines.py中引入一个类class ImagePipeline(ImagesPipeline),并写入两个函数def get_media_requests(self, item, info)和def file_path(self, request, response=None, info=None),这两个函数在images.py中可以找到

# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class PicturesPipeline:
def process_item(self, item, spider):
return item
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item["image_urls"]:
yield scrapy.Request(image_url,meta={"image_name":item["image_name"]})
def file_path(self, request, response=None, info=None):
file_name=request.meta["image_name"].strip().replace('\r\n\t\t','')+'jpg'
file_name=file_name.replace('/','-')
return file_name- 在settings.py中修改需要的内容(设置User-Agent,图片路径等)
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'# Obey robots.txt rules
ROBOTSTXT_OBEY = FalseITEM_PIPELINES = {
'pictures.pipelines.ImagePipeline': 300,
}
IMAGES_STORE='C:\\Users\\lenovo\\Pictures\\pictures'注意:ITEM_PIPELINES中的ImagePipeline一定要和pipelines.py中的class ImagePipeline(ImagesPipeline)类名一样,不然图片名称无法修改
- 在pycharm中执行程序
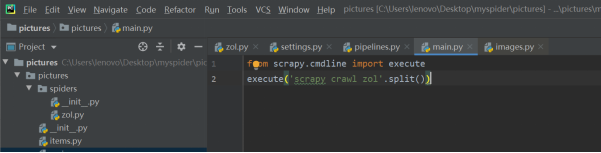
- 运行程序,查看结果
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









