







Pytorch学习笔记-04 权值初始化与损失函数
文章目录
权值初始化
Xavier初始化
方差一致性:保持数据尺度维持在恰当范围,通常方差为 1
10种初始化方法
- Xavier 均匀分布
- Xavier 正态分布
- Kaiming 均匀分布
- Kaiming 正态分布
- 均匀分布
- 正态分布
- 常数分布
- 正交矩阵初始化
- 单位矩阵初始化
- 稀疏矩阵初始化
损失函数
损失函数:衡量模型输出与真实标签的差异
nn.CrossEntropyLoss
功能:nn.LogSoftmax 与 nn.NLLLoss 结合 ,进行交叉熵计算
主要参数:
- weight :各类别的 loss 设置权值
- ignore_index :忽略某个类别
- reduction :计算模式,可为 none/sum/mean
- none逐个元素计算
- sum所有元素求和,返回标量
- mean加权平均,返回标量
nn.NLLLoss
功能:实现负对数似然函数中的 负号功能
主要参数:
- weight :各类别的 loss 设置权值
- ignore_index :忽略某个类别
- reduction :计算模式,可为 none/sum/mean
- none逐个元素计算
- sum所有元素求和,返回标量
- mean加权平均,返回标量
nn.BCELoss
功能:二分类交叉熵
注意事项:输入值取值在[0,1]
主要参数:
- weight :各类别的 loss 设置权值
- ignore_index :忽略某个类别
- reduction :计算模式,可为 none/sum/mean
nn.BCEWithLogitsLoss
功能:结合Sigmoid 与 二分类交叉熵
注意事项:网络最后不加sigmoid 函数
主要参数:
- pos_weight :正样本的权值
- weight :各类别的 loss 设置权值
- ignore_index :忽略某个类别
- reduction :计算模式,可为 none/sum/mean
其他loss
-
nn.L1Loss
计算 inputs 与 target 之差的绝对值
-
nn.MSELoss
功能:计算 inputs 与 target 之差的平方
-
nn.SmoothL1Loss
-
nn.PoissonNLLLoss
- 功能:泊松分布的负对数似然损失函数
-
nn.KLDivLoss
- 功能:计算KLD divergence KL 散度,相对熵
- 注意事项:需提前将输入计算 log probabilities
如通过nn.logsoftmax
-
nn.MarginRankingLoss
- 功能:计算两个向量之间的相似度 ,用于排序任务
- 特别说明:该方法计算两组数据之间的差异,返回一个 n*n的 loss 矩阵
-
nn.MultiLabelMarginLoss
- 多标签分类函数
-
nn.SoftMarginLoss
- 功能:计算二分类的 logistic 损失
-
nn.MultiLabelSoftMarginLoss
- 功能:SoftMarginLoss 多标签版本
-
nn.MultiMarginLoss
- 功能:计算多分类的折页损失
-
nn.TripletMarginLoss
-
功能:计算三元组损失,人脸验证中常用
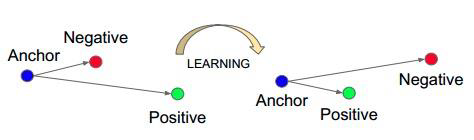
-
-
nn.HingeEmbeddingLoss
- 功能:计算两个输入的相似性,常用于非线性embedding 和半监督学习
-
nn.CosineEmbeddingLoss
- 功能:采用余弦相似度计算两个输入的相似性
-
nn.CTCLoss
- 计算 CTC 损失,解决时序类数据的分类 Connectionist Temporal Classification
优化器
pytorch的优化器: 管理 并 更新 模型中可学习参数的值,使得模型输出更接近真实标签
e.g.
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001
基本属性:
- defaults :优化器超参数
- state :参数的缓存,如 momentum 的缓存
- params_groups :管理的参数组
- step_count :记录更新次数,学习率调整中使用
基本方法
- zero_grad ():清空所管理参数的梯度
- pytorch特性: 张量梯度不自动清零
- step()step():执行一步更新
- add_param_group ():添加参数组
- state_dict ():获取优化器当前状态信息 字典
- load_state_dict ():加载状态信息字典
十种优化器
- optim.SGD :随机梯度下降法
- optim.Adagrad :自适应学习率梯度下降法
- optim.RMSprop Adagrad 的改进
- optim.Adadelta Adagrad 的改进
- optim.Adam RMSprop 结合 Momentum
- optim.Adamax Adam 增加学习率上限
- optim.SparseAdam :稀疏版的 Adam
- optim.ASGD :随机平均梯度下降
- optim.Rprop :弹性反向传播
- optim.LBFGS BFGS 的改进
学习率调整策略
classLRScheduler
主要属性:
- optimizer :关联的优化器
- last_epoch :记录 epoch 数
- base_lrs :记录初始学习率
主要方法:
- step() 更新 下一个 epoch 的学习率
StepLR
功能:等间隔调整学习率
主要参数:
- step_size :调整间隔数
- gamma :调整系数
MultiStepLR
功能:按给定间隔调整学习率
主要参数:
- milestones :设定调整时刻数
- gamma :调整系数
ExponentialLR
功能:按指数衰减调整学习率
主要参数:
- gamma :指数的底
CosineAnnealingLR
功能:余弦周期调整学习率
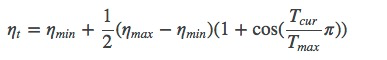
主要参数:
- T_max :下降周期
- eta_min :学习率下限
ReduceLRonPlateau
功能:监控指标,当指标不再变化则调整
主要参数:
- mode min/max 两种模式
- factor :调整系数
- patience :“耐心”,接受几次不变化
- cooldown :“冷却时间”,停止监控一段时间
- verbose :是否打印日志
- min_lr :学习率下限
- eps :学习率衰减最小值
LambdaLR
功能:自定义调整策略
主要参数:
- lr_lambda: function or list
学习率调整小结
- 有序调整: Step 、 MultiStep 、 Exponential 和 CosineAnnealing
- 自适应调整: ReduceLROnPleateau
- 自定义调整: Lambda
学习率初始化
- 设置较小数: 0.01 、 0.001 、 0.0001
r :学习率下限 - eps :学习率衰减最小值
LambdaLR
功能:自定义调整策略
主要参数:
- lr_lambda: function or list
学习率调整小结
- 有序调整: Step 、 MultiStep 、 Exponential 和 CosineAnnealing
- 自适应调整: ReduceLROnPleateau
- 自定义调整: Lambda
学习率初始化
- 设置较小数: 0.01 、 0.001 、 0.0001
- 搜索最大学习率: 《 Cyclical Learning Rates for Training Neural Networks 》
















 2289
2289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











