







Multi-view adaptive graph convolutions for graph classification
文章目录
Abstract
本文提出了一种新型的基于图的神经网络的多视图方法。针对非欧几里得流形,对经典深度学习方法的关键概念,如卷积、池化和多视图架构,进行了系统和方法上的调整。
本文工作的目的是提出一个新的多视图图卷积层,以及一个新的视图池层,利用:
- a)一个新的混合拉普拉斯矩阵,基于特征距离度量学习进行调整;
- b)一个图的特征矩阵的多个可训练表示,使用可训练距离矩阵,将视图的概念适应于图;
- c)一个称为图视图池的多视图图聚合方案,以综合来自多个生成的 "视图 "信息。
上述各层被用于一个端到端的图神经网络架构中,用于图分类,并显示出与其他最先进的方法相比具有竞争力的结果。
1 Introduction
图可以有力地表示数据之间的关系。由于图的应用领域广泛,从生物结构到现代社会网络,图表示以及最近爆炸性增长的图神经网络(GNNs)领域,帮助我们在神经网络的帮助下重新解决与图有关的挑战性任务。
为此,将经典卷积神经网络(CNN)的操作,如卷积和池化,适应于非欧几里得领域(如图和流形)的任务,产生了几何深度学习的新兴领域。
本文提出了一种用于图分类任务的灵活的多视图GNN结构,它将结构和信号信息传播到整个网络。为此,提出了一种新型的多视图图卷积层,利用混合拉普拉斯,将特征空间的信息与输入图的结构相结合。随后,提出使用多个可训练的距离度量来应对训练的不稳定性和过拟合,因为事实证明,单一距离度量的学习容易出现过拟合[17]。最后,通过对图的信号进行频谱过滤,将不同的混合拉普拉斯系数与每个 "视图 "联系起来,计算出每个 "视图 "的投影信号。
2 Related work
最近的一些方法试图设计探索不同图结构的架构。在这个方向上,MGCN[22]被开发出来,通过多维切比雪夫多义词对多关系图关系进行封装。在GCAPS-CNN[45]中,作者在谱系GNN中引入了cap-sules的概念,以封装每个顶点特征的局部高阶统计信息。在一项近似的工作中,CAPS-GNN[46]通过计算手工制作的统计数据来探索额外的顶点信息。 然而,这两种方法都明确地计算了额外的顶点信息,而它们并不涉及任何可训练的组件。
在[41]中引入了 "视图 "的概念,每个 "视图 "代表一个三维物体从不同角度的二维投影,以产生为对象识别和检索的任务提供信息表征。在[54]中,作者使用了 "视图 "的概念来构建不同的大脑图形,其中结构是由结构性MRI扫描确定的,特征矩阵是由基于扩散MRI采集的多种束学算法计算的,以融合分散在不同医学成像模式中的信息,进行成对相似性预测。然而,上述基于视图的方法都没有引入可训练的任务驱动的视图生成,而我们的方法就是这样。
大多数的图卷积方法都是基于将图的特征投射到一个单一的图结构中。我们的方法背后的动机是,"视图 "是从一个共同的输入中人为创建的。这些,可以提取不同的学习表征,就像三维物体被投射到二维图像上并独立处理一样。然而,与以前的方法相比,生成的 "视图 "是可训练的,这是一个新颖的、未曾探索过的领域。
3 Proposed method
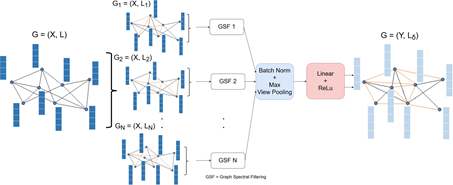
拟议的工作受到[41]和[54]的启发,使用由共享输入(即人类视觉)产生的 "视图 "概念。所提出的多视图图卷积(MV-GC)层的关键思想是,在每个 "视图 "中,从特征空间中顶点的成对马兰诺比斯距离[8]中构建一个不同的n个完整图(Kn)。因此,在距离度量学习的背景下,每个 "视图 "都囊括了顶点之间的不同关系。这一信息通过所谓的混合拉普拉斯在MV-GC层进行编码。混合拉普拉斯是输入图的拉普拉斯多视图自适应图卷积5和基于非欧氏距离的拉普拉斯项的线性组合,从现在起称为 "视图 "拉普拉斯,来自上述Kn图。因此,光谱图卷积被一个不同的混合拉普拉斯特征空间所近似,产生了同一图形信号的多个可学习的投影。因此,应用[19]中的批量归一化和视图最大池化操作,从现在开始称为视图池化 "层(VPOOL),产生一个聚合的图输出信号。与其他现有的在整个网络中保持图形结构不变的方法[21]相比,在提议的方法中,内在的图形结构在GNN的学习过程中被改变了。整个过程可以用图1来说明。
通过www.DeepL.com/Translator(免费版)翻译
网络使用由共享输入,产生"视图 "。
所提出的多视图图卷积(MV-GC)层的关键思想是,在每个 "视图 "中,从特征空间中成对的Mahalanobis距离中构建一个不同的n个完整图(Kn)。
每个 "视图 "都囊括了距离度量学习背景下顶点之间的不同关系。这一信息通过所谓的混合拉普拉斯在MV-GC层进行编码。
混合拉普拉斯是对输入图的拉普拉斯的线性组合和一个基于非欧几里得距离的拉普拉斯项。
3.1 Notations and prerequisites
为了提高本文的可读性,对本文所用的记号和一些初步的背景理论进行了总结。图G定义为G=(V,E),其中V是顶点集,E是边集,其中Eij∈E定义为(vi,vj),vi,vj∈V。考虑顶点的特征空间,n个顶点的图的替换表示可以是G=(A,X),其中A∈rn×n是邻接矩阵,X=[x1,x2,…,xn]∈rn×d是图的特征矩阵,其中因此,将图拉普拉斯定义为L=D−A,其中D∈Rn×n是(D)ii=∑j(A)ij的对角度矩阵。最后,定义了拉普拉斯算子的一个常用的标准化版本,如下所示:
范数是实对称的半正定矩阵,它由正交特征向量及其有序的实非负本征值λi组成的完备集,其中i=[0,n−1]。另外,由于L范数的特征值位于[0,λ最大]的范围内,λ最大≤为2,因此在图谱卷积中得到了广泛的应用。对于任意正半定矩阵和向量x,y,广义马氏距离定义为:对于任意正半定矩阵和向量x,y,具有变换矩阵M的广义马氏距离定义为:(1)对于任意正半定矩阵和向量x,y,广义马氏距离定义为:(1)对于任意正半定矩阵和向量x,y,广义马氏距离定义为:
T表示转置操作。上面的方程可以用协方差矩阵C=M−1来表示向量x和y之间的相异性的定量度量,这两个向量取自相同的分布。对于M=i,等式。2降为欧几里得距离。后者假设不同维度之间的方差为1,协方差为零,这在实际应用中很少出现。
3.2 Construction of the hybrid Laplacian
最初创建每个图G=(A,X),N个“视图”。每个“视图”与特征变换矩阵MV∈Rd×d和v∈[1,.,N]相关联,每个MV是定义为MV=QvQTv∈Rd×d的正半定矩阵,其中Qv在学习过程开始时被随机初始化。
特别地,分别取第i和第j个顶点的特征向量xi和xj之间的广义马氏距离如下:
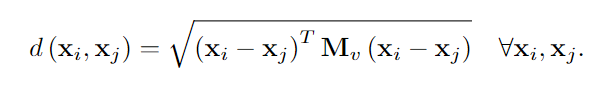
此外,特征差矩阵F∈rc×d(c=12n(n−1))被定义为唯一顶点对(vi,vj)∈V之间的所有特征差的矩阵,而不考虑它们在E中的连通性
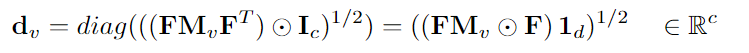
上述步骤是必要的,因为它显著减少了所需的内存(参见SEC。3.4),并允许以端到端的方式训练网络。在学习过程中,试图通过反向传播从给定的数据中学习优化的有监督距离计量,从而最小化GNN的图分类损失。DV的唯一距离对被放回到“视图”距离矩阵Hv∈Rn×n中。使用高斯核将每个“视图”相似性矩阵定义为:
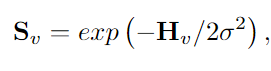
其中σ是标准差,h∈[1,.,N]的混合拉普拉斯算子LH的计算公式为:LH=LIN+αLv,(9)其中Lv=in−D−1/2SvD−1/2,LIN是输入图的拉普拉斯算子。
每个“视图”的贡献由标量值α控制,该值设置为1,以避免额外的超参数调整。LV表示n个完全图(Kn),C=12n(n−,1)个基于特征差和可训练距离矩阵MV的加权边。对于每个视图v,我们只根据图的特征,通过考虑不同的可训练Qv来计算Lv,从而计算不同的距离;但是,由于我们想要保持原有图的结构,我们通过将Lin添加到Lv来传播输入图的连通性。
这样做,我们还模仿成功的资源网络体系结构,将前一层的输出传播到后层(所谓的“身份连接快捷方式”)。所有这些都有助于更快地收敛和遇到早期层中的消失梯度问题。
3.3 Construction of the graph output signal
对于输入图形G,堆叠N个图形信号Zs=[X1,X2,…,XN],以及N个混合拉普拉斯LS=[L1,L2,…,LN]。然后,将批标准化应用于Z,然后是视图最大聚合步骤(VPOOL)。这样,由于批量规范化,VPOOL层对于QV的随机初始化变得不变,并且由于聚合步骤,还融合了从不同“视图”捕获的信息。聚集的视图池信号具有共享特征矩阵,然后将其传递到线性层,其后是非线性激活函数σ和丢弃层(Dropout Layer)(丢弃)(Dropout Layer(Drop))[40]。必须注意的是,对Z进行批量归一化可以很好地应用来自不同视图的图形信号具有零均值和聚集输出中的激活函数。从字面上看,上面的所有步骤都可以用下面的方程式来概括:
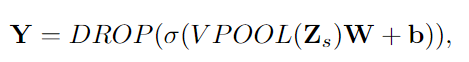
其中Y∈Rn×m是图形输出信号,m是输出特征的数目。线性层参数为W∈Rk·d×m,b∈Rm。在此基础上,假设不同图之间的特征空间具有恒定维数(即同一数据集的不同图之间的d是恒定的),所提出的方法可以处理不同数目的输入顶点。换句话说,在等式13中,模型参数仅依赖于切比雪夫度K和特征向量;因此与图的顶点无关。此外,线性层学习处理来自多个视图的聚合紧凑信号,从而获得更好的泛化特性。此外,基于VPOOL的索引,将对应的最频繁的混合拉普拉斯传递到下一层,我们称之为定义为L_δ的“主导”混合拉普拉斯,还对L_s进行了最大和平均视图合并测试,给出了略差的结果。
最后,整个多视图GNN体系结构由三个MV-GClayer组成,每个MV-GClayer后面跟着一个VPOOL和一个线性层,如等式所示。13.在第一MV-GC层中,根据邻接矩阵计算输入拉普拉斯,如公式所示。1,我们称之为intrinsic 拉普拉斯。
在其余的层中,前一层的“主导”拉普拉斯L-δ是下一层的输入拉普拉斯。m的选择提供了调整可训练参数的数量和模型复杂度的灵活性。对于m>K·d,线性层充当编码层(通常是我们体系结构的第一层),而对于m<K·d,线性层充当解码层。在最后一层,与[6]和[48]类似,将均值和最大运算符应用于跨顶点维的图形输出信号,并将其进一步拼接。这一步骤进一步聚合了学习到的特征,同时降低了复杂性。然后将串联的输出要素馈送到2个完全连接的层。对于预测,使用软最大函数来产生最终输出̄YPRED。整个网络架构都经过端到端培训。作为损失函数,在给定yT是目标单热点向量的情况下,将交叉熵用于Q类,定义如下:
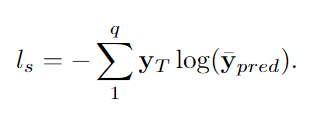
3.4 Computational complexity analysis
该方法产生稠密的图形表示。所提出的MV-GC层要求计算顶点特征之间的所有差异,其差值为O(N2)。如方程式所示。7、利用距离矩阵的对称性,只利用唯一顶点对之间的特征差异。因此,密集非方阵乘法的时间复杂度从每个视图的mo(N2d2)降低到0.5O(N2d2),Hadamard逐个元素乘法的时间复杂度从O(N2d)降低到0.5O(N2d)。虽然时间复杂度仍然是平方的,但我们可以将其缩减到原来的4倍。在目前的实现中,MV-GC层的时间复杂度与视图的数量呈线性关系,但是,每个视图所需的操作是完全独立的,可以并行实现。此外,等式所需的空间复杂度。7从每个视图的O(N4)减少到0.5O(N2d),使用公式。3.如文献[29]所述,所需的学习空间复杂度为每个视图O(D2)和每个线性层O(K·d·m),它们与顶点数无关。尽管如此,缩放我们的层以进行大图数据分析仍然是一项具有挑战性的任务,进一步的性能优化留到了未来的工作中。
4 Experimental evaluation
4.1 Dataset description and modi cations
所提出的模型(MV-AGC)在四个生物数据集和四个社会网络数据集上进行了评估,可在[20]中找到。每个数据集都有一个任意的无向图集,有n个顶点和二进制边的数量,以及一个分类图标T。
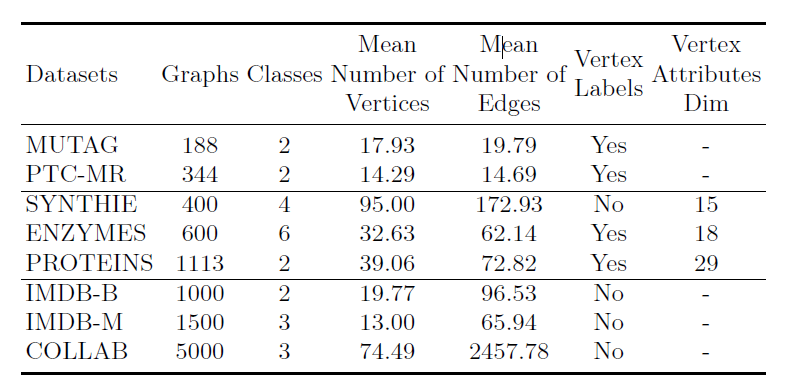
- 在MUTAG[9]中,边对应于原子键,顶点对应于原子属性。
- PTC-MR[43]是一个由344个分子图组成的数据集,其中类别表示致癌性。
- 在ENZYMES[37]中,每个酶都是顶级酶类中的一个成员。
- PROTEINS[2]由1113个图组成,顶点是其二级结构元素,两个顶点之间的边如果是三维空间中的邻居就存在。
- COLLAB[51]是一个科学合作数据集,包括来自三个物理领域的不同研究人员的5K图。
- IMDB-B和IMDB-M[50]由一起出现在电影中的演员的自我网络组成,其目标是找到电影的类型。
- SYNTHIE[31]是一个合成数据集,由400个图组成,有四个类别,每个顶点有15个连续值的属性。
表2.使用离散顶点标签的平均精度与标准偏差–生物数据集
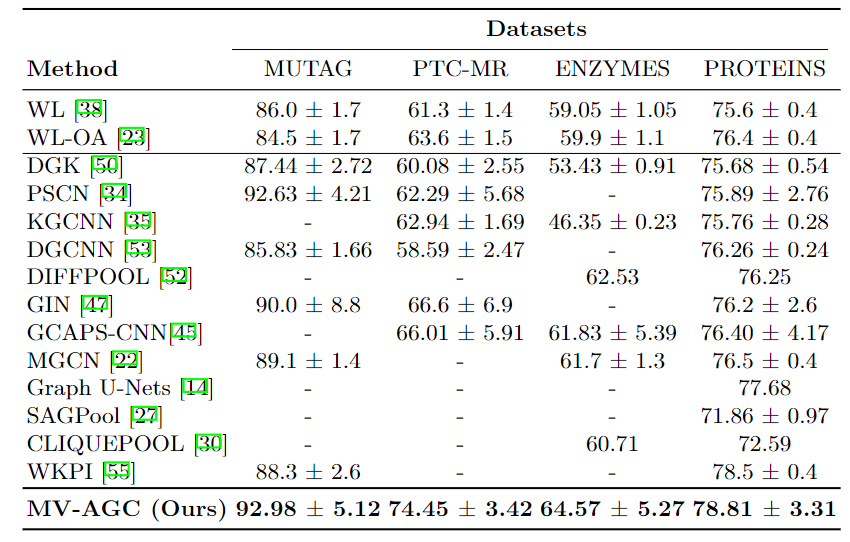
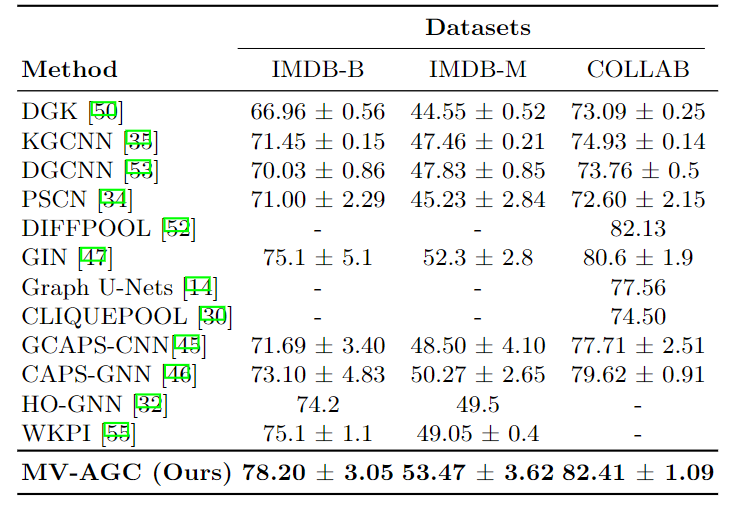
表3.使用顶点度的平均准确度与标准偏差–社交网络数据集
4.2 Implementation details
所描述的多视图GNN架构是在PyTorch[36]框架中实现的。训练是通过随机梯度下降优化器实现的,恒定的学习率从4e−4到8e不等−3,单批次大小。作为非线性激活函数,使用了ReLU。Dropout被用来避免过度拟合,主要是在小的数据集上。
在所有进行的实验中,切比雪夫度K被设置为6。隐藏的全连接层有128个单元。Qv被初始化为范围为(0,1)的随机均匀分布。 Mv在每次迭代中都被正则化,除以它的最大元素,但保留了它的理想属性。
每个MV-GC层的视图数在第一层被设置为8,其他层为6。每个数据集的epochs从COLLAB的30个到ENZYMES数据集的80个不等。对于生物信息学数据集,每个线性层的输出特征m的数量被设置为80、128和256。 对于COLLAB数据集,由于计算要求高,每个MV-GC层的视图数量较少。对于所有的数据集,实验是在具有12GB内存和16GB内存的NVIDIA GeForce GTX-1080 GPU上进行的。
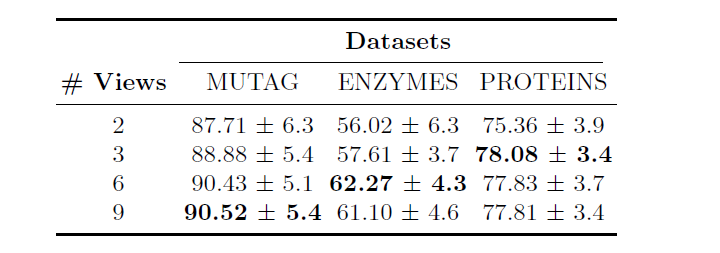
在选择模型的超参数时采用了增量训练策略,例如视图的数量。首先,我们使用了一个单一的MV-GC层,我们观察到多个视图对图形分类有很大帮助。作为理智的检查,我们检查了Q的v梯度,它大致从平均值10开始−3,在训练结束时达到平均值10−8。然后,由于复杂性,我们不能fit超过三层,这提供了最好的结果。我们进行了超参数调整,并在两个数据集上训练网络,在其他数据集上使用相同的模型和超参数。
如表5所示,在没有任何超参数调整的情况下,我们改变了每个MV-GC层的 "视图 "数量,当每层的视图数量增加到一定数值时,泛化效果明显提高。每层只有一个可训练的变换矩阵会使模型接近于[29],这通常是不稳定的训练,也不会产生泛化的表征。在训练时间和准确性之间,视图的选择也有一个权衡。尽管如此,表5清楚地证明了多视图度量学习用于图分类的想法是不难的。
5 Conclusions
本论文提出了一个在multi-view graph上的CNNs模拟。提出了一个新颖的多视图GNN架构,能够以自适应的方式利用顶点信息。
提出的MV-GC层基于可训练的非欧氏距离度量学习过程,生成代表多种图结构的 “视图”。我们通过新引入的混合拉普拉斯来探索图中的成对特征关系。每个 "视图 "用不同的混合拉普拉契亚对输入的图信号进行频谱过滤,产生多个view特征,从而表示数据之间的不同关系。
还引入了一个新的视图集合层,能够融合来自不同视图的信息。所提出的多视图图距离度量学习方法也可以应用于其他图卷积方案,这不在本文的讨论范围之内,而是作为未来的研究方向。
图中的成对特征关系。每个 "视图 "用不同的混合拉普拉契亚对输入的图信号进行频谱过滤,产生多个view特征,从而表示数据之间的不同关系。
还引入了一个新的视图集合层,能够融合来自不同视图的信息。所提出的多视图图距离度量学习方法也可以应用于其他图卷积方案,这不在本文的讨论范围之内,而是作为未来的研究方向。
模型(MV-AGC)在4个具有离散顶点标签的生物信息学数据集,以及3个社交网络数据集中提供了最先进的结果。 最后,所提出的方法在所有具有连续值顶点属性的数据集中都优于以前的方法。















 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











