







算法面试之ELMO BERT GPT
1.ELMO
ELMO的本质思想是:我事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
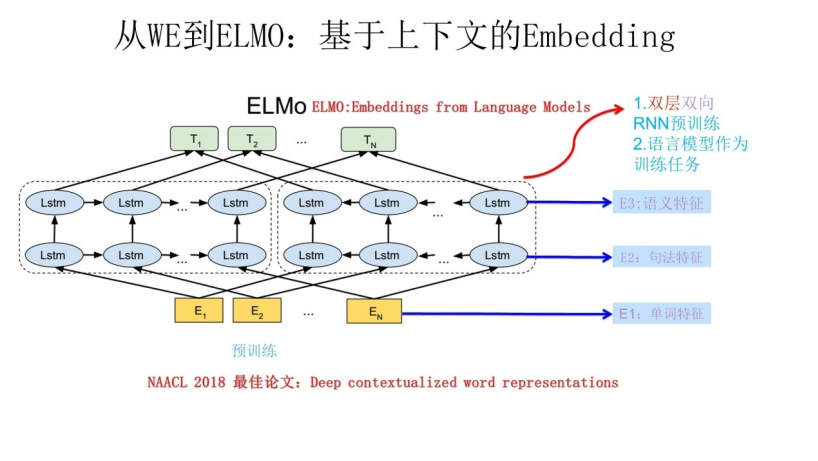
ELMo为一个典型的自回归预训练模型,其包括两个独立的单向LSTM实现的单向语言模型进行自回归预训练,不使用双向的LSTM进行编码的原因正是因为在预训练任务中,双向模型将提前看到上下文表征而对预测结果造成影响。因此,ELMo在本质上还是属于一个单向的语言模型,因为其只在一个方向上进行编码表征,只是将其拼接了而已
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
上图展示的是其预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词的上下文去正确预测单词
句子中每个单词都能得到对应的三个Embedding:最底层是单词的Word Embedding,往上走是第一层双向LSTM中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











