







算法面试之BERT细节
BPE,WordPiece
bert在分词的时候使用的是WordPiece算法。与BPE算法类似,WordPiece算法也是从词表中选出两个子词合并成新的子词。但他们的区别是:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
具体做法如下:假设句子S=(t1,t2,…,tn)由n个子词组成,t_i表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积:
假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子S似然值的变化可表示为:
logP(tz) -(log(P(tx)) + log(P(ty))) = log(P(tz) / P(tx)P(ty))
从上面的公式可以看出,似然值的变化就是两个子词之间的互信息,我们选择具有最大的互信息值的两个词进行合并,表明这两个词在语言模型上具有较强的关联性。
bert输入
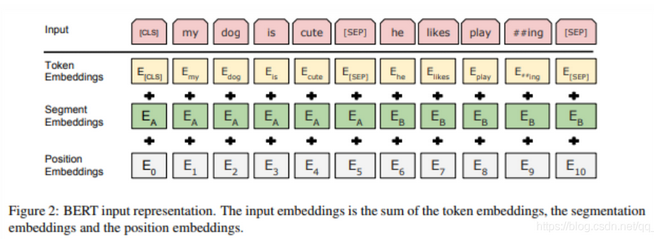
1.Token Embeddings
token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示
假设输入文本是 “I like strawberries”。
输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的。
tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。
使用WordPiece tokenization让BERT在处理英文文本的时候仅需要存储30,522 个词,而且很少遇到oov的词。
WordPiece的一种主要的实现方式叫做BPE(Byte-Pair Encoding)双字节编码。BPE的大概训练过程:首先将词分成一个一个的字符,然后在词的范围内统计字符对出现的次数,每次将次数最多的字符对保存起来,直到循环次数结束。
Token Embeddings 层会将每一个wordpiece token转换成768维的向量。这样,例子中的6个token就被转换成了一个(6, 768) 的矩阵或者是(1, 6, 768)的张量(如果考虑batch_size的话)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1515
1515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











