






问题描述:
python计算机二级易错选择题汇总17
问题解答:
选择题极其容易丢分,需要多刷几遍,才能避免错误。
###################################################################
10、软件测试的目的是( )。
A设计和执行测试用例
B.发现并改正程序中的错误
C.诊断程序中的错误
D.发现程序中的错误
软件测试的目的是评估一个软件应用程序或系统的质量,并确定它是否满足规定的需求和预期的结果。针对给出的选项,我们可以逐一分析:
A. 设计和执行测试用例
这确实是软件测试的一部分,但它只是测试过程的一个环节,而不是测试的最终目的。测试设计和执行是为了找到程序中的潜在问题,但它们的直接目标不是测试的最终目的。
B. 发现并改正程序中的错误
这里,“发现并改正”包含了两个步骤:发现和改正。软件测试的主要目的是发现错误,但改正错误通常是开发人员的任务,而不是测试人员的直接职责。因此,这个选项不完全准确。
C. 诊断程序中的错误
虽然诊断是确定错误原因的过程,但它更偏向于在发现问题后进行的深入分析,而不是测试的直接目的。测试主要是为了发现错误,而不是深入诊断它们。
D. 发现程序中的错误
这是软件测试最直接和核心的目的。通过执行测试用例和评估程序行为,测试人员旨在找出程序中的错误、缺陷、不符合需求的地方或潜在的性能问题。
综上所述,软件测试的目的是D. 发现程序中的错误。
########################################################################
12、关于Python语言语法的描述,正确的选项是( )。
A.Python整数类型的取值没有范围约束
B.Python语言的单行注释以//双斜杠开头
C.python_id、_1 sgood、except、a23、中国_c都是合法变量名
D.x,y=y,x是错误的赋值语句
针对这四个关于Python语言语法的描述,我们来逐一分析:
A. Python整数类型的取值没有范围约束
- 这个描述是正确的。Python的整数类型是动态大小的,这意味着它们可以随着需要而增长,因此理论上没有范围约束(实际上受限于可用内存)。
B. Python语言的单行注释以//双斜杠开头
- 这个描述是错误的。Python的单行注释是以
#井号开头的,而不是//双斜杠。双斜杠在Python中通常用于整除操作。
C. python_id、_1sgood、except、a23、中国_c都是合法变量名
- 这个描述部分正确。
python_id、a23、中国_c和_1sgood(注意,这里假设_1sgood中的空格是一个错误,并且应该是_1sgood)都是合法的Python变量名。但是,except是Python的关键字,因此不能用作变量名。
D. X,y=y,X是错误的赋值语句
- 这个描述是错误的。在Python中,你可以通过同时赋值来交换两个变量的值,例如
X, y = y, X是有效的,并且会实现X和y的值的交换。
综上所述,正确的选项是:
A. Python整数类型的取值没有范围约束
#####################################################################


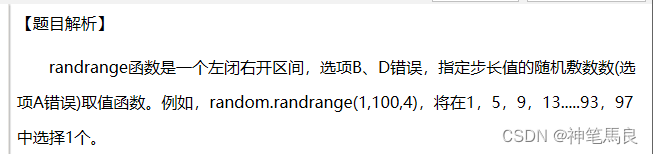
花括号里面指定好1,2了,就必须按照指定的顺序进行填充。
#####################################################################


不要犯经验错误,这里没有开根号。

########################################################################
33、关于Python文件的描述,错误的选项是( )。
A.二进制文件没有统一编码
B.图片文件、视频文件、声音文件等都以二进制形式存储
C.文本文件只能以文本文件方式打开,不能以二进制文件打开
D.文本文件一般由单一编码的字符组成
关于Python文件的描述,我们来看每个选项:
A. 二进制文件没有统一编码
- 这是正确的。二进制文件确实没有统一的字符编码,因为它们直接存储字节,而不将字节解释为特定的字符。
B. 图片文件、视频文件、声音文件等都以二进制形式存储
- 这也是正确的。这些类型的文件通常包含不能直接由文本编辑器解释和显示的原始字节数据,因此它们以二进制形式存储。
C. 文本文件只能以文本文件方式打开,不能以二进制文件打开
- 这是错误的。在Python中,文本文件也可以以二进制模式打开,例如使用
open()函数并指定'rb'模式。然而,当以二进制模式打开文本文件时,你需要自己处理字符编码,因为Python不会自动将字节解码为字符串。
D. 文本文件一般由单一编码的字符组成
- 这是正确的。文本文件通常包含使用特定字符编码(如UTF-8、ASCII、GBK等)编码的字符序列。
因此,错误的选项是C:文本文件只能以文本文件方式打开,不能以二进制文件打开。
#########################################################


###################################################################
36、文件zw1.txt的内容如下
赠汪伦
李白
李白乘舟将欲行
忽闻岸上踏歌声
执行以下代码的输出结果是()。
ls=["桃花潭水深千尺\n","不及汪伦送我情"]
f=open("zw1.txt","a+t")
f.writelines(ls)
for line in f.readlines()[:2]:
print(line)
A.赠汪伦李白
B.赠江伦李白李白乘舟将欲行
C.赠汪伦\n李白n
D.不显示任何内容
____________________________________________________________________
首先,我们来分析给出的代码和情景:
zw1.txt文件初始内容如下:
赠汪伦
李白
李白乘舟将欲行
忽闻岸上踏歌声
- 定义了一个列表
ls,包含两行文本,每行文本后面都跟着一个换行符\n。 - 使用
open("zw1.txt", "a+t")打开zw1.txt文件以追加文本模式(a+)和文本模式(t,这其实是默认的,可以省略)。 - 使用
f.writelines(ls)将列表ls中的内容追加到文件的末尾。 - 尝试使用
for line in f.readlines()[:2]:读取文件的前两行并打印出来。
现在,我们逐步分析执行这段代码后的情况:
- 当执行
f.writelines(ls)后,zw1.txt的内容变为:
赠汪伦
李白
李白乘舟将欲行
忽闻岸上踏歌声
桃花潭水深千尺
不及汪伦送我情
-
紧接着,代码尝试读取文件的前两行。但是,由于文件是以追加模式打开的,并且
writelines()操作后文件指针位于文件的末尾,所以f.readlines()[:2]将不会从文件的开头开始读取,而是从文件的当前位置(即末尾)开始读取,直到文件结束。因为从末尾开始没有内容可读,所以f.readlines()[:2]实际上返回一个空列表。 -
因此,
for line in f.readlines()[:2]:循环体将不会被执行,所以不会打印任何内容。
综上所述,执行这段代码的输出结果是:
D. 不显示任何内容
如果要读取并打印文件的前两行(不包括追加的内容),你需要在写入后重新定位文件指针到文件的开头,例如使用 f.seek(0)。但是,给出的代码中没有这一步,所以答案是 D。
____________________________________________________________________
在 open() 函数中,a+t 是文件模式的组合。它由两部分组成:
-
a:表示以追加模式打开文件。如果文件不存在,它将被创建。在追加模式下打开文件时,新的数据将被写入到文件的末尾。光标位置会自动移动到文件末尾,因此在写入数据后,光标会停留在新写入的数据后面,以便继续写入或读取。 -
+t:这是文本模式的组合。+表示允许读取和写入操作,t表示文本模式。在文本模式下,文件内容被视为字符串,而不是字节。这意味着在读取文件内容时,它会被解码为字符串;在写入文件时,字符串会被编码为字节。
因此,a+t 模式允许在文本文件的末尾追加数据,并且允许读取和写入文件内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











