






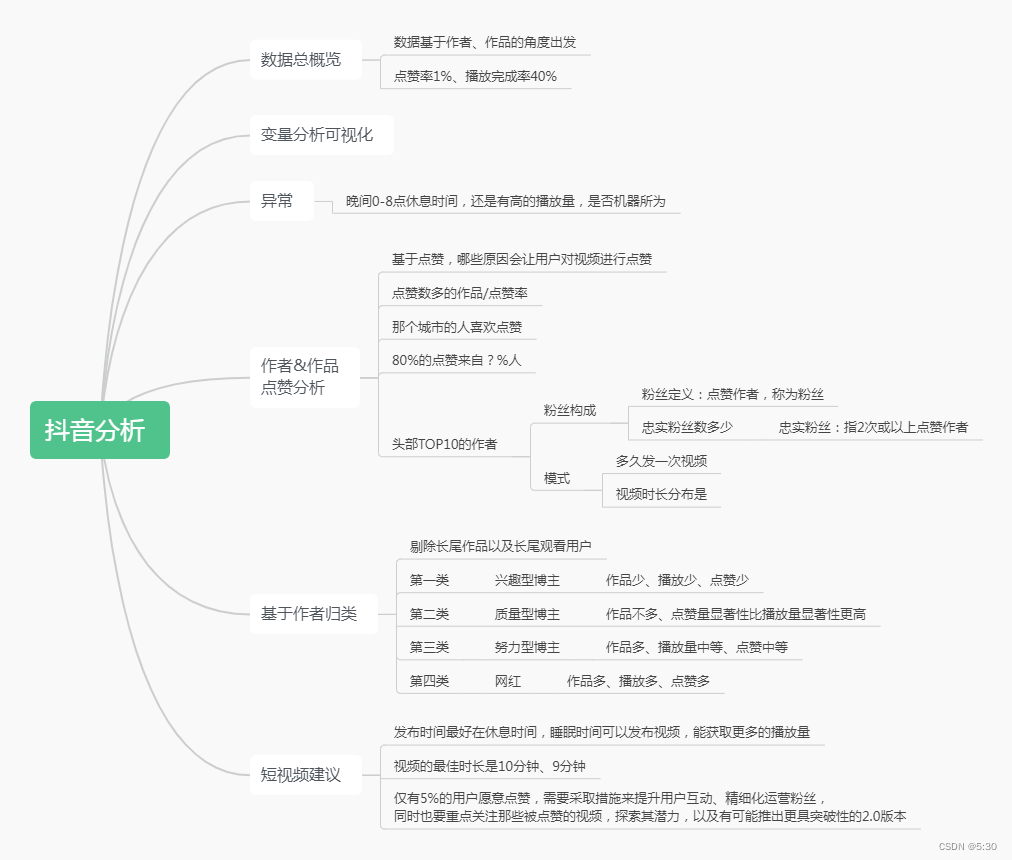
 该博客围绕抖音用户浏览数据展开分析,合计1737357条数据,涉及众多用户、作者和作品。分析了播放完成率、点赞率等指标,发现特殊重度用户,还探讨了视频浏览偏好、发布高峰时段,通过聚类对作者进行归类并可视化。
该博客围绕抖音用户浏览数据展开分析,合计1737357条数据,涉及众多用户、作者和作品。分析了播放完成率、点赞率等指标,发现特殊重度用户,还探讨了视频浏览偏好、发布高峰时段,通过聚类对作者进行归类并可视化。
项目背景
数据为抖音用户浏览数据,此份数据指标以“作品发布时间”为准,是以作者/作品的角度研究分析出发的一份数据
- 合计1737357条数据,共计40天(不一定连续) ;
- 数据涉及59232名用户,分布在387个城市里面;
- 共计208187名作者,发布449472部作品,配音40761首,视频时长72种,4个频道,作者分布在411个城市;
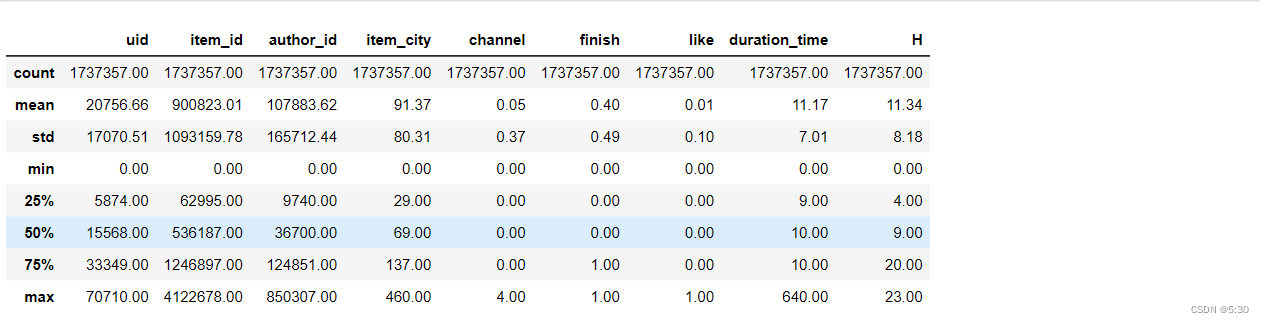
- 播放完成率40%,点赞率只有1%
分析思路
数据字段描述
读取数据,数据预处理
data = pd.read_csv('./douyin_dataset.txt',encoding='gb18030')
data = data[[ 'uid', 'user_city', 'item_id', 'author_id', 'item_city',
'channel', 'finish', 'like', 'music_id', 'duration_time', 'real_time',
'H', 'date']]
data['user_city'] = data['user_city'].astype('str')
data['music_id'] = data['music_id'].astype('str')
data['real_time'] = pd.to_datetime(data['real_time'])
data_like = data[data['like']==1]

数据概览
播放完成率40%,点赞率只有1%
data.describe()
变量可视化
- 从数据的指标来看,此份数据以发布时间为准,那么就是以作者/作品的角度进行出发分析的数据
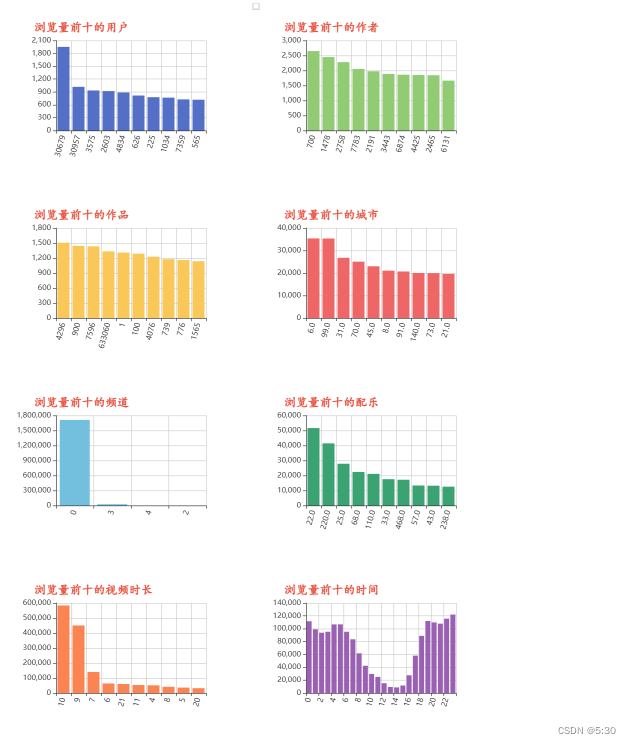
- 特殊的用户为ID30679,共计浏览1951个视频,浏览时长20601分钟,共计343个小时,每天看8.6小时视频,为重度用户/机器人
- 最高浏览量的作品、作者、城市、配乐均较为均衡
- 98%的作品来自0频道
- 大家更喜欢浏览9-10分钟的视频,或长或短的视频浏览量均没有上面2者高
- 晚间0-7点,下班时间18-24点,均为作品发布高峰,获取了比较多的浏览量
# 浏览量前十的用户
df1 = data.groupby(['uid'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 浏览量前十的作者
df2 = data.groupby(['author_id'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 浏览量前十的作品\
df3 = data.groupby(['item_id'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 浏览量前十的城市
df4 = data.groupby(['user_city'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 频道浏览情况
df5 = data.groupby(['channel'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 浏览前十的配乐
df6 = data.groupby(['music_id'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 作品时长分布(浏览)
df7 = data.groupby(['duration_time'])['uid'].agg({'count'}).sort_values(by=['count'],ascending=False)[:10]
# 发布时间分布(浏览)
df8 = data.groupby(['H'])['uid'].agg({'count'}).sort_index()
def bar_lan(x,y,title,title_pos):
bar1 = (
Bar()
.add_xaxis(x)
.add_yaxis("", y)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False,distance=30))
.set_global_opts(
title_opts=opts.TitleOpts(
title=title,
pos_left=title_pos[0],
pos_top=title_pos[1],
title_textstyle_opts=opts.TextStyleOpts(
color='#ea513f',
font_family='cursive',
font_size=19)
),
xaxis_opts=opts.AxisOpts(is_scale=True,axislabel_opts={'rotate': '75'})
)
)
return bar1
bar1 = bar_lan(df1.index.tolist(),df1['count'].tolist(),'浏览量前十的用户',['5%', '2%'])
bar2 = bar_lan(df2.index.tolist(),df2['count'].tolist(),'浏览量前十的作者',['55%', '2%'])
bar3 = bar_lan(df3.index.tolist(),df3['count'].tolist(),'浏览量前十的作品',['5%', '27%'])
bar4 = bar_lan(df4.index.tolist(),df4['count'].tolist(),'浏览量前十的城市',['55%', '27%'])
bar5 = bar_lan(df5.index.tolist(),df5['count'].tolist(),'浏览量前十的频道',['5%', '52%'])
bar6 = bar_lan(df6.index.tolist(),df6['count'].tolist(),'浏览量前十的配乐',['55%', '52%'])
bar7 = bar_lan(df7.index.tolist(),df7['count'].tolist(),'浏览量前十的视频时长',['5%','77%'])
bar8 = bar_lan(df8.index.tolist(),df8['count'].tolist(),'浏览量前十的时间',['55%', '77%'])
# 使用 Grid 进行图表排列
grid = (
Grid(init_opts=opts.InitOpts(width="800px", height='1200px'))
.add(bar1, grid_opts=opts.GridOpts(pos_left="10%", pos_right="60%" ,pos_top="5%", pos_bottom="83%"))
.add(bar2, grid_opts=opts.GridOpts(pos_left="60%", pos_right="10%" ,pos_top="5%", pos_bottom="83%"))
.add(bar3, grid_opts=opts.GridOpts(pos_left="10%", pos_right="60%", pos_top="30%", pos_bottom="58%"))
.add(bar4, grid_opts=opts.GridOpts(pos_left="60%", pos_right="10%", pos_top="30%", pos_bottom="58%"))
.add(bar5, grid_opts=opts.GridOpts(pos_left="10%", pos_right="60%", pos_top="55%", pos_bottom="33%"))
.add(bar6, grid_opts=opts.GridOpts(pos_left="60%", pos_right="10%", pos_top="55%", pos_bottom="33%"))
.add(bar7, grid_opts=opts.GridOpts(pos_left="10%", pos_right="60%", pos_top="80%", pos_bottom="8%"))
.add(bar8, grid_opts=opts.GridOpts(pos_left="60%", pos_right="10%", pos_top="80%", pos_bottom="8%"))
)
# 使用 Page 进行页面组合
page = Page(layout=Page.SimplePageLayout)
page.add(grid)
page.render_notebook()
点赞分析
# 点赞数多的作品/点赞率
df_like1 = data.groupby(['item_id'])['like'].agg({'点赞率':'mean','点赞数':'sum'}).sort_values(by=['点赞数'],ascending=False)
# 那个城市的人喜欢点赞
df_like2 = data.groupby(['user_city'])['like'].agg({'点赞数':'sum'}).sort_values(by=['点赞数'],ascending=False)
80%的点赞来自?%的人
点赞也是存在头部效应,符合5-96法则
df_like3 = data.groupby(['uid'])['like'].agg({'点赞数':'sum'}).sort_values(by=['点赞数'],ascending=False).reset_index()
df_like3['累加'] = df_like3['点赞数'].cumsum()
df_like3['点赞占比'] = df_like3['累加']/ df_like3['点赞数'].sum()
df_like3['用户数占比'] = (df_like3.index+1)/ df_like3['点赞数'].count()
df_like3.head()

k =0.1
for i,j in zip(df_like3['点赞占比'],df_like3['用户数占比']):
if k >=0.9:
break
if i>=k:
print('{}的用户点了{}的赞'.format(format(j,'.2%'),format(i,'.2%')))
k = k + 0.1

def line_chart(t, data):
chart = (
Line(init_opts = opts.InitOpts(theme='light', width='500px', height='300px'))
.add_xaxis([i[0] for i in data])
.add_yaxis(
'',
[i[1] for i in data],
is_symbol_show=False,
areastyle_opts=opts.AreaStyleOpts(opacity=1, color="cyan")
)
.set_global_opts(
title_opts=opts.TitleOpts(title=t),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=True),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
return chart
df = df_like3['点赞占比'].reset_index().values.tolist()
line_chart('用户点赞量', df).render_notebook()
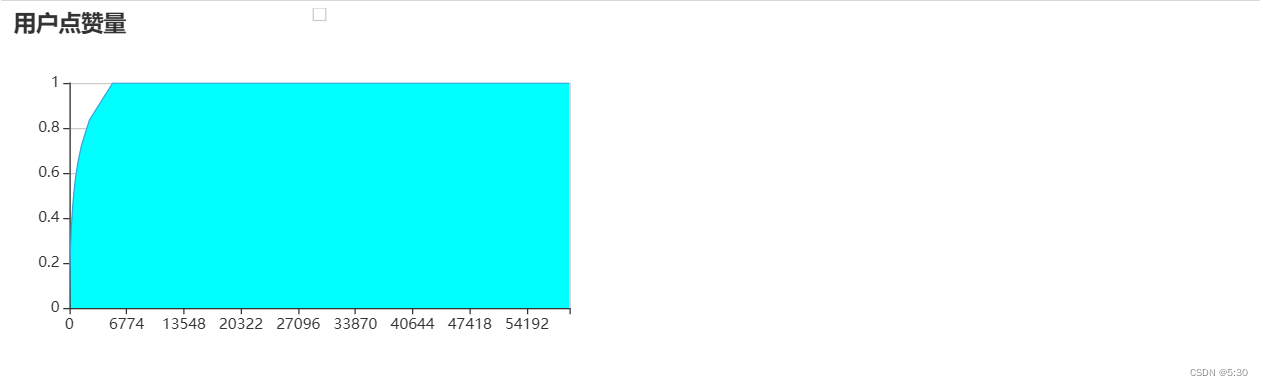
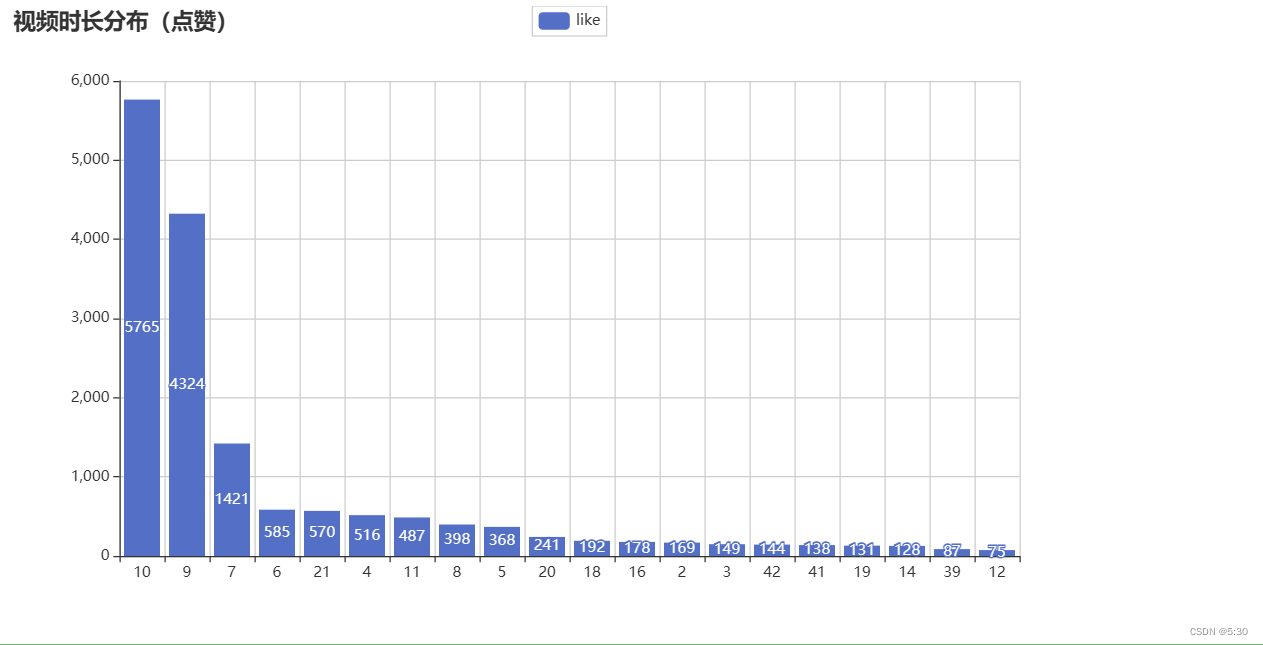
那种视频播放量大 ,受欢迎(点赞多)
df_like6 = data_like.groupby(['duration_time'])['like'].agg({'like':'count'}).sort_values(by=['like'],ascending=False).head(20)
duration_time_like_plt = (
Bar()
.add_xaxis(df_like6.index.tolist())
.add_yaxis("like", df_like6['like'].values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="视频时长分布(点赞)"),
)
)
duration_time_like_plt.render_notebook()
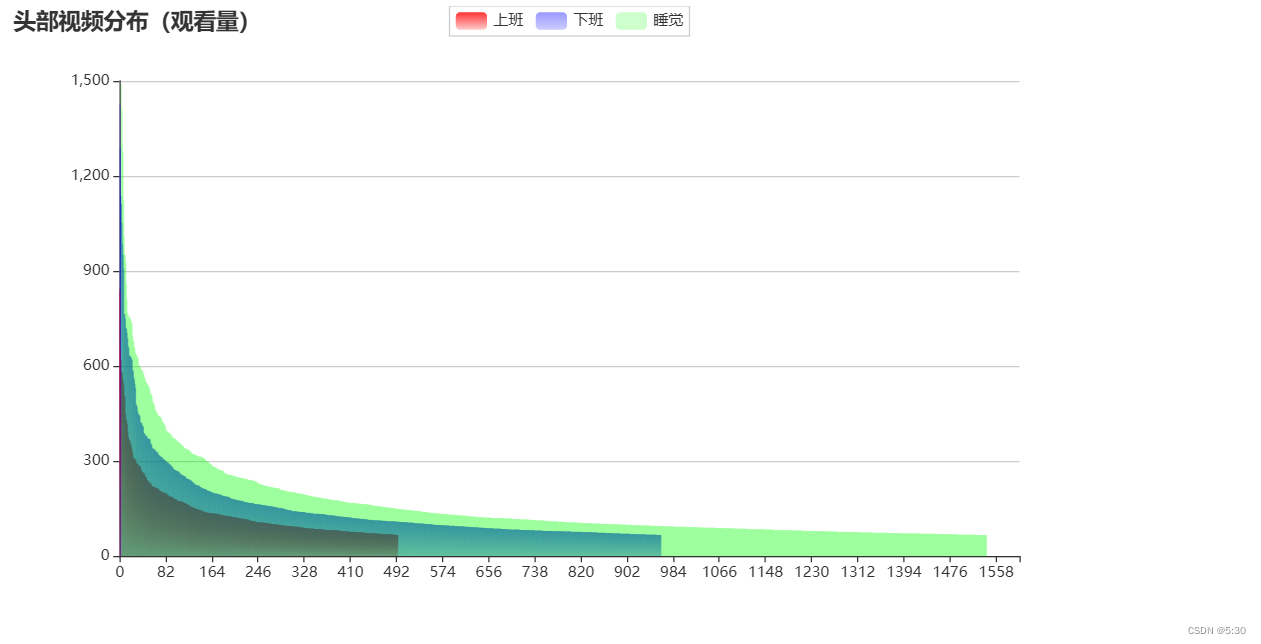
分段分析(上班、下班、睡觉)
去掉长尾作品(浏览量=1)、长尾观看用户(浏览量<=4),那段时间发布视频,作品能得到最终比较好的点赞效果,或播放效果
bins = [0,8,18,24]
labels=['睡觉','上班','下班']
data['time_cut'] = pd.cut(data['H'],bins=bins,labels=labels,include_lowest=True)
# 去掉长尾作品(浏览量=1)、长尾观看用户(浏览量<=4),那段时间发布视频,作品能得到最终比较好的点赞效果,或播放效果
item_long_tail = df_item[df_item['count']==1].index.tolist()
use_long_tail = df_use[df_use['count']==1].index.tolist()
long_tail_excluding_df = data[(~data['item_id'].isin(item_long_tail))&(~data['uid'].isin(use_long_tail))]
#部分用户的数据删除后导致作品浏览量=1,再删除这部分数据
mask = long_tail_excluding_df.duplicated(subset=['item_id'], keep=False)
df_filtered = long_tail_excluding_df[mask]
df_filtered.head()

看下数据极值,分位数
df_long_tail = df_filtered.groupby(['time_cut','item_id'])['uid','like'].agg({'uid':'count','like':'sum'}).reset_index()
df_long_tail.dropna(inplace=True)
re_long_tail_qu = df_long_tail.groupby(['time_cut'])['uid','like'].quantile([0.25, 0.5, 0.75])
re_long_tail_max_min =df_long_tail.groupby(['time_cut'])['uid','like'].agg({'max','min'})
pd.DataFrame(re_long_tail_qu)



TOP3000作品分析可视化
更多的头部作者更愿意在睡觉时间发布视频,并且这些视频均取得了不错的播放量
df_bar = df_long_tail.sort_values(by=['uid'],ascending=False).head(3000)
red_bar = df_bar[df_bar.time_cut=='上班']['uid'].tolist()
blue_bar = df_bar[df_bar.time_cut=='下班']['uid'].tolist()
green_bar= df_bar[df_bar.time_cut=='睡觉']['uid'].tolist()
import pyecharts.options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
from pyecharts.commons.utils import JsCode
# 颜色的RGBA值,透明度范围是0到1
red_color = JsCode("new echarts.graphic.LinearGradient(0, 0, 0, 1, [{offset: 0, color: 'rgba(255, 0, 0, 0.8)'},{offset: 1, color: 'rgba(255, 0, 0, 0.2)'}], false)")
blue_color = JsCode("new echarts.graphic.LinearGradient(0, 0, 0, 1, [{offset: 0, color: 'rgba(0, 0, 255, 0.4)'},{offset: 1, color: 'rgba(0, 0, 255, 0.2)'}], false)")
green_color = JsCode("new echarts.graphic.LinearGradient(0, 0, 0, 1, [{offset: 0, color: 'rgba(0, 255, 0, 0.2)'},{offset: 1, color: 'rgba(0, 255, 0, 0.2)'}], false)")
category = ["{}".format(i) for i in range(0,1600)]
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(xaxis_data=category)
.add_yaxis(
series_name="上班", y_axis=red_bar, label_opts=opts.LabelOpts(is_show=False), itemstyle_opts=opts.ItemStyleOpts(color=red_color)
)
.add_yaxis(
series_name="下班", y_axis=blue_bar, label_opts=opts.LabelOpts(is_show=False), itemstyle_opts=opts.ItemStyleOpts(color=blue_color)
)
.add_yaxis(
series_name="睡觉", y_axis=green_bar, label_opts=opts.LabelOpts(is_show=False), itemstyle_opts=opts.ItemStyleOpts(color=green_color)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="头部视频分布(观看量)"),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=False)),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
# .render("bar_chart_display_delay.html")
)
bar.render_notebook()
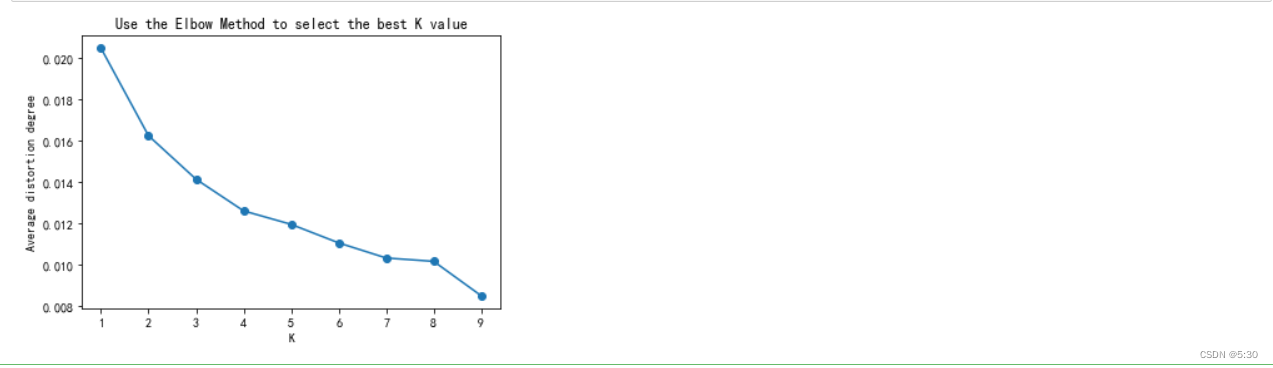
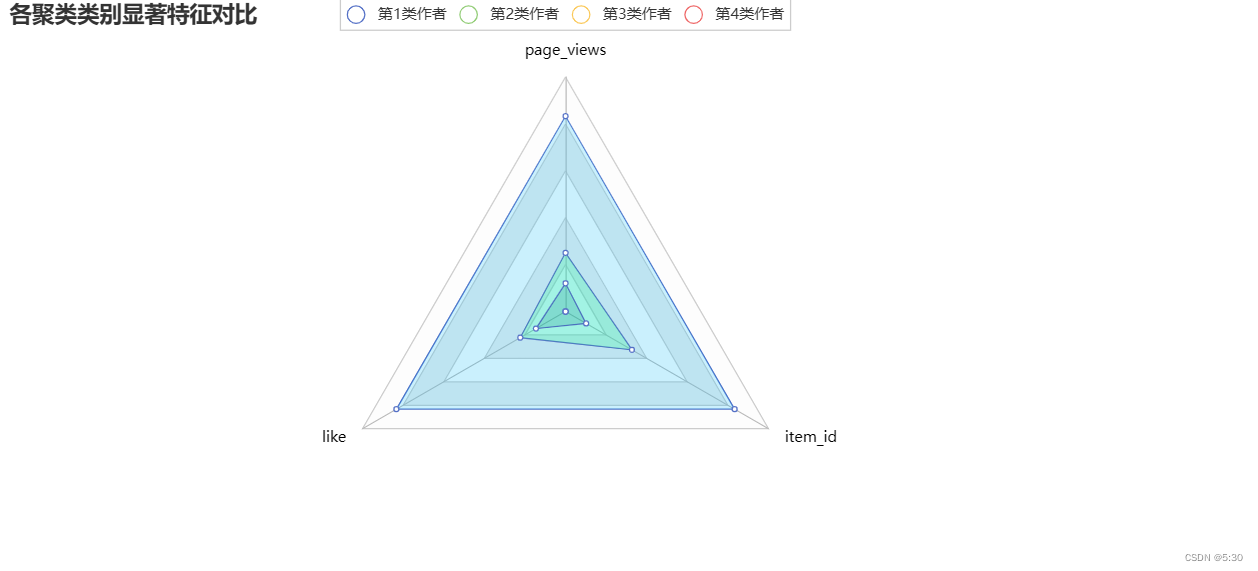
作者归类
根据作者的播放量、点赞量、作品量,对作者进行归类
# 根据作者的播放量、点赞量、作品量,对作者进行归类
df_author = df_filtered.groupby('author_id')['author_id','like','item_id'].\
agg({'author_id':'count','like':'sum','item_id':'nunique'})
df_author.columns = ['page_views','like','item_id']
df_author.reset_index(inplace=True)
## 数据标准化
model_scaler = MinMaxScaler()
data_scaled = model_scaler.fit_transform(df_author[['page_views','like','item_id']])
K = range(1, 10)
meandistortions = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(data_scaled)
meandistortions.append(sum(np.min(cdist(data_scaled, kmeans.cluster_centers_, 'euclidean'), axis=1))/data_scaled.shape[0])
plt.plot(K, meandistortions, marker='o')
plt.xlabel('K')
plt.ylabel('Average distortion degree')
plt.title('Use the Elbow Method to select the best K value')
plt.show()
Kmeans = KMeans(n_clusters=4,max_iter=50)
Kmeans.fit(data_scaled)
cluster_labels_k = Kmeans.labels_ #输出归类结果
cluster_labels = pd.DataFrame(cluster_labels_k, columns=['clusters'])
res = pd.concat((df_author, cluster_labels), axis=1)
# 计算各个聚类类别内部最显著特征值
cluster_features = []
for line in range(4):
label_data = res[res['clusters'] == line]
part_data = label_data.iloc[:, 1:4]
part_desc = part_data.describe().round(3)
merge_data = part_desc.iloc[2, :]
cluster_features.append(merge_data)
df_clusters = pd.DataFrame(cluster_features)
num_sets_max_min = model_scaler.fit_transform(df_clusters).tolist()
c = (
Radar(init_opts=opts.InitOpts())
.add_schema(
schema=[
opts.RadarIndicatorItem(name="page_views",max_=1.2),
opts.RadarIndicatorItem(name="like", max_=1.2),
opts.RadarIndicatorItem(name="item_id", max_=1.2),
],
splitarea_opt=opts.SplitAreaOpts(
is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1)
),
textstyle_opts=opts.TextStyleOpts(color="#000000"),
)
.add(
series_name="第1类作者",
data=[num_sets_max_min[0]],
areastyle_opts=opts.AreaStyleOpts(color="#FF0000",opacity=0.2), # 区域面积,透明度
)
.add(
series_name="第2类作者",
data=[num_sets_max_min[1]],
areastyle_opts=opts.AreaStyleOpts(color="#00BFFF",opacity=0.2), # 区域面积,透明度
)
.add(
series_name="第3类作者",
data=[num_sets_max_min[2]],
areastyle_opts=opts.AreaStyleOpts(color="#00FF7F",opacity=0.2), # 区域面积,透明度
)
.add(
series_name="第4类作者",
data=[num_sets_max_min[3]],
areastyle_opts=opts.AreaStyleOpts(color="#007F7F",opacity=0.2), # 区域面积,透明度
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="各聚类类别显著特征对比"),
)
)
c.render_notebook()
作者归类三维可视化
res1 = res.reset_index()[['page_views','like','item_id','clusters','index']]
import asyncio
from aiohttp import TCPConnector, ClientSession
from pyecharts.charts import Scatter3D
symbol_list = ['circle', 'rect', 'roundRect', 'triangle']
# 配置 config
config_xAxis3D = 'page_views'
config_yAxis3D = 'like'
config_zAxis3D = 'item_id'
config_color = "clusters"
# # config_symbolSize = "vitaminc"
res2 = res1.to_dict(orient='records')
# # 构造数据
data = [
[
item[config_xAxis3D],
item[config_yAxis3D],
item[config_zAxis3D],
item[config_color],
# item[config_yAxis3D],
# item['index'],
]
for item in res2
]
c = (
Scatter3D() # bg_color="black"
.add(
series_name="",
data=data,
xaxis3d_opts=opts.Axis3DOpts(
name=config_xAxis3D,
type_="value",
textstyle_opts=opts.TextStyleOpts(color="#E03D30"),
),
yaxis3d_opts=opts.Axis3DOpts(
name=config_yAxis3D,
type_="value",
textstyle_opts=opts.TextStyleOpts(color="#FCC320"),
),
zaxis3d_opts=opts.Axis3DOpts(
name=config_zAxis3D,
type_="value",
textstyle_opts=opts.TextStyleOpts(color="#279846"),
),
grid3d_opts=opts.Grid3DOpts(width=100, height=100, depth=100),
)
.set_global_opts(
visualmap_opts=[
opts.VisualMapOpts(
type_="color",
is_calculable=True,
dimension=3,
pos_top="10",
max_=8 / 2,
range_color=[
"#1710c0",
"#0b9df0",
"#00fea8",
"#00ff0d",
],
),
# opts.VisualMapOpts(
# type_="size",
# is_calculable=True,
# dimension=4,
# pos_bottom="10",
# max_=80 / 2,
# range_color=[
# "#1710c0",
# "#0b9df0",
# "#00fea8",
# "#00ff0d",
# ],
# ),
]
)
.render("scatter3d.html")
)
](https://i-blog.csdnimg.cn/blog_migrate/345e8c87c1e94c06b4f133c9a31a7781.png)

















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









