









修饰符
- m multiLine 对于str中含\n的情况
- g global
- i ignoreCase
元字符
- 反斜杠加转义
| 元字符 | 含义 | 简写 |
|---|---|---|
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 | word |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 | |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 | space |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 | |
| [\w\W] | 所有字符 | |
| \d | 匹配一个数字字符。等价于 [0-9]。 | digit |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 | |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。 | bridge border |
| \B | 匹配非单词边界。 | |
ES6新增部分
1. 声明正则的变化方式
var reg = new RegExp('xyz', i)
// 也可以 修饰符以第二个参数为准
var reg = new RegExp(/xyz/, 'i')
// 等价于ES5
var reg = /xyz/i
2. 字符串上的正则方法调整

// ES6,当调用字符串方法match时,本质上调用的是RegExp原型上的[Symbol.match]
String.prototype.match → RegExp.prototype[Symbol.match]
String.prototype.replace → RegExp.prototype[Symbol.replace]
String.prototype.search → RegExp.prototype[Symbol.search]
String.prototype.split → RegExp.prototype[Symbol.split]
3. 新增的修饰符u y s
| 修饰符 | 含义 | 简写 |
|---|---|---|
| \y | 再次匹配的时候看是否粘粘的,是全局的 | sticky |
| \u | 识别D800以后的4字节文字,会将4字节看做1个字来匹配 | unicode |
| \ | ||
| \ |

y
<script>
(function () {
const str = "aaa_aa_a";
const reg2 = /a+/y
console.log(reg2.exec(str))
console.log(reg2.exec(str))
console.log(reg2.exec(str))
console.log(reg2.exec(str))
})();
</script>
<script>
(function () {
console.log('--------------脚本2-----------------')
const str = "aaa_aa_a";
const reg1 = /a+/g
console.log(reg1.exec(str))
console.log(reg1.exec(str))
console.log(reg1.exec(str))
console.log(reg1.exec(str))
})();
</script>
u
console.log(/^\uD83D/.test('\uD83D\uDC2A')) // true
console.log(/^\uD83D/u.test('\uD83D\uDC2A')) // false
console.log(/^.$/.test('\uD83D\uDC2A')) // false .也匹配不到
console.log(/^.$/u.test('\uD83D\uDC2A')) // true
document.body.innerText = '\uD83D\uDC2A'
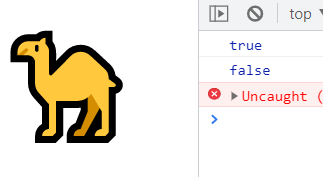
s 让.能代表一切
.不能代表的\n \rU2028(行分隔符) U2029(段分隔符)
console.log(/foo.bar/s.test('foo\nbar')) // true
console.log((/foo.bar/s).dotAll)// true
UTF_16
- Unicode分区定义,ASCII是Unicode的一部分
- 每个区存放2的16次方个(2字节,每个字节8位)U+0000 到 U+FFFF 第一个平面(BMP平面)
- 整个Unicode分为17个平面
- 特殊的汉字,2个字节表示不了时,用4个字节
- U+D800 到 U+FFFF没有对应的字符

// 一定要大于D800
document.body.innerText = '\uD842\uDFB7' // 𠮷
document.body.innerText = '\uD866\uDF99' // 𩮙
'瀛'.charCodeAt(0) // 28699
(28699).toString(16) // "701b"
document.body.innerText = '\u701b' // 瀛
用码点显示emoji

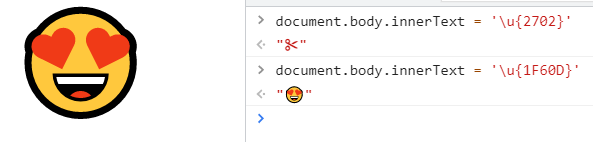
(/\u{1F60D}/u).test('😍') // true
(/a{2}/).test('aa') // true 这里的{}表示量词















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









