






大家好,我是TheWeiJun,欢迎来到我的公众号。今天给大家带来Scrapy源码分析之Dupfilters模块源码详解,希望大家能够喜欢。如果你觉得我的文章内容有价值,记得点赞+关注!
特别声明:本公众号文章只作为学术研究,不用于其它用途。
目录
① 问题思考
② 案例分享
③ 源码分析
④ 源码重写
⑤ 总结分享
一、问题思考
Question
①我们在使用Scrapy框架的时候,一直在好奇Scrapy是如何对每一个请求进行指纹过滤的?
Question
②基于Scrapy原来的去重机制,如果要实现一个增量式爬虫。我们该如何实现呢?此刻默认的去重机制肯定无法满足我们的需求!
Question
③如果我不用Scrapy-Redis分布式做爬虫抓取,采用Scrapy,每次抓取完成后,指纹全部丢失,我们该如何将指纹和Scrapy-Redis一样进行持久化存储呢?当下一次再启动的时候,它依然存在每一个请求的指纹?
Question
④scrapy.Request请求参数设置为dont_filter=True,即可忽略去重,这个机制是如何触发的?
那么带着这些问题,我们对Scrapy的源码进行分析吧,我相信这篇文章会让大家受益匪浅!
二、案例分析
1. 源码分析前,我们还是和以往一样,构建一个小的demo。代码结构如何:
spiders目录下代码:
# -*- coding: utf-8 -*-import scrapyclass BaiduSpider(scrapy.Spider):name = "baidu"allowed_domains = ["baidu.com"]start_urls = ['http://baidu.com/', 'http://baidu.com/']def start_requests(self):for index, url in enumerate(self.start_urls):yield scrapy.Request(url=url, callback=self.parse, meta={"index": index})def parse(self, response):print(response.meta["index"], "-------------")
说明:为了更好的了解源代码,我们需要做一个简单的测试,如上图代码所示。启动爬虫后,输出如下:
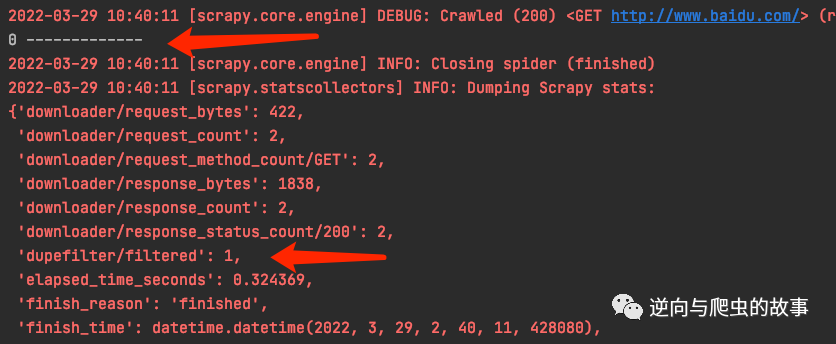
结论:index为1并没有被打印出来,是因为触发了scrapy默认的去重机制导致,这个时候我们会发现scrapy的stats中间件将dupefilter/filtered的值设置为1。
2. 接下来换个思路进行B轮测试。测试方案为将:dont_filter=True,代码如下:
# -*- coding: utf-8 -*-import scrapyclass BaiduSpider(scrapy.Spider):name = "baidu"allowed_domains = ["baidu.com"]start_urls = ['http://baidu.com/', 'http://baidu.com/']def start_requests(self):for index, url in enumerate(self.start_urls):yield scrapy.Request(url=url, callback=self.parse, meta={"index": index}, dont_filter=True)def parse(self, response):print(response.meta["index"], "-------------")
输出如下:

结论:开启dont_filter=True,则不会对请求url进行去重,并且不会触发去重统计的信息。
探索:通过这个小的实验,带着好奇心,接下来我们需要对scrapy的源码进行分析了。
三、源码分析
1. 查看官网文档,搜索指定的模块dupefilter,搜索结果如下:

通过阅读文档,我们可以确定scrapy默认使用的去重机制:
1. scrapy.dupefilters.RFPDupefilter在settings.py模块中默认是开启状态!默认RFPDupeFilter基于使用该scrapy.utils.request.request_fingerprint函数的请求指纹进行过滤。
2. 为了更改检查重复项的方式,您可以子类化RFPDupeFilter并覆盖其request_fingerprint方法。此方法应接受scrapyRequest对象并返回其指纹。
2. 源码阅读及分析
先定位到scrapy默认配置去重机制的参数,如下:
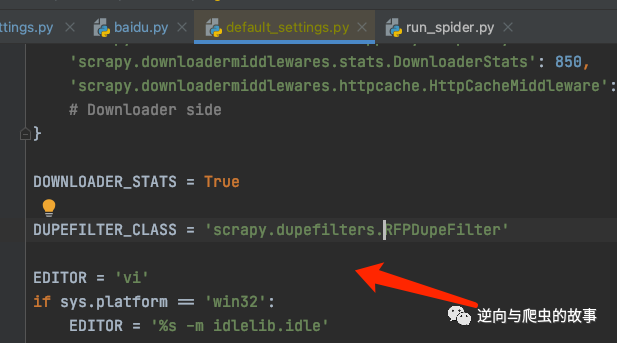
搜索指定关键字,附上源码如下:
import loggingimport osfrom typing import Optional, Set, Type, TypeVarfrom twisted.internet.defer import Deferredfrom scrapy.http.request import Requestfrom scrapy.settings import BaseSettingsfrom scrapy.spiders import Spiderfrom scrapy.utils.job import job_dirfrom scrapy.utils.request import referer_str, request_fingerprintBaseDupeFilterTV = TypeVar("BaseDupeFilterTV", bound="BaseDupeFilter")class BaseDupeFilter:@classmethoddef from_settings(cls: Type[BaseDupeFilterTV], settings: BaseSettings) -> BaseDupeFilterTV:return cls()def request_seen(self, request: Request) -> bool:return Falsedef open(self) -> Optional[Deferred]:passdef close(self, reason: str) -> Optional[Deferred]:passdef log(self, request: Request, spider: Spider) -> None:"""Log that a request has been filtered"""passRFPDupeFilterTV = TypeVar("RFPDupeFilterTV", bound="RFPDupeFilter")class RFPDupeFilter(BaseDupeFilter):"""Request Fingerprint duplicates filter"""def __init__(self, path: Optional[str] = None, debug: bool = False) -> None:self.file = Noneself.fingerprints: Set[str] = set()self.logdupes = Trueself.debug = debugself.logger = logging.getLogger(__name__)if path:self.file = open(os.path.join(path, 'requests.seen'), 'a+')self.file.seek(0)self.fingerprints.update(x.rstrip() for x in self.file)@classmethoddef from_settings(cls: Type[RFPDupeFilterTV], settings: BaseSettings) -> RFPDupeFilterTV:debug = settings.getbool('DUPEFILTER_DEBUG')return cls(job_dir(settings), debug)def request_seen(self, request: Request) -> bool:fp = self.request_fingerprint(request)if fp in self.fingerprints:return Trueself.fingerprints.add(fp)if self.file:self.file.write(fp + '\n')return Falsedef request_fingerprint(self, request: Request) -> str:return request_fingerprint(request)def close(self, reason: str) -> None:if self.file:self.file.close()def log(self, request: Request, spider: Spider) -> None:if self.debug:msg = "Filtered duplicate request: %(request)s (referer: %(referer)s)"args = {'request': request, 'referer': referer_str(request)}self.logger.debug(msg, args, extra={'spider': spider})elif self.logdupes:msg = ("Filtered duplicate request: %(request)s"" - no more duplicates will be shown"" (see DUPEFILTER_DEBUG to show all duplicates)")self.logger.debug(msg, {'request': request}, extra={'spider': spider})self.logdupes = Falsespider.crawler.stats.inc_value('dupefilter/filtered', spider=spider)
分析:和官方文档的说明一致,RFPDupeFilter类继承了BaseDupeFilter,实现了去重机制。接下来对源码进行内容拆分讲解。
-
__init__函数:
def __init__(self, path: Optional[str] = None, debug: bool = False) -> None:self.file = Noneself.fingerprints: Set[str] = set() # 用python set做去重self.logdupes = Trueself.debug = debug # 是否开启DUPEFILTER_DEBUGself.logger = logging.getLogger(__name__)if path: # 将本地化保存的requests.seen文件中的fp指纹加载到set中。self.file = open(os.path.join(path, 'requests.seen'), 'a+')self.file.seek(0)self.fingerprints.update(x.rstrip() for x in self.file)
-
from_settings函数:
@classmethoddef from_settings(cls: Type[RFPDupeFilterTV], settings: BaseSettings) -> RFPDupeFilterTV:debug = settings.getbool('DUPEFILTER_DEBUG')return cls(job_dir(settings), debug)"""默认情况下,RFPDupeFilter仅记录第一个重复请求。设置DUPEFILTER_DEBUG为True将使其记录所有重复的请求。ob_dir(settings)为读取本地path路径,JOBDIR = "路径地址",代码如下:"""def job_dir(settings: BaseSettings) -> Optional[str]:path = settings['JOBDIR']if path and not os.path.exists(path):os.makedirs(path)return path
-
其他方法:
def request_seen(self, request: Request) -> bool:fp = self.request_fingerprint(request) # 计算指纹if fp in self.fingerprints: # 判断指纹是否在set中。return Trueself.fingerprints.add(fp) # 不存在就添加指纹if self.file: # 持久化指纹self.file.write(fp + '\n')return Falsedef request_fingerprint(self, request: Request) -> str:return request_fingerprint(request) # 调用封装好的指纹方法,此刻两个方法名一致,注意:不是调用的同一个方法# 下面会单独分析此方法def close(self, reason: str) -> None:if self.file: # 如果有文件,关闭文件self.file.close()def log(self, request: Request, spider: Spider) -> None:# 输出日志,默认情况下,RFPDupeFilter仅记录第一个重复请求。设置DUPEFILTER_DEBUG为True将使其记录所有重复的请求。if self.debug:msg = "Filtered duplicate request: %(request)s (referer: %(referer)s)"args = {'request': request, 'referer': referer_str(request)}self.logger.debug(msg, args, extra={'spider': spider})elif self.logdupes:msg = ("Filtered duplicate request: %(request)s"" - no more duplicates will be shown"" (see DUPEFILTER_DEBUG to show all duplicates)")self.logger.debug(msg, {'request': request}, extra={'spider': spider})self.logdupes = False# 记录重复的请求个数spider.crawler.stats.inc_value('dupefilter/filtered', spider=spider)
-
request_fingerprint(request)函数:
"""由于代码过多,我只粘贴部分核心源码"""def request_fingerprint(request: Request,include_headers: Optional[Iterable[Union[bytes, str]]] = None,keep_fragments: bool = False,) -> str:"""Return the request fingerprint."""headers: Optional[Tuple[bytes, ...]] = Noneif include_headers:headers = tuple(to_bytes(h.lower()) for h in sorted(include_headers))cache = _fingerprint_cache.setdefault(request, {})cache_key = (headers, keep_fragments)if cache_key not in cache:fp = hashlib.sha1()fp.update(to_bytes(request.method))fp.update(to_bytes(canonicalize_url(request.url, keep_fragments=keep_fragments)))fp.update(request.body or b'')if headers:for hdr in headers:if hdr in request.headers:fp.update(hdr)for v in request.headers.getlist(hdr):fp.update(v)cache[cache_key] = fp.hexdigest()return cache[cache_key]# 读取request:method、url、body or ""、headers进行sha1加密# 加密后的内容放到cache字典中,然后最后返回fp。# request_seen函数最后将fp添加到set()中。# 默认不去重headers。
在scrapy中,当一个请求被spider发起时,它会先经过去重器校验,校验的过程大致如下:
1.对发起的请求的相关信息,通过特定的算法(sha1),生成一个请求指纹2.判断这个指纹是否存在于指纹集合中.3.如果在指纹集合,则表示此请求曾经执行过,舍弃它.4.如果不在,则表示此为第一次执行,将指纹加入到指纹集合中,并将请求加入到请求队列中,等待调度.
scrapy默认的调度器是scrapy.core.scheduler.Scheduler,其中主要的去重代码都在enqueue_request这个方法里,代码如下:
def enqueue_request(self, request):if not request.dont_filter and self.df.request_seen(request):self.df.log(request, self.spider)return Falsedqok = self._dqpush(request)if dqok:self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)else:self._mqpush(request)self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)self.stats.inc_value('scheduler/enqueued', spider=self.spider)return True"""scrapy的Request对象如果设置dont_filter=True,则不会去重。我们知道request传入dont_filter=True时会不去重,这个逻辑就是在这里判断的。self.df.request_seen(request)在上面中我们已经提到。"""
四、源码重写
# settings.py自定自定义模块DUPEFILTER_CLASS = 'scrapy_demo.dupfilters.RFPDupeFilter'# 假设对首页域名不去重,可以这样设置,直接重写request_seen即可。def request_seen(self, request: Request) -> bool:fp = self.request_fingerprint(request)path = furl(request.url).pathstrif path and len(path) == 1:return Falseif fp in self.fingerprints:return Trueself.fingerprints.add(fp)if self.file:self.file.write(fp + '\n')return False
五、总结分享
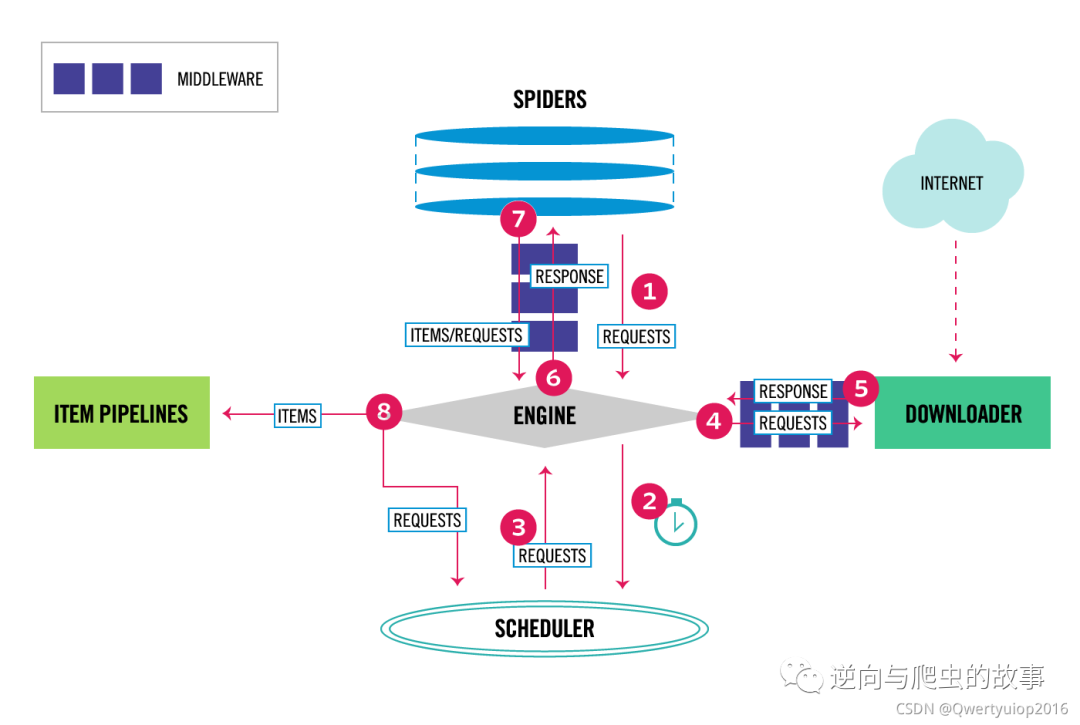
总结:如果为了自定义某些功能,建议大家从scrapy运行流程图去入手,即可定位到需要重写的模块范围,然后查看官网文档进行阅读即可。
作者简介
我是TheWeiJun,有着执着的追求,信奉终身成长,不定义自己,热爱技术但不拘泥于技术,爱好分享,喜欢读书和乐于结交朋友,欢迎扫我微信与我交朋友💕
分享日常学习中关于爬虫及逆向分析的一些思路,文中若有错误的地方,欢迎大家多多交流指正💕
文章来源:逆向与爬虫的故事
原文链接:Scrapy源码分析之Dupfilters模块(第二期)
微信搜公众号:逆向与爬虫的故事;给我一个关注!

















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











