






开源的风吹到视频生成:阿里开源登顶VBench的万相大模型
=话不多说,看看标题就知道:=
1.先从github上下载源码,或者下载zip解压:
git clone https://github.com/Wan-Video/Wan2.1
2.下载模型
from modelscope import snapshot_download
# 指定模型名称
model_name = "Wan-AI/Wan2.1-T2V-1.3B"
# 指定下载路径(绝对路径)
custom_path = "Wan2.1-T2V-1.3B"
# 下载模型
model_dir = snapshot_download(
model_name, # 模型名称
cache_dir=custom_path, # 指定下载路径
revision="master" # 可选:指定模型版本(默认master)
)
print(f"模型已下载到:{model_dir}")
3.按照官方指令进行推理
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
本人做了三个个改动:
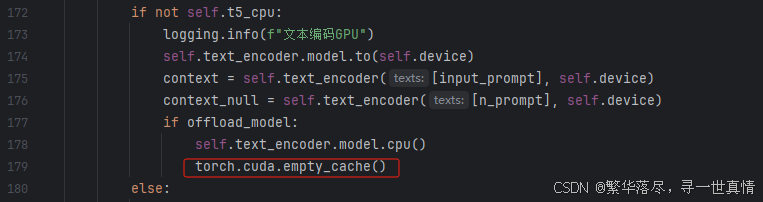
1.用–t5_cpu参数会将文本编码器放到CPU上跑,但是在CPU上跑文本编码也是很慢的,因此先在GPU上跑,然后在源码上torch.cuda.empty_cache()清理掉缓存,就快了很多
2.由于很多机器,比如V100或者2080Ti,或多或少都不支持flash_attention。只需要在源码的model.py将flash_attention替换成from .attention import attention as flash_attention就可以了
# 源码
# from .attention import flash_attention
#替换成
from .attention import attention as flash_attention
3.这个一个意想不到的问题,windows上不支持用号明明文件,如果用源码跑完会保存不了mp4,因此需要将替换掉。如在generate.py文件中将*号替换成X
args.save_file = args.save_file.replace("*", "X")
4.输入prompt,生成对应的视频
prompt:
In a realistic close-up shot with smooth camera movement, a charming woman is seen outdoors on a grassy lawn. She is wearing a white shirt paired with a white jacket, and she adorns a necklace and earrings, adding elegance to her appearance. The woman is gracefully walking around an area enclosed by a wooden fence, moving in a gentle arc as she walks past the fence. The background features a lush green lawn and tent-like structures, creating a serene and refreshing atmosphere. The lighting is ample, highlighting the natural beauty of the scene.
效果视频:



















 1941
1941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









