







压缩优缺点
优点:节省磁盘空间,提升磁盘利用率,加速磁盘/网络IO;
缺点:解压/压缩是需要CPU的,压缩会使集群cpu利用率高,所以当集群负载高了就不要使用压缩了;
总结来说,需不需要使用压缩是磁盘和CPU的取舍,也反映了大数据层面的任何调优都不是万能的,都需要根据实际需求来做调优。
压缩格式
大数据中常用的压缩格式:Bzip2,Gzip,Lzo,Lz4,Snappy
在具体的情况下到底选用哪种压缩方式主要是由压缩比、压缩速度、是否支持分片来决定的。另外,因为压缩比和压缩速度是成反比的,所以比较了压缩比实际上也就比较了压缩速度:
- 从压缩比方面考虑:
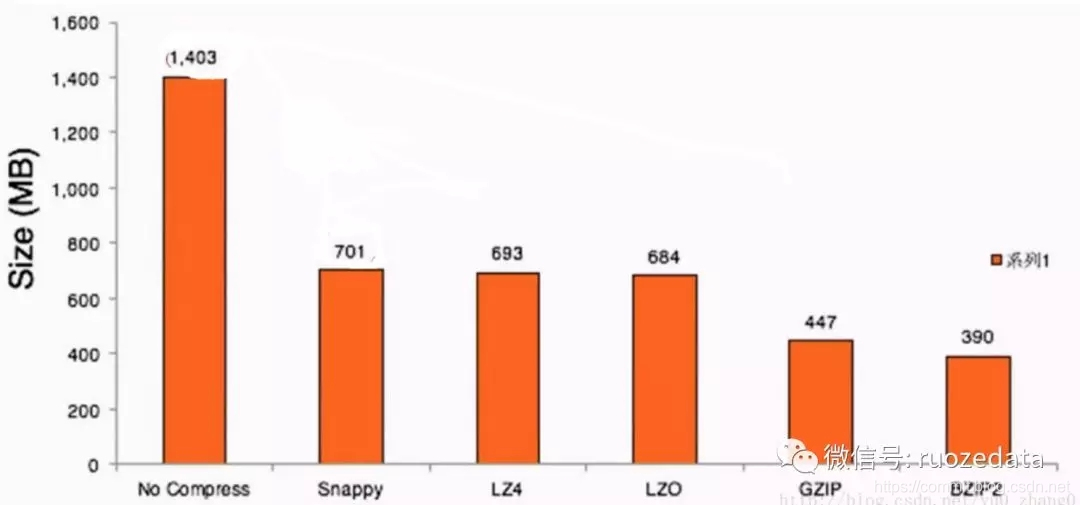
压缩比:Snappy < Lz4 < Lzo < Gzip < Bzip2
Bzip2和Gzip是一个级别的,压缩比都比较大;
Snappy的压缩比是最小的,所以也是压缩速度最快的,所以很多时候如果更看重压缩速度,就选择使用Snappy压缩 - 从是否分片考虑
Bzip2 默认支持分片
Lzo 默认不支持分片,但是建立索引后支持压缩
压缩的使用场景
以 Flume采集数据,经过MapReduce任务做ETL,最后数据输入到HDFS为例:
- Input过程:将数据输入到hadoop集群,准备做ETL任务。这个过程是肯定需要做压缩的,因为涉及到网络的传输。选用什么压缩格式?由于准备要做ETL操作,需要使用MapReduce/Spark,如果不支持分片的话,就只有一个MapTask,速度就很慢。
Flume --可分片的压缩–> HDFS 之后在HDFS上解压 - Temp:因为之后就要进行Shuffle的操作,没有必要使用高压缩比的,而且之前已经分片过了,所以只需要使用速度快的压缩方式,通常使用Snappy压缩
Map --压缩(快速的)–> shuffle --解压–>Reduce - Output过程:选哪种压缩需要看场景,看之后数据是直接落地了还是还需要再操作,如果作为下一个作业的输入,这个过程就得考虑是否需要分片
Reduce --压缩–> 之后 (这种情况的压缩需要分情况,如果这个数据结果归档了,就需要高压缩比的;如果这个数据结果要作为下一个MapReduce的输入,则需要可分片的)
MapTask的决定因素
MapTask的数量是由InputFormat来指定的,InputFormat生成多少个InputSpilt就会有多少个task。
之前总有误区,一个block会有一个MapTask,这是因为InputFormat对于每个文件,默认是一个block生成一个InputSplit。所以在上面的Input过程有些蒙圈,觉得落入HDFS上的文件,在使用没有分片能力的压缩格式下,为什么只能有一个MapTask?其实这时候,压缩后的文件落入HDFS后,也分成了很多很多block,但是这时候的InputSplit不再是根据block的数量,而是根据压缩格式的类型。所以不能分片的压缩格式下,生成的文件只能有一个MapTask。
怎样使用
MapReduce任务
在 $HAOOP_HOME/etc/hadoop/core-site.xml和mapred-site.xml配置
Hive任务
在命令行中 set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress.codec=xxx;














 6013
6013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









