







文章目录
MySQL学习
1. 启动与连接Mysql
启动mysql服务
net stop mysql --停止服务
net start mysql --开启服务
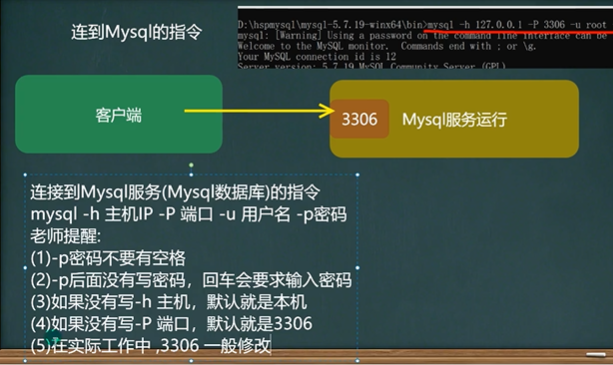
连接到Mysql的指令,连接前保证mysql服务启动了
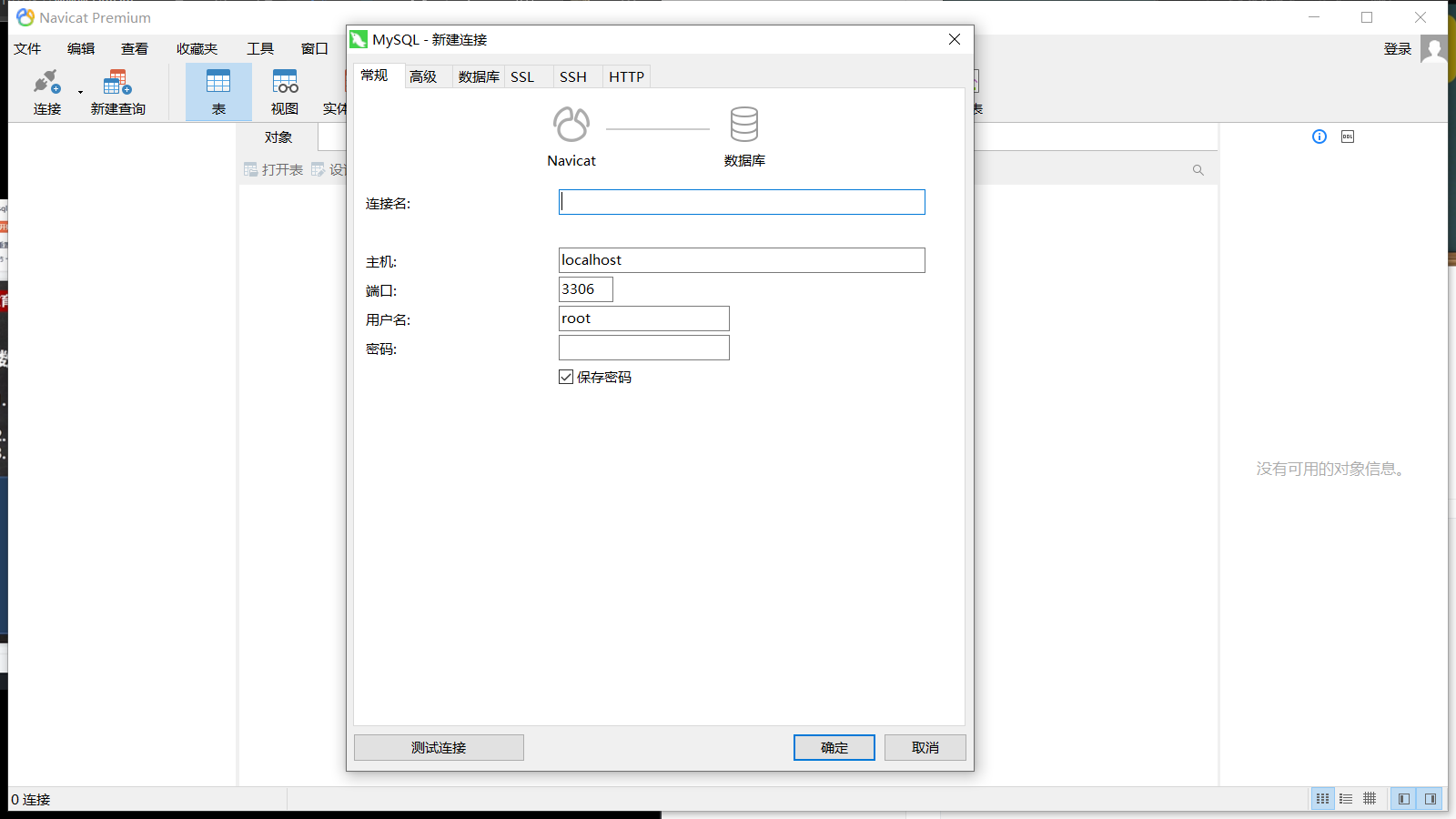
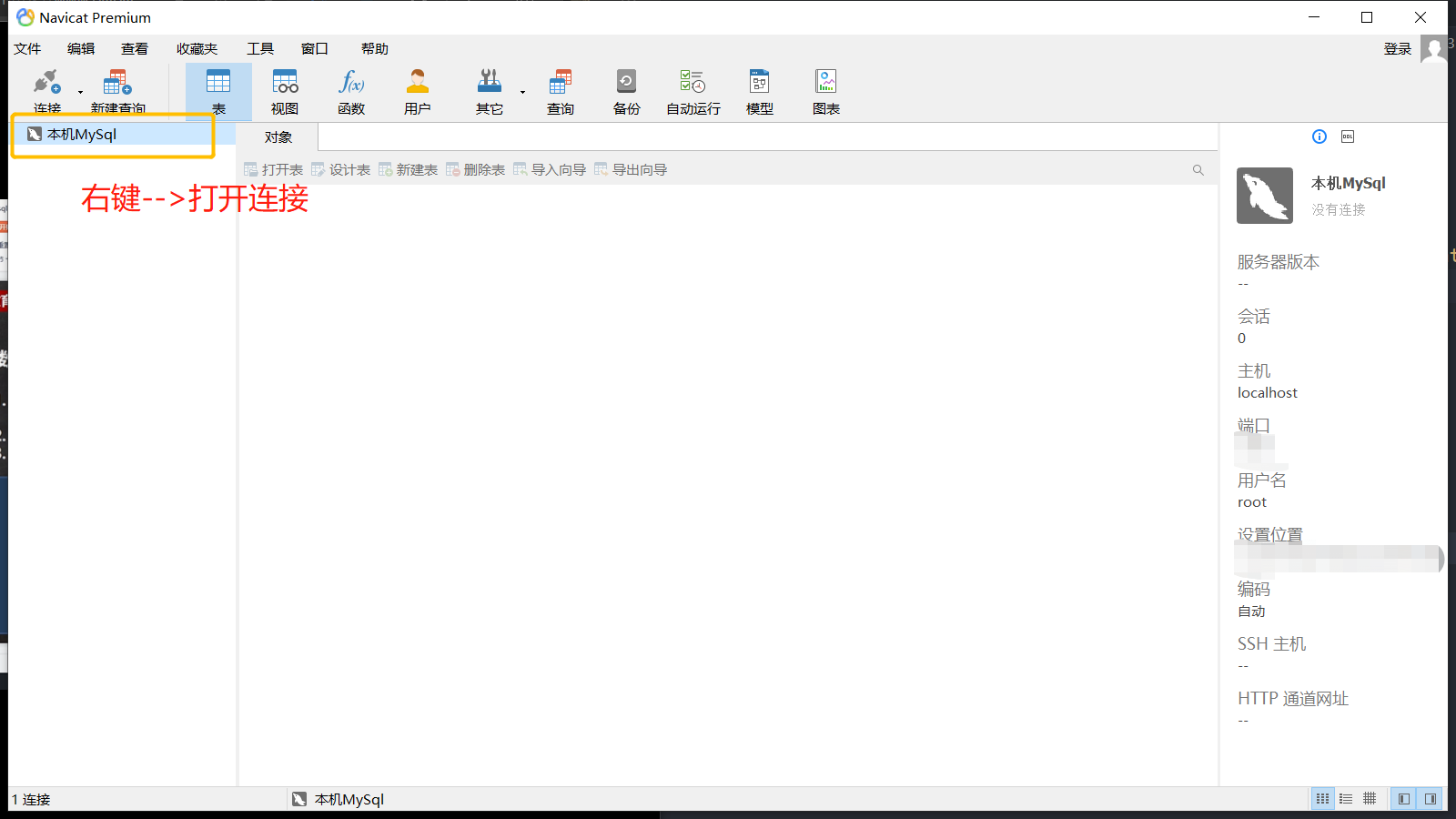
可视化工具Navicat Premium 15
点击连接,选择数据库
2. 数据库三层结构


3. 创建、删除 查看数据库
#创建数据库
CREATE DATABASE db_yhx;
#删除数据库
DROP DATABASE db_yhx;
#创建一个使用utf8字符集的db_yhx数据库
CREATE DATABASE db_yhx CHARACTER SET utf8;
#创建一个使用utf8字符集,并带校验规则的db_yhx数据库
CREATE DATABASE db_yhx CHARACTER SET utf8 COLLATE utf8_bin
#utf8_bin区分大小写 默认utf8_general_ci不区分大小写
#查看数据库
SHOW DATABASES
#查看创建数据库时的语句
SHOW CREATE DATABASE db_yhx
# CREATE DATABASE `db_yhx` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */ /*!80016 DEFAULT ENCRYPTION='N' */
#使用哪个数据库
USE db_yhx
# 如果是通过图形界面改变的,要把表的相应字段里设置也改变
SELECT * FROM student WHERE NAME = 'TOM'
SELECT * FROM student WHERE name = 'tom'
4. 数据库备份 和 恢复
备份数据库(注意:在DOS执行)
mysqldump -u 用户名 -p -B 数据库1 数据库2 ... 数据库n > 文件名.sql
恢复数据库(注意:进入Mysql命令行再执行
Source 文件名.sql
#备份 :mysqldump -u root -p -B db_yhx > D:\\test.sql
#这个备份的文件,就是对应的sql语句
DROP DATABASE db_yhx;
#恢复数据库,要进到MySql命令行才行
#法一:Source 文件名.sql
Source D:\\test.sql;
#法二:当然也可以将D:\\test.sql 中的语句全部复制到Navicat中新建查询并执行一遍,也能恢复
#只想备份库中的某几个表(也是在DOS里执行)
# mysqldump -u 用户名 -p密码 数据库 表1 表2... 表n > d:\\文件名.sql
#这里-p后面可以不写密码,系统会让你后面输入的
# 备份时生成的 文件名.sql文件内就是sql语句-->用于建立一个数据库, Source 也可以理解为复制,你在自己的数据库下执行这个sql文件即可获得这个数据库
5. 创建表
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
...
)CHARACTER SET 字符集 collate 校对规则 engine 引擎
field:指定的列名
datatype:指定列类型
character set:如果不指定则为所在数据库字符集
collate:如不指定则为所在数据库校对规则
engine:引擎(后文讲解)
#注意这里` 符号的使用
USE db_yhx;
CREATE TABLE `table_student`
(
id INT,
`name` VARCHAR(255),
`birthday` DATE
)
CHARACTER SET utf8
COLLATE utf8_bin
ENGINE INNODB
6. 常用的数据类型
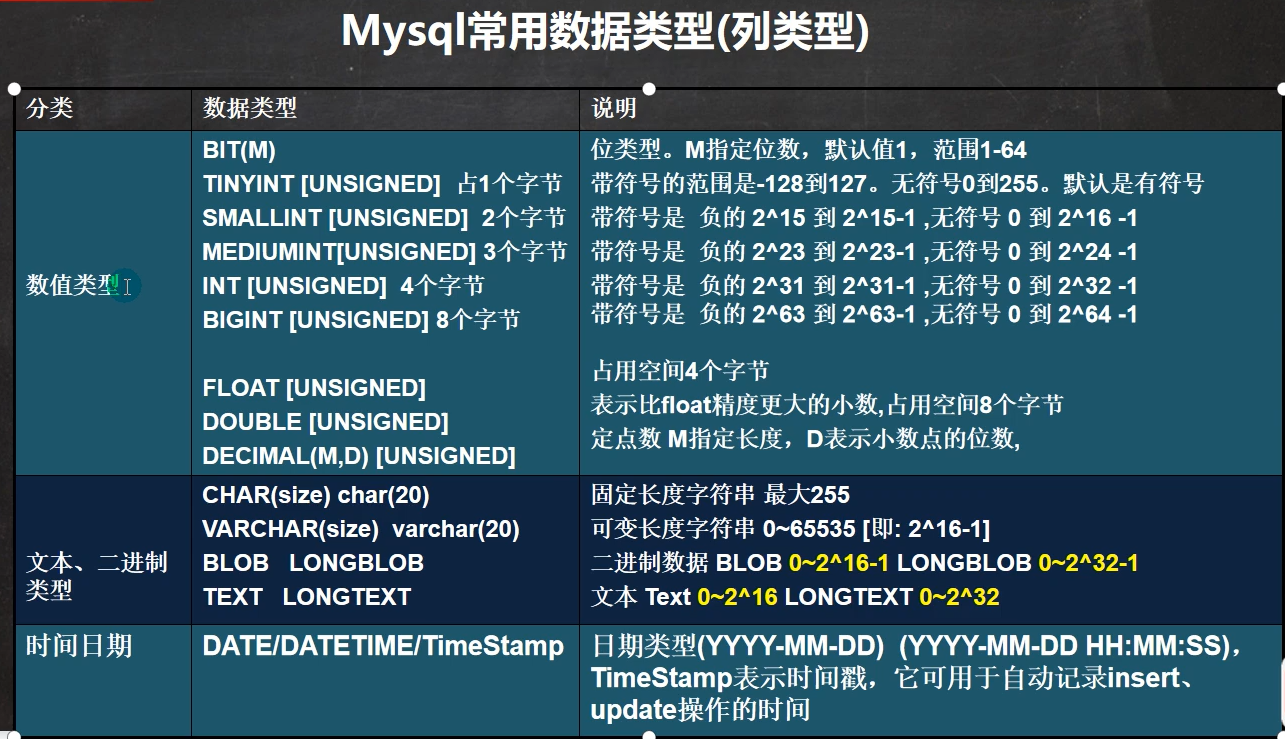
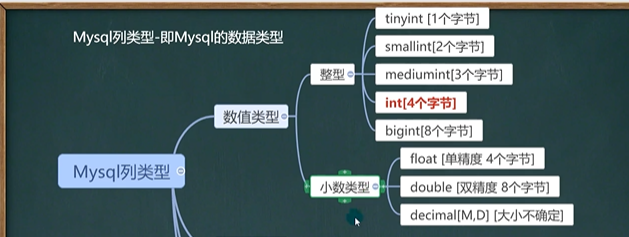
6.1 数值型(整型)

CREATE TABLE t1
(
id TINYINT #如果没有指定unsigned,则该数据类型为 有符号
);
INSERT INTO t1 VALUES(128); #error 超出范围
CREATE TABLE t2
(
id TINYINT UNSIGNED
);
INSERT INTO t2 VALUES(-1); #error 超出范围
6.2 数值型(bit)
#1. bit(m), m 在1-64
#2. 添加数据,数据范围按照给定的位数限制 一位就是0-1,两位就是00-11即0-3
#3. 显示按照bit
CREATE TABLE t2 (num BIT(2));
INSERT INTO t2 VALUES(3);
INSERT INTO t2 VALUES(1);
SELECT * FROM t2;
# num
# 11
# 01
#查询时也可以按照数据的十进制大小查询,但是查询结果仍然显示的是bit
SELECT * FROM t2 WHERE num = 3;
# num
# 11
#插入多条数据,用()分开
INSERT INTO t2 VALUES(0),(2);
SELECT * FROM t2;
# num
# 11
# 01
# 00
# 10

6.3 数值型(小数)

CREATE TABLE t3
(
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20)
);
#超过精度的会进行四舍五入保存
INSERT INTO t3 VALUES(1.12345678910111213141516171819202122,2.12345678910111213141516171819202122,3.12345678910111213141516171819202122);
SELECT * FROM t3;
#1.12346 2.123456789101112 3.12345678910111213142
#DECIMAL(M,D) M表示位数即2^M ---> 最多能表示2^M 这么大的数,D表示小数点后的几位D==1表示小数点后1位
CREATE TABLE t4
(
num1 DECIMAL(2,1),
num2 BIGINT UNSIGNED
);
INSERT INTO t4 VALUES(1.2222,12345678910111213141);
SELECT * FROM t4;
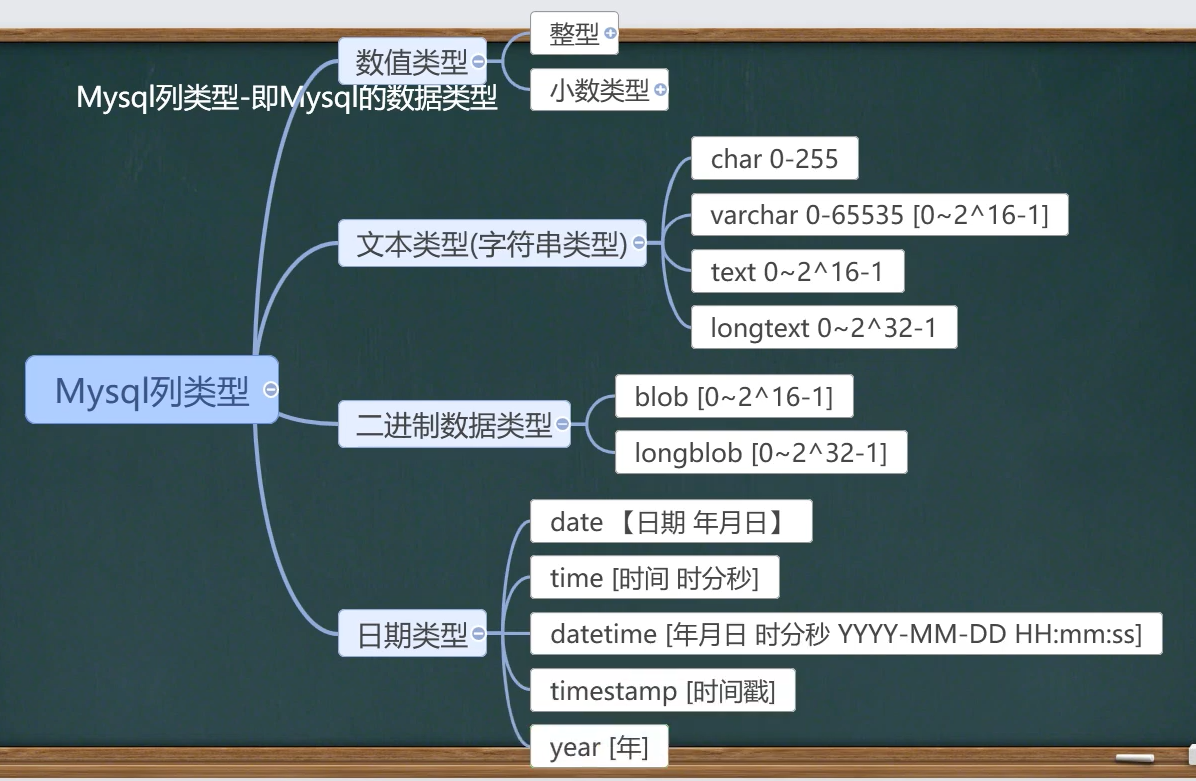
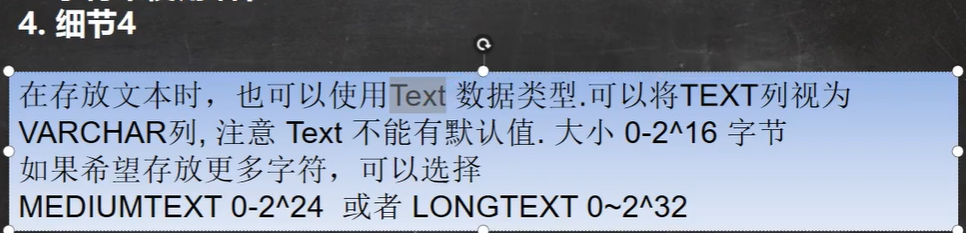
6.4 文本类型

size 表示:字节
注意这里编码不同则size也不同:
utf8是按3个字节为一个字符保存,所以utf8最大(65535-3)/3 = 21844,
gbk是按2个字节为一个字符保存,所以gbk最大 (65535-3) / 2 = 32766

CREATE TABLE t5
(
`name` CHAR(4)
);
# CHAR(4)表示不管是汉字还是字母都是四个,4表示4个字符而不是字节,不区分汉字英文
# 至于占多少空间取决于你的编码
INSERT INTO t5 VALUES('加油呀你');
-- INSERT INTO t5 VALUES('加油鸭你a'); #超出范围
INSERT INTO t5 VALUES('abcd');
-- INSERT INTO t5 VALUES('abcde'); #超出范围


6.5 日期类型
DATE,DATETIME. TIMESTAMP
CREATE TABLE t6
(
birthday DATE, -- 年月日
job_time DATETIME, -- 年月日 时分秒
login_time TIMESTAMP -- 时间戳,若希望login_time 列自动更新需要配置以下内容
NOt NULL DEFAULT CURRENT_TIMESTAMP -- 不能为空,默认当前时间戳
ON UPDATE CURRENT_TIMESTAMP -- 自动更新时间戳
);
SELECT * from t6;
INSERT INTO t6(birthday,job_time)
VALUES('2022-4-19','2022-5-30 19:38:20');
SELECT * FROM t6;# 2022-04-19 2022-05-30 19:38:20 2022-04-19 19:40:04
7. 删除表
DROP TABLE table_name;
8. 修改表
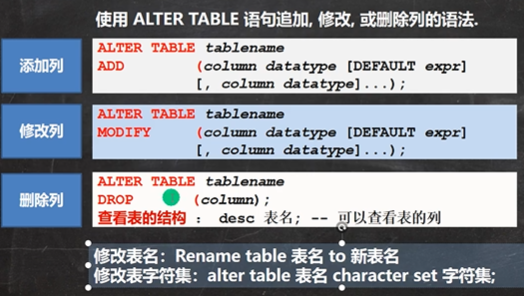
-- 在字段 resume 后面添加 image 字段 类型为varchar(32) 非空默认 ' '
ALTER TABLE emp
ADD image VARCHAR(32) NOT NULL DEFAULT ' '
AFTER resume;
DESC emp -- 显示表结构
-- Field Type Null Key DEFAULT Extra
-- id int YES (Null)
-- name varchar(32) YES (Null)
-- sex char(1) YES (Null)
-- birthday date YES (Null)
-- entry_time datetime YES (Null)
-- job varchar(32) YES (Null)
-- salary double YES (Null)
-- resume varchar(32) YES (Null)
-- image varchar(32) NO
ALTER TABLE emp
MODIFY job VARCHAR(60) NOT NULL DEFAULT ' '; -- 修改job字段 类型为varchar(60) 默认值' '
DESC emp -- 显示表结构
-- Field Type Null Key DEFAULT Extra
-- id int YES (Null)
-- name varchar(32) YES (Null)
-- sex char(1) YES (Null)
-- birthday date YES (Null)
-- entry_time datetime YES (Null)
-- job varchar(60) YES
-- salary double YES (Null)
-- resume varchar(32) YES (Null)
-- image varchar(32) NO
ALTER TABLE emp
DROP sex; -- 删除 sex 字段
RENAME TABLE emp TO employee; -- 修改表明
ALTER TABLE employee CHARACTER SET utf8; -- 修改字符集
ALTER TABLE employee CHANGE `name` `user_name` VARCHAR(64) -- 修改name 字段 为 user_name 类型 varchar(64)
NOT NULL DEFAULT ' ';
DESC employee;
-- Field Type Null Key DEFAULT Extra
-- id int YES (Null)
-- user_name varchar(32) NO
-- birthday date YES (Null)
-- entry_time datetime NO (Null)
-- job varchar(60) YES
-- salary double YES (Null)
-- resume varchar(32) YES (Null)
-- image varchar(32) NO
9. CRUD学习
insert

update
SELECT * FROM employee;
-- 1 小明 2000-01-02 2020-09-01 10:10:10 后端工程师 12000 加油 无
-- 2 小红 2000-02-02 2020-09-02 11:11:11 前端工程师 11000 加油 无
# 如果没有带 where 语句,则会修改所有的记录
UPDATE employee SET salary = 5000 WHERE user_name = '小红';
SELECT * FROM employee WHERE user_name = '小红';
-- 2 小红 2000-02-02 2020-09-02 11:11:11 前端工程师 5000 加油 无
# 将小红的salary 从原来的基础上 加2000
UPDATE employee SET salary = salary + 2000 WHERE user_name = '小红';
SELECT * FROM employee WHERE user_name = '小红';
-- 2 小红 2000-02-02 2020-09-02 11:11:11 前端工程师 7000 加油 无
# 将小红的salary 从原来的基础上再加8000, 并将job 改为算法工程师
UPDATE employee
SET salary = salary + 8000,
job = '算法工程师'
WHERE user_name = '小红';
SELECT * FROM employee WHERE user_name = '小红';
-- 2 小红 2000-02-02 2020-09-02 11:11:11 算法工程师 15000 加油 无
delete
delete 不可能将某一列的数据删除,只能将一列置空;
delete 删除记录,drop删除表
delete from table_name [where ...] -- 不加where,则全部删除
select
语句执行顺序
select 5
..
from 1
..
where 2
..
group by 3
..
having 4
..
order by 6
..
limit 7
..
算数表达式中有NULL则计算出来就是NULL
0. 基本语法

create TABLE student(
id int not null DEFAULT 1,
name VARCHAR(20) not null DEFAULT '',
chinese FLOAT not null DEFAULT 0.0,
english FLOAT not null DEFAULT 0.0,
math FLOAT not null DEFAULT 0.0
);
INSERT INTO student (id,name,chinese,english,math) VALUES (1,'韩顺平',89,78,90);
INSERT INTO student (id,name,chinese,english,math) VALUES (2,'张飞',67,98,56);
INSERT INTO student (id,name,chinese,english,math) VALUES (3,'宋江',87,78,77);
INSERT INTO student (id,name,chinese,english,math) VALUES (4,'关羽',88,98,90);
INSERT INTO student (id,name,chinese,english,math) VALUES (5,'赵云',82,84,67);
INSERT INTO student (id,name,chinese,english,math) VALUES (6,'欧阳锋',55,85,45);
INSERT INTO student (id,name,chinese,english,math) VALUES (7,'黄蓉',75,65,30);
INSERT INTO student (id,name,chinese,english,math) VALUES (8,'韩信',45,65,99);
# 必须查询的所有字段都相同时,distinct才会去重
SELECT `name`, english FROM student;
-- 韩顺平 78
-- 张飞 98
-- 宋江 78
-- 关羽 98
-- 赵云 84
-- 欧阳锋 85
-- 黄蓉 65
-- 韩信 65
SELECT DISTINCT english FROM student;
-- 78
-- 98
-- 84
-- 85
-- 65
# 必须查询的所有字段都相同时,distinct才会去重
SELECT `name`, english FROM student;
-- name english
-- 韩顺平 78
-- 张飞 98
-- 宋江 78
-- 关羽 98
-- 赵云 84
-- 欧阳锋 85
-- 黄蓉 65
-- 韩信 65
SELECT DISTINCT english FROM student;
-- english
-- 78
-- 98
-- 84
-- 85
-- 65
# 取别名
SELECT name as 姓名,(chinese+english+math) as 总分 FROM student;
-- 姓名 总分
-- 韩顺平 257
-- 张飞 221
-- 宋江 242
-- 关羽 276
-- 赵云 233
-- 欧阳锋 185
-- 黄蓉 170
-- 韩信 209
在where句子中经常使用的运算符
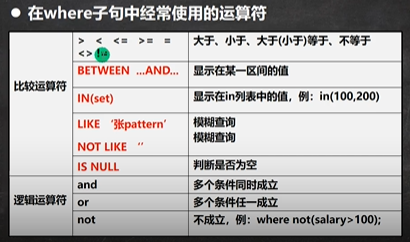
1.模糊查询 like
在模糊查询中两个特殊符号:%,_
%: 任意多个字符
_: 任意一个字符
//找名字中第二个字母是A的
select ename from emp where ename like '_A%'
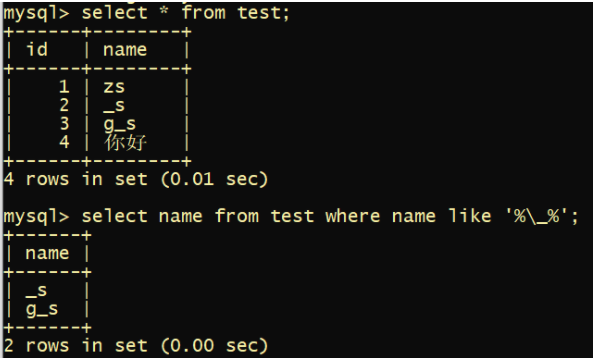
//找出名字中有下划线的
select ename from emp where ename like '%\_%'
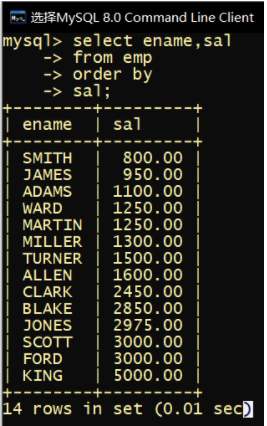
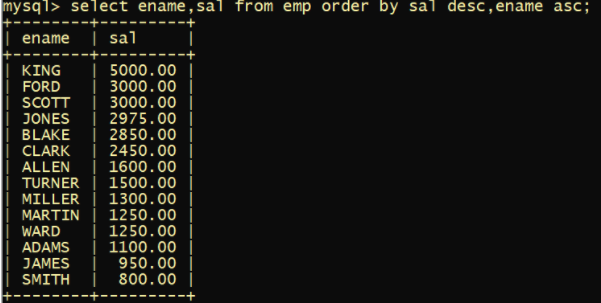
2.排序 Order by
默认升序
select ename,sal from emp order by sal; //升序
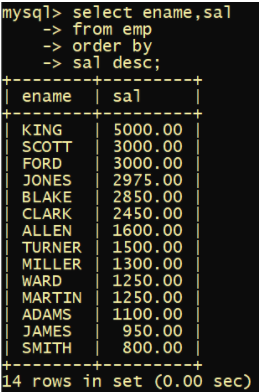
select ename,sal from emp order by sal desc; //降序
按照工资的降序排列,当工资相同时再按照名字升序排
越靠前的字段主导作用越大,只有前面不起作用才能后面上
select ename,sal from emp order by sal desc,enam asc;
语句执行顺序
- from
- where
- select
- order by
select
ename,job,sal
from
emp
where
job = 'SALESMAN'
order by
sal desc;
# 用哪个字段 ORDER BY了 就要在SELECT 上加入它
# 如果使用的别名 ORDER BY 则在SELECT 中就要as 出别名
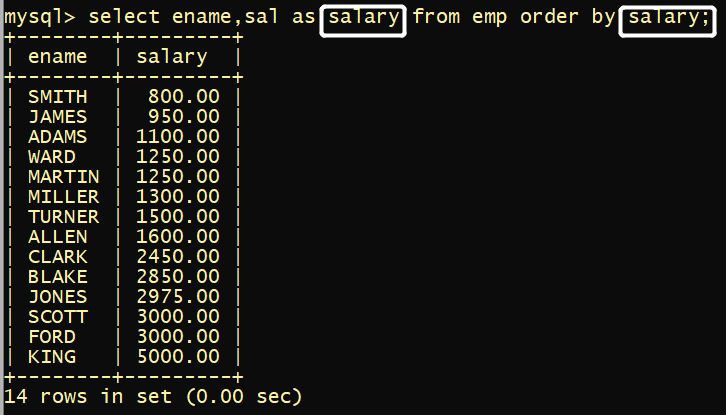
# 也可以用 别名进行排序,即as后的名称
3.分组函数
3.0 基本知识
-
count计数;sum求和;avg平均数;max最大值;min最小值
-
是对某一组数据进行处理,又名:多行处理函数
输入多行,输出一行
-
分组函数自动忽略NULL
#1. select sum(comm) from emp; //计算时会把NULL忽略的 # 不用如下 select sum(comm) from emp where comm is not null;#2. select ename,(sal+conmm)*12 as 年薪 from emp;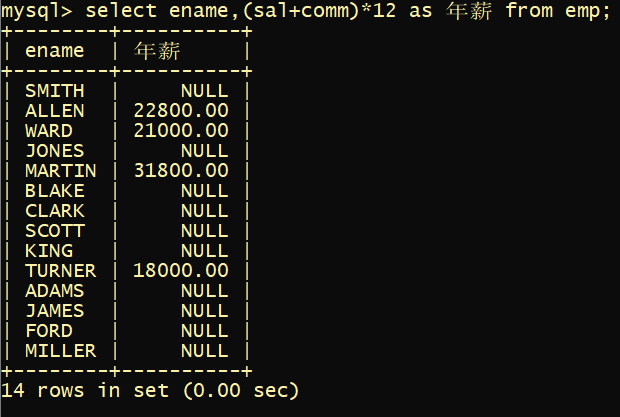
算数表达式中有NULL则计算出来就是NULL
如何处理:
ifnull()空处理函数:ifnull ( 可能为NULL的数据 , 被当作什么处理 )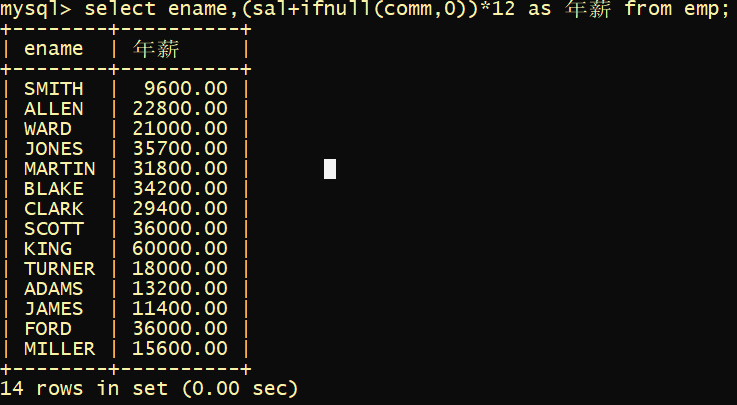
-
分组函数不可直接使用在where语句中
3.1 count
-- count(*) //统计总记录条数,和某个字段无关
-- count(comm) //表示统计comm字段中不为NULL的数据总数
SELECT * FROM student;
-- 韩顺平 89 78 90
-- 张飞 67 98 56
-- 宋江 87 78 77
-- 关羽 88 98 90
-- 赵云 82 84 67
-- 欧阳锋 55 85 45
-- 黄蓉 75 65 30
-- 韩信 45 65 99
-- (Null) 100 100 100
SELECT COUNT(*) FROM student;
-- 9
select COUNT(name) FROM student;
-- 8
3.2 sum
sum仅对数值类型起作用
select SUM(math),SUM(english) FROM student;
-- 654 751
3.3 avg
avg仅对数值类型起作用
SELECT AVG(math) FROM student;
-- 72.66666666666667
3.4 max / min
max, min 仅对数值类型起作用
SELECT MAX(chinese + math + english) as 总分最高分,min(chinese + math + english) as 总分最低分 FROM student;
-- 300 170
4. group by
SELECT * FROM `emp`;
-- empno ename job mgr hireadate sal comm deptno
-- 7369 SMITH CLERK 7902 1990-12-17 800.00 20
-- 7499 ALLEN SALESMAN 7698 1991-02-20 1600.00 300.00 30
-- 7521 WARD SALESMAN 7698 1991-02-22 1250.00 500.00 30
-- 7566 JONES MANAGER 7839 1991-04-02 2975.00 20
-- 7654 MARTIN SALESMAN 7698 1991-09-28 1250.00 1400.00 30
-- 7698 BLAKE MANAGER 7839 1991-05-01 2850.00 30
-- 7782 CLARK MANAGER 7839 1991-06-09 2450.00 10
-- 7788 SCOTT ANALYST 7566 1991-04-19 3000.00 20
-- 7839 KING PRESIDENT 1991-11-17 5000.00 10
SELECT * FROM `dept`;
-- deptno dname loc
-- 10 ACCOUNTING NEW YORK
-- 20 RESEARCH DALLAS
-- 30 SALES CHICAGO
-- 40 OPERATIONS BOSHTON
SELECT * FROM `salgrade`;
-- grade losal hisal
-- 1 700.00 1200.00
-- 2 1201.00 1400.00
-- 3 1401.00 2000.00
-- 4 2001.00 3000.00
-- 5 3001.00 9999.00
# 通过部门分组,查询不同部门的平均工资、最高工资、最低工资
SELECT AVG(sal), MAX(sal),MIN(sal)
FROM emp
GROUP BY deptno;
-- 2443.750000 3000.00 800.00
-- 1566.666667 2850.00 950.00
-- 2916.666667 5000.00 1300.00
# 这里我先加入了一组数据以便观察 下面的分组函数
INSERT INTO emp VALUES(9999,'XXXX','CLERK',7782,'1991-2-23',1700,NULL,10);
SELECT * FROM emp WHERE deptno = 10;
-- 7782 CLARK MANAGER 7839 1991-06-09 2450.00 10
-- 7839 KING PRESIDENT 1991-11-17 5000.00 10
-- 7934 MILLER CLERK 7782 1991-01-23 1300.00 10
-- 9999 XXXX CLERK 7782 1991-02-23 1700.00 10
# GROUP BY 将相同的deptno和job放入一个分组,然后按照部门编号排序
SELECT AVG(sal), MAX(sal),MIN(sal),deptno,job
FROM emp
GROUP BY deptno,job
ORDER BY deptno;
-- 1500.000000 1700.00 1300.00 10 CLERK
-- 2450.000000 2450.00 2450.00 10 MANAGER
-- 5000.000000 5000.00 5000.00 10 PRESIDENT
-- 3000.000000 3000.00 3000.00 20 ANALYST
-- 800.000000 800.00 800.00 20 CLERK
-- 2975.000000 2975.00 2975.00 20 MANAGER
-- 950.000000 950.00 950.00 30 CLERK
-- 2850.000000 2850.00 2850.00 30 MANAGER
-- 1400.000000 1600.00 1250.00 30 SALESMAN
# 可以发现10号 部门的CLERK 平均工资确实是 (1300+1700)/ 2 = 1500,最高最低工资也是对的
5. having
having 是在 group by分组之后,再进行过滤
SELECT AVG(`sal`) as '平均工资',deptno
FROM emp GROUP BY deptno
HAVING `平均工资` < 2000;
-- 平均工资 deptno
-- 1566.666667 30
6. group by 和 having
group by :按照某个字段或者某些字段进行分组
having:having是对分组之后的数据进行再次过滤,having是group by的搭档,只有group by之后才能having
分组函数一般都会和 group by 联合使用,且任何一个分组函数(count、sum、avg、max、min)都是在group by 语句执行结束之后才会执行的;当一条 sql 语句中没有 group by的话,整张表自成一组
group by是在where语句之后才执行
select ename.sal from emp where sal > avg(sal); //error
因为分组函数在group by之后才会执行,而group by又是在where语句结束之后才会执行,但是这个语句中还未分组就要执行where语句了,故错误
例:找出工资高于平均工资的员工
step1. 找出平均工资
select avg(sal) from emp;
+-------------+
| avg(sal) |
+-------------+
| 2073.214286 |
+-------------+
step2. 找出高于平均工资的人
select ename,sal from emp where sal > 2073.214286;
+-------+---------+
| ename | sal |
+-------+---------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
+-------+---------+
合并
select ename,sal from emp where sal > (select avg(sal) from emp);
+-------+---------+
| ename | sal |
+-------+---------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
+-------+---------+
例:找出每个工作岗位的最高薪资
select max(sal),job from emp group by job;
+----------+-----------+
| max(sal) | job |
+----------+-----------+
| 1300.00 | CLERK |
| 1600.00 | SALESMAN |
| 2975.00 | MANAGER |
| 3000.00 | ANALYST |
| 5000.00 | PRESIDENT |
+----------+-----------+
而 select ename,max(sal),job from emp group by job; 可以执行但结果错了,在Oracle数据库中直接报错
当sql语句出现group by时,select 之后只能出现与group by之后相关的语句(分组函数、参与分组的字段)
例:找出每个部门不同工资岗位的最高薪资(按照部门编号排序)
select
deptno,job,max(sal)
from
emp
group by
deptno,job
order by
deptno;
+--------+-----------+----------+
| deptno | job | max(sal) |
+--------+-----------+----------+
| 10 | CLERK | 1300.00 |
| 10 | MANAGER | 2450.00 |
| 10 | PRESIDENT | 5000.00 |
| 20 | ANALYST | 3000.00 |
| 20 | CLERK | 1100.00 |
| 20 | MANAGER | 2975.00 |
| 30 | CLERK | 950.00 |
| 30 | MANAGER | 2850.00 |
| 30 | SALESMAN | 1600.00 |
+--------+-----------+----------+
例:找出部门最高薪资大于2900的
mysql> select max(sal),deptno from emp group by deptno having max(sal) > 2900;
+----------+--------+
| max(sal) | deptno |
+----------+--------+
| 3000.00 | 20 |
| 5000.00 | 10 |
+----------+--------+
2 rows in set (0.00 sec)
mysql> select max(sal),deptno from emp where sal > 2900 group by deptno; //效率较高,where比 group by先执行
+----------+--------+
| max(sal) | deptno |
+----------+--------+
| 3000.00 | 20 |
| 5000.00 | 10 |
+----------+--------+
2 rows in set (0.00 sec)
例:找出部门平均薪资大于2000的数据
select deptno,avg(sal) from emp where avg(sal) > 2000 group by deptno; //error
//where 后不能用 分组函数
mysql> select avg(sal),deptno from emp group by deptno having avg(sal) > 2000;
+-------------+--------+
| avg(sal) | deptno |
+-------------+--------+
| 2175.000000 | 20 |
| 2916.666667 | 10 |
+-------------+--------+
2 rows in set (0.00 sec)
7. 查询结果去重
distinct 关键字
select enma,distinct job from emp; //error distinct 只能出现在所有字段最前方
表示去重后面所有字段 :联合去重
例:统计岗位数量
select count(distinct job) from emp;
+---------------------+
| count(distinct job) |
+---------------------+
| 5 |
+---------------------+
1 row in set (0.00 sec)
10. 字符串相关函数
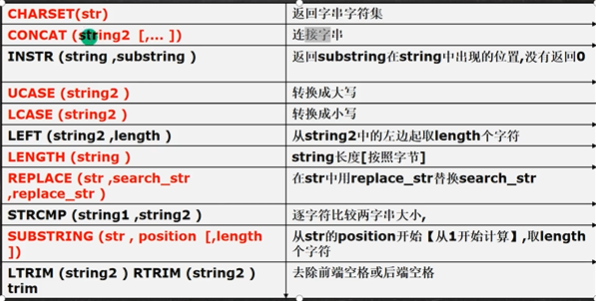
# 这里用了反斜杠做转义字符
SELECT CONCAT(ename,'\'s job is ',job) as '说明' FROM emp;
-- 说明
-- SMITH's job is CLERK
-- ALLEN's job is SALESMAN
-- WARD's job is SALESMAN
-- JONES's job is MANAGER
-- MARTIN's job is SALESMAN
-- BLAKE's job is MANAGER
-- CLARK's job is MANAGER
-- SCOTT's job is ANALYST
-- KING's job is PRESIDENT
# DUAL:亚元表,系统表,可以作为测试表使用
SELECT INSTR('xiaoming','ming') FROM DUAL;
-- 5
# 转小写
SELECT LCASE(ename) FROM emp;
#从左边取n个字符
SELECT LEFT(ename,2) FROM emp;
-- SM
-- AL
-- WA
-- JO
-- MA
-- BL
-- CL
-- SC
-- KI
#从右边取n个字符
SELECT RIGHT(ename,2) FROM emp;
-- TH
-- EN
-- RD
-- ES
-- IN
-- KE
-- RK
-- TT
-- NG
# 以下两个字符串均不在 emp 中,但是可以显示
SELECT LENGTH('xxx') FROM emp;
-- 3
SELECT LENGTH('小明') FROM emp;
-- 6
SELECT REPLACE(job,'MANAGER','经理') FROM emp;
-- CLERK
-- SALESMAN
-- SALESMAN
-- 经理
-- SALESMAN
-- 经理
-- 经理
-- ANALYST
-- PRESIDENT
# 相等返回0,不相等逐字比较两字符串大小,返回-1或1
SELECT STRCMP('xxx','XXX') FROM DUAL;
-- 0 DUAL表不区分大小写
SELECT STRCMP('a','b') FROM DUAL;
-- -1
SELECT STRCMP('b','a') FROM DUAL;
-- 1
# 从第一个位置取2个字符,初始位置从1开始
SELECT SUBSTR(ename,1,2) FROM emp;
# 去除左右空格
SELECT LTRIM(' 你好') FROM DUAL;
SELECT RTRIM('你好 ') FROM DUAL;
11. 数学相关函数

小题目:
SELECT COUNT(job),AVG(sal),job FROM emp GROUP BY job
SELECT COUNT(*) as '员工总数',( SELECT count(*) FROM emp WHERE comm IS NOT NULL or comm > 0) AS '有奖金员工总数' FROM emp;
-- 与上面那个功能一样
-- IF 里面 那个1,只要是非空值即可,不仅限于'1'
SELECT COUNT(*) AS '员工总数', COUNT(IF(comm IS NULL,NULL,1)) AS '有奖金员工总人数' FROM emp;
SELECT COUNT(*) as '经理总数' FROM emp WHERE job = 'MANAGER';
SELECT MAX(sal) - MIN(sal) FROM emp;
12. 时间日期相关函数

unix_timestamp() 返回的是 1970-1-1到现在的秒数
# 从一个时间戳转换转换成指定格式的日期
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),'%Y-%m-%d') FROM DUAL;
-- 2022-04-20
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),'%Y-%m-%d %H:%m:%s') FROM DUAL;
-- 2022-04-20 09:04:16
# 在实际开发中,我们经常使用int来保存一个unix时间戳,然后使用from_unixtime()进行转换,还是非常有实用价值的

# 显示发送时间在十分钟中内的信息
select * from mes where DATE_ADD(send_time,INVERVAL 10 MINUTE) >= NOW();
send_time NOW()
\-------------|-------------------|-------------\
|____________+10__________|
send_time + 10 >= NOW() 即可说明是在10分组内发送的
13. 加密和系统函数
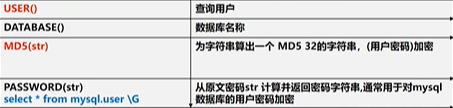
# 注意:MySQL8.0 版本以后password函数被弃用,可以使用MD5 或 SHA1替代
# 用户@ip
SELECT USER(); -- SELECT USER() FROM DUAL;也可以
-- root@localhost
# 查询当前使用的数据库名称
SELECT DATABASE();
# MD5(str) 为字符串算出一个 MD5 32位的字符串,常用用户密码加密
# 不管str是多少位,MD5 都是32位的
SELECT MD5('123456');
-- e10adc3949ba59abbe56e057f20f883e
SELECT LENGTH(MD5('123456'));
-- 32
CREATE TABLE `user`
(id INT,
`name` VARCHAR(32) NOT NULL DEFAULT ' ',
pwd CHAR(32) NOT NULL DEFAULT ' ');
INSERT into `user`
VALUES(111,'小红',MD5('this is a password'));
SELECT * FROM `user` WHERE `name` = '小红' AND `pwd` = MD5('this is a password');
-- 111 小红 2986b7f0cd0ba9827ace0810c8818825
# PASSWORD(str) 加密函数,mysql数据库的用户密码就是 PASSWORD() 函数加密
# 但MySQL8.0以后该方法被弃用,可以使用MD5 或 SHA1 替代
SELECT SHA1('this is a password');
-- 11b2a5d9c9bb1633fdc13ac114d7f75031aef9dc
# 查询 数据库.表 的数据
SELECT * FROM mysql.`user`;
14. 流程控制函数

# IF 可以理解为 三目运算符
# 多分支那个最后只能返回一个值
SELECT ename ,IF(comm IS NULL,0.0,comm) FROM emp; -- NULL 用 IS
-- SMITH 0.0
-- ALLEN 300.00
-- WARD 500.00
-- JONES 0.0
-- MARTIN 1400.00
-- BLAKE 0.0
-- CLARK 0.0
-- SCOTT 0.0
-- KING 0.0
SELECT ename ,IFNULL(comm,0.0) FROM emp;
-- SMITH 0.00
-- ALLEN 300.00
-- WARD 500.00
-- JONES 0.00
-- MARTIN 1400.00
-- BLAKE 0.00
-- CLARK 0.00
-- SCOTT 0.00
-- KING 0.00
SELECT ename,(SELECT CASE job
WHEN 'CLERK' THEN '职员'
WHEN 'MANAGER' THEN '经理'
WHEN 'SALESMAN' THEN '销售'
ELSE '分析师' END)
FROM emp;
-- SMITH 职员
-- ALLEN 销售
-- WARD 销售
-- JONES 经理
-- MARTIN 销售
-- BLAKE 经理
-- CLARK 经理
-- SCOTT 分析师
-- KING 分析师
15. 分页查询

-- 第1页内容
SELECT * FROM emp
ORDER BY empno
LIMIT 0,3;
-- 第2页内容
SELECT * FROM emp
ORDER BY empno
LIMIT 3,3;
-- 推导一个公式
SELECT * FROM emp
ORDER BY empno
LIMIT 每页显示记录数 * (第几页 - 1),每页显示记录数
16. 多表查询
基本知识
# 默认情况下,两个表查询时,规则:
# 1.从第一张表中,取出一行 和 第二张表的每一行进行组合,再从第一张表取一行,与第二张表的每一行组合,直到第一张表每行都取完,返回结果中包含两张表的所有列
# 2.一共返回的记录数= 第一张表行数*第二张表的行数
# 3.这样多表查询默认处理返回的结果,称为笛卡尔集
# 4.解决这个多表查询的关键就是要写出正确的过滤条件 WHERE
SELECT * FROM emp,dept;
# 显示 员工名,工资,部门名称(要过滤,两张表的部门编号要匹配)
SELECT ename,sal,dname
FROM emp,dept
WHERE emp.deptno = dept.deptno;
# 显示 员工名,工资,部门名称,部门编号(要过滤,两张表的部门编号要匹配)
-- SELECT ename,sal,dname,deptno -- error 因为两张表都有部门编号,所以要特别指定是哪张表--> 表.列名
-- FROM emp,dept
-- WHERE emp.deptno = dept.deptno;
SELECT ename,sal,dname,emp.deptno
FROM emp,dept
WHERE emp.deptno = dept.deptno;
#显示各个员工姓名,工资,工资级别
-- 思路 姓名,工资来自emp, 工资级别来自 salgrade
SELECT ename,sal,grade
FROM emp,salgrade
WHERE sal BETWEEN losal AND hisal;
16.1 自连接
将同一张表,看作两张表
SELECT * FROM emp;
-- 7369 SMITH CLERK 7902 1990-12-17 800.00 20
-- 7499 ALLEN SALESMAN 7698 1991-02-20 1600.00 300.00 30
-- 7521 WARD SALESMAN 7698 1991-02-22 1250.00 500.00 30
-- 7566 JONES MANAGER 7839 1991-04-02 2975.00 20
-- 7654 MARTIN SALESMAN 7698 1991-09-28 1250.00 1400.00 30
-- 7698 BLAKE MANAGER 7839 1991-05-01 2850.00 30
-- 7782 CLARK MANAGER 7839 1991-06-09 2450.00 10
-- 7788 SCOTT ANALYST 7566 1991-04-19 3000.00 20
-- 7839 KING PRESIDENT 1991-11-17 5000.00 10
-- 7844 TURNER SALESMAN 7698 1991-09-08 1500.00 30
-- 7900 JAMES CLERK 7698 1991-12-03 950.00 30
-- 7902 FORD ANALYST 7566 1991-12-03 3000.00 20
-- 7934 MILLER CLERK 7782 1991-01-23 1300.00 10
# 显示员工姓名 和其上级姓名
# 思路:把一张表当作两张表使用 --起别名
# 要查询的信息,它们之间有什么关联 --WHERE
# 列名不明确可以重命名
SELECT worker.ename AS '员工名', boss.ename AS '上级名'
FROM emp worker,emp boss -- 这里也可以写作 emp AS worker,emp AS boss
WHERE worker.mgr = boss.empno;
-- FORD JONES
-- SCOTT JONES
-- JAMES BLAKE
-- TURNER BLAKE
-- MARTIN BLAKE
-- WARD BLAKE
-- ALLEN BLAKE
-- MILLER CLARK
-- CLARK KING
-- BLAKE KING
-- JONES KING
-- SMITH FORD
16.2 子查询
子查询是指嵌入在其它sql语句中的select语句,也叫嵌套查询。
单行子查询:只返回一行数据的子查询语句
多行子查询:返回多行数据的子查询,使用关键字 in
SELECT ename,job,sal,deptno FROM emp WHERE deptno = 10;
-- CLARK MANAGER 2450.00 10
-- KING PRESIDENT 5000.00 10
-- MILLER CLERK 1300.00 10
# 查询与部门10的员工工作相同的雇员的名字、岗位、工资、部门号、但是不包括10自己的。
SELECT
ename,
job,
sal,
deptno
FROM
emp
WHERE
job IN ( SELECT DISTINCT job FROM emp WHERE deptno = 10 )
AND deptno <> 10;
-- SMITH CLERK 800.00 20
-- JONES MANAGER 2975.00 20
-- BLAKE MANAGER 2850.00 30
-- JAMES CLERK 950.00 30
16.2.1 子查询当作临时表
# 找出每类商品价格最高的商品名称,商品编号,商品价格
# 以下 并没有表,只作为思维演示
SELECT
goods_name,
goods_id,
goods_price
FROM
# 先按商品类型goods_id分组得到各种类型商品的最大价格作为子表
# 再和商品表组合查询,条件为goods表商品的类型id 和子表的商品id一样,goods表商品的价格和子表的max_price一样
( SELECT goods_id, MAX( goods_price ) AS max_price FROM goods GROUP BY goods_id ) temp, -- 查询的表起别名,再和另外的表组合查询
goods
WHERE
temp.goods_id = goods.goods_id
AND temp.max_price = goods.goods_price;
16.2.2 表复制
CREATE TABLE my_test01 ( id INT, `name` VARCHAR ( 32 ), sal DOUBLE, job VARCHAR ( 32 ), deptno INT );
DESC my_test01;
# 把emp表内数据复制到my_table01
INSERT INTO my_test01 ( id, `name`, sal, job, deptno ) SELECT
empno,
ename,
sal,
job,
deptno
FROM
emp;
SELECT * FROM my_test01; -- successful
# 自我复制(蠕虫复制)
# 每次复制都是追加形式
# 可以用于测试数据检索速度
INSERT INTO my_test01 SELECT
*
FROM
my_test01;
-----------------------------------------------------------------
CREATE TABLE my_test02 LIKE emp; -- 这个语句把emp表的结构(列)复制到my_test02
INSERT INTO my_test02 SELECT * FROM emp; -- 创建一个有重复数据的表
# 去重
-- 1.
CREATE TABLE my_temp LIKE my_test02;
-- 2.
INSERT INTO my_temp SELECT DISTINCT * FROM my_test02;
-- 3.
DELETE FROM my_test02;
-- 4.
INSERT INTO my_test02 SELECT * FROM my_temp;
-- 5.
DROP TABLE my_temp;
17. 合并查询
有时在实际应用中,为了合并多个select语句的执行结果,可以使用集合操作符号 union,union all
union all
该操作符用于取得两个结果集的并集,当使用该操作符时,不会取消重复行
union
与union all相似,但是会自动去掉结果集中的重复行
18. 外连接
# 左外连接:如果左侧的表完全显示(即使没有和左表匹配的项,也会将左表完全显示)我们就说是左外连接
SELECT ... FROM 表1 LEFT JOIN 表2 ON 条件
# 右外连接,同理
SELECT
dept.deptno,
ename
FROM
dept
LEFT JOIN emp ON emp.deptno = dept.deptno;
-- 10 MILLER
-- 10 KING
-- 10 CLARK
-- 20 FORD
-- 20 SCOTT
-- 20 JONES
-- 20 SMITH
-- 30 JAMES
-- 30 TURNER
-- 30 BLAKE
-- 30 MARTIN
-- 30 WARD
-- 30 ALLEN
-- 40 (Null)
SELECT
dname,
ename,
job
FROM
dept
LEFT JOIN emp ON dept.deptno = emp.deptno;
-- ACCOUNTING MILLER CLERK
-- ACCOUNTING KING PRESIDENT
-- ACCOUNTING CLARK MANAGER
-- RESEARCH FORD ANALYST
-- RESEARCH SCOTT ANALYST
-- RESEARCH JONES MANAGER
-- RESEARCH SMITH CLERK
-- SALES JAMES CLERK
-- SALES TURNER SALESMAN
-- SALES BLAKE MANAGER
-- SALES MARTIN SALESMAN
-- SALES WARD SALESMAN
-- SALES ALLEN SALESMAN
-- OPERATIONS (Null) (Null)
19. 约束
# 约束用于确保数据库的数据满足特定的商业规则,约束包括:
# NOT NULL
-- 非空
# UNIQUE
-- 该列不能重复,但是如果默认可以为Null则可以有多个Null,如果一个列(字段)是 unique not null 使用效果类似 primary key
-- 一个表中可以有多个字段为unique
# PRIMARY KEY -- 主键,主键唯一(可以复合主键)且非空
# FOREIGN KEY -- 外键
# CHECK -- 用于强制行数据必须满足的条件
# 五种
# 主键
# 1.
CREATE TABLE t1
( id INT PRIMARY KEY,
`name` VARCHAR(32),
sal DOUBLE
);
# 2.
CREATE TABLE t1
( id INT,
`name` VARCHAR(32),
sal DOUBLE,
PRIMARY KEY(id)
);
# 复合主键
CREATE TABLE t2
(
id INT,
`name` VARCHAR(32),
sal DOUBLE,
PRIMARY KEY(id,`name`) -- 复合主键
);
DESC t2; -- 也会显示约束情况 PRI-->主键,出现两个或以上则说明它们是复合主键
-- id int NO PRI
-- name varchar(32) NO PRI
-- sal double YES
# 外键
# 用于定义主表和从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或是unique约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null
-- 细节说明
# 1.外键指向表的字段,要求是primary key或者是unique
# 2.表的类型是innodb,这样的表才支持外键
# 3.外键的字段的类型要和主键字段的类型一致(长度可以不同)
# 4.外键字段的值,必须在主键字段中出现过,或者为null(前提是外键字段允许为null)
# 5.一旦建立主外键的关系,数据就不能随意删除了

CREATE TABLE `class`
(
id INT PRIMARY KEY,
`name` VARCHAR(32)
);
CREATE TABLE `student`
(
id INT PRIMARY KEY,
`name` VARCHAR(32) NOT NULL DEFAULT '',
class_id INT,
FOREIGN KEY (class_id) REFERENCES `class`(id)
);
INSERT INTO class VALUES(100,'java'),(200,'web');
SELECT * FROM class;
INSERT INTO student VALUES(1,'tom',100);
INSERT INTO student VALUES(2,'jack',200);
INSERT INTO student VALUES(3,'john',300); -- error,外键依赖项(class.id) 没有300
INSERT INTO student VALUES(4,'lucy',NULL); -- successful
# 如果没有外键指向该条记录则可以删除,否则不行
DELETE FROM class WHERE id = 100; -- error,因为有个外键指向它id = 100了
DELETE FROM student WHERE `name` = 'tom';
DELETE FROM class WHERE id = 100; -- successful
# CHECK
CREATE TABLE t3
( id INT PRIMARY KEY,
`name` VARCHAR(32),
sex VARCHAR(6) CHECK (sex IN ('man','woman')),
sal DOUBLE CHECK ( sal > 1000 AND sal < 2000)
);
INSERT INTO t3 VALUES(1,'tom','M',1200); -- error
INSERT INTO t3 VALUES(1,'tom','man',1200); -- successful
INSERT INTO t3 VALUES(2,'jerry','woman',2100); -- error
INSERT INTO t3 VALUES(2,'jerry','woman',1900); -- successful
20. 自增长
# 字段名 整型 primary key auto_increment
-- 使用细节
-- 1. 一般来说自增长是和primary key配合使用的
-- 2. 自增长也可以单独使用【但是需要配合一个unique】
-- 3. 自增长修饰的字段为整数型的(虽然小数也可以,但是使用非常少)
-- 4. 自增长默认从1开始,你也可以通过如下命令修改 alter table 表名 auto_increment = 新的开始值
-- 5. 如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准,如果指定了自增长,一般来说就按照自增长的规则来添加数据
CREATE TABLE t4
(
id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(32) NOT NULL DEFAULT '',
`name` VARCHAR(32) NOT NULL DEFAULT ''
);
DESC t4;
INSERT INTO t4
VALUES
( NULL, 'jack@qq.com', 'jack' );
INSERT INTO t4
VALUES
( NULL, 'tom@qq.com', 'tom' );
INSERT INTO t4 ( email, `name` ) -- 原本没有自增长的时候,这样写是错的,但有了自增长id会自动加1
VALUES
( 'xxx@qq.com', 'xxx' );
SELECT * FROM t4;
# 修改自增长起始数,已经添加了的数据不影响
ALTER TABLE t4 AUTO_INCREMENT = 100;
INSERT INTO T4 VALUES(NULL,'qqq@qq.com','qqq');
SELECT * FROM t4;
-- 1 jack@qq.com jack
-- 2 tom@qq.com tom
-- 3 xxx@qq.com xxx
-- 100 qqq@qq.com qqq
INSERT INTO t4 VALUES(NULL,'www@qq.com','www');
SELECT * FROM t4;
-- 1 jack@qq.com jack
-- 2 tom@qq.com tom
-- 3 xxx@qq.com xxx
-- 100 qqq@qq.com qqq
-- 101 www@qq.com www
# 如果你添加了一个自增长处有值的数据,则后续则会按照这个值继续自增长
INSERT INTO t4 VALUES(999,'eee@qq.com','eee');
INSERT INTO t4 VALUES(NULL,'ttt@qq.com','ttt');
SELECT * FROM t4;
-- 1 jack@qq.com jack
-- 2 tom@qq.com tom
-- 3 xxx@qq.com xxx
-- 100 qqq@qq.com qqq
-- 101 www@qq.com www
-- 999 eee@qq.com eee
-- 1000 ttt@qq.com ttt
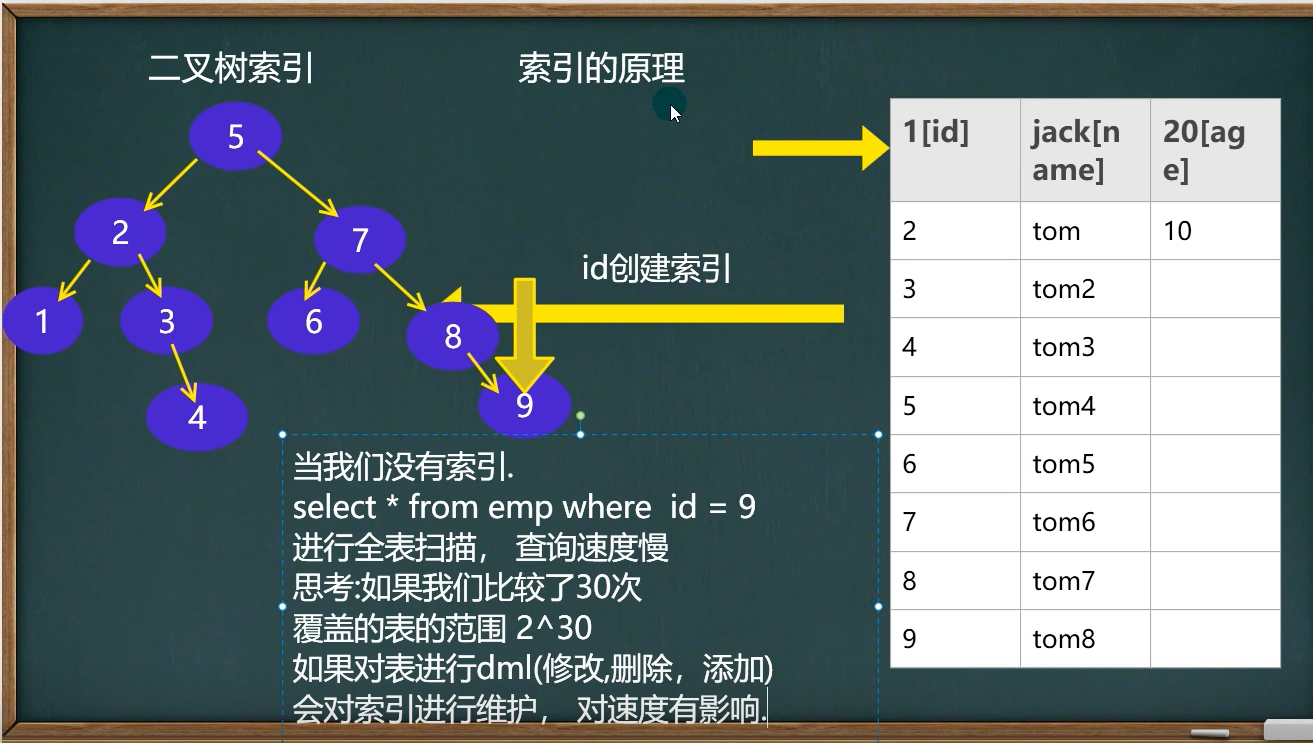
21. 索引
CREATE INDEX index_name ON 表(字段);
创建索引后文件会变大,索引也会占用空间
# 索引类型
# 1. 主键索引,设为主键(类型Primary Key),则自动生成主键索引
# 2. 唯一索引(UNIQUE)
# 3. 普通索引(INDEX)
# 4. 全文索引(FULLTEXT) [适用于MyISAM]
# 开发中一般不用MySQL自带的而考虑使用:全文搜索 Solr 和 ElasticSearch(ES)
CREATE TABLE T1
(
id INT PRIMARY KEY -- 主键,同时也是索引,称为主键索引
user_account VARCHAR(32) UNIQUE -- 唯一约束,同时也是索引,称为unique索引
)
CREATE TABLE t5 (
id INT,
`name` VARCHAR ( 32 ));
# 查看某表是否有索引
SHOW INDEXES FROM t5;
# 添加索引方式1
# 如果某列的值不会重复,优先使用unique索引
# 添加唯一索引
CREATE UNIQUE INDEX id_index ON t5(id);
# 添加普通索引
CREATE INDEX id_index ON t5(id);
# 添加索引方式2
# 添加普通索引
ALTER TABLE t5 ADD INDEX id_index(id);
# 添加主键索引
ALTER TABLE t5 ADD PRIMARY KEY (id);
# 删除索引
DROP INDEX id_index ON t5;
# 或
ALTER TABLE t5 DROP INDEX id_index;
# 删除主键索引,因为主键唯一,所以不用指定是哪一列
ALTER TABLE t5 DROP PRIMARY KEY;
# 修改索引:先删除,再创建
# 查看索引
# 1.
SHOW INDEX FROM t5;
# 2.
SHOW INDEXES FROM t5;
# 3.
SHOW KEYS FROM t5;
# 4. 这个显示索引的信息比上面的少很多,就看Key字段
DESC t5;

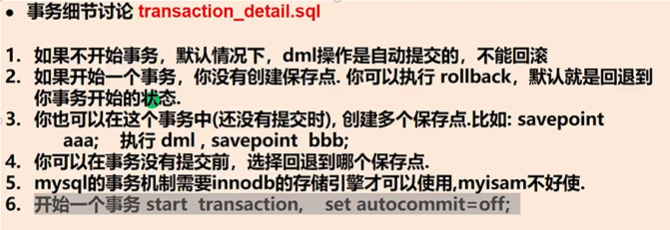
22. 事务
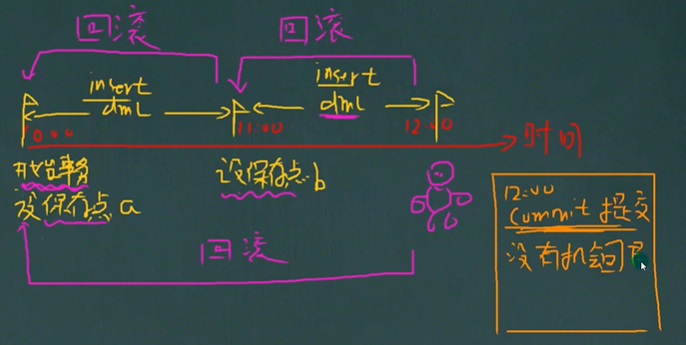
22.1 什么是事务
# 什么是事务,事务用于保证数据的一致性,它由一组相关的dml(增、删、改)语句组成,该组的dml语句要么全部成功,要么全部失败。如:转账就要用事务来处理,以保证数据的一致性。
CREATE TABLE t6 (
id INT,
`name` VARCHAR ( 32 ));
START TRANSACTION;
SAVEPOINT a;
INSERT INTO t6 VALUES(1,'tom');
SAVEPOINT b;
INSERT INTO t6 VALUES(2,'jack');
COMMIT;
SELECT * FROM t6;
ROLLBACK TO a; -- 可以回到任意保存点,回了以后该保存点的后面语句算未执行过,但是commit过了的话就回不去了
--
-- ROLLBACK TO b;
-- ROLLBACK; -- 如果是这样,表示直接回到事务开始的状态

22.2 事务隔离级别
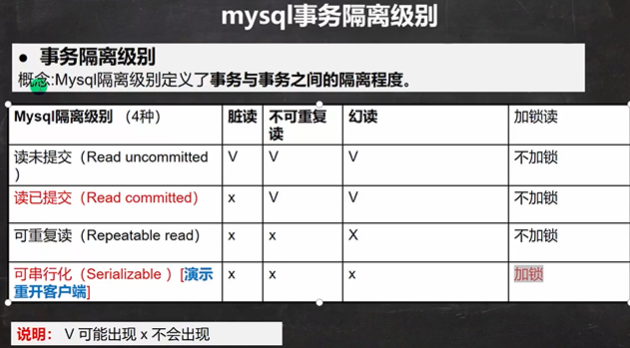
# 隔离级别与事务相关联,没有事务,隔离级别就是空谈
# 通过设置事务的隔离级别能有效改变一些问题
# -- 控制台 1 ---
# 查看当前mysql事务隔离级别
mysql> SELECT @@transaction_isolation;
-- +-------------------------+
-- | @@transaction_isolation |
-- +-------------------------+
-- | REPEATABLE-READ |
-- +-------------------------+
-- 1 row in set (0.00 sec)
# 设置隔离级别为 读未提交(read uncommitted)
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@transaction_isolation;
-- +-------------------------+
-- | @@transaction_isolation |
-- +-------------------------+
-- | READ-UNCOMMITTED |
-- +-------------------------+
-- 1 row in set (0.00 sec)
# 开始事务
mysql> start transaction;
-- Query OK, 0 rows affected (0.00 sec)
# 选用一个数据库
mysql> use db_yhx;
-- Database changed
# 创建一个表
CREATE TABLE `account` ( id INT, `name` VARCHAR ( 32 ), money INT );
-- Query OK, 0 rows affected (0.07 sec)
# 插入一个数据
mysql> INSERT INTO account VALUES(1,'tom',1000);
-- Query OK, 1 row affected (0.02 sec)
# 让控制台2 去查看,发现出现脏读现象
# 控制台1 这边读 也可以读到
SELECT * FROM `account`;
-- +------+------+-------+
-- | id | name | money |
-- +------+------+-------+
-- | 1 | tom | 1000 |
-- +------+------+-------+
-- 1 row in set (0.00 sec)
# 控制台1 修改数据
mysql> UPDATE `account` SET `money` = 999 WHERE `id` = 1;
-- Query OK, 1 row affected (0.09 sec)
-- Rows matched: 1 Changed: 1 Warnings: 0
# 控制台1 继续添加数据,并提交事务
mysql> INSERT INTO account VALUES(2,'tony',4000);
-- Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO account VALUES(3,'jerry',500);
-- Query OK, 1 row affected (0.01 sec)
mysql> COMMIT;
-- Query OK, 0 rows affected (0.00 sec)
# 此时让控制台2 去读。出现了不可重复读、幻读
# -- 控制台2 ---
mysql> SELECT @@transaction_isolation;
-- +-------------------------+
-- | @@transaction_isolation |
-- +-------------------------+
-- | REPEATABLE-READ |
-- +-------------------------+
-- 1 row in set (0.00 sec)
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- +-------------------------+
-- | @@transaction_isolation |
-- +-------------------------+
-- | READ-UNCOMMITTED |
-- +-------------------------+
-- 1 row in set (0.00 sec)
mysql> start transaction;
-- Query OK, 0 rows affected (0.00 sec)
mysql> use db_yhx;
-- Database changed
# 居然在事务没有提及的前提下,读到了数据 ---> 脏读
SELECT * FROM `account`;
-- +------+------+-------+
-- | id | name | money |
-- +------+------+-------+
-- | 1 | tom | 1000 |
-- +------+------+-------+
-- 1 row in set (0.00 sec)
# 控制台1 提交事务后 控制台2 居然读到的数据变成了控制台1 更改过的数据
# 不可重复读 -> 事务A的提交影响了事务B的查询结果
# 幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
mysql> SELECT * FROM account;
-- +------+-------+-------+
-- | id | name | money |
-- +------+-------+-------+
-- | 1 | tom | 999 |
-- | 2 | tony | 4000 |
-- | 3 | jerry | 500 |
-- +------+-------+-------+
-- 3 rows in set (0.00 sec)
一些指令

事务的acid特性

23. MySQL表类型和存储引擎


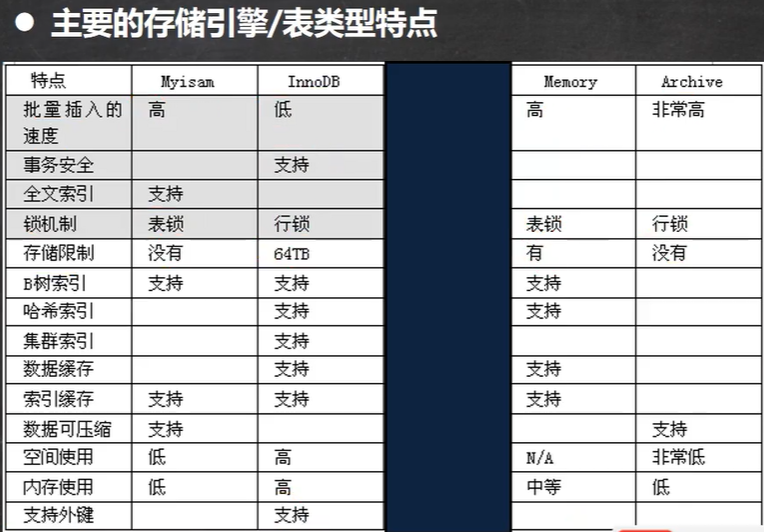

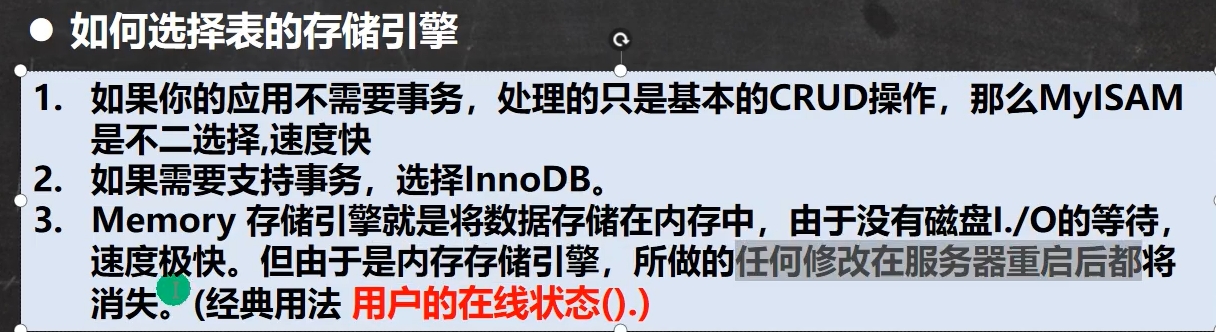
# 修改存储引擎
ALTER TABLE `表名` ENGINE = 存储引擎;
24. 视图(view)
# 视图是一个虚拟表,其内容由查询定义,同真实的表一样,视图包含列,其数据来自对应的真实表(基表)
# 应用:你想让一个用户只能看到一个表的部分列,可以通过视图只让他看其中的某几个列,视图其实是一种对基表的映射
# 总结
# 1.视图是根据基表(可以是多个基表)来创建的,视图是虚拟的表
# 2.视图也有列,数据来自基表
# 3.通过视图可以修改基表的数据
# 4.基表的改变,也会影响到视图的数据
# 创建视图
CREATE VIEW emp_view
AS
SELECT empno,ename,job,deptno FROM emp;
# 查看视图
DESC emp_view;
SELECT * FROM emp_view;
-- +-------+--------+-----------+--------+
-- | empno | ename | job | deptno |
-- +-------+--------+-----------+--------+
-- | 7369 | SMITH | CLERK | 20 |
-- | 7499 | ALLEN | SALESMAN | 30 |
-- | 7521 | WARD | SALESMAN | 30 |
-- | 7566 | JONES | MANAGER | 20 |
-- | 7654 | MARTIN | SALESMAN | 30 |
-- | 7698 | BLAKE | MANAGER | 30 |
-- | 7782 | CLARK | MANAGER | 10 |
-- | 7788 | SCOTT | ANALYST | 20 |
-- | 7839 | KING | PRESIDENT | 10 |
-- | 7844 | TURNER | SALESMAN | 30 |
-- | 7900 | JAMES | CLERK | 30 |
-- | 7902 | FORD | ANALYST | 20 |
-- | 7934 | MILLER | CLERK | 10 |
-- +-------+--------+-----------+--------+
# 查看创建视图的指令
SHOW CREATE VIEW emp_view;
-- emp_view CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `emp_view` AS select `emp`.`empno` AS `empno`,`emp`.`ename` AS `ename`,`emp`.`job` AS `job`,`emp`.`deptno` AS `deptno` from `emp` utf8mb4 utf8mb4_0900_ai_ci
# 删除视图
DROP VIEW emp_view;
- 创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式:视图名.frm)
- 视图中可以再使用视图
CREATE VIEW emp_view2
AS
SELECT empno,ename FROM emp_view;
-- 这个视图的改变也会影响基表
视图的最佳实践

# 课后作业:创建一个显示雇员编号,雇员名,官员部门名称 和 薪水级别(即使用三张表 构建一个视图)
# 三表查询 得要两个限制条件,n个表联合查询,要n-1个限制条件
CREATE VIEW emp_view3 AS SELECT
empno,
ename,
dname,
grade
FROM
emp,
dept,
salgrade
WHERE
emp.deptno = dept.deptno
AND ( sal BETWEEN losal AND hisal );
25. MySQL管理
# MySQL中的用户,都存储在数据库mysql中user表中
-- user表的重要字段名
# host 允许登录的“位置”,localhost表示该用户只允许本机登录,也可以指定ip地址
# user:用户名
# authentication_string:密码,是通过mysql的加密函数之后的密码
-- 用户管理的目的
# 可以根据不同的开发人员,赋给他相应的mysql操作权限
# 创建用户
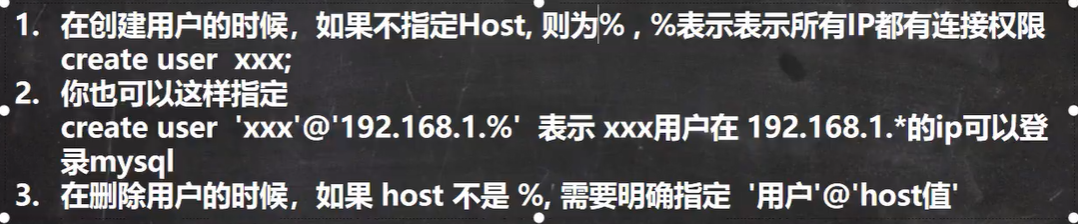
CREATE USER '用户名' @'允许登录的ip' IDENTIFIED BY '密码';
# 删除用户
DROP USER '用户名' @'允许登录的位置';
# 修改密码
SET PASSWORD = PASSWORD('密码');
# 修改他人密码,需要权限
SET PASSWORD FOR '用户名'@'登录位置' = PASSWORD('密码');
权限管理

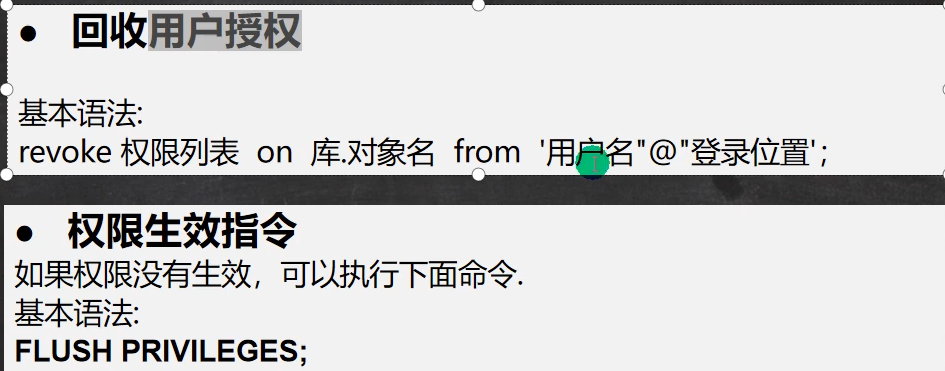
用户管理细节
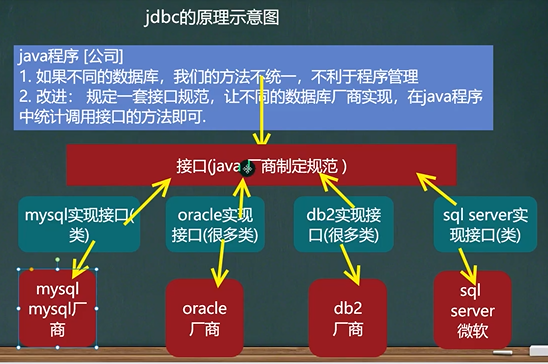
JDBC
# 1.JDBC为访问不同的数据库提供了统一的接口,为使用者屏蔽细节问题
# 2.Java程序员使用JDBC,可以连接任何提供了JDBC驱动程序的数据库系统,从而完成对数据库的各种操作
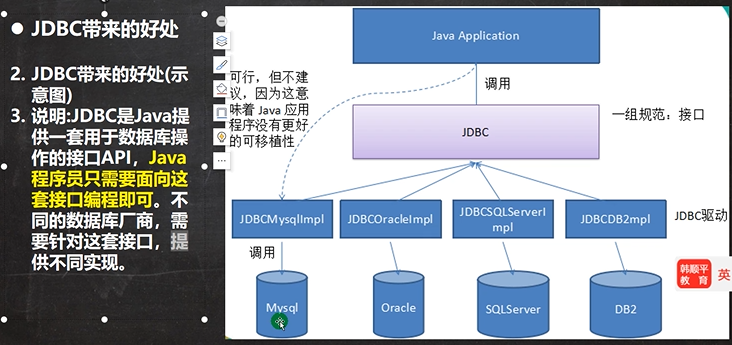
# JDBC API 是一系列的接口,它统一和规范了应用程序与数据库的连接、执行SQL语句,并得到返回结果等各类操作,相关类和接口在java.sql和javax.sql包中。
1. JDBC快速入门
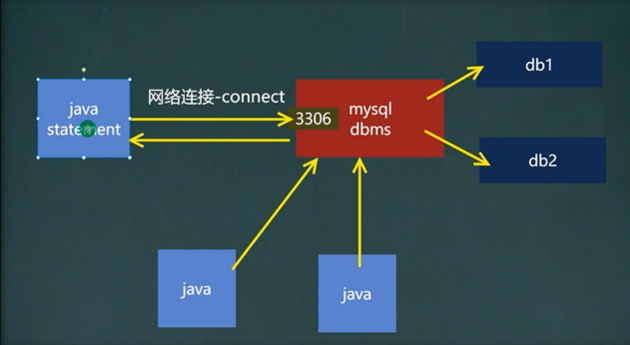
# 1.注册驱动 -- 加载Driver类
# 2.获取连接 -- 得到Connection
# 3.执行crud -- 发送SQL命令,给到mysql执行
# 4.释放资源 -- 关闭连接
package myJDBC02;
import com.mysql.cj.jdbc.Driver;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* 完成简单的操作
*/
public class jdbc01 {
public static void main(String[] args) throws SQLException {
//将mysql.jar 拷贝到该目录下,点击 加入到库 即加入到该项目中
//1.注册驱动
Driver driver = new Driver();
//2.得到连接
// "jdbc:mysql://localhost:3306/xxx_db";
//(1)jdbc:mysql:// 规定好的,表示协议,通过jdbc的方式连接mysql
//(2)localhost:表示主机,也可以是其他ip地址
//(3)3306 :表示mysql监听的端口
//(4)xxx_db :表示你要连接到哪个数据库
//(5)设置时区 ,UTC是全球标准时间,而我们使用的北京时间是东八区,领先UTC 8个小时,UTC + (+0800) = 北京时间
// 使用UTC插入时间会使时间不对,所以我这里使用了Shanghai时间
// mysql连接本质就是socket连接
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
//将用户名和密码放入到Properties对象中
Properties properties= new Properties();
// key值是规定好的,value根据自己的设定写
properties.setProperty("user","root"); //用户
properties.setProperty("password","123456"); //密码
//连接
Connection connect = driver.connect(url, properties);
//3.执行sql
// String sql = "insert into actor values(null,'刘德华','男','1970-11-11','111')";
String sql = "update actor set name = '周星驰' where id = 1;";
// 用于执行静态SQL语句并返回其生成的结果的对象
Statement statement = connect.createStatement();
int rows = statement.executeUpdate(sql); // 如果是dml(增删改)语句,则返回受影响行数
System.out.println(rows > 0?"成功":"失败");
//4.关闭连接
statement.close();
connect.close();
}
}
2. JDBC 的 5种连接方式
package myJDBC02;
import com.mysql.cj.jdbc.Driver;
import org.junit.jupiter.api.Test;
import java.io.FileInputStream;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Properties;
/**
* 连接 MySQL的5种方式
*/
public class jdbc02 {
public static void main(String[] args) {
}
@Test
//方式一:直接使用com.mysql.jdbc.Driver() 属于静态加载,灵活性差,依赖性强
public void connect01() throws SQLException {
Driver driver = new Driver();
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Properties properties= new Properties();
properties.setProperty("user","root"); //用户
properties.setProperty("password","123456"); //密码
//连接
Connection connect = driver.connect(url, properties);
System.out.println("方式一 "+ connect);
}
@Test
//方式二;反射机制,动态加载,更加灵活,减少依赖性
public void connect02() throws SQLException, NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException, ClassNotFoundException {
Class<?> clazz = Class.forName("com.mysql.cj.jdbc.Driver");
Driver driver = (Driver) clazz.getDeclaredConstructor().newInstance();
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Properties info = new Properties();
info.setProperty("user","root");
info.setProperty("password","123456");
Connection conn = driver.connect(url,info);
System.out.println("方式二 "+ conn);
}
@Test
// 方式三:使用DriverManager 替代Driver 进行统一管理
public void connect03() throws NoSuchMethodException, ClassNotFoundException, InvocationTargetException, InstantiationException, IllegalAccessException, SQLException {
Class<?> aClass = Class.forName("com.mysql.cj.jdbc.Driver");
Driver driver = (Driver) aClass.getDeclaredConstructor().newInstance();
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
String user = "root";
String password = "123456";
// 注册Driver驱动
DriverManager.registerDriver(driver);
//连接
Connection connection = DriverManager.getConnection(url,user,password);
System.out.println("方式三 "+connection);
}
@Test
//方式四:使用Class.forName() 自动完成注册驱动,简化代码,使用较多
public void connect04() throws ClassNotFoundException, SQLException {
//加载Driver时,完成了驱动注册
/* mysql驱动5.1.6 以上可以无需Class.forName("com.mysql.cj.jdbc.Driver");
* 从jdk1.5以后使用了jdbc4,不再需要显式调用class.forName()注册驱动而是自动调用驱动jar包下META_INF\services\java.sql.Driver文本中的类名去注册
* 建议还是写上,更加明确
*/
Class.forName("com.mysql.cj.jdbc.Driver");
/* com.mysql.cj.jdbc.Driver 内的 静态代码块源码
* 在类加载时,静态代码块就被加载了
* static {
* try {
* DriverManager.registerDriver(new Driver());
* } catch (SQLException var1) {
* throw new RuntimeException("Can't register driver!");
* }
* }
*/
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
String user = "root";
String password = "123456";
Connection connection = DriverManager.getConnection(url,user,password);
System.out.println("方式四 "+connection);
}
@Test
// 方式五:在方式四的基础上改进,创建一个properties文件进行配置,通过取properties文件内的数据来进行
public void connect05() throws ClassNotFoundException, SQLException, IOException {
// 通过Properties 获取配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src\\mysql.properties"));
String url = properties.getProperty("url");
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
Class.forName(driver);
Connection connection = DriverManager.getConnection(url,user,password);
System.out.println("方式五 "+connection);
}
}
// src\mysql.properties
// user=root
// password=123456
// url=jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai
// driver=com.mysql.cj.jdbc.Driver
3. ResultSet 底层
package ResultSet;
import java.sql.*;
public class ResultSet1 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
String user = "root";
String password = "123456";
Connection connection = DriverManager.getConnection(url, user, password);
Statement statement = connection.createStatement();
String sql = "SELECT * FROM actor";
// 当前resultSet指向表头 -- id name sex date,而非指向第一行记录
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()){
int id = resultSet.getInt(1);
String name = resultSet.getString(2);
String sex = resultSet.getString(3);
Date date = resultSet.getDate(4);
System.out.println(id +"\t"+name+"\t"+sex + "\t"+date);
}
// 1 周星驰 男 1970-11-11
// 2 刘德华 男 1990-12-12
// 3 Tom 男 1990-01-30
resultSet.close();
statement.close();
connection.close();
}
}
4. Statement
# Statement 用于执行SQL语句并返回其生成得结果的对象
# 实际开发中不使用Statement

-- 查找某个管理员是否存在
SELECT
*
FROM
admin
WHERE
`name` = 'tom'
AND pwd = 123;
-- 同样的问题,SQL注入
-- 输入用户名为 1' OR
-- 输入密码(万能密码)为 OR '1' = '1
-- 就会变成如下
SELECT
*
FROM
admin
WHERE
`name` = '1'
OR ' AND pwd = '
OR '1' = '1';
-- 这样一定会查询出结果
SQL注入,演示
package Statement;
import java.sql.*;
import java.util.Scanner;
/**
* 演示Statement 注入问题
*/
public class Statement01 {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
String admin_name;
String admin_pwd;
Scanner scanner = new Scanner(System.in);
System.out.print("请输入name:");
admin_name = scanner.nextLine(); // 如果希望看到SQL注入,则使用nextLine(),因为next()遇到空格或单引号会分隔输入
System.out.print("请输入pwd:");
admin_pwd = scanner.nextLine();
Class.forName("com.mysql.cj.jdbc.Driver");
String user = "root";
String password = "990226";
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Connection connection = DriverManager.getConnection(url,user,password);
Statement statement = connection.createStatement();
String sql = "SELECT `name`,pwd from admin where `name` = '"+ admin_name + "' and pwd='"+admin_pwd+ "';";
ResultSet resultSet = statement.executeQuery(sql);
if (resultSet.next()){
System.out.println("登录成功");
}else {
System.out.println("登录失败");
}
resultSet.close();
statement.close();
connection.close();
// output
// 请输入name:1' OR
// 请输入pwd:OR '1' = '1
// 登录成功
// 进程已结束,退出代码0
}
}
5. PrepareStatement
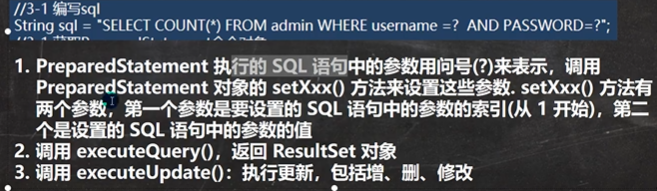
预处理好处

package ParperStatement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Scanner;
public class PrepareStatement01 {
public static void main(String[] args) throws Exception{
String user = "root";
String password = "990226";
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection(url,user,password);
String admin_name;
String admin_pwd;
Scanner scanner = new Scanner(System.in);
System.out.print("输入name:");
admin_name = scanner.nextLine();
System.out.print("输入pwd:");
admin_pwd = scanner.nextLine();
// sql 中的 ? 相当于 占位符
String sql = "select * from `admin` where `name` = ? and pwd = ?";
// 实际上,preparedStatement 是实现了 PreparedStatement接口 的一个对象,这里是mysql,不同数据库厂商有不同的实现对象
PreparedStatement preparedStatement = conn.prepareStatement(sql);
//给 ? 赋值,第一个?就是1,第二个?就是2,以此类推
preparedStatement.setString(1, admin_name);
preparedStatement.setString(2, admin_pwd);
ResultSet resultSet = preparedStatement.executeQuery(); // 这里就不用再在括号里写sql了
if (resultSet.next()) {
System.out.println("登录成功");
}else {
System.out.println("登录失败");
}
resultSet.close();
preparedStatement.close();
conn.close();
//output
// 输入name:1' OR
// 输入pwd:OR '1' = '1
// 登录失败
//
// 进程已结束,退出代码0
}
}
使用dml语句
package ParperStatement;
import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.Scanner;
public class PrepareStatement02 {
public static void main(String[] args) {
}
@Test
//添加
public static void Add() throws Exception{
String user = "root";
String password = "990226";
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection(url,user,password);
String admin_name;
String admin_pwd;
Scanner scanner = new Scanner(System.in);
System.out.print("输入添加的name:");
admin_name = scanner.nextLine();
System.out.print("输入添加的pwd:");
admin_pwd = scanner.nextLine();
String sql = "insert into admin values (?,?);";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
preparedStatement.setString(1, admin_name);
preparedStatement.setString(2, admin_pwd);
int rows = preparedStatement.executeUpdate();
if (rows > 0) {
System.out.println("添加成功");
}else {
System.out.println("添加失败");
}
preparedStatement.close();
conn.close();
}
@Test
// 修改
public static void Modify() throws Exception{
String user = "root";
String password = "990226";
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection(url,user,password);
String admin_name;
String admin_name2;
Scanner scanner = new Scanner(System.in);
System.out.print("输入修改前的name:");
admin_name = scanner.nextLine();
System.out.print("输入修改后的name:");
admin_name2 = scanner.nextLine();
String sql = "update admin set `name` = ? where `name` = ?;";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
preparedStatement.setString(1, admin_name2);
preparedStatement.setString(2, admin_name);
int rows = preparedStatement.executeUpdate();
if (rows > 0) {
System.out.println("修改成功");
}else {
System.out.println("修改失败");
}
preparedStatement.close();
conn.close();
}
@Test
// 删除
public static void Del() throws Exception {
String user = "root";
String password = "990226";
String url = "jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai";
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection(url,user,password);
Scanner scanner = new Scanner(System.in);
String del_name;
String del_pwd;
String sql = "delete from admin where `name` =? and pwd = ?;";
System.out.print("输入要删除的name:");
del_name = scanner.nextLine();
System.out.print("输入要删除name的pwd:");
del_pwd = scanner.nextLine();
PreparedStatement preparedStatement = conn.prepareStatement(sql);
preparedStatement.setString(1, del_name);
preparedStatement.setString(2, del_pwd);
int rows = preparedStatement.executeUpdate();
if (rows > 0) {
System.out.println("删除成功");
}else{
System.out.println("删除失败");
}
preparedStatement.close();
conn.close();
}
}
6. JDBC API复习

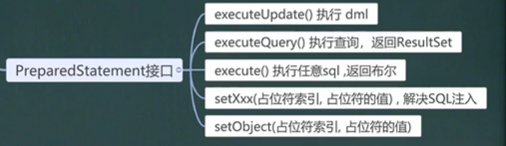

7. 封装 JDBCUtils
# 说明
# 在jdbc操作中,获取连接 和 释放资源是经常使用到的,故可以将其封装
// JDBCUtils.java
package JDBCUtils;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.*;
import java.util.Properties;
/**
* 这是一个工具类,完成MySQL的连接和关闭
*/
public class JDBCUtils {
//定义相关的属性(4个),因为只需要一份,因此使用静态static
private static String user;//用户名
private static String pwd;//密码
private static String url;//url
private static String driver;//驱动名
//在static代码块初始化
static {
Properties props = new Properties();
try {
props.load(new FileInputStream("src\\mysql.properties"));
user = props.getProperty("user");
pwd = props.getProperty("password");
url = props.getProperty("url");
driver = props.getProperty("driver");
} catch (IOException e) {
//在实际开发中可以如下处理
// 1.将编译异常转成运行异常
// 2.这时调用者可以选择捕获该异常,也可以选择默认处理该异常,比较方便
throw new RuntimeException(e);
}
}
//连接数据库,返回Connection
public static Connection getConnection(){
try {
return DriverManager.getConnection(url,user,pwd);
} catch (SQLException e) {
// 1.将编译异常转成运行异常
// 2.这时调用者可以选择捕获该异常,也可以选择默认处理该异常,比较方便
throw new RuntimeException(e);
}
}
// 关闭相关资源
/*
* 1.ResultSet 结果集
* 2.Statement 或者 PreparedStatement
* 3.Connection
* 4.如果需要关闭资源,就传入对象,否则传入null
*/
public static void close(ResultSet set, Statement statement,Connection connection){
//判断是否为空
try {
if(set != null){
set.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
// useJDBCUtils.java
package JDBCUtils;
import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 演示使用JDBCUtils工具类
*/
public class useJDBCUtils {
public static void main(String[] args) {
}
@Test
public void testDML(){
String sql = "update actor set name = ? where id = ?;";
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1, "哈哈哈");
preparedStatement.setInt(2, 3);
preparedStatement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.close(null,preparedStatement,connection);
}
}
@Test
public void testSelect(){
String sql ="select * from actor;";
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String sex = resultSet.getString("sex");
Date born_date = resultSet.getDate("borndate");
String phone = resultSet.getString("phone");
System.out.println(id + "\t" + name + "\t" + sex + "\t" + born_date + "\t" + phone);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.close(resultSet, preparedStatement, connection);
}
}
}
8. JDBC 控制事务

用银行转账问题来展示
未处理时account表的数据
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 马云 | 3000 |
| 2 | 马化腾 | 5000 |
+----+--------+---------+
2 rows in set (0.00 sec)
没有使用 事务 进行处理,可能会发生错误
@Test
//用非事务处理转账问题
public void noTransaction(){
String sql ="update account set balance = balance - 100 where id = 1;";
String sql2 = "update account set balance = balance + 100 where id = 2;";
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql); // 默认情况下,connection是默认自动 commit
preparedStatement.executeUpdate();
int i = 1 / 0; //故意抛出异常,使得下面的代码不能执行
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.close(null, preparedStatement, connection);
}
}
结果如下:一方转出100,但另一方并未收到转账的100
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 马云 | 2900 |
| 2 | 马化腾 | 5000 |
+----+--------+---------+
2 rows in set (0.00 sec)
使用 事务 解决该问题(仍然接着上面的数据)
@Test
// 使用 事务 进行解决
public void useTransaction(){
String sql ="update account set balance = balance - 100 where id = 1;";
String sql2 = "update account set balance = balance + 100 where id = 2;";
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = JDBCUtils.getConnection();
connection.setAutoCommit(false); // 将事务自动提交设置为 false
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();
// int i = 1 / 0; //故意抛出异常,使得下面的代码不能执行
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();
//提交事务
connection.commit();
} catch (Exception e) { //注意这里捕获的异常 范围大一些
// 回滚 即 撤销执行的SQL
// 默认回滚到 事务开始时的状态
// 还有一种是 rollback(savePoint),回滚到保存点
System.out.println("发生了异常,回滚到初始时期");
try {
connection.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
e.printStackTrace();
} finally {
JDBCUtils.close(null, preparedStatement, connection);
}
}
结果
mysql> select * from account;
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 马云 | 2800 |
| 2 | 马化腾 | 5100 |
+----+--------+---------+
2 rows in set (0.00 sec)
9. 批处理

package Batch;
import JDBCUtils.JDBCUtils;
import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.PreparedStatement;
/**
* 演示批处理
*/
public class Batch01 {
@Test
// 传统方法
public void noBatch() throws Exception {
Connection connection = JDBCUtils.getConnection();
String sql = "insert into admin2 values (null,?,?);";
PreparedStatement preparedStatement= connection.prepareStatement(sql);
System.out.println("开始执行");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1, "jack"+i);
preparedStatement.setString(2, "999");
preparedStatement.executeUpdate();
}
System.out.println("结束执行");
long end = System.currentTimeMillis();
System.out.println("传统方法耗时:"+(end-start));
// 开始执行
// 结束执行
// 传统方法耗时:47755
JDBCUtils.close(null,preparedStatement,connection);
}
@Test
// 批处理
// 批处理时 url 要加 rewriteBatchedStatements=true
// url写多个设置时用 & 隔开
// 如:url=jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
public void Batch() throws Exception{
Connection connection = JDBCUtils.getConnection();
String sql = "insert into admin2 values (null,?,?)"; //批处理时,这里sql语句不要加';'
PreparedStatement preparedStatement= connection.prepareStatement(sql);
System.out.println("开始执行");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1, "jack"+i);
preparedStatement.setString(2, "999");
// 将 sql语句加入到批处理包中 -->看源码
preparedStatement.addBatch();
// 当有1000条记录时,再批量执行
if((i+1)%1000 == 0){ //满1000条sql语句
preparedStatement.executeBatch();
//清空一把
preparedStatement.clearBatch();
}
}
System.out.println("结束执行");
long end = System.currentTimeMillis();
System.out.println("批量方法耗时:"+(end-start));
// 开始执行
// 结束执行
// 批量方法耗时:280
JDBCUtils.close(null,preparedStatement,connection);
}
}
10. 数据库连接池
传统方式



10.1 C3P0
package useC3P0;
import JDBCUtils.JDBCUtils;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.junit.jupiter.api.Test;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
public class useC3P01 {
@Test
public void noC3P0(){
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = JDBCUtils.getConnection();
JDBCUtils.close(null,null,connection);
}
long end = System.currentTimeMillis();
System.out.println("传统方式:"+ (end - start));
// 传统方式:62123
}
@Test
public void useC3P0() throws Exception {
//1.创建一个数据源对象
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//2.通过配置文件获取相关信息
Properties properties = new Properties();
properties.load(new FileInputStream("src\\mysql.properties"));
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String url = properties.getProperty("url");
String driver = properties.getProperty("driver");
//3.给数据源 comboPooledDataSource 配置相关信息
// 注意:连接管理是由 comboPooledDataSource 来管理
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
// 设置初始化连接数,根据项目调整
comboPooledDataSource.setInitialPoolSize(10);
// 设置最大连接数
comboPooledDataSource.setMaxPoolSize(50);
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = comboPooledDataSource.getConnection(); // 该 方法就是从 DataSource 接口实现的
connection.close();
}
long end = System.currentTimeMillis();
System.out.println("C3P0 方式:"+(end - start));
// C3P0 方式:618
}
@Test
/*
* 使用c3p0-config.xml配置文件使用c3p0
*/
public void useC3P0_properties() throws Exception {
ComboPooledDataSource mysql_c3p0 = new ComboPooledDataSource("mysql_c3p0");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = mysql_c3p0.getConnection();
connection.close();
}
long end = System.currentTimeMillis();
System.out.println("使用xml配置文件方法:"+(end - start));
// 使用xml配置文件方法:1285
}
}
// c3p0-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<named-config name="mysql_c3p0">
<!-- 配置数据库用户名 -->
<property name="user">root</property>
<!-- 配置数据库密码 -->
<property name="password">123456</property>
<!-- 配置数据库链接地址 -->
<property name="jdbcUrl">jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai</property>
<!-- 配置数据库驱动 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<!-- 数据库连接池一次性向数据库要多少个连接对象 -->
<property name="acquireIncrement">20</property>
<!-- 初始化连接数 -->
<property name="initialPoolSize">10</property>
<!-- 最小连接数 -->
<property name="minPoolSize">5</property>
<!--连接池中保留的最大连接数。Default: 15 -->
<property name="maxPoolSize">30</property>
<!--JDBC的标准参数,用以控制数据源内加载的PreparedStatements数量。但由于预缓存的statements 属于单个connection而不是整个连接池。所以设置这个参数需要考虑到多方面的因素。如果maxStatements与maxStatementsPerConnection均为0,则缓存被关闭。Default:0 -->
<property name="maxStatements">0</property>
<!--maxStatementsPerConnection定义了连接池内单个连接所拥有的最大缓存statements数。Default: 0 -->
<property name="maxStatementsPerConnection">0</property>
<!--c3p0是异步操作的,缓慢的JDBC操作通过帮助进程完成。扩展这些操作可以有效的提升性能 通过多线程实现多个操作同时被执行。Default:3 -->
<property name="numHelperThreads">3</property>
<!--用户修改系统配置参数执行前最多等待300秒。Default: 300 -->
<property name="propertyCycle">3</property>
<!-- 获取连接超时设置 默认是一直等待单位毫秒 -->
<property name="checkoutTimeout">1000</property>
<!--每多少秒检查所有连接池中的空闲连接。Default: 0 -->
<property name="idleConnectionTestPeriod">3</property>
<!--最大空闲时间,多少秒内未使用则连接被丢弃。若为0则永不丢弃。Default: 0 -->
<property name="maxIdleTime">10</property>
<!--配置连接的生存时间,超过这个时间的连接将由连接池自动断开丢弃掉。当然正在使用的连接不会马上断开,而是等待它close再断开。配置为0的时候则不会对连接的生存时间进行限制。 -->
<property name="maxIdleTimeExcessConnections">5</property>
<!--两次连接中间隔时间,单位毫秒。Default: 1000 -->
<property name="acquireRetryDelay">1000</property>
<!--c3p0将建一张名为Test的空表,并使用其自带的查询语句进行测试。如果定义了这个参数那么属性preferredTestQuery将被忽略。你不能在这张Test表上进行任何操作,它将只供c3p0测试使用。Default: null -->
<property name="automaticTestTable">null</property>
<!-- 获取connection时测试是否有效 -->
<property name="testConnectionOnCheckin">true</property>
</named-config>
</c3p0-config>
10.2 Druid
package useDruid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
public class useDruid {
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.load(new FileInputStream("src\\druid.properties"));
//创建一个指定参数的数据库连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = dataSource.getConnection();
// System.out.println("连接成功");
connection.close();
}
long end = System.currentTimeMillis();
System.out.println("Druid方式 "+(end - start));//Druid方式 1119
}
}
//druid.properties
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbc_learn?serverTimezone=Asia/Shanghai&rewriteBatchedStatement=true
characterEncoding=utf-8
username=root
password=123456
initialSize=5
maxActive=10
maxWait=3000
validationQuery=SELECT 1
封装成工具类
package useDruid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class JDBCUtilsByDruid {
static DataSource ds;
static {
try {
Properties properties = new Properties();
properties.load(new FileInputStream("src\\druid.properties"));
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws Exception {
return ds.getConnection();
}
public static void close(ResultSet resultSet, Statement statement,Connection connection){
try {
if (resultSet != null) {
resultSet.close();
}
if(statement != null){
statement.close();
}
if (connection != null){
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
11. Apache
11.0 理解用途
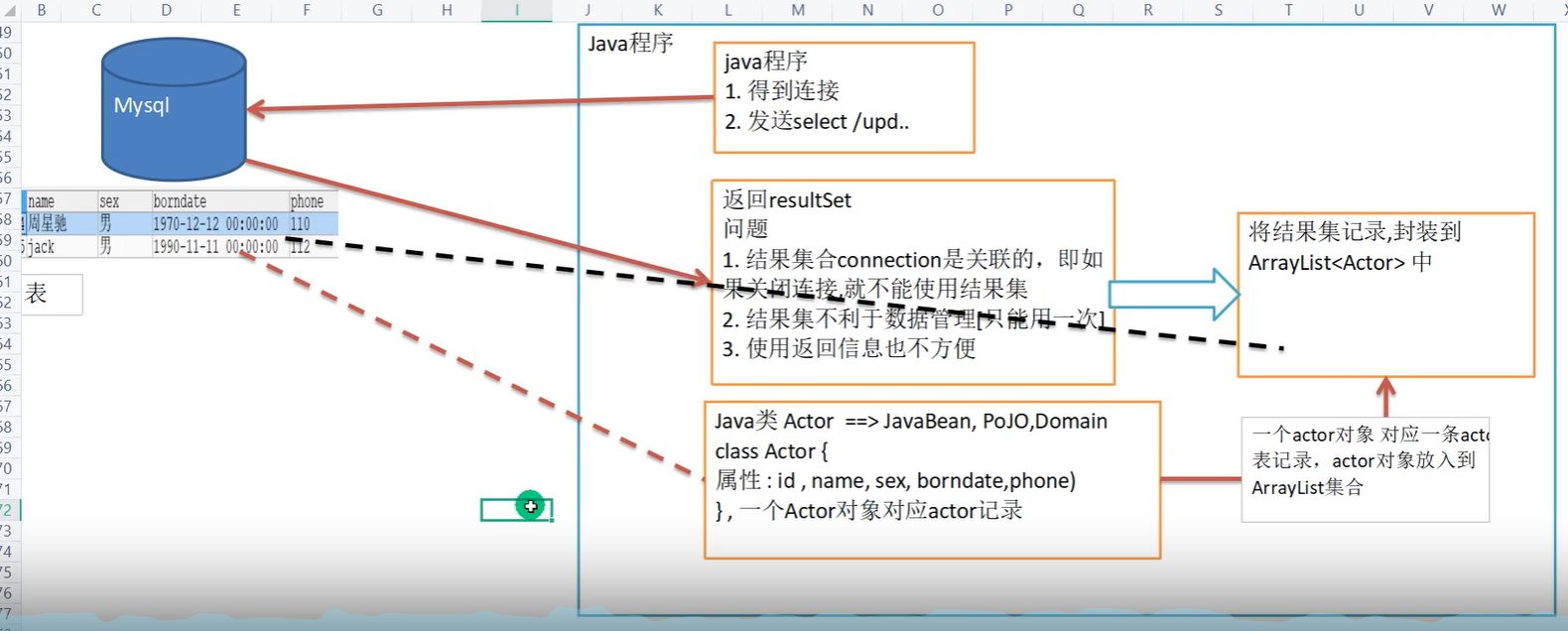
如希望使用查询到的结果集,传统方法必须保持connection的连接,但是这样就算是使用连接池技术,也是占用了资源。但是如果使用了Apache-DBUtils工具类,就可以利用其封装好的方法将结果集保存到ArrayList中,哪怕关闭了连接ArrayList内的查询结果也不会受到影响。
用基本的方法理解DBUtils工具类的做法
在Utils工具类内除了封装连接connection、PreparedStatement、和close方法外再新增一个ArrayList(List<?> list = new ArrayList();
?:代表你查询结果的类,如数据库中有个Actor表,
就可以先建一个类,类的属性均是数据库表中的字段名
// 这种类就叫做 JavaBean或者POJO或Domain
Class Actor{
private int id;
private String name;
...
无参构造函数;//必须有,涉及底层 反射机制
有参构造函数;
Set,Get方法
})
之后每次使用ResultSet rs = PreparedStatement.executeQuery()返回的结果集后,通过遍历(while(rs.next())),得到各个字段的数据(Int id = rs.getInt("id")),并利用ArrayList的add方法将查询的结果添加到list中list.add(id,name) 即可保存查询的结果集,关闭连接后仍然可以使用查询结果。
且使用该工具类,可将查询到的结果集作为函数返回值,而不是像以前,在哪个函数里查询了就得在哪里查看、使用。
以上便是简单理解Apache 的DBUtils工具类的做法,但是自己做的话代码很麻烦,且复用性较低,而Apache将各方面想的很周到,创造了DBUtils工具类,只需导入jar包即可。
//使用举例
package Apache;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.jupiter.api.Test;
import useDruid.JDBCUtilsByDruid;
import java.sql.Connection;
import java.util.List;
public class Use_DBUtils {
@Test
public void testApache() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
//sql 语句也可以查询部分字段 sql = "select `id`,`name` from `actor` where id > ?";
String sql = "select * from `actor` where id > ?";
//(1)query 方法就是执行sql语句,得到 resultSet 封装到 ArrayList 集合中
//(2)返回集合
//(3)connection:连接
//(4)sql:要执行的sql语句
//(5)new BeanListHandler<>(Actor.class):再将 resultSet 中的Actor对象 封装到ArrayList
// 底层使用反射机制,去获取Actor 类的属性,然后进行封装
//(6)1:就是给sql语句中的?赋值的,可以有多个值,因为是可变参数
//(7)底层得到的resultSet 、PreparedStatement 都会在 query中关闭
List<Actor> list = queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
System.out.println("集合信息为");
for (Actor actor : list) {
System.out.println(actor);
}
//JDBC释放资源
JDBCUtilsByDruid.close(null,null,connection);
}
}
//Actor类
package Apache;
import java.time.LocalDateTime;
public class Actor {
private Integer id;
private String name;
private String sex;
private LocalDateTime bornDate;
private String phone;
public Actor() { //一定要给,底层会用到反射机制
}
public Actor(int id, String name, String sex, LocalDateTime bornDate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.bornDate = bornDate;
this.phone = phone;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public LocalDateTime getBornDate() {
return bornDate;
}
public void setBornDate(LocalDateTime bornDate) {
this.bornDate = bornDate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "\nActor{" +
"id=" + id +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
", bornDate=" + bornDate +
", phone='" + phone + '\'' +
'}';
}
}
query源码分析
private <T> T query(Connection conn, boolean closeConn, String sql, ResultSetHandler<T> rsh, Object... params) throws SQLException {
if (conn == null) {
throw new SQLException("Null connection");
} else if (sql == null) {
if (closeConn) {
this.close(conn);
}
throw new SQLException("Null SQL statement");
} else if (rsh == null) {
if (closeConn) {
this.close(conn);
}
throw new SQLException("Null ResultSetHandler");
} else {
PreparedStatement stmt = null;
ResultSet rs = null;
Object result = null;
try {
stmt = this.prepareStatement(conn, sql);
this.fillStatement(stmt, params); // 填?参数
rs = this.wrap(stmt.executeQuery()); //这里什么都没做,就是返回executeQuery()的结果,可能是预留处理
result = rsh.handle(rs); //handle返回处理成ArrayList的结果集,handle里面就有new ArrayList和add等方法。底层使用了反射机制
} catch (SQLException var33) {
this.rethrow(var33, sql, params);
} finally {
try {
this.close(rs); //关闭resultSet
} finally {
this.close(stmt); //关闭PreparedStatement
if (closeConn) {
this.close(conn);
}
}
}
return result; //返回结果集
}
}
11.1 CRUD
返回的集合问题

11.2 JavaBean与数据库列名属性的对应关系

package Apache;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import org.junit.jupiter.api.Test;
import useDruid.JDBCUtilsByDruid;
import java.sql.Connection;
import java.util.List;
public class Use_DBUtils {
@Test
public void testApache() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
//sql 语句也可以查询部分字段 sql = "select `id`,`name` from `actor` where id > ?";
String sql = "select * from `actor` where id > ?";
//(1)query 方法就是执行sql语句,得到 resultSet 封装到 ArrayList 集合中
//(2)返回集合
//(3)connection:连接
//(4)sql:要执行的sql语句
//(5)new BeanListHandler<>(Actor.class):再将 resultSet 中的Actor对象 封装到ArrayList
// 底层使用反射机制,去获取Actor 类的属性,然后进行封装
//(6)1:就是给sql语句中的?赋值的,可以有多个值,因为是可变参数
//(7)底层得到的resultSet 、PreparedStatement 都会在 query中关闭
List<Actor> list = queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class), 1);
System.out.println("集合信息为");
for (Actor actor : list) {
System.out.println(actor);
}
//JDBC释放资源
JDBCUtilsByDruid.close(null,null,connection);
}
//apache-dbutils + druid完成返回结果为单行记录
@Test
public void testApache2() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
//返回单个对象
String sql = "select * from `actor` where id = ?";
//若不存在则返回null
Actor actor = queryRunner.query(connection, sql, new BeanHandler<>(Actor.class), 2);
System.out.println(actor);
JDBCUtilsByDruid.close(null,null,connection);
}
//apache-dbutils + druid查询结果为单行单列的结果,返回的就是Object
@Test
public void testApache3() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
//返回单个对象
String sql = "select `name` from `actor` where id = ?";
//若不存在则返回null
Object actor_name = queryRunner.query(connection, sql, new ScalarHandler("name"),2);
System.out.println(actor_name);
JDBCUtilsByDruid.close(null,null,connection);
}
//apache-dbutils + druid 进行dml
@Test
public void testApache4() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
String sql = "update `actor` set `id` = ? where `id` = ?";
//update方法不光是可以修改数据 ,删除和插入数据也可以,见testApache5()、testApache6()
int affectedRow = queryRunner.update(connection, sql, 4, 3);
if (affectedRow != 0) {
System.out.println("修改成功");
}
JDBCUtilsByDruid.close(null, null,connection);
}
@Test
public void testApache5() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
String sql = "insert into `actor` values (null,'钢铁侠2','男','1980-2-22',666);";
//update方法不光是可以修改数据 ,删除和插入数据也可以
int affectedRow = queryRunner.update(connection, sql);
if (affectedRow != 0) {
System.out.println("添加成功");
}
JDBCUtilsByDruid.close(null, null,connection);
}
@Test
public void testApache6() throws Exception {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
String sql = "delete from `actor` where `id`= 2";
//update方法不光是可以修改数据 ,删除和插入数据也可以
int affectedRow = queryRunner.update(connection, sql);
if (affectedRow != 0) {
System.out.println("删除成功");
}
JDBCUtilsByDruid.close(null, null,connection);
}
}
12. DAO

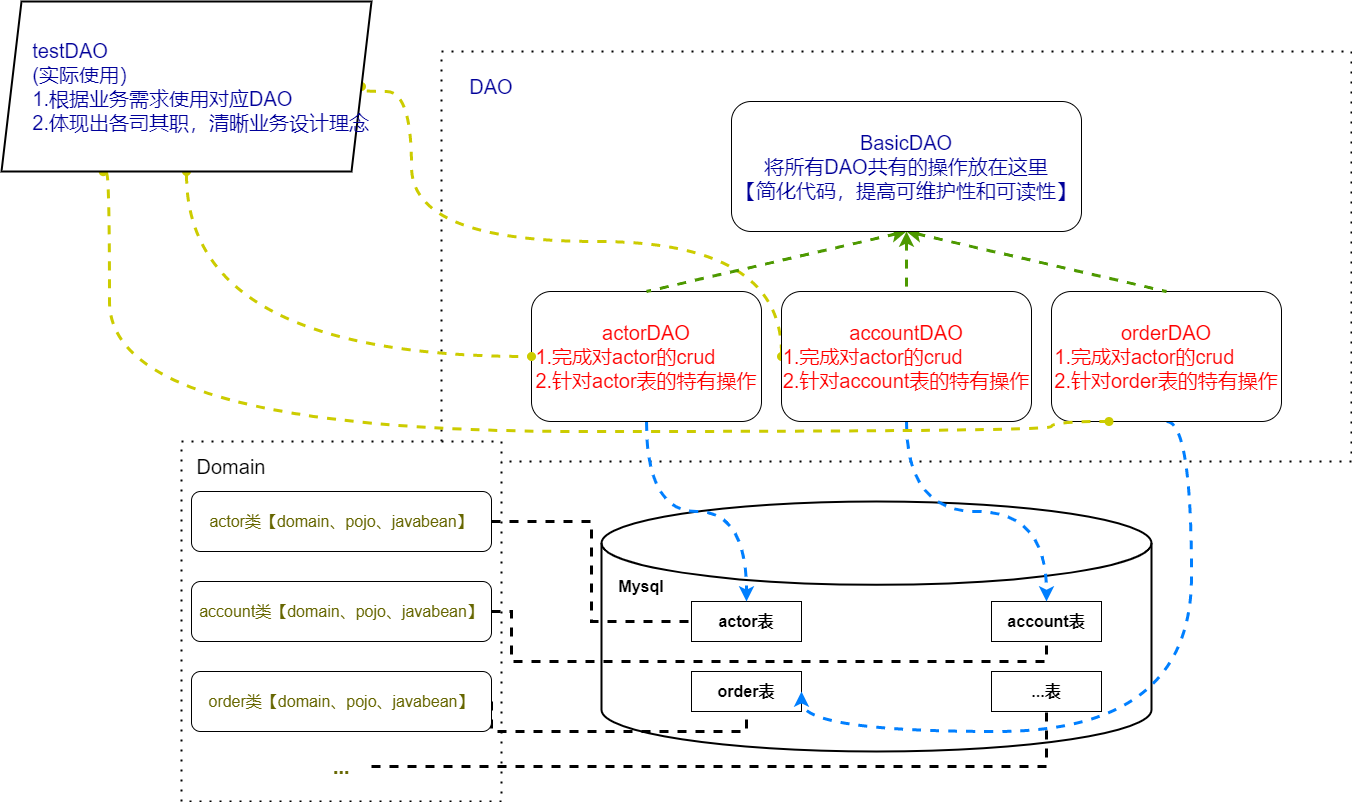
DAO:data access object 数据访问对象
BasicDAO:是专门和数据库交互的,即完成对数据库(表)的crud操作、在BasicDAO的基础上,实现一张表对应一个DAO,更好的完成功能,比如actor表-actor.java类(javabean)-actorDAO.java
演示简单使用
代码结构:
//testDAO.java
package DAO_.test;
import DAO_.dao.ActorDAO;
import DAO_.dao.GoodsDAO;
import DAO_.domain.Actor;
import DAO_.domain.Goods;
import org.junit.jupiter.api.Test;
import useDruid.JDBCUtilsByDruid;
import java.sql.Connection;
import java.util.List;
public class TestDAO {
@Test
/*
测试ActorDAO对actor表的crud
*/
public void test1(){
ActorDAO actorDAO = new ActorDAO();
List<Actor> actorList = actorDAO.queryMulti("select * from `actor` where `id` > ?", Actor.class, 0);
for (Actor actor : actorList) {
System.out.println(actor);
}
Object o = actorDAO.queryScalar("select `name` from `actor` where `id`= ?", 6);
System.out.println(o);
int affectedRow = actorDAO.update("update `actor` set `name` = '钢铁侠' where `id` = ? ",6);
if (affectedRow != 0){
o = actorDAO.queryScalar("select `name` from `actor` where `id`= ?", 6);
System.out.println(o);
}
Actor ActorOne = actorDAO.queryOne("select * from `actor` where `id` = ?", Actor.class, 6);
System.out.println(ActorOne);
}
@Test
/*
对Goods的dml操作
*/
public void test2(){
GoodsDAO goodsDAO = new GoodsDAO();
List<Goods> goodsList = goodsDAO.queryMulti("select * from `goods`", Goods.class);
for (Goods goods : goodsList) {
System.out.println(goods);
}
Goods queryOne = goodsDAO.queryOne("select * from `goods` where `id` = ?", Goods.class,30);
System.out.println(queryOne);
Object o = goodsDAO.queryScalar("select `goods_name` from goods where id = ?", 40);
System.out.println(o);
int affectedRow = goodsDAO.update("delete from `goods` where `id` = ?", 60);
if (affectedRow != 0) {
goodsList = goodsDAO.queryMulti("select * from `goods`", Goods.class);
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
}
}
//Actor.java
package DAO_.domain;
import java.time.LocalDateTime;
public class Actor {
private int id;
private String name;
private String sex;
private LocalDateTime bornDate;
private String phone;
public Actor() { //一定要给,底层会用到反射机制
}
public Actor(int id, String name, String sex, LocalDateTime bornDate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.bornDate = bornDate;
this.phone = phone;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public LocalDateTime getBornDate() {
return bornDate;
}
public void setBornDate(LocalDateTime bornDate) {
this.bornDate = bornDate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "Actor{" +
"id=" + id +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
", bornDate=" + bornDate +
", phone='" + phone + '\'' +
'}';
}
}
//BasicDAO.java
package DAO_.dao;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import useDruid.JDBCUtilsByDruid;
import java.sql.Connection;
import java.util.List;
public class BasicDAO<T> { // 泛型指定具体类型
private QueryRunner qr = new QueryRunner();
//开发通用的dml方法,针对任意表
public int update(String sql,Object... params){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
int update = qr.update(connection, sql, params);
return update;
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
/**
*返回多个对象(即查询结果有多行),针对任意表
* @param sql sql语句,可以有?
* @param clazz 传入一个人类的Class对象,比如Actor.class
* @param params 传入?的具体的值,可以是多个
* @return 根据clazz返回对应类型的ArrayList结果集
*/
public List<T> queryMulti(String sql,Class<T> clazz,Object... params){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
return qr.query(connection, sql, new BeanListHandler<T>(clazz), params);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
/**
* 返回单个对象(即查询结果仅有一行),针对任意表
* @param sql
* @param clazz
* @param params
* @return
*/
public T queryOne(String sql,Class<T> clazz,Object... params){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
return qr.query(connection, sql, new BeanHandler<T>(clazz), params);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
/**
* 返回单行单列
* @param sql
* @param params
* @return
*/
public Object queryScalar(String sql,Object ... params){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
return qr.query(connection, sql, new ScalarHandler(), params);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
}
//ActorDAO.java
package DAO_.dao;
import DAO_.domain.Actor;
/**
* 有BasicDAO里的方法
* 若有业务需求,则可以新增特有的方法
*/
public class ActorDAO extends BasicDAO<Actor>{
}
// Goods的Javabean 和 DAO 同Actor类似















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









