




 本文深入探讨了数组相关的算法问题,包括移除元素、删除重复元素、查找多数元素、求H指数、跳跃游戏、接雨水、寻找重复数、存在重复元素、存在最近的三元组等经典题目,分析了各种解决方案及其时间复杂度,涵盖了从哈希表到二分搜索、滑动窗口、二叉搜索树等多种算法思想。
本文深入探讨了数组相关的算法问题,包括移除元素、删除重复元素、查找多数元素、求H指数、跳跃游戏、接雨水、寻找重复数、存在重复元素、存在最近的三元组等经典题目,分析了各种解决方案及其时间复杂度,涵盖了从哈希表到二分搜索、滑动窗口、二叉搜索树等多种算法思想。
27. 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
给定 nums = [3,2,2,3], val = 3, 函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 你不需要考虑数组中超出新长度后面的元素。示例 2:
给定 nums = [0,1,2,2,3,0,4,2], val = 2, 函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。 注意这五个元素可为任意顺序。 你不需要考虑数组中超出新长度后面的元素。说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以**「引用」**方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 int len = removeElement(nums, val); // 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
class Solution {
public int removeElement(int[] nums, int val) {
int length = nums.length;
for(int i = 0;i<length;i++){
if(nums[i]==val){
nums[i]=nums[length-1];
i--;
length--;
}
}
return length;
}
}
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int length = nums.size();
for(int i = 0;i<length;i++){
if(nums[i] == val){
nums[i] = nums[length-1];
length--;
i--;
}
}
return length;
}
};
26. 删除排序数组中的重复项
给定一个排序数组,你需要在** 原地** 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2], 函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。 你不需要考虑数组中超出新长度后面的元素。示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4], 函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。 你不需要考虑数组中超出新长度后面的元素。
class Solution {
public int removeDuplicates(int[] nums) {
int i = 0,j= 1;
while(i<nums.length&&j<nums.length){
if(nums[i]!=nums[j]){
i++;
nums[i] = nums[j];
}
j++;
}
return i+1;
}
}
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
if(nums.empty()) return 0;
int i=0,j=1,size = nums.size();
while( i<size&& j<size){
if(nums[i] != nums[j]){
i++;
nums[i] = nums[j];
}
j++;
}
return i+1;
}
};
80. 删除排序数组中的重复项 II
难度中等252
给定一个排序数组,你需要在**原地**删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在**原地修改输入数组**并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定 nums = [1,1,1,2,2,3], 函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 你不需要考虑数组中超出新长度后面的元素。示例 2:
给定 nums = [0,0,1,1,1,1,2,3,3], 函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 你不需要考虑数组中超出新长度后面的元素。
public int removeDuplicates(int[] nums) {
int i =0,j= 1;
int n= 1;
while(i<nums.length&&j<nums.length){
if(nums[i]!=nums[j]||n!=2){
n = nums[i] == nums[j] ? 2:1;
i++;
nums[i] = nums[j];
}
j++;
}
return i+1;
}
189. 旋转数组
难度简单629
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: [1,2,3,4,5,6,7] 和 k = 3 输出: [5,6,7,1,2,3,4] 解释: 向右旋转 1 步: [7,1,2,3,4,5,6] 向右旋转 2 步: [6,7,1,2,3,4,5] 向右旋转 3 步: [5,6,7,1,2,3,4]示例 2:
输入: [-1,-100,3,99] 和 k = 2 输出: [3,99,-1,-100] 解释: 向右旋转 1 步: [99,-1,-100,3] 向右旋转 2 步: [3,99,-1,-100]说明:
- 尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
- 要求使用空间复杂度为 O(1) 的 原地 算法。
方法 1:额外数组法:
public void rotate(int[] nums, int k) {
k=k%nums.length;
int[] m = new int[k];
System.arraycopy(nums,nums.length-k,m,0,k);
System.arraycopy(nums,0,nums,k,nums.length-k);
System.arraycopy(m,0,nums,0,k);
}
方法 2:暴力循环k次法
public void rotate1(int[] nums, int k) {
k=k%nums.length;
for(int j = 0;j<k;j++){
int lastOne = nums[nums.length-1];
for(int i = nums.length-1;i>0;i++){
nums[i] = nums[i-1];
}
nums[1] = lastOne;
}
}
方法 3:使用反转
这个方法基于这个事实:当我们旋转数组 k 次, k%nk%n 个尾部元素会被移动到头部,剩下的元素会被向后移动。
在这个方法中,我们首先将所有元素反转。然后反转前 k 个元素,再反转后面 n-kn−k 个元素,就能得到想要的结果。
假设 n=7n=7 且 k=3k=3 。
原始数组 : 1 2 3 4 5 6 7
反转所有数字后 : 7 6 5 4 3 2 1
反转前 k 个数字后 : 5 6 7 4 3 2 1
反转后 n-k 个数字后 : 5 6 7 1 2 3 4 --> 结果
- Java
public class Solution {
public void rotate(int[] nums, int k) {
k %= nums.length;
reverse(nums, 0, nums.length - 1);
reverse(nums, 0, k - 1);
reverse(nums, k, nums.length - 1);
}
public void reverse(int[] nums, int start, int end) {
while (start < end) {
int temp = nums[start];
nums[start] = nums[end];
nums[end] = temp;
start++;
end--;
}
}
}
复杂度分析
- 时间复杂度:O(n)O(n) 。 nn 个元素被反转了总共 3 次。
- 空间复杂度:O(1)O(1) 。 没有使用额外的空间。
41. 缺失的第一个正数
给你一个未排序的整数数组,请你找出其中没有出现的最小的正整数。
示例 1:
输入: [1,2,0] 输出: 3示例 2:
输入: [3,4,-1,1] 输出: 2示例 3:
输入: [7,8,9,11,12] 输出: 1提示:
你的算法的时间复杂度应为O(n),并且只能使用常数级别的额外空间。
将数组视为哈希表
最早知道这个思路是在《剑指 Offe》这本书上看到的,感兴趣的朋友不妨做一下这道问题:剑指 Offer 03. 数组中重复的数字。下面简要叙述:
- 由于题目要求我们「只能使用常数级别的空间」,而要找的数一定在
[1, N + 1]左闭右闭(这里N是数组的长度)这个区间里。因此,我们可以就把原始的数组当做哈希表来使用。事实上,哈希表其实本身也是一个数组; - 我们要找的数就在
[1, N + 1]里,最后N + 1这个元素我们不用找。因为在前面的N个元素都找不到的情况下,我们才返回N + 1; - 那么,我们可以采取这样的思路:就把 1 这个数放到下标为 0 的位置, 2 这个数放到下标为 1 的位置,按照这种思路整理一遍数组。然后我们再遍历一次数组,第 1个遇到的它的值不等于下标的那个数,就是我们要找的缺失的第一个正数。
- 这个思想就相当于我们自己编写哈希函数,这个哈希函数的规则特别简单,那就是数值为
i的数映射到下标为i - 1的位置。
我们来看一下这个算法是如何应用在示例 2 上的。
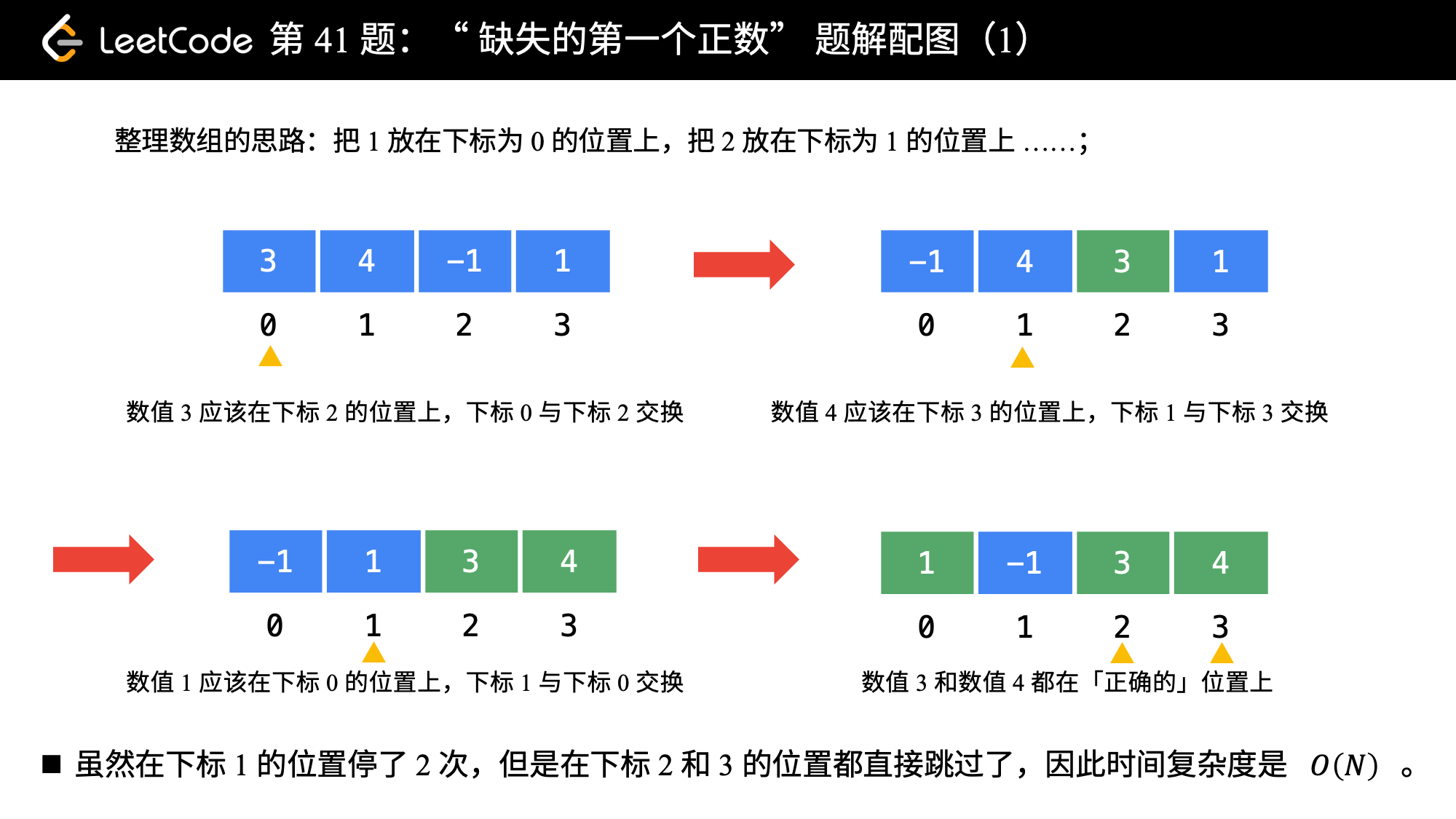
注意:理解下面代码 nums[nums[i] - 1] != nums[i] 的作用。
public class Solution {
public int firstMissingPositive(int[] nums) {
int len = nums.length;
for (int i = 0; i < len; i++) {
while (nums[i] > 0 && nums[i] <= len && nums[nums[i] - 1] != nums[i]) {
int temp = nums[nums[i] - 1];
nums[nums[i] - 1] = nums[i];
nums[i] = temp;
}
}
for (int i = 0; i < len; i++) {
if (nums[i] != i + 1) {
return i + 1;
}
}
return len + 1;
}
}
299. 猜数字游戏
难度简单82
你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下:
- 你写出一个秘密数字,并请朋友猜这个数字是多少。
- 朋友每猜测一次,你就会给他一个提示,告诉他的猜测数字中有多少位属于数字和确切位置都猜对了(称为“Bulls”, 公牛),有多少位属于数字猜对了但是位置不对(称为“Cows”, 奶牛)。
- 朋友根据提示继续猜,直到猜出秘密数字。
请写出一个根据秘密数字和朋友的猜测数返回提示的函数,返回字符串的格式为
xAyB,x和y都是数字,A表示公牛,用B表示奶牛。
xA表示有x位数字出现在秘密数字中,且位置都与秘密数字一致。yB表示有y位数字出现在秘密数字中,但位置与秘密数字不一致。请注意秘密数字和朋友的猜测数都可能含有重复数字,每位数字只能统计一次。
示例 1:
输入: secret = "1807", guess = "7810" 输出: "1A3B" 解释: 1 公牛和 3 奶牛。公牛是 8,奶牛是 0, 1 和 7。示例 2:
输入: secret = "1123", guess = "0111" 输出: "1A1B" 解释: 朋友猜测数中的第一个 1 是公牛,第二个或第三个 1 可被视为奶牛。说明: 你可以假设秘密数字和朋友的猜测数都只包含数字,并且它们的长度永远相等。
public static String getHint(String secret, String guess) {
int A =0;
int[] snums =new int[10];
int[] gnums =new int[10];
for(int i = 0;i<secret.length();i++){
if(secret.charAt(i) == guess.charAt(i))
A++;
else{
snums[secret.charAt(i)-'0'] += 1;
gnums[guess.charAt(i)-'0'] += 1;
}
}
int B = 0;
for(int i = 0;i<10;i++){
B += Math.min(snums[i],gnums[i]);
}
return A+"A"+B+"B";
}
134. 加油站
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油
gas[i]升。你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油
cost[i]升。你从其中的一个加油站出发,开始时油箱为空。如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
- 如果题目有解,该答案即为唯一答案。
- 输入数组均为非空数组,且长度相同。
- 输入数组中的元素均为非负数。
示例 1:
输入: gas = [1,2,3,4,5] cost = [3,4,5,1,2] 输出: 3 解释: 从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 因此,3 可为起始索引。示例 2:
输入: gas = [2,3,4] cost = [3,4,3] 输出: -1 解释: 你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 因此,无论怎样,你都不可能绕环路行驶一周。
一次遍历法,车能开完全程需要满足两个条件:
- 车从
i站能开到i+1。 - 所有站里的油总量要
>=车子的总耗油量。
那么,假设从编号为0站开始,一直到k站都正常,在开往k+1站时车子没油了。这时,应该将起点设置为k+1站。
问题1: 为什么应该将起始站点设为k+1?
- 因为
k->k+1站耗油太大,0->k站剩余油量都是不为负的,每减少一站,就少了一些剩余油量。所以如果从k前面的站点作为起始站,剩余油量不可能冲过k+1站。
问题2: 为什么如果k+1->end全部可以正常通行,且rest>=0就可以说明车子从k+1站点出发可以开完全程?
- 因为,起始点将当前路径分为
A、B两部分。其中,必然有(1)A部分剩余油量<0。(2)B部分剩余油量>0。 - 所以,无论多少个站,都可以抽象为两个站点(A、B)。(1)从B站加满油出发,(2)开往A站,车加油,(3)再开回B站的过程。
重点**:B剩余的油>=A缺少的总油。必然可以推出,B剩余的油>=A站点的每个子站点缺少的油。**
代码
public int canCompleteCircuit(int[] gas, int[] cost) {
int curRest = 0, sumRest = 0, start = 0;
for (int i = 0; i < gas.length; i++) {
curRest += gas[i] - cost[i];
sumRest += gas[i] - cost[i];
if (curRest < 0) {
start = i + 1;
curRest = 0;
}
}
return sumRest>=0? start:-1;
}
118. 杨辉三角
给定一个非负整数 *numRows,*生成杨辉三角的前 numRows 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
示例:
输入: 5 输出: [ [1], [1,1], [1,2,1], [1,3,3,1], [1,4,6,4,1] ]

public static List<List<Integer>> generate(int numRows) {
List<List<Integer>> res= new LinkedList<>();
if(numRows == 0) return res;
res.add(Arrays.asList(1));
if(numRows == 1) return res;
List<Integer> lastLine = new LinkedList<Integer>();
for(int i = 2; i<= numRows;i++){
List<Integer> curLine = new LinkedList<>();
curLine.add(1);
for(int j =0;j<lastLine.size()-1;j++){
curLine.add(lastLine.get(j) + lastLine.get(j + 1));
}
curLine.add(1);
res.add(curLine);
lastLine = curLine;
}
return res;
}
解法一
和 118 题 一样,我们只需要一层一层的求。但是不需要把每一层的结果都保存起来,只需要保存上一层的结果,就可以求出当前层的结果了。
public List<Integer> getRow(int rowIndex) {
List<Integer> pre = new ArrayList<>();
List<Integer> cur = new ArrayList<>();
for (int i = 0; i <= rowIndex; i++) {
cur = new ArrayList<>();
for (int j = 0; j <= i; j++) {
if (j == 0 || j == i) {
cur.add(1);
} else {
cur.add(pre.get(j - 1) + pre.get(j));
}
}
pre = cur;
}
return cur;
}
参考 这里,其实我们可以优化一下,我们可以把 pre 的 List 省去。
这样的话,cur每次不去新建 List,而是把cur当作pre。
又因为更新当前j的时候,就把之前j的信息覆盖掉了。而更新 j + 1 的时候又需要之前j的信息,所以在更新前,我们需要一个变量把之前j的信息保存起来。
public List<Integer> getRow(int rowIndex) {
int pre = 1;
List<Integer> cur = new ArrayList<>();
cur.add(1);
for (int i = 1; i <= rowIndex; i++) {
for (int j = 1; j < i; j++) {
int temp = cur.get(j);
cur.set(j, pre + cur.get(j));
pre = temp;
}
cur.add(1);
}
return cur;
}
区别在于我们用了 set 函数来修改值,由于当前层比上一层多一个元素,所以对于最后一层的元素如果用 set 方法的话会造成越界。此外,每层的第一个元素始终为1。基于这两点,我们把之前j == 0 || j == i的情况移到了for循环外进行处理。
除了上边优化的思路,还有一种想法,那就是倒着进行,这样就不会存在覆盖的情况了。
因为更新完j的信息后,虽然把j之前的信息覆盖掉了。但是下一次我们更新的是j - 1,需要的是j - 1和j - 2 的信息,j信息覆盖就不会造成影响了。
public List<Integer> getRow(int rowIndex) {
int pre = 1;
List<Integer> cur = new ArrayList<>();
cur.add(1);
for (int i = 1; i <= rowIndex; i++) {
for (int j = i - 1; j > 0; j--) {
cur.set(j, cur.get(j - 1) + cur.get(j));
}
cur.add(1);//补上每层的最后一个 1
}
return cur;
}
解法二 公式法
如果熟悉杨辉三角,应该记得杨辉三角其实可以看做由组合数构成。
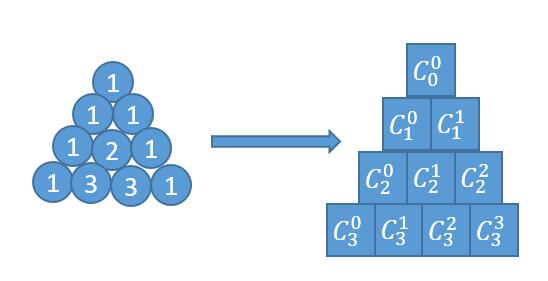
根据组合数的公式,将(n-k)!约掉,化简就是下边的结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wwgXO3e1-1627477036565)(队列.assets/image-20200725110409750.png)]
然后我们就可以利用组合数解决这道题。
public List<Integer> getRow(int rowIndex) {
List<Integer> ans = new ArrayList<>();
int N = rowIndex;
for (int k = 0; k <= N; k++) {
ans.add(Combination(N, k));
}
return ans;
}
private int Combination(int N, int k) {
long res = 1;
for (int i = 1; i <= k; i++)
res = res * (N - k + i) / i;
return (int) res;
}
参考 这里,我们可以优化一下。
上边的算法对于每个组合数我们都重新求了一遍,但事实上前后的组合数其实是有联系的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MMMk3miw-1627477036566)(队列.assets/image-20200725110429884.png)]
代码的话,我们只需要用pre变量保存上一次的组合数结果。计算过程中,可能越界,所以用到了long。
public List<Integer> getRow(int rowIndex) {
List<Integer> ans = new ArrayList<>();
int N = rowIndex;
long pre = 1;
ans.add(1);
for (int k = 1; k <= N; k++) {
long cur = pre * (N - k + 1) / k;
ans.add((int) cur);
pre = cur;
}
return ans;
}
169. 多数元素
难度简单674
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数大于
⌊ n/2 ⌋的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入: [3,2,3] 输出: 3示例 2:
输入: [2,2,1,1,1,2,2] 输出: 2
HashMap的思路
遍历整个数组,对记录每个数值出现的次数(利用HashMap,其中key为数值,value为出现次数);
接着遍历HashMap中的每个Entry,寻找value值> nums.length / 2的key即可。
class Solution {
public int majorityElement(int[] nums) {
Map<Integer, Long> map = Arrays.stream(nums).boxed().collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
long limit = nums.length >> 1;
for (Map.Entry<Integer, Long> entry : map.entrySet())
if (entry.getValue() > limit)
return entry.getKey();
return -1;
}
}
排序思路
既然数组中有出现次数> ⌊ n/2 ⌋的元素,那排好序之后的数组中,相同元素总是相邻的。
即存在长度> ⌊ n/2 ⌋的一长串 由相同元素构成的连续子数组。
举个例子:
无论是1 1 1 2 3,0 1 1 1 2还是-1 0 1 1 1,数组中间的元素总是“多数元素”,毕竟它长度> ⌊ n/2 ⌋。
class Solution {
public int majorityElement(int[] nums) {
Arrays.sort(nums);
return nums[nums.length >> 1];
}
}
摩尔投票法思路
候选人(cand_num)初始化为nums[0],票数count初始化为1。
当遇到与cand_num相同的数,则票数count = count + 1,否则票数count = count - 1。
当票数count为0时,更换候选人,并将票数count重置为1。
遍历完数组后,cand_num即为最终答案。
为何这行得通呢?
投票法是遇到相同的则票数 + 1,遇到不同的则票数 - 1。
且“多数元素”的个数> ⌊ n/2 ⌋,其余元素的个数总和<= ⌊ n/2 ⌋。
因此“多数元素”的个数 - 其余元素的个数总和 的结果 肯定 >= 1。
这就相当于每个“多数元素”和其他元素 两两相互抵消,抵消到最后肯定还剩余至少1个“多数元素”。
无论数组是1 2 1 2 1,亦或是1 2 2 1 1,总能得到正确的候选人。
class Solution {
public int majorityElement(int[] nums) {
int candidate = nums[0];
int vote = 0;
for(int each : nums){
vote = each == candidate? vote+1 : vote-1;
if(vote<0){
candidate = each;
vote = 1;
}
}
return candidate;
}
}
229. 求众数 II
给定一个大小为 n 的数组,找出其中所有出现超过
⌊ n/3 ⌋次的元素。说明: 要求算法的时间复杂度为 O(n),空间复杂度为 O(1)。
示例 1:
输入: [3,2,3] 输出: [3]示例 2:
输入: [1,1,1,3,3,2,2,2] 输出: [1,2]
写代码三步走
1、如果投A(当前元素等于A),则A的票数++;
2、如果投B(当前元素等于B),B的票数++;
3、如果A,B都不投(即当前与A,B都不相等),那么检查此时A或B的票数是否减为0,如果为0,则当前元素成为新的候选人;如果A,B两个人的票数都不为0,那么A,B两个候选人的票数均减一。
最后会有这么几种可能:有2个大于n/3,有1个大于n/3,有0个大于n/3
遍历结束后选出了两个候选人,但是这两个候选人是否满足>n/3,还需要再遍历一遍数组,找出两个候选人的具体票数,因为题目没有像169题保证一定有。
class Solution {
public List<Integer> majorityElement(int[] nums) {
List<Integer> res = new ArrayList<>();
if (nums == null || nums.length == 0) {
return res;
}
// 定义两个候选者和它们的票数
int cand1 = 0,cand2 = 0;
int cnt1 = 0, cnt2 = 0;
// 投票过程
for (int num : nums) {
// 如果是候选者1,票数++
if (num == cand1) {
cnt1++;
// 一遍遍历,如果你不想写continue,你写多个else if也可以
continue;
}
// 如果是候选者2,票数++
if (num == cand2) {
cnt2++;
continue;
}
// 既不是cand1也不是cand2,如果cnt1为0,那它就去做cand1
if (cnt1 == 0) {
cand1 = num;
cnt1++;
continue;
}
// 如果cand1的数量不为0但是cand2的数量为0,那他就去做cand2
if (cnt2 == 0) {
cand2 = num;
cnt2++;
continue;
}
// 如果cand1和cand2的数量都不为0,那就都-1
cnt1--;
cnt2--;
}
// 检查两个票数符不符合
cnt1 = cnt2 = 0;
for (int num : nums) {
if (num == cand1) {
cnt1++;
} else if (num == cand2) {
// 这里一定要用else if
// 因为可能出现[0,0,0]这种用例,导致两个cand是一样的,写两个if结果就变为[0,0]了
cnt2++;
}
}
int n = nums.length;
if (cnt1 > n / 3) {
res.add(cand1);
}
if (cnt2 > n / 3) {
res.add(cand2);
}
return res;
}
}
274. H 指数
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数 不超过 h 次。)
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
示例:
输入:citations = [3,0,6,1,5] 输出:3 解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。**提示:**如果 h 有多种可能的值,h 指数是其中最大的那个。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XEfodkuW-1627477036567)(队列.assets/image-20200726090936564.png)]
public static int hIndex(int[] citations) {
if(citations.length ==0) return 0;
Arrays.sort(citations);
int i = 0;
while (i < citations.length && citations[citations.length - 1 - i] > i) {
i++;
}
return i;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MPjQIFMe-1627477036567)(队列.assets/image-20200726091010222.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hFPLLJdk-1627477036568)(队列.assets/image-20200726091034753.png)]
public class Solution {
public int hIndex(int[] citations) {
int n = citations.length;
int[] papers = new int[n + 1];
// 计数
for (int c: citations)
papers[Math.min(n, c)]++;
// 找出最大的 k
int k = n;
for (int s = papers[n]; k > s; s += papers[k])
k--;
return k;
}
}
275. H指数 II
给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列。编写一个方法,计算出研究者的 h 指数。
h 指数的定义: “h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数不多于 h 次。)"
示例:
输入: citations = [0,1,3,5,6] 输出: 3 解释: 给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6 次。 由于研究者有 3 篇论文每篇至少被引用了 3 次,其余两篇论文每篇被引用不多于 3 次,所以她的 h 指数是 3。说明:
如果 h 有多有种可能的值 ,h 指数是其中最大的那个。
public static int hIndex(int[] citations) {
if(citations.length ==0) return 0;
int left = 0,right = citations.length;
while(left<right){
int mid = (left+right)>>>1;
if(citations[mid]<citations.length-mid )
left = mid+1;
else
right = mid;
}
return citations.length-right;
}
public static int hIndex(int[] citations) {
if(citations.length ==0) return 0;
int left = 0,right = citations.length;
while(left<right){
int mid = (left+right)>>>1;
int value = citations[mid];
int target = citations.length-mid ;
if(value < target )
left = mid+1;
else
right = mid;
}
return citations.length-right;
}
特别注意:
在二分搜素中可以采用 左闭右开,向下取整的模式,
其含义为在求mid的过程中,永远无法取到区间中最右边的元素,
判断条件是小于时value < target,需要将调整左边界调整到mid+1位置
判断条件是大于等于value >= target,需要将调整右边界调整到mid位置
使用小于,大于等于组合,向下取整,
217. 存在重复元素
给定一个整数数组,判断是否存在重复元素。
如果任意一值在数组中出现至少两次,函数返回
true。如果数组中每个元素都不相同,则返回false。示例 1:
输入: [1,2,3,1] 输出: true示例 2:
输入: [1,2,3,4] 输出: false示例 3:
输入: [1,1,1,3,3,4,3,2,4,2] 输出: true
public boolean containsDuplicate(int[] nums) {
Set<Integer> numsSet = new HashSet<>();
for(int i =0;i<nums.length;i++){
if(numsSet.contains(nums[i]))
return true;
else
numsSet.add(nums[i]);
}
return false;
}
219. 存在重复元素 II
给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的 绝对值 至多为 k。
示例 1:
输入: nums = [1,2,3,1], k = 3 输出: true示例 2:
输入: nums = [1,0,1,1], k = 1 输出: true示例 3:
输入: nums = [1,2,3,1,2,3], k = 2 输出: false
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer,Integer> numsMap = new HashMap<>();
for(int i= 0;i<nums.length;i++){
if(numsMap.containsKey(nums[i])){
if(Math.abs(numsMap.get(nums[i]) - i)<=k)
return true;
else
numsMap.put(nums[i],i);
}
numsMap.put(nums[i],i);
}
return false;
}
思路
- 标签:哈希
- 维护一个哈希表,里面始终最多包含
k个元素,当出现重复值时则说明在k距离内存在重复元素 - 每次遍历一个元素则将其加入哈希表中,如果哈希表的大小大于
k,则移除最前面的数字 - 时间复杂度:O(n)O(n),nn 为数组长度
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
HashSet<Integer> set = new HashSet<>();
for(int i = 0; i < nums.length; i++) {
if(set.contains(nums[i])) {
return true;
}
set.add(nums[i]);
if(set.size() > k) {
set.remove(nums[i - k]);
}
}
return false;
}
}
220. 存在重复元素 III
难度中等200
在整数数组
nums中,是否存在两个下标 *i* 和 *j*,使得 nums [i] 和 nums [j] 的差的绝对值小于等于 t ,且满足 *i* 和 *j* 的差的绝对值也小于等于 ķ 。如果存在则返回
true,不存在返回false。示例 1:
输入: nums = [1,2,3,1], k = 3, t = 0 输出: true示例 2:
输入: nums = [1,0,1,1], k = 1, t = 2 输出: true示例 3:
输入: nums = [1,5,9,1,5,9], k = 2, t = 3 输出: false
方法二 (二叉搜索树) 【通过】
思路
- 如果窗口中维护的元素是有序的,只需要用二分搜索检查条件二是否是满足的就可以了。
- 利用自平衡二叉搜索树,可以在对数时间内通过
插入和删除来对滑动窗口内元素排序。
算法
方法一真正的瓶颈在于检查第二个条件是否满足需要扫描滑动窗口中所有的元素。因此我们需要考虑的是有没有比全扫描更好的方法。
如果窗口内的元素是有序的,那么用两次二分搜索就可以找到 x+tx+t 和 x-tx−t 这两个边界值了。
然而不幸的是,窗口中的元素是无序的。这里有一个初学者非常容易犯的错误,那就是将滑动窗口维护成一个有序的数组。虽然在有序数组中 搜索 只需要花费对数时间,但是为了让数组保持有序,我们不得不做插入和删除的操作,而这些操作是非常不高效的。想象一下,如果你有一个kk大小的有序数组,当你插入一个新元素xx的时候。虽然可以在O(\log k)O(logk)时间内找到这个元素应该插入的位置,但最后还是需要O(k)O(k)的时间来将xx插入这个有序数组。因为必须得把当前元素应该插入的位置之后的所有元素往后移一位。当你要删除一个元素的时候也是同样的道理。在删除了下标为ii的元素之后,还需要把下标ii之后的所有元素往前移一位。因此,这种做法并不会比方法一更好。
为了能让算法的效率得到真正的提升,我们需要引入一个支持 插入,搜索,删除 操作的 动态 数据结构,那就是自平衡二叉搜索树。自平衡 这个词的意思是,这个树在随机进行插入,删除操作之后,它会自动保证树的高度最小。为什么一棵树需要自平衡呢?这是因为在二叉搜索树上的大部分操作需要花费的时间跟这颗树的高度直接相关。可以看一下下面这棵严重左偏的非平衡二叉搜索树。
6
/
5
/
4
/
3
/
2
/
1
图 1. 一个严重左偏的非平衡二叉搜索树。
在上面这棵二叉搜索树上查找一个元素需要花费 线性 时间复杂度,这跟在链表中搜索的速度是一样的。现在我们来比较一下下面这棵平衡二叉搜索树。
4
/ \
2 6
/ \ /
1 3 5
图2. 一颗平衡的二叉搜索树
假设这棵树上节点总数为 nn,一个平衡树能把高度维持在 h = \log nh=logn。因此这棵树上支持在 O(h) = O(\log n)O(h)=O(logn) 时间内完成 插入,搜索,删除 操作。
下面给出整个算法的伪代码:
- 初始化一颗空的二叉搜索树
set - 对于每个元素x,遍历整个数组
- 在
set上查找大于等于xx的最小的数,如果s - x \leq ts−x≤t则返回true - 在
set上查找小于等于xx的最大的数,如果x - g \leq tx−g≤t则返回true - 在
set中插入xx - 如果树的大小超过了kk, 则移除最早加入树的那个数。
- 在
- 返回
false
我们把大于等于 xx 的最小的数 ss 当做 xx 在 BST 中的后继节点。同样的,我们能把小于等于 xx 最大的数 gg 当做 xx 在 BST 中的前继节点。ss 和 gg 这两个数是距离 xx 最近的数。因此只需要检查它们和 xx 的距离就能知道条件二是否满足了。
- Java
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
TreeSet<Integer> set = new TreeSet<>();
for (int i = 0; i < nums.length; ++i) {
// Find the successor of current element
Integer s = set.ceiling(nums[i]);
if (s != null && s <= nums[i] + t) return true;
// Find the predecessor of current element
Integer g = set.floor(nums[i]);
if (g != null && nums[i] <= g + t) return true;
set.add(nums[i]);
if (set.size() > k) {
set.remove(nums[i - k]);
}
}
return false;
}
复杂度分析
- 时间复杂度:O(n \log (\min(n,k)))O(nlog(min(n,k)))
我们需要遍历这个 nn 长度的数组。对于每次遍历,在 BST 中搜索,插入或者删除都需要花费 O(\log \min(k, n))O(logmin(k,n)) 的时间。 - 空间复杂度:O(\min(n,k))O(min(n,k))
空间复杂度由 BST 的大小决定,其大小的上限由 kk 和 nn 共同决定。
笔记
- 当数组中的元素非常大的时候,进行数学运算可能造成溢出。所以可以考虑使用支持大数的数据类型,例如 long。
- C++ 中的
std::set,std::set::upper_bound和std::set::lower_bound分别等价于 Java 中的TreeSet,TreeSet::ceiling和TreeSet::floor。Python 标准库不提供自平衡 BST。
方法三 (桶) 【通过】
思路
受 桶排序 的启发,我们可以把 桶 当做窗口来实现一个线性复杂度的解法。
算法
桶排序是一种把元素分散到不同桶中的排序算法。接着把每个桶再独立地用不同的排序算法进行排序。桶排序的概览如下所示:
在上面的例子中,我们有 8 个未排序的整数。我们首先来创建五个桶,这五个桶分别包含 [0,9], [10,19], [20, 29], [30, 39],[40,49] 这几个区间。这 8 个元素中的任何一个元素都在一个桶里面。对于值为 x 的元素来说,它所属桶的标签为 x/w,在这里我们让 w = 10。对于每个桶我们单独用其他排序算法进行排序,最后按照桶的顺序收集所有的元素就可以得到一个有序的数组了。
回到这个问题,我们尝试去解决的最大的问题在于:
- 对于给定的元素 x 在窗口中是否有存在区间 [x-t, x+t] 内的元素?
- 我们能在常量时间内完成以上判断嘛?
我们不妨把把每个元素当做一个人的生日来考虑一下吧。假设你是班上新来的一位学生,你的生日在 三月 的某一天,你想知道班上是否有人生日跟你生日在 t=30天以内。在这里我们先假设每个月都是30天,很明显,我们只需要检查所有生日在 二月,三月,四月 的同学就可以了。
之所以能这么做的原因在于,我们知道每个人的生日都属于一个桶,我们把这个桶称作月份!每个桶所包含的区间范围都是 t,这能极大的简化我们的问题。很显然,任何不在同一个桶或相邻桶的两个元素之间的距离一定是大于 t的。
我们把上面提到的桶的思想应用到这个问题里面来,我们设计一些桶,让他们分别包含区间 …, [0,t], [t+1, 2t+1], …。我们把桶来当做窗口,于是每次我们只需要检查 xx 所属的那个桶和相邻桶中的元素就可以了。终于,我们可以在常量时间解决在窗口中搜索的问题了。
还有一件值得注意的事,这个问题和桶排序的不同之处在于每次我们的桶里只需要包含最多一个元素就可以了,因为如果任意一个桶中包含了两个元素,那么这也就是意味着这两个元素是 足够接近的 了,这时候我们就直接得到答案了。因此,我们只需使用一个标签为桶序号的散列表就可以了。
public class Solution {
// Get the ID of the bucket from element value x and bucket width w
// In Java, `-3 / 5 = 0` and but we need `-3 / 5 = -1`.
private long getID(long x, long w) {
return x < 0 ? (x + 1) / w - 1 : x / w;
}
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
if (t < 0) return false;
Map<Long, Long> d = new HashMap<>();
long w = (long)t + 1;
for (int i = 0; i < nums.length; ++i) {
long m = getID(nums[i], w);
// check if bucket m is empty, each bucket may contain at most one element
if (d.containsKey(m))
return true;
// check the nei***or buckets for almost duplicate
if (d.containsKey(m - 1) && Math.abs(nums[i] - d.get(m - 1)) < w)
return true;
if (d.containsKey(m + 1) && Math.abs(nums[i] - d.get(m + 1)) < w)
return true;
// now bucket m is empty and no almost duplicate in nei***or buckets
d.put(m, (long)nums[i]);
if (i >= k) d.remove(getID(nums[i - k], w));
}
return false;
}
}
复杂度分析
- 时间复杂度:O(n)
对于这 n 个元素中的任意一个元素来说,我们最多只需要在散列表中做三次 搜索,一次 插入 和一次 删除。这些操作是常量时间复杂度的。因此,整个算法的时间复杂度为 O(n)。
- 空间复杂度:O*(min(n,k))
需要开辟的额外空间取决了散列表的大小,其大小跟它所包含的元素数量成线性关系。散列表的大小的上限同时由 n和 k 决定。因此,空间复杂度为 O(min(n,*k))。
55. 跳跃游戏
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个位置。
示例 1:
输入: [2,3,1,1,4] 输出: true 解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。示例 2:
输入: [3,2,1,0,4] 输出: false 解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
public boolean canJump(int[] nums) {
int farStep=0;
for(int i=0;i<nums.length;i++){
if(i>farStep)
break;
farStep = Math.max(farStep,i+nums[i]);
if(farStep>=nums.length-1)
return true;
}
return false;
}
45. 跳跃游戏 II
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
示例:
输入: [2,3,1,1,4] 输出: 2 解释: 跳到最后一个位置的最小跳跃数是 2。 从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。说明:
假设你总是可以到达数组的最后一个位置。
public int jump(int[] nums) {
int curRange =0,farStep=0,count = 0,i=0;
while(i<nums.length-1){
farStep = Math.max(farStep, i + nums[i]);
if(i == curRange){
curRange = farStep;
count++;
}
i++;
}
return count;
}
特别注意:
**循环边界条件:**因为 for 循环里会更新 ans 也就是跳跃的次数,这道题题目中有确保一定会达到终点,而就算 i == end 了,如果我已经到达终点我也是不需要再跳一次的。
**初次curRange的值:**应设为0,而非nums[0].
121. 买卖股票的最佳时机
难度简单1099
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。
注意:你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4] 输出: 5 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。示例 2:
输入: [7,6,4,3,1] 输出: 0 解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
public int maxProfit(int[] prices) {
int lowPrice=Integer.MAX_VALUE;
int maxProfit = 0;
for(int i=0;i<prices.length;i++){
maxProfit = Math.max(prices[i]-lowPrice,maxProfit);
lowPrice = Math.min(prices[i], lowPrice);
}
return maxProfit;
}
注意:价格变低了,挣得钱肯定不会变多,可以减少一次判断
public int maxProfit(int prices[]) {
int minprice = Integer.MAX_VALUE;
int maxprofit = 0;
for (int i = 0; i < prices.length; i++) {
if (prices[i] < minprice)
minprice = prices[i];
else if (prices[i] - minprice > maxprofit)
maxprofit = prices[i] - minprice;
}
return maxprofit;
}
122. 买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4] 输出: 7 解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。示例 2:
输入: [1,2,3,4,5] 输出: 4 解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。示例 3:
输入: [7,6,4,3,1] 输出: 0 解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。提示:
1 <= prices.length <= 3 * 10 ^ 40 <= prices[i] <= 10 ^ 4
贪心算法
只加正数
public int maxProfit(int[] prices) {
int sumProfit = 0;
for(int i=0;i<prices.length-1;i++){
sumProfit += prices[i+1]>prices[i] ? prices[i+1]-prices[i] : 0;
}
return sumProfit;
}
123. 买卖股票的最佳时机 III
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [3,3,5,0,0,3,1,4] 输出: 6 解释: 在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。示例 2:
输入: [1,2,3,4,5] 输出: 4 解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。示例 3:
输入: [7,6,4,3,1] 输出: 0 解释: 在这个情况下, 没有交易完成, 所以最大利润为 0。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8T6R2IaP-1627477036569)(队列.assets/image-20200727185618096.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dp9rFc1l-1627477036569)(队列.assets/image-20200727200642519.png)]
阶段1,3,5可能发生的两种情况:
- 昨天没有持有股票,今天保持
f[i-1]f[j] - 昨天持有股票,今天刚买,享有今天的收益
res[i-1][j-1]+price[i-1]-price[i-2]
阶段2,4可能发生的情况:
- 昨天持有股票,今天保持收益
res[i-1][j]+price[i-1]-price[i-2] - 昨天没有股票,今天刚买,没有收益
res[i-1][j-1] - 卖出又立即买入可以等同没有卖出
最后一天手中没有股票,返回最后一天状态1、3、5中的最大值
public int maxProfit(int[] price){
int[][] res = new int[price.length+1][6];
res[0][1] = 0;
res[0][2] = res[0][3] = res[0][4] = res[0][5] = Integer.MIN_VALUE;
for(int i = 1;i<=price.length;i++){
for(int j =1;j<=5;j+=2){
res[i][j] = res[i-1][j];
if(i>1&&j>1&&res[i-1][j-1] != Integer.MIN_VALUE)
res[i][j] = Math.max(res[i][j], res[i-1][j-1]+price[i-1]-price[i-2]);
}
for(int j =2;j<=5;j+=2){
res[i][j] = res[i-1][j-1];
if(i>1&&res[i-1][j] != Integer.MIN_VALUE)
res[i][j] = Math.max(res[i-1][j]+price[i-1]-price[i-2],res[i-1][j-1]);
}
}
return Math.max(Math.max(res[price.length][1],res[price.length][3]),res[price.length][5]);
}
特别注意:
- 注意if判别条件,避免越界
- res1对应第一天,price0对应第一天
11. 盛最多水的容器
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
**说明:**你不能倾斜容器,且 n 的值至少为 2。
图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
示例:
输入:[1,8,6,2,5,4,8,3,7] 输出:49

public int maxArea(int[] height) {
int i=0,j= height.length-1;
int area = 0;
while(i<j){
area = Math.max(area,(j-i) * Math.min(height[i], height[j])) ;
if(height[i]<height[j]){
int left = height[i];
while(i+1<=j){
i++;
if(height[i]>left)
break;
}
}
else{
int right = height[j];
while(j-1>=i){
j--;
if(height[j]>right)
break;
}
}
}
return area;
}
public int maxArea(int[] height) {
int i = 0, j = height.length - 1, res = 0;
while(i < j){
res = height[i] < height[j] ?
Math.max(res, (j - i) * height[i++]):
Math.max(res, (j - i) * height[j--]);
}
return res;
}
int maxArea(vector<int>& height) {
int left = 0, right = height.size()-1;
int area = (right - left)*min(height[right],height[left]);
while(left!= right){
if(height[right]>height[left]) left++;
else right--;
int newArea= (right - left)*min(height[right],height[left]);
area = newArea >area?newArea:area;
}
return area;
}
42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dtaYApvu-1627477036571)(队列.assets/rainwatertrap.png)]
上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 感谢 Marcos 贡献此图。
示例:
输入: [0,1,0,2,1,0,1,3,2,1,2,1] 输出: 6
int trap(vector<int>& height) {
if(height.size()<3) return 0;
int res =0,part=0;
int left = 0,right=height.size()-1;
int pos;
while(left<right-1){
if(height[left]>height[right]){
pos = right -1;
while(height[pos]<height[right]&&pos!= left)
{
res += height[right]-height[pos];
pos--;
}
right = pos;
}
else{//height[left]<=height[right]
pos = left+1;
while(height[pos]<height[left]&&pos!= right){
res += height[left]-height[pos];
pos++;
}
left = pos;
}
}
return res;
}
注意:
不能两个指针都从左往右移动,因为不知道短板在左边还是右边
注意大while循环的判断条件,为了避免出错,建议一律使用范围判断,而非相等判断
334. 递增的三元子序列
难度中等200收藏分享切换为英文关注反馈
给定一个未排序的数组,判断这个数组中是否存在长度为 3 的递增子序列。
数学表达式如下:
如果存在这样的 i, j, k, 且满足 0 ≤ i < j < k ≤ n-1,
使得 arr[i] < arr[j] < arr[k] ,返回 true ; 否则返回 false 。说明: 要求算法的时间复杂度为 O(n),空间复杂度为 O(1) 。
示例 1:
输入: [1,2,3,4,5] 输出: true示例 2:
输入: [5,4,3,2,1] 输出: false
bool increasingTriplet(vector<int>& nums) {
if(nums.size()<3) return false;
int small=INT_MAX, mid=INT_MAX,pos=0;
while(pos<nums.size()){
if(nums[pos]<=small){
small = nums[pos];
}
else if(nums[pos]<=mid){
mid = nums[pos];
}
else return true;
pos++;
}
return false;
}
首先,新建两个变量 small 和 mid ,分别用来保存题目要我们求的长度为 3 的递增子序列的最小值和中间值。
接着,我们遍历数组,每遇到一个数字,我们将它和 small 和 mid 相比,若小于等于 small ,则替换 small;否则,若小于等于 mid,则替换 mid;否则,若大于 mid,则说明我们找到了长度为 3 的递增数组!
问题:当已经找到了长度为 2 的递增序列,这时又来了一个比 small 还小的数字,为什么可以直接替换 small 呢,这样 small 和 mid 在原数组中并不是按照索引递增的关系呀?
pos找到了比mid大的,mid之前至少有一个比他小的数,直接返回true
pos找到了比mid小,比small大的数,恢复递增顺序。
假如当前的 small 和 mid 为 [3, 5],这时又来了个 1。假如我们不将 small 替换为 1,那么,当下一个数字是 2,后面再接上一个 3 的时候,我们就没有办法发现这个 [1,2,3] 的递增数组了!也就是说,我们替换最小值,是为了后续能够更好地更新中间值!
128. 最长连续序列
给定一个未排序的整数数组,找出最长连续序列的长度。
要求算法的时间复杂度为 O(n)。
示例:
输入: [100, 4, 200, 1, 3, 2] 输出: 4 解释: 最长连续序列是 [1, 2, 3, 4]。它的长度为 4。
int longestConsecutive(vector<int>& nums) {
if(nums.empty())return 0;
unordered_set<int> numSet(nums.begin(),nums.end());
int maxLength=1, length=1;
for(int i:numSet){
if(!numSet.count(i-1)){
int j =i+1;
while(numSet.count(j)){
j++;
}
length = j-i;
}
maxLength = maxLength>length? maxLength:length;
}
return maxLength;
}
注意:
可以将numSet.find(i)!=numsSet.end()替换为numSet.count(i)可以提升效率
避免重复计算的方法:
- 使用set,过滤重复元素
- 如果有邻接的比他小的数,一律不计算。
仔细分析这个过程,我们会发现其中执行了很多不必要的枚举,如果已知有一个x*,x+1,x+2,⋯,x+y 的连续序列,而我们却重新从 x+1,x+2 或者是x*+y处开始尝试匹配,那么得到的结果肯定不会优于枚举 x 为起点的答案,因此我们在外层循环的时候碰到这种情况跳过即可。
那么怎么判断是否跳过呢?由于我们要枚举的数 x 一定是在数组中不存在前驱数x−1 的,不然按照上面的分析我们会从x−1 开始尝试匹配,因此我们每次在哈希表中检查是否存在x−1 即能判断是否需要跳过了。
164. 最大间距
给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。
如果数组元素个数小于 2,则返回 0。
示例 1:
输入: [3,6,9,1] 输出: 3 解释: 排序后的数组是 [1,3,6,9], 其中相邻元素 (3,6) 和 (6,9) 之间都存在最大差值 3。示例 2:
输入: [10] 输出: 0 解释: 数组元素个数小于 2,因此返回 0。说明:
- 你可以假设数组中所有元素都是非负整数,且数值在 32 位有符号整数范围内。
- 请尝试在线性时间复杂度和空间复杂度的条件下解决此问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qzd0mpjG-1627477036571)(队列.assets/image-20200907185702857.png)]
class Solution {
class Bucket{
public:
bool used = false;
int maxval = INT_MIN;
int minval = INT_MAX;
};
public:
int maximumGap(vector<int>& nums) {
if(nums.size()<2)return 0;
int maxNum = *max_element(nums.begin(),nums.end());
int minNum = *min_element(nums.begin(),nums.end());
int BucketSize = nums.size()-1;//数字个数减1个桶
int BucketRange = (maxNum - minNum)/(BucketSize-1);//BucketSize个桶,BucketSize-1个间距,计算出间距大小
//建桶
vector<Bucket> buckets(BucketSize);
//装桶
for(int i: nums){
int bucketNum = (i -minNum)/BucketRange;
buckets[bucketNum].used =true;
buckets[bucketNum].maxval = max(buckets[bucketNum].maxval,i);
buckets[bucketNum].minval = min(buckets[bucketNum].minval,i);
}
int pre = minNum,res =buckets[0].maxval-pre;//注意边界,当两个元素时
//注意pre的用法
//桶间元素比较
for(int m = 0;m<BucketSize;m++){
if(buckets[m].used){
res = max(buckets[m].minval-pre,res);
pre = buckets[m].maxval;
}
}
return res;
}
};
287. 寻找重复数
给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
示例 1:
输入: [1,3,4,2,2] 输出: 2示例 2:
输入: [3,1,3,4,2] 输出: 3说明:
- 不能更改原数组(假设数组是只读的)。
- 只能使用额外的 O(1) 的空间。
- 时间复杂度小于 O(n2) 。
- 数组中只有一个重复的数字,但它可能不止重复出现一次。
外层使用二分搜索,内层暴力搜索
只要数组中小于等于中位数m的元素个数超过了了m,就说明中位数前面(包括)有重复元素,否则在后面,减少了一半的搜索空间
int findDuplicate(vector<int>& nums) {
int begin=1,end=nums.size();
while(begin<end){
int mid = (begin+end)>>1;
int sum=0;
for(int i :nums){
if(i<=mid){
sum++;
}
}
if(sum>mid){
end = mid;
}
else{
begin = mid+1;
}
}
return begin;
}
剑指 Offer 59 - II. 队列的最大值
难度中等147收藏分享切换为英文关注反馈
请定义一个队列并实现函数
max_value得到队列里的最大值,要求函数max_value、push_back和pop_front的均摊时间复杂度都是O(1)。若队列为空,
pop_front和max_value需要返回 -1示例 1:
输入: ["MaxQueue","push_back","push_back","max_value","pop_front","max_value"] [[],[1],[2],[],[],[]] 输出: [null,null,null,2,1,2]示例 2:
输入: ["MaxQueue","pop_front","max_value"] [[],[],[]] 输出: [null,-1,-1]
为了解决上述问题,我们只需记住当前最大值出队后,队列里的下一个最大值即可。
具体方法是使用一个双端队列 deque,在每次入队时,如果 deque队尾元素小于即将入队的元素 value**,则将小于 value 的元素全部出队后,再将 value入队;否则直接入队。
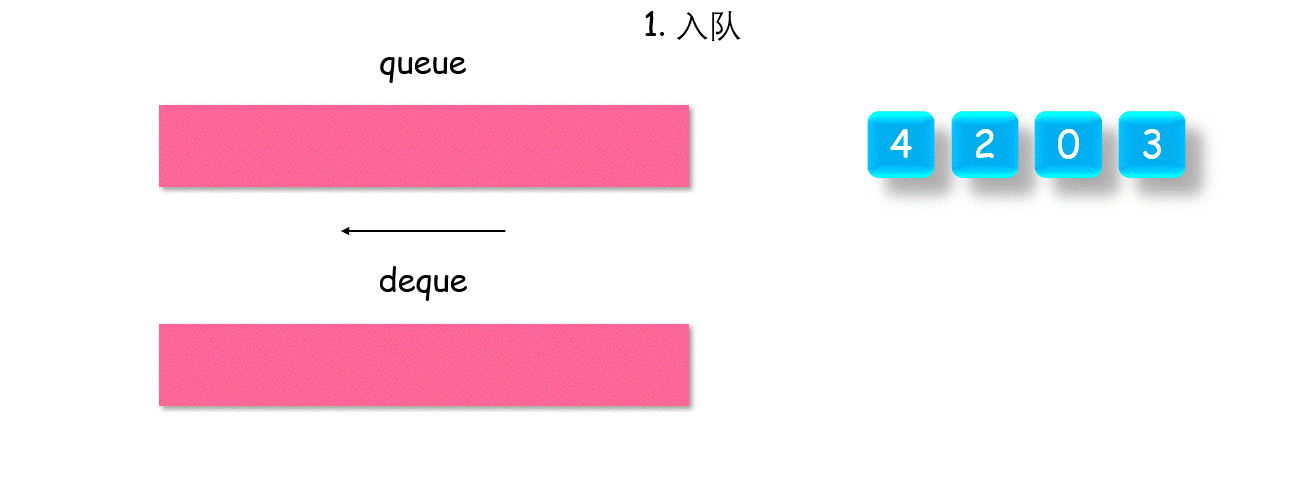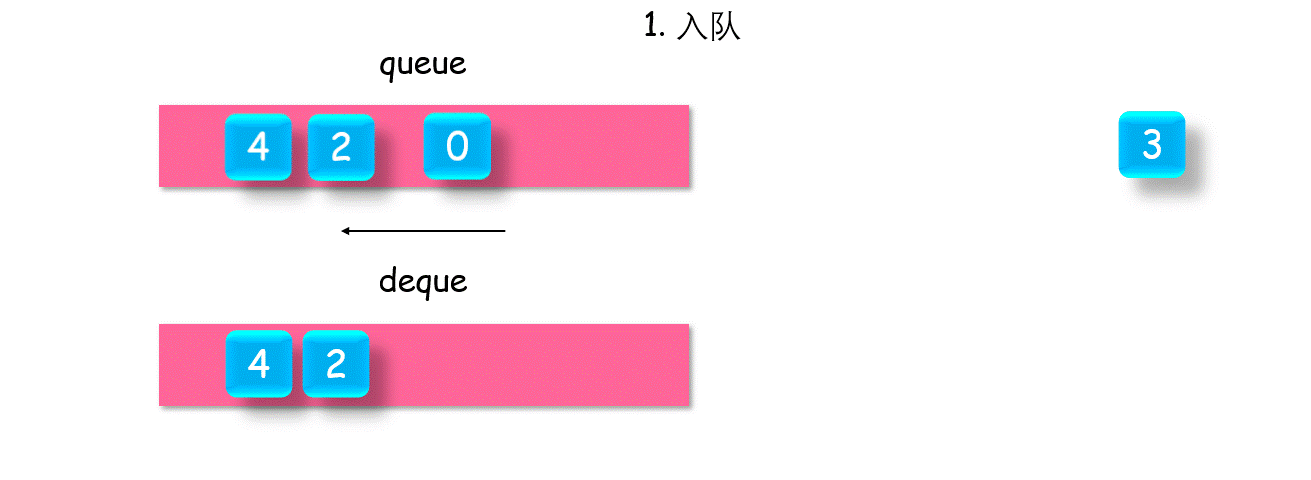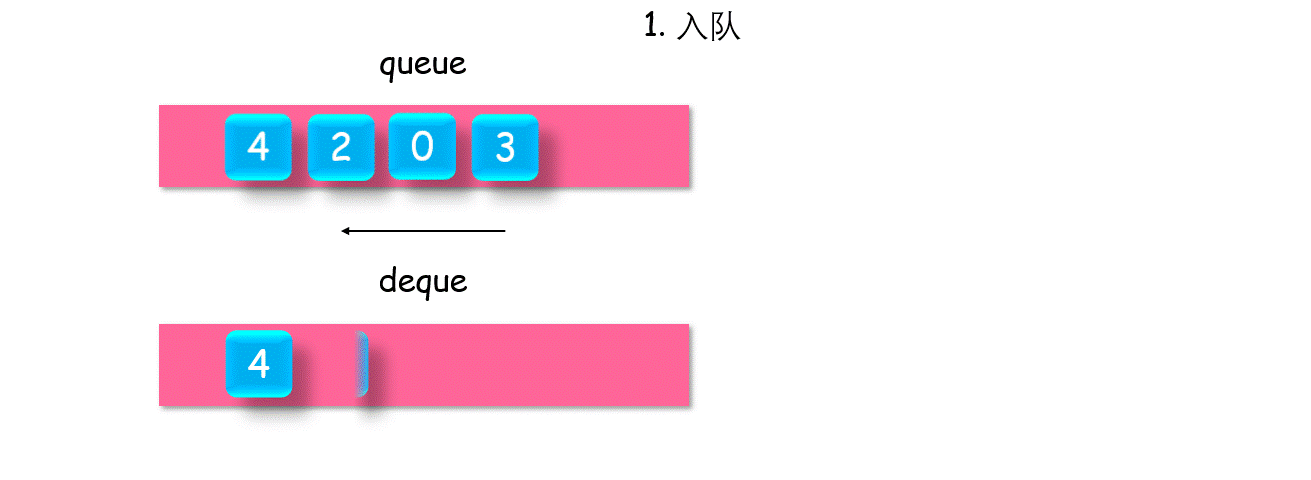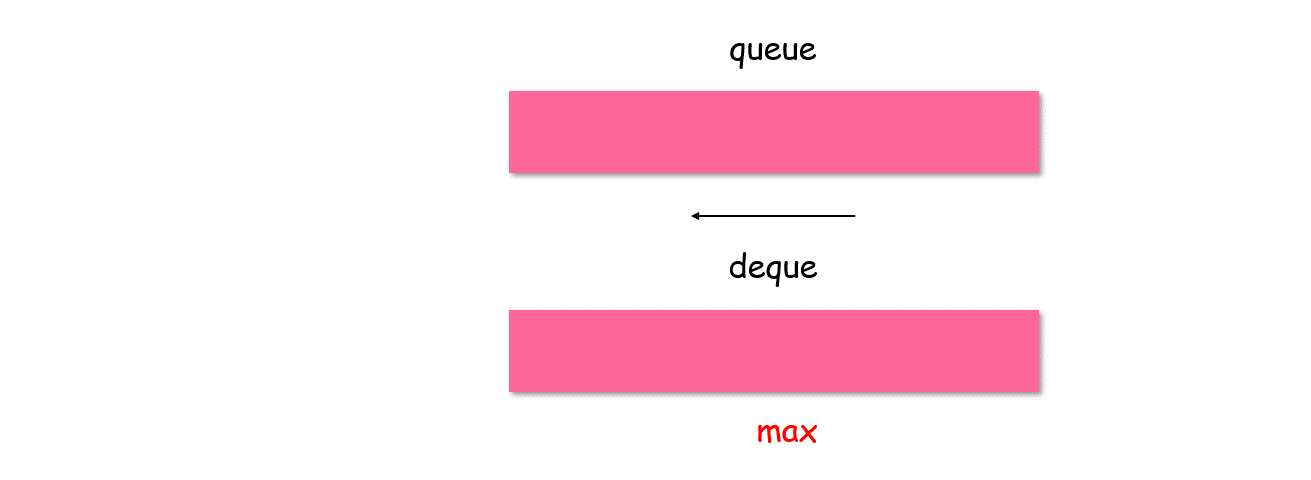
这时,辅助队列 dequedeque 队首元素就是队列的最大值。
class MaxQueue {
public:
MaxQueue() {
}
queue<int> Que;
deque<int> MaxQue;
int max_value() {
if(Que.empty()) return -1;
return MaxQue.front();
}
void push_back(int value) {
Que.push(value);
if(!MaxQue.empty()&&MaxQue.back()<value){
while(!MaxQue.empty()&&MaxQue.back()<value){
MaxQue.pop_back();
}
}
MaxQue.push_back(value);
}
int pop_front() {
if(Que.empty()) return -1;
int res = Que.front();
if(res==MaxQue.front()){
MaxQue.pop_front();
}
Que.pop();
return res;
}
};
组中小于等于中位数m的元素个数超过了了m,就说明中位数前面(包括)有重复元素,否则在后面,减少了一半的搜索空间
int findDuplicate(vector<int>& nums) {
int begin=1,end=nums.size();
while(begin<end){
int mid = (begin+end)>>1;
int sum=0;
for(int i :nums){
if(i<=mid){
sum++;
}
}
if(sum>mid){
end = mid;
}
else{
begin = mid+1;
}
}
return begin;
}
剑指 Offer 59 - II. 队列的最大值
难度中等147收藏分享切换为英文关注反馈
请定义一个队列并实现函数
max_value得到队列里的最大值,要求函数max_value、push_back和pop_front的均摊时间复杂度都是O(1)。若队列为空,
pop_front和max_value需要返回 -1示例 1:
输入: ["MaxQueue","push_back","push_back","max_value","pop_front","max_value"] [[],[1],[2],[],[],[]] 输出: [null,null,null,2,1,2]示例 2:
输入: ["MaxQueue","pop_front","max_value"] [[],[],[]] 输出: [null,-1,-1]
为了解决上述问题,我们只需记住当前最大值出队后,队列里的下一个最大值即可。
具体方法是使用一个双端队列 deque,在每次入队时,如果 deque队尾元素小于即将入队的元素 value**,则将小于 value 的元素全部出队后,再将 value入队;否则直接入队。
[外链图片转存中…(img-ooSgWjik-1627477036572)]
这时,辅助队列 dequedeque 队首元素就是队列的最大值。
class MaxQueue {
public:
MaxQueue() {
}
queue<int> Que;
deque<int> MaxQue;
int max_value() {
if(Que.empty()) return -1;
return MaxQue.front();
}
void push_back(int value) {
Que.push(value);
if(!MaxQue.empty()&&MaxQue.back()<value){
while(!MaxQue.empty()&&MaxQue.back()<value){
MaxQue.pop_back();
}
}
MaxQue.push_back(value);
}
int pop_front() {
if(Que.empty()) return -1;
int res = Que.front();
if(res==MaxQue.front()){
MaxQue.pop_front();
}
Que.pop();
return res;
}
};

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









