





SHAP 应用
shap是可视化机器学习模型的一种方法,在使用shap之前,需要训练好特定的模型,然后导入shap库
import shap
shap.initjs()#这是为了能够输出shap的图像
接着,将模型输入shap解释器中,创建一个explainer对象,利用它计算每个观察对象的SHAP值,每个特征将对应一个SHAP值。
explainer = shap.Explainer(model)
shap_values = explainer(Xtrain)
应用举例
- 瀑布图
# 为第一个观察对象创建瀑布图!
shap.plots.waterfall(shap_values[0])
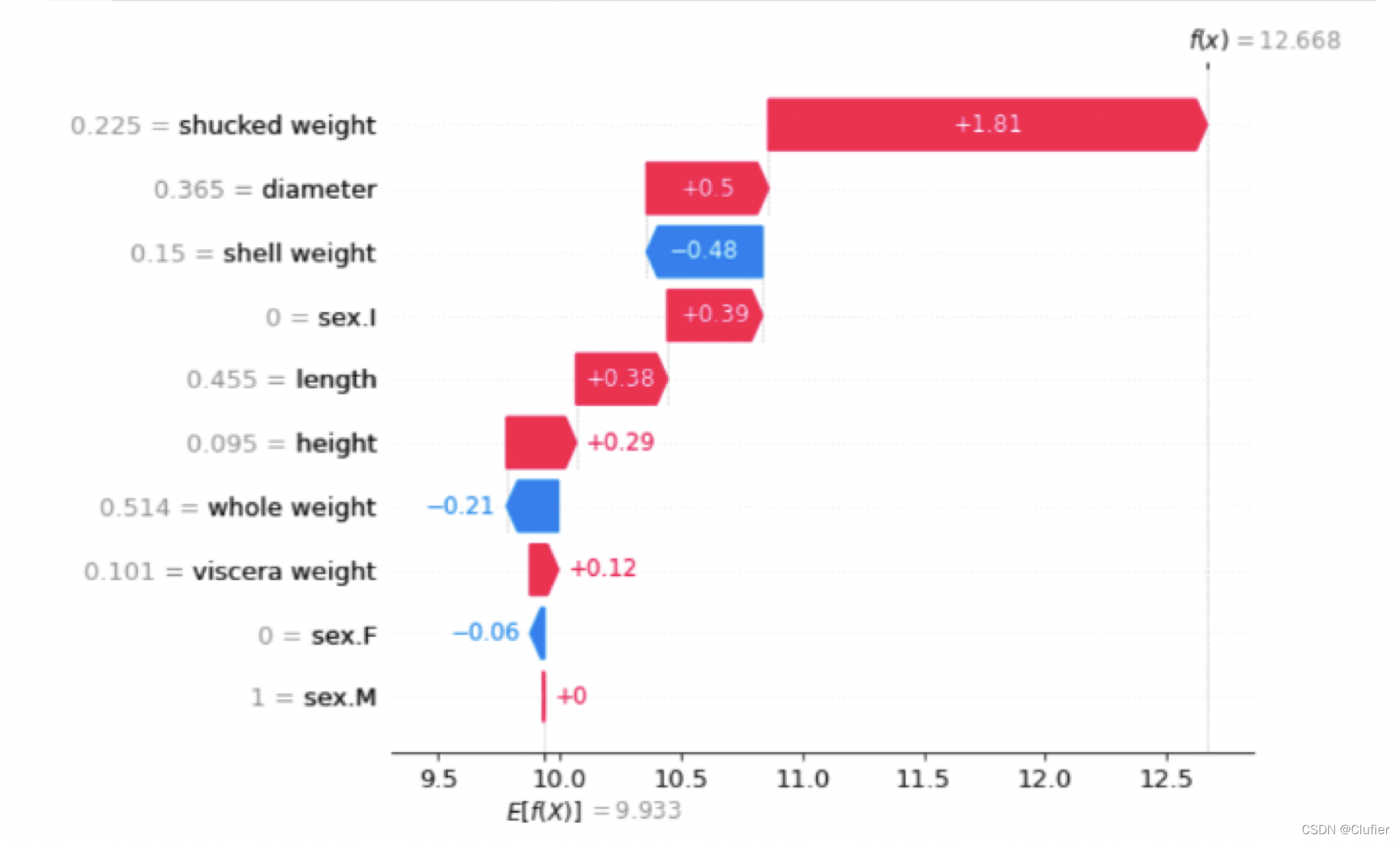
在上面这张图中,E[f(x)] = 9.933是基线值,也是平均预测值。最终值是f(x) = 12.668,也是这个对象的预测值。图中每一行代表一个特征,每一行的shap值大小代表了这个特征对于该对象总shap值的贡献。比如,shucked weight就让这个个体的预测值在基线值的基础上增加了1.81。
我们可以为每个对象生成一个瀑布图,每个图都将不一样。
2. 力图
shap.plots.force(shap_values[0])
力图展示的数据和瀑布图差不多

3. 决策图
瀑布图和力图展示的是个体水平的预测,如果要了解整体模型,我们就要将每个个体的SHAP值进行整合。
# 获取期望值和shap值数组
expected_value = explainer.expected_value
shap_array = explainer.shap_values(X)
#获取前十个对象的决策图
shap.decision_plot(expected_value, shap_array[0:10],feature_names=list(X.columns))

在这张决策图中,有十个对象,可以从图像的底端看到,每个对象的起点都是基线值9.933,当我们沿着y轴的特征值向上看的时候,观测对象们的SHAP值开始因为特征贡献的不同而发生变化,并导致最终SHAP的不同。
从这十个对象的决策图,我们可以看到一些规律,比如shucked weight和shell weight对观测对象的SHAP值似乎会产生相反的作用,从而导致图线显示出曲折。
需要注意的是,随着我们输入到决策图中对象的增加,决策图会因为图线太多而开始变得混乱,因此,我们最好限制住输入到决策图中的观测对象数量。
- 平均SHAP
平均SHAP就是对所有特征对应对象的SHAP值取绝对值后相加,下面以柱状图的形式展现。
shap.plots.bar(shap_values)

由图可见,在平均意义上,shell weight是对模型的预测具有最大影响力的一个特征。从这个意义上来讲,平均SHAP图可以视为特征重要性图。需要注意的是,上面这张图不能够告诉我们具体地,特征与模型是如何交互的。
- 蜂窝图
蜂窝图也是将所有的SHAP值进行综合展示的方法。在这种图中,左侧的标签是特征,并且它们也是按照重要性排序的,这一点上和平均SHAP图一样。不同的是,蜂窝图中的每一点都代表一个真实的样本。对于每一组(每一行)来说,数据点的颜色是由特征的值决定的。特征的值越大,点的颜色越红。相同SHAP值的点越多,那么“蜂窝”的截面积就越大,看起来就会越粗。
# Beeswarm plot
shap.plots.beeswarm(shap_values)

蜂窝图解决了前面几张图的一些弊端。它允许我们在看到特征重要性的同时,对于特征如何影响整体预测值有一个直观的判断。比如,在蜂窝图中,shell weight与预测值呈正相关关系,shucked weight则呈现负相关。
如果我们想要进一步探究一下这两个特征与模型的关系,可以绘制散点图。
fig, ax = plt.subplots(nrows=1, ncols=2,figsize=(16,8))
#SHAP scatter plots
shap.plots.scatter(shap_values[:,"shell weight"],ax=ax[0],show=False)
shap.plots.scatter(shap_values[:,"shucked weight"],ax=ax[1])

这个散点图告诉我们,shell weight与SHAP是呈现正相关的,而shucked weight则呈现负相关。在这里,预测的目标是鲍鱼(abalone)的养殖时间,shell weight是鲍鱼壳的重量,shucked weight是鲍鱼去壳的重量。
这就是说,鲍鱼的壳重量越大,那么我们可以预测它的养殖时间越长,但是它的去壳质量越大,养殖时间却是越短的。这与我们的直觉是不符合的:难道不是养殖时间越长,鲍鱼的去壳重量和壳重量都增加吗?
原因可能在于去壳质量和带壳质量这两个特征具有比较强的相关关系,它影响了算法的计算。
我们绘制同时包含这两个特征的散点图来看看,会发现,它们呈现很明显的正相关关系。

用散点图的方式展现相关关系,还是非常初级的做法,下回我们会用SHAP进行相关关系分析。

















 7598
7598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









