






2025深度学习发论文&模型涨点之——SHAP可解释性+聚类分析
传统的SHAP方法主要关注于个体样本的解释,难以揭示数据集中潜在的全局结构和模式。为了弥补这一不足,研究者们开始探索将SHAP与聚类分析相结合,以期在保持局部解释能力的同时,挖掘数据中的全局特征重要性分布和群体差异。这种结合不仅能够帮助研究者更好地理解模型的整体行为,还能为特征工程、模型优化和决策制定提供更全面的指导。
我整理了一些SHAP可解释性+聚类分析【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
Shapley-based Explainable AI for Clustering Applications in Fault Diagnosis and Prognosis
基于 Shapley 值的可解释人工智能在故障诊断和预测中的聚类应用
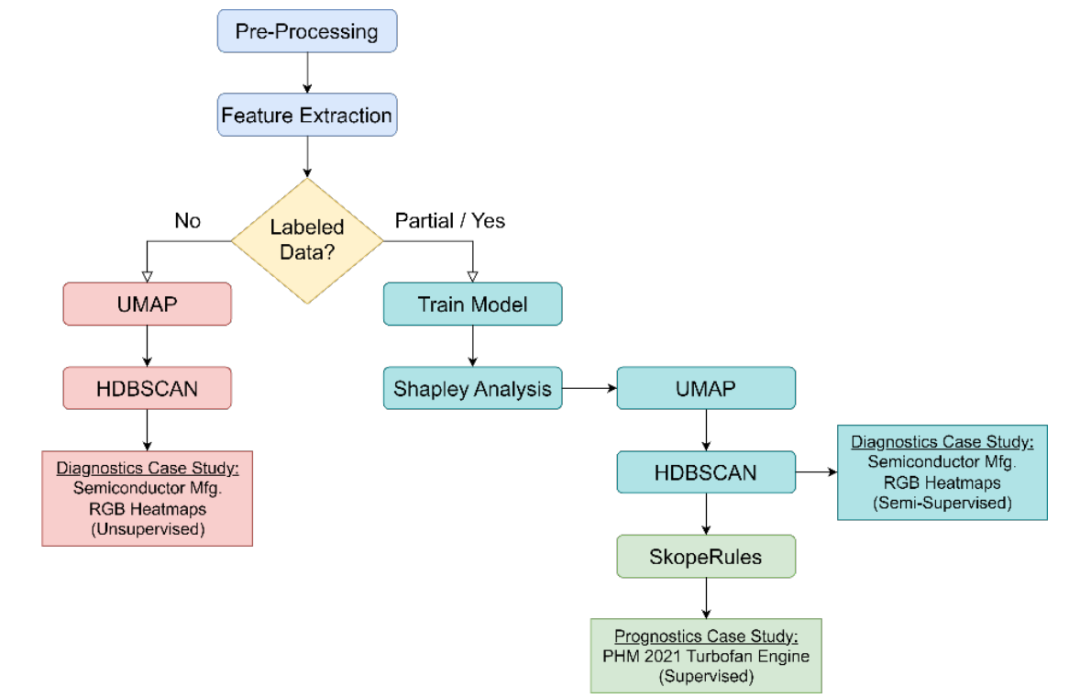
方法
Shapley 值分析:利用 SHAP 和蒙特卡洛采样方法计算 Shapley 值,以量化特征对模型预测的贡献。
UMAP 降维:使用 Uniform Manifold Approximation and Projection 技术将高维数据投影到低维嵌入空间,以便于可视化和聚类。
HDBSCAN 聚类:采用 Hierarchical Density-Based Spatial Clustering of Applications with Noise 算法进行聚类,自动确定聚类数量并排除噪声点。
SkopeRules 规则生成:利用 SkopeRules 方法生成高精度的决策规则,以描述聚类结果并提高可解释性。
创新点
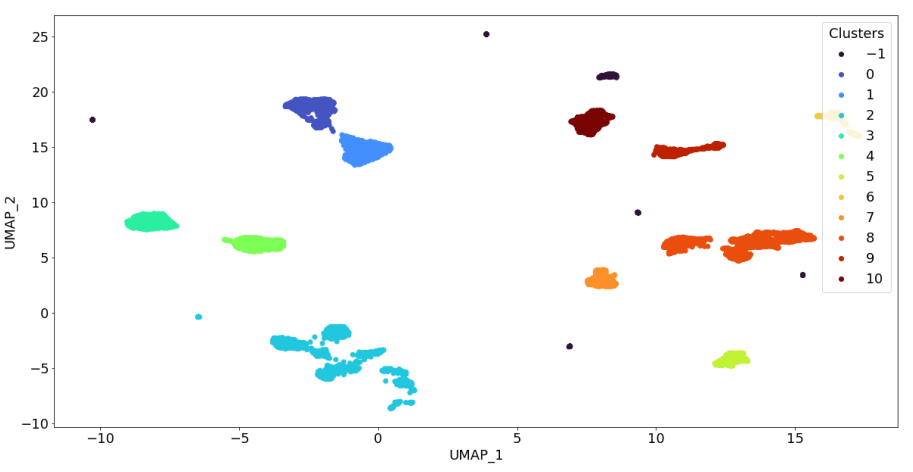
扩展 Shapley 基聚类到半监督学习:首次将 Shapley 值应用于半监督聚类框架,解决了实际工业应用中标签数据稀缺的问题。例如,在半导体制造案例中,仅使用 1.6% 的标记数据,Shapley 基解释的聚类将未聚类样本比例从 2% 降低到 0.1%。
高精度决策规则:在故障诊断和预测中,生成的决策规则具有高精度(超过 0.85),并且规则简洁(最多包含两个特征)。例如,在涡轮风扇发动机预测性维护案例中,12 个聚类规则中有 12 个的精度超过 0.85。
多案例验证:通过两个不同的工业案例(半导体制造和涡轮风扇发动机退化)验证了方法的有效性,展示了该方法在不同数据类型和应用场景中的灵活性。
论文2:
Beyond explainingXAI-based AdaptiveLearning with SHAP Clustering for EnergyConsumption Prediction
超越解释:基于XAI的自适应学习与SHAP聚类在能源消耗预测中的应用
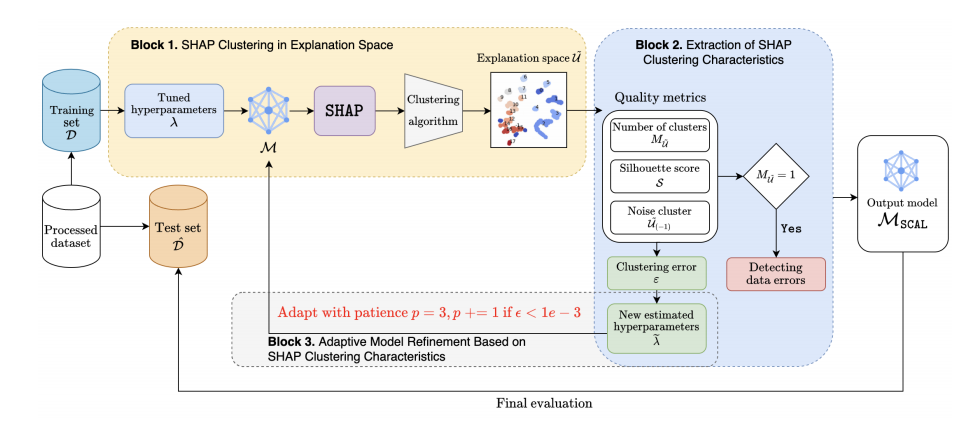
方法
SHAP聚类:利用SHAP值对模型预测进行解释,并通过DBSCAN聚类算法对SHAP值进行聚类,以识别不同的模式和异常值。
质量指标提取:通过轮廓系数、噪声聚类的存在性等指标来评估聚类的质量,并为模型优化提供依据。
模型自适应优化:根据SHAP聚类的特征,通过调整模型的超参数(如最大深度和正则化参数)来优化模型,提高其泛化能力和解释性。
创新点
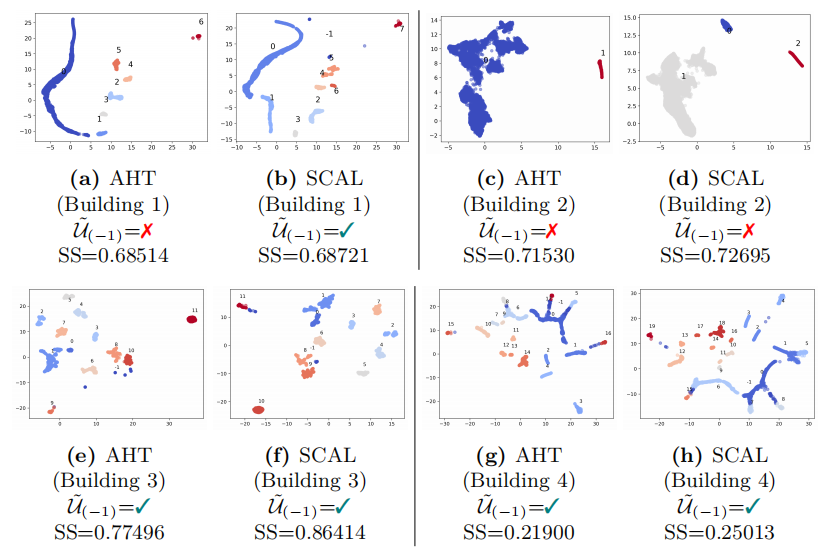
SHAP聚类的应用:首次将SHAP聚类应用于回归问题,通过聚类SHAP值识别数据中的不同模式,显著提高了模型对数据分布变化的适应性(例如在COVID-19疫情期间能源消耗模式的变化)。
模型性能提升:与传统的自动化超参数调整(AHT)方法相比,SCAL方法在测试集上的均方根误差(RMSE)降低了约10%-30%,R²值提高了约5%-15%,表明模型对未见数据的泛化能力更强。
解释空间的优化:通过SHAP聚类优化解释空间,提高了模型解释的可理解性和透明度,同时通过减少噪声聚类,进一步提升了模型的鲁棒性。
跨领域适用性:该方法不仅适用于能源消耗预测,还在金融困境预测(分类问题)和电力消耗预测(回归问题)中展示了良好的迁移性和性能提升。
论文3:
K-SHAP Policy Clustering Algorithm for Anonymous Multi-Agent State-Action Pairs
K-SHAP:匿名多智能体状态-动作对的策略聚类算法
方法
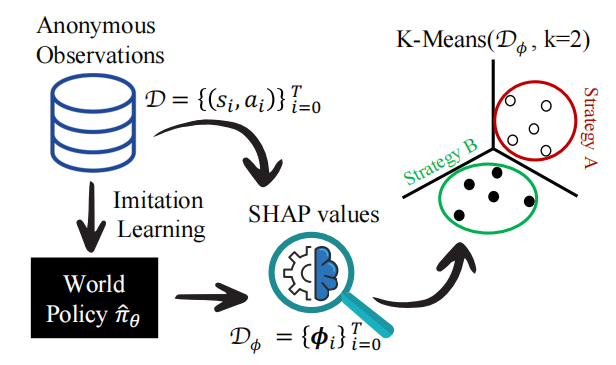
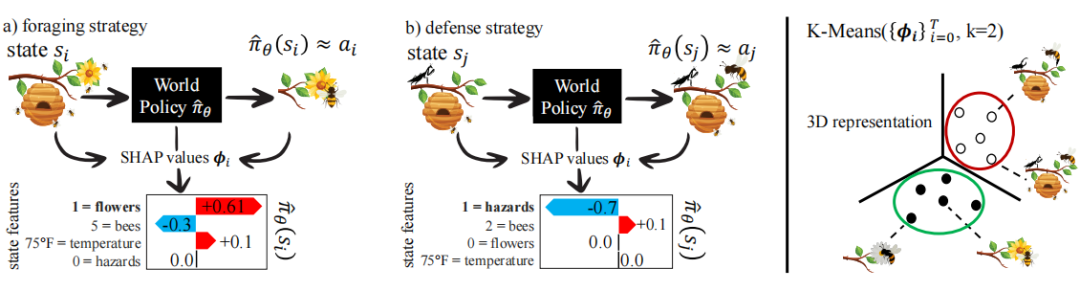
全局策略学习:通过模仿学习(IL)任务,学习一个能够模仿所有智能体行为的全局策略(world-policy),该策略能够根据不同的环境状态输出相应的动作。
SHAP值解释:利用SHAP值对全局策略进行解释,计算每个状态特征对动作的贡献,从而得到每个匿名观测的SHAP值向量。
K-Means聚类:将SHAP值向量作为新的特征空间,使用K-Means算法对观测进行聚类,以识别不同的智能体策略。
创新点
匿名状态-动作对的聚类:首次提出针对匿名多智能体状态-动作对的策略聚类方法,解决了金融等领域的数据匿名性问题。
性能提升:在合成市场数据和真实金融数据上,K-SHAP的聚类性能显著优于现有方法。例如,在合成数据的聚类任务中,K-SHAP的调整兰德指数(ARI)和归一化互信息(NMI)比其他方法高出约2-3倍。
SHAP值的优势:通过SHAP值将状态特征统一到相同的度量空间,简化了聚类过程,提高了聚类的准确性和效率。
适应性:该方法不仅适用于金融市场数据,还可以扩展到其他需要匿名行为分析的领域,如军事和网络安全。

















 4562
4562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









