







支持的操作:O(1)的插入,O(1)的查找,O(1)的删除
java中hash table(线程安全,有加锁机制)、hash map(线程不安全)、hash set(只有key,没有value)的区别
目录:
- 1.hash function - (常用hash函数、open hash解决冲突需要掌握)
1.2 hash-function (128 in lintcode)
1.3 strstr-ii 字符串查找 (594 in lintcode) (★★★★★) - 2.Rehashing
2.2 rehashing (129 in lintcode) (★★★★★)
2.3 LRU-cache LRU缓存策略 (134 in lintcode) (★★★★★)
2.3 其他相关题目
1. Hash Function
1). 根据hash function,计算出key对应的下标,然后下标访问数组的复杂度是O(1).
2). key space << hash 数组的大小,最好差距在10倍以上
3). 一些著名的hash算法: MD5、SHA-1、SHA-2,用于加密,不是用在hash 表中的,这些复杂度太高了。
4). 常用的hash函数:
a*31^2 + b * 31 +c* 31^0

a. 取模运算对加减乘除的次序没有影响。为了避免溢出,边乘边取模,不能直接用pow函数。
b. 31是经验值,其他也可以,但是乘31效果比较好。选择质数会更好,数字太大,会影响计算速度,数字太小,冲突太多。像Apache的底层库中,用的是33.
5). 整数或者double型的数怎么处理:将每个字节看作一个字符,如整数是4个字节,则看作是4个字符处理
6). 解决hash冲突:再好的hash函数也会存在冲突(collision)
**2种解决方案:**Open Hashing vs Closed Hashing(两个链接有动画)
https://www.cs.usfca.edu/~galles/visualization/ClosedHash.html
https://www.cs.usfca.edu/~galles/visualization/OpenHash.html
A. closed Hash - 占坑法

删除时:

B. open hash - 拉链法(较常用)- 实现方法:hash 函数+基本的链表操作
每个数组位置是一个链表的头。
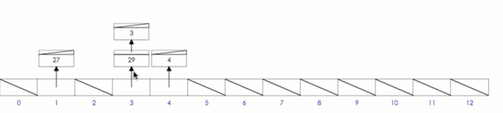
1.2 hash-function (128 in lintcode)
1).题目
http://www.lintcode.com/zh-cn/problem/hash-function/
http://www.jiuzhang.com/solution/hash-function/
在数据结构中,哈希函数是用来将一个字符串(或任何其他类型)转化为小于哈希表大小且大于等于零的整数。一个好的哈希函数可以尽可能少地产生冲突。一种广泛使用的哈希函数算法是使用数值33,假设任何字符串都是基于33的一个大整数,比如:
hashcode("abcd") = (ascii(a) * 333 + ascii(b) * 332 + ascii(c) *33 + ascii(d)) % HASH_SIZE
= (97* 333 + 98 * 332 + 99 * 33 +100) % HASH_SIZE
= 3595978 % HASH_SIZE
其中HASH_SIZE表示哈希表的大小(可以假设一个哈希表就是一个索引0 ~ HASH_SIZE-1的数组)。
给出一个字符串作为key和一个哈希表的大小,返回这个字符串的哈希值。
2).代码
class Solution {
public:
/*
* @param key: A string you should hash
* @param HASH_SIZE: An integer
* @return: An integer
*/
int hashCode(string &key, int HASH_SIZE) {
// write your code here
long res = 0;
for(int i=0;i<key.size();++i){
res = (res *33 % HASH_SIZE + key[i]) % HASH_SIZE;
}
return res;
}
};
1.3 strstr-ii 字符串查找 (594 in lintcode) (★★★★★)
1).题目
http://www.lintcode.com/zh-cn/problem/strstr-ii/
http://www.jiuzhang.com/solution/strstr-ii/
实现时间复杂度为 O(n + m)的方法 strStr。
strStr 返回目标字串在源字串中第一次出现的第一个字符的位置. 目标字串的长度为 m , 源字串的长度为 n . 如果目标字串不在源字串中则返回 -1。
2).代码
class Solution {
public:
const int BASE = 1000000;
/*
* @param source: A source string
* @param target: A target string
* @return: An integer as index
*/
int strStr2(const char* source, const char* target) {
// write your code here
if(source == NULL || target == NULL){
return -1;
}
int m = strlen(target);
int n = strlen(source);
if(m==0){
return 0;
}
//compute 31^m
int power=1;
for(int i=0;i<m;++i){
power = power * 31 % BASE;
}
//hashCode of target
int targetCode = 0;
for(int i=0;i<m;++i){
targetCode = (targetCode * 31 % BASE + target[i]) % BASE; //直接赋值,不是相加
}
//hashCode of source
int hashCode = 0;
for(int i=0;i<n;++i){
//abc+d
hashCode = (hashCode * 31 % BASE + source[i]) % BASE;
//abcd-a
if(i>=m){
hashCode -= source[i-m] * power % BASE;
if(hashCode < 0){
hashCode += BASE;
}
}
//判断
if(i>=m-1 && hashCode == targetCode){
char tmp[m]; //为什么是m
memcpy(tmp,&source[i-m+1], m);
tmp[m] = '\0';
if(strcmp(tmp,target)==0){
return i-m+1;
}
}
}
return -1;
}
};
2. Rehashing
2.1.hash表的饱和度
饱和度 = 实际存储元素个数 / 总共开辟的空间大小 = size / capacity
一般来说,超过1/10(经验值)的时候,说明需要进行rehashing
不是原有的数组被填满了才是不够,如有100个位置的数组,已经放了10个数,那么就认为已经满了
2.2 Rehashing - 129 in lintcode
1). 题目
http://www.lintcode.com/problem/rehashing/
http://www.jiuzhang.com/solutions/rehashing/
哈希表容量的大小在一开始是不确定的。如果哈希表存储的元素太多(如超过容量的十分之一),我们应该将哈希表容量扩大一倍,并将所有的哈希值重新安排。假设你有如下一哈希表:
size=3, capacity=4
[null, 21, 14, null]
↓ ↓
9 null
↓
null
哈希函数为:
int hashcode(int key, int capacity) {
return key % capacity;
}
这里有三个数字9,14,21,其中21和9共享同一个位置因为它们有相同的哈希值1(21 % 4 = 9 % 4 = 1)。我们将它们存储在同一个链表中。
重建哈希表,将容量扩大一倍,我们将会得到:
size=3, capacity=8
index: 0 1 2 3 4 5 6 7
hash : [null, 9, null, null, null, 21, 14, null]
给定一个哈希表,返回重哈希后的哈希表。
注意事项
哈希表中负整数的下标位置可以通过下列方式计算:
- C++/Java:如果你直接计算-4 % 3,你会得到-1,你可以应用函数:a % b = (a % b + b) % b得到一个非负整数。
- Python:你可以直接用-1 % 3,你可以自动得到2。
2) 代码
/**
* Definition of ListNode
* class ListNode {
* public:
* int val;
* ListNode *next;
* ListNode(int val) {
* this->val = val;
* this->next = NULL;
* }
* }
*/
class Solution {
public:
/**
* @param hashTable: A list of The first node of linked list
* @return: A list of The first node of linked list which have twice size
*/
vector<ListNode*> rehashing(vector<ListNode*> hashTable) {
// write your code here
if(hashTable.size()==0){
return hashTable;
}
int cap = hashTable.size();
int newCap = cap * 2;
vector<ListNode*> resTable(newCap, NULL);
cout<<resTable.size()<<endl;
for(int i=0;i < hashTable.size();++i){
ListNode* head = hashTable[i];
while(head){
cout<<i<<endl;
int val = head->val;
int newval = (val % newCap + newCap) % newCap;
if(!resTable[newval]){
resTable[newval] = new ListNode(val);
}
else{
ListNode* cur = resTable[newval];
while(cur->next){
cur = cur->next;
}
cur->next = new ListNode(val);
}
head = head->next;
}
}
return resTable;
}
};
2.3 LRU-cache LRU缓存策略 - 134 in lintcode (★★★★★)
1)题目
http://www.lintcode.com/problem/lru-cache/
http://www.jiuzhang.com/solutions/lru-cache/
Example: [2 1 3 2 5 3 6 7]
为最近最少使用(LRU)缓存策略设计一个数据结构,它应该支持以下操作:获取数据(get)和写入数据(set)。
获取数据get(key):如果缓存中存在key,则获取其数据值(通常是正数),否则返回-1。
写入数据set(key, value):如果key还没有在缓存中,则写入其数据值。当缓存达到上限,它应该在写入新数据之前删除最近最少使用的数据用来腾出空闲位置。
2)思路 & 代码:
删除最近最少使用的,即当缓存达到上限之后,需要删除使用时间离现在最远的元素。

所以需要支持中间删除、头部删除,以及尾部追加,适合用LinkedList来实现。

所以需要 hash表 + LInkedList。在java中该数据结构叫做LinkedHashMap。单双向链表都可以实现,单向链表存上一个节点。
LinkedHashMap = DoublyLinkedList + HashMap
HashMap<key, DoublyListNode> DoublyListNode {
prev, next, key, value;
}
Newest node append to tail.
Eldest node remove from head.
单向链表:
Singly List 是否可行?
- 可以,在 Hash 中存储 Singly List 中的 prev node 即可
如 linked list = dummy->1->2->3->null 时
hash[1] = dummy, hash[2] = node1
class keyValueNode{
public:
int key,val;
keyValueNode* next; //存当前结点的前一个节点
keyValueNode(int _key,int _val){
key = _key;
val = _val;
next = NULL;
}
keyValueNode(){
key = 0;
val = 0;
next = NULL;
}
};
class LRUCache {
private:
void moveToTail(keyValueNode * prev){
if(prev->next == tail){
return;
}
keyValueNode* node = prev->next;
prev->next = node->next;
if(node->next != NULL){
hash[node->next->key] = prev;
}
tail->next = node;
node->next = NULL;
hash[node->key] = tail;
tail = node;
}
public:
unordered_map<int, keyValueNode*> hash;
keyValueNode* head,*tail;
int capacity,size;
/*
* @param capacity: An integer
*/LRUCache(int capacity) {
// do intialization if necessary
this->head = new keyValueNode(0,0);
this->tail = head;
this->capacity = capacity;
this->size = 0;
hash.clear();
}
/*
* @param key: An integer
* @return: An integer
*/
int get(int key) {
// write your code here
if(hash.find(key) == hash.end()){
return -1;
}
moveToTail(hash[key]);
return hash[key]->next->val;
}
/*
* @param key: An integer
* @param value: An integer
* @return: nothing
*/
void set(int key, int value) {
// write your code here
if(hash.find(key)!=hash.end()){
hash[key]->next->val = value;
moveToTail(hash[key]);
}
else{
keyValueNode * node = new keyValueNode(key,value);
tail->next = node;
hash[key] = tail;
tail = node;
size++;
if(size > capacity){
hash.erase(head->next->key);
head->next = head->next->next;
if(head->next!=NULL){
hash[head->next->key] = head;
}
size--;
}
}
}
};
2.4 相关题目
http://www.lintcode.com/problem/subarray-sum/
http://www.lintcode.com/problem/copy-list-with-random-pointer/
http://www.lintcode.com/problem/anagrams/
http://www.lintcode.com/problem/longest-consecutive-sequence/















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









