









【Papers quickthrough】Out-of-manifold, Putting Words in BERT’s Mouth, MTLE.
Out-of-manifold Regularization in Contextual Embedding Space for Text Classification
Paper Url. Accepted by ACL 2021 Long Paper.

1. Abstract
最近对BERT的研究主要集中在低维子空间,其中向量向量由输入词(或其上下文)计算得到。我们提出了一种新的方法来寻找和规范剩余的空间,被称为流形外(Out-of-manifold),不能通过文字访问。具体地说,我们利用两个从实际观测词中得到的向量来合成流形外的向量,利用它们来微调网络。通过训练一个鉴别器来检测输入向量是否位于流形内,同时优化一个生成器来产生新的向量,使其易于被鉴别器识别为流形外的向量。这两个模块成功地以统一的端到端方式协作,将流形外规范化。我们对各种文本分类基准的广泛评估证明了我们的方法的有效性,以及它与旨在增强流形的现有数据增强技术的良好兼容性。
2. Model
提出了一种新的混合方法,称为OoMMix,以规范上下文向量空间中的流形外文本分类。
用于流形外正则化的两个模块,即向量生成器和流形鉴别器(右)。
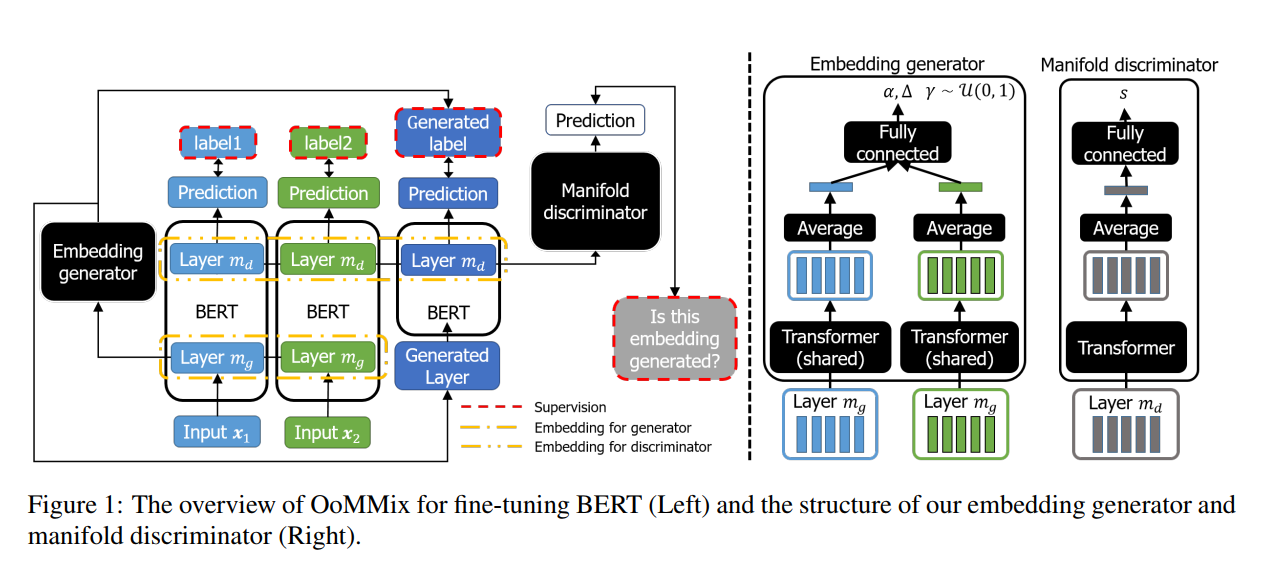
定义了一个额外的任务来识别上下文向量是来自生成器还是实际单词。这项任务的目的是学习实际向量和生成向量之间的区别特征,以便我们能够容易地发现不能通过实际观察到的词访问的子空间。也就是引入了一个鉴别器网络,通过上下文向量计算分数,分数表示他实际的概率。生成器可以产生流形外的向量,通过鉴别器可以清楚地区别于实际的(流形内的)上下文向量。
3. Results
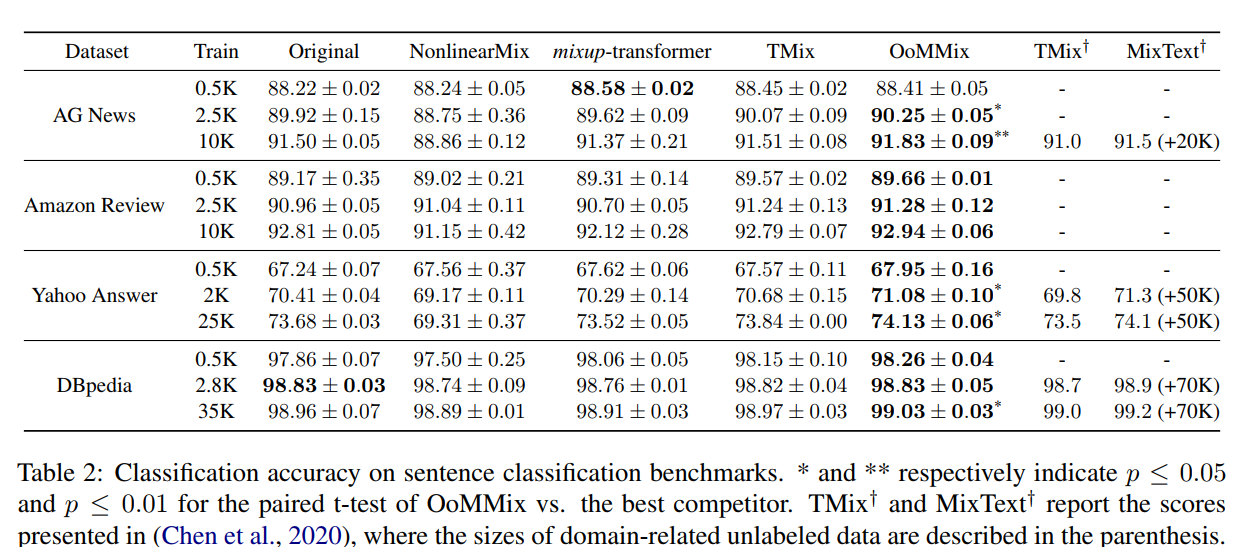
提升很小,0.3%左右。
4. Conclusion
本文提出了OoMMix来正则化上下文向量空间中的非流形。主要动机是从单词计算的向量只利用低维流形,而一个高维空间可用于模型容量。因此,OoMMix发现对目标任务有用但不能通过单词访问的向量。在流形鉴别器的帮助下,向量生成器成功地生成带有其标签的流形外向量。我们演示了OoMMix的有效性及其与现有数据增强技术的兼容性。我们的方法有点反直觉,因为不能通过实际的单词访问的向量对目标模型是有帮助的。由于文本(即单词)的离散特征向量到其上下文编码的高维连续空间中,无法覆盖整个空间,因此对于任何目标任务,也应仔细考虑未覆盖的空间。在这种意义上,我们需要将流形外规格化,以防止该空间中的异常行为,这对于一个大的预先训练的上下文向量空间尤为重要。
Putting Words in BERT’s Mouth: Navigating Contextualized Vector Spaces with Pseudowords

Paper Url. Accepted by EMNLP 2021.
1. Abstract
我们提出了一种在上下文化向量空间(特别是BERT空间)中探索单个点周围区域的方法,作为一种研究这些区域如何对应单词意义的方法。通过引入语境化的“伪词”作为输入层中静态向量的替代,然后对句子中的单词进行掩码预测,我们能够以一种受控的方式围绕单个实例研究bert空间的几何结构。将我们的方法应用于一组精心构建的针对英语歧义词的句子中,我们发现语境化空间具有实质性的规律性,即对应不同词义的区域;但在这些区域之间偶尔会出现“意义空白”。——不符合任何可理解意义的区域。
2. Model
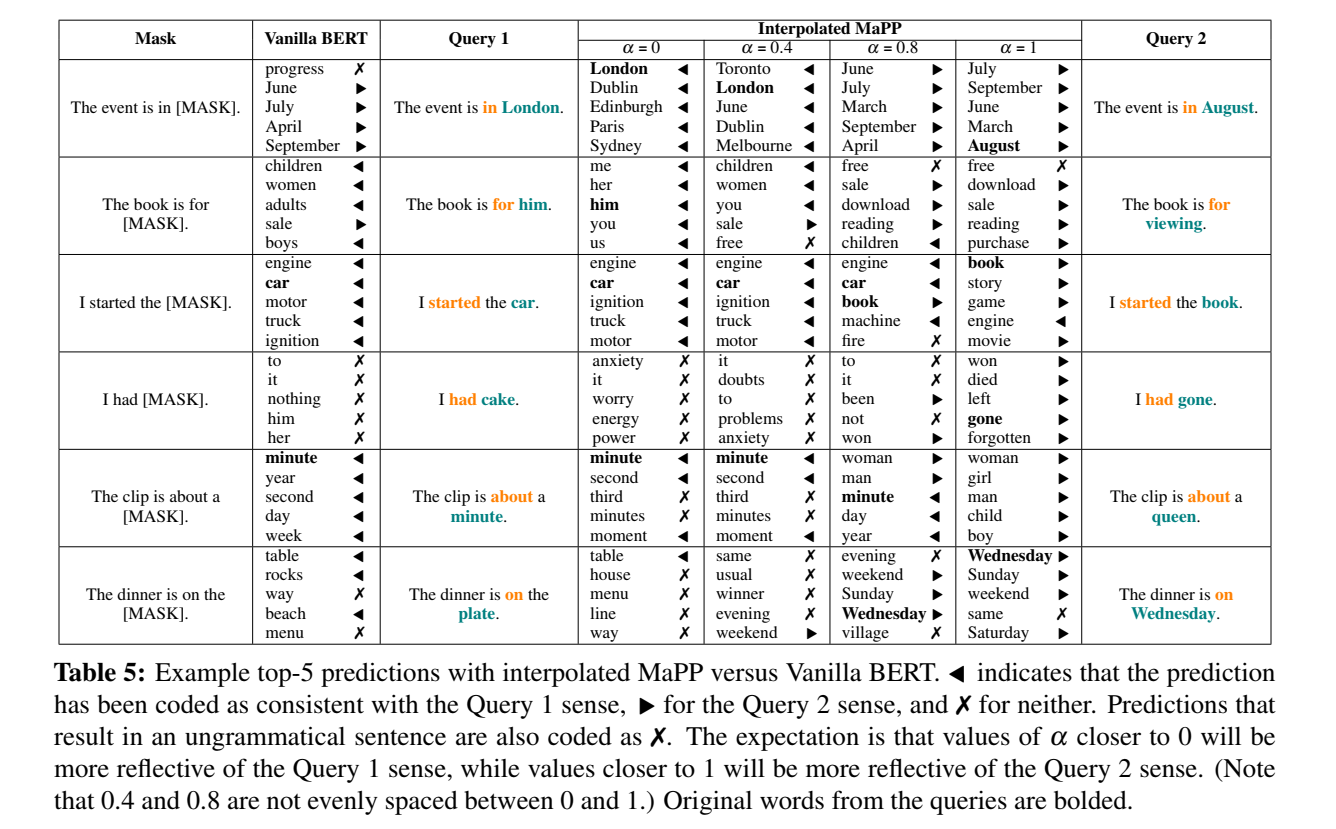
4. Conclusion
我们提出了一种新颖的方法和数据集,用于研究BERT空间的几何形状,使用遍历技术,允许输入空间的延续。我们证明在BERT空间中有大量的规律性,区域对应于不同的意义。此外,我们还发现了空间区域的空洞的证据,这些空洞并不符合任何可理解的意义。我们的技术带来了各种类型的分析,为未来的工作创造了途径。我们计划立即进行的方向是(a)检验较长、自然发生的句子中的感觉表征,(b)将我们的分析扩展到多语言环境中。
Multi-Task Label Embedding for Text Classification
Paper Url. Accepted by EMNLP 2018. Cited by 《Fusing label Embedding into BERT》
Key Point:将文本分类中的标签转换为语义向量,从而将原始任务转换为向量匹配任务。实现了多任务标签嵌入的无监督,监督和半监督模型,所有这些模型都利用了任务之间的语义相关性。

1. Abstract
文本分类中的多任务学习利用相关任务之间的隐关联来提取共同特征并获得性能增益。但是,以往的大量工作将每个任务的标签视为独立的、无意义的独热编码,导致潜在标签信息的丢失。在本文中,我们提出多任务标签向量,将文本分类中的标签转换为语义向量,从而将原始任务转化为向量匹配任务。该模型利用了任务间的语义关联,便于在新任务出现时进行扩展或迁移。在五个文本分类基准数据集上的大量实验表明,我们的模型可以有效地提高具有标签和附加信息语义表示的相关任务的性能。
2. Introduction
2.1 Intuition
- Lack of Label Information 独热编码导致潜在标签信息的丢失
- Inability of Scaling 无法多任务交互,引入新任务时模型需改变
- Inability of Transferring 无法迁移
2.2 Contribution
- 利用label embedding
- 涉及新任务时,网络结构不需要修改,只有来自新任务的数据需要training
- 在完成多项相关任务的training后,模型也可以transfer,以处理全新的任务,而不需要任何额外的训练,同时仍可实现可观的性能。
2.3 多任务角度
- Multi-Cardinality 多基数 。例如,具有不同平均序列长度和班级编号的电影评论数据集。SST-1, SST-2, IMDB.
- Multi-Domain 多领域 。任务在语料库领域各不相同,例如书籍,DVD,电子产品和厨房用具的产品评论数据集。 Multi-Domain Sentiment Dataset (Blitzer et al., 2007)
- Multi-Objective 多目标。任务针对不同的目标,例如情感分析,主题分类和问题类型判断。IMDB, RN, QC.
3. Model

3.1 Model-1 Unsupervised
只有文本与标签集,没有标注文本,使用无监督模型得到word embedding,求平均以得到文本表示,通过计算余弦相似度获取label。
3.2 Model-2 Supervised
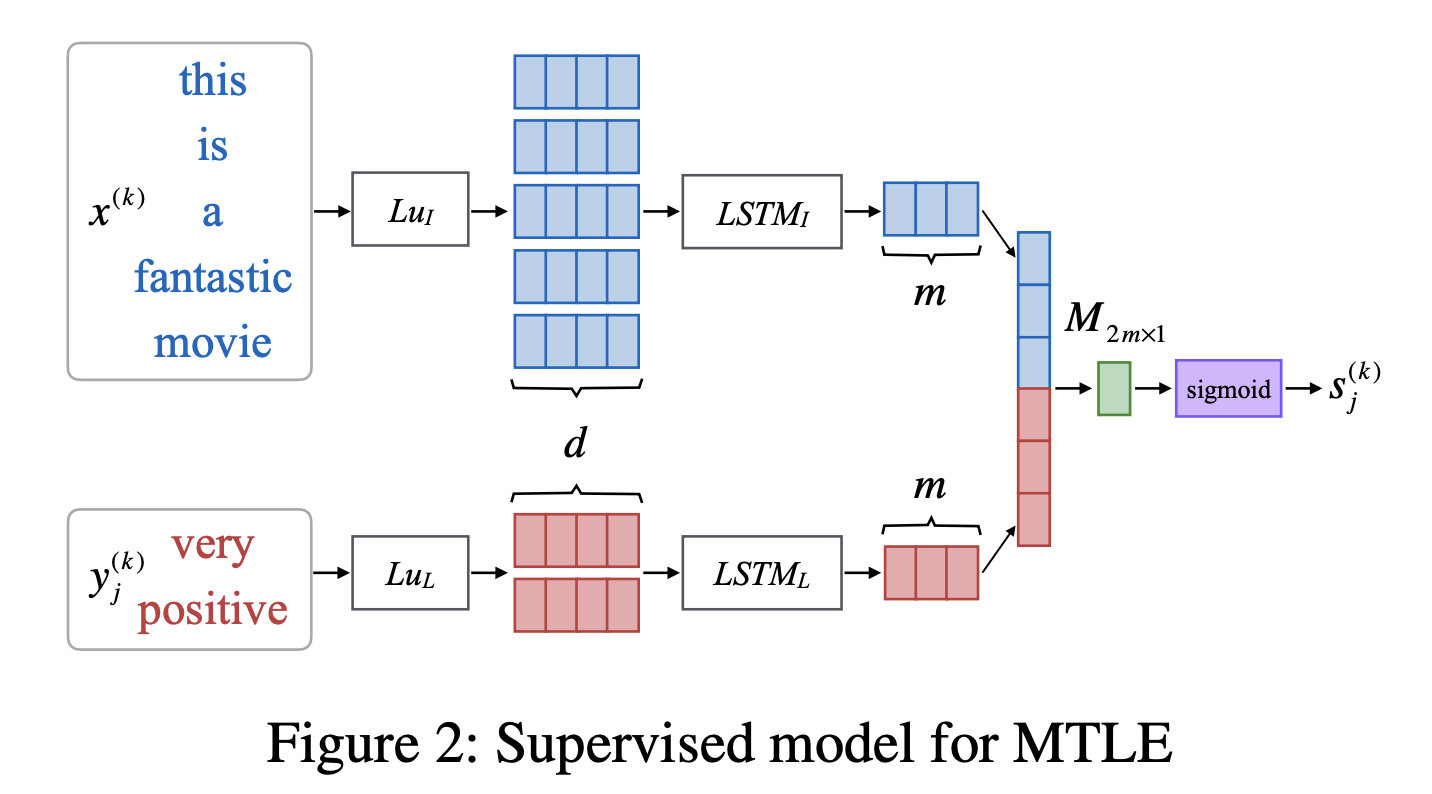
利用大小为 2 m × 1 2m\times1 2m×1的全连接层,用 M 2 m × 1 M_{2m\times1} M2m×1表示,以实现Matcher接受来自 L u I Lu_I LuI和 L u L Lu_L LuL的输出产生匹配分数,
当涉及新任务时,Model-II可以非常方便地扩展,因为整个网络结构不需要修改。我们可以继续对模型-II进行训练,并根据来自新任务的样本(热更新)进一步调整参数,或者基于来自所有任务的样本再次重新训练模型II,这些样本被定义为冷更新。
3.3 Model-3 Semi-Supervised
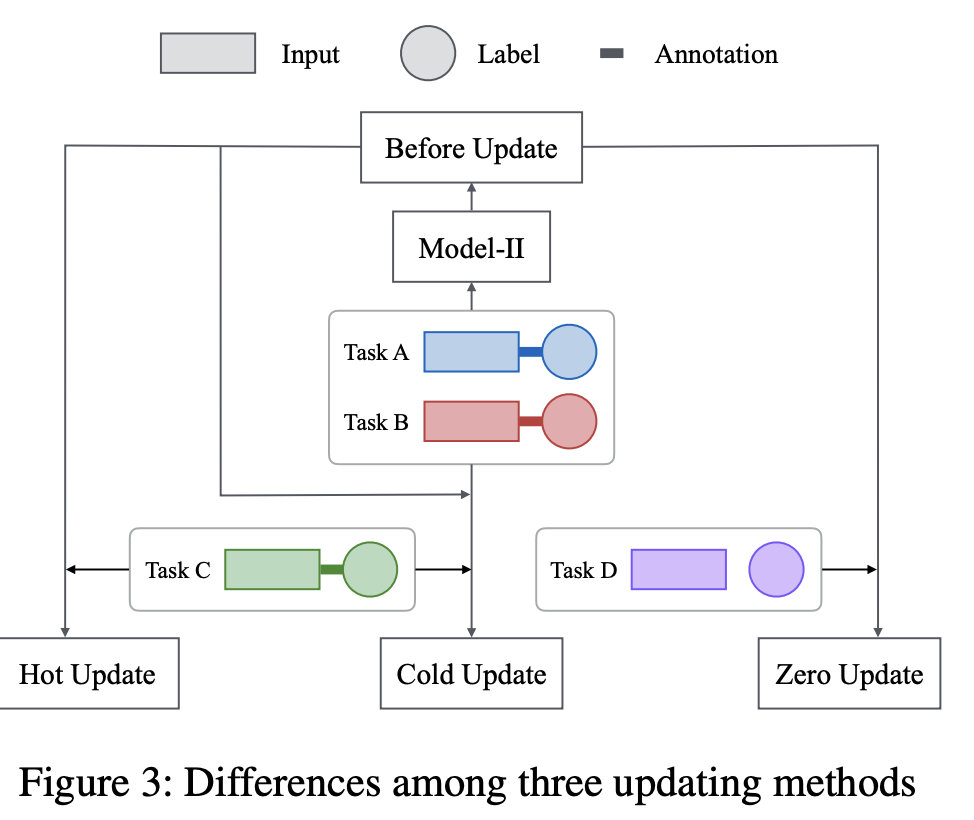
如果新任务提供了注释,我们可以选择应用模型II的热更新或冷更新。如果新任务完全没有标记,我们仍然可以使用Model-2进行向量映射,并为每个输入序列找到最佳标签,而不需要任何进一步的训练,我们将其定义为零更新。为了避免混淆,我们特别使用模型III来表示新任务的注释不可用并且只有零更新适用的情况,其对应于人的转移和半监督学习能力。热更新,冷更新和零更新之间的差异如图3所示,其中“更新前”表示在新任务引入之前对旧任务进行训练的模型。
当涉及到新的任务时,Model-II非常方便进行扩展,因为整个网络结构不需要修改。我们可以继续训练Model-II,并根据来自新任务的样本(定义为Hot Update)进一步调整参数,或者根据来自所有任务的样本(定义为Cold Update)再次训练Model-II。我们将在实验部分详细研究这两种缩放方法的性能。
4. Results
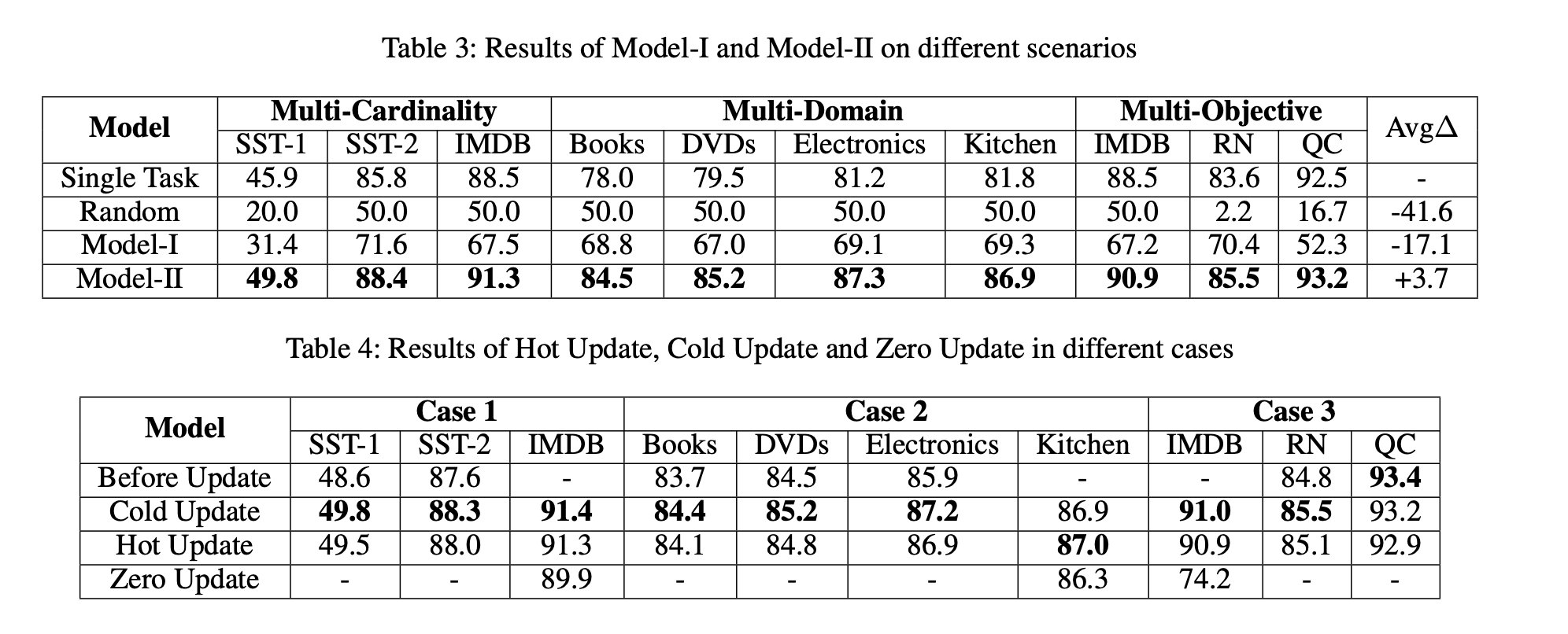
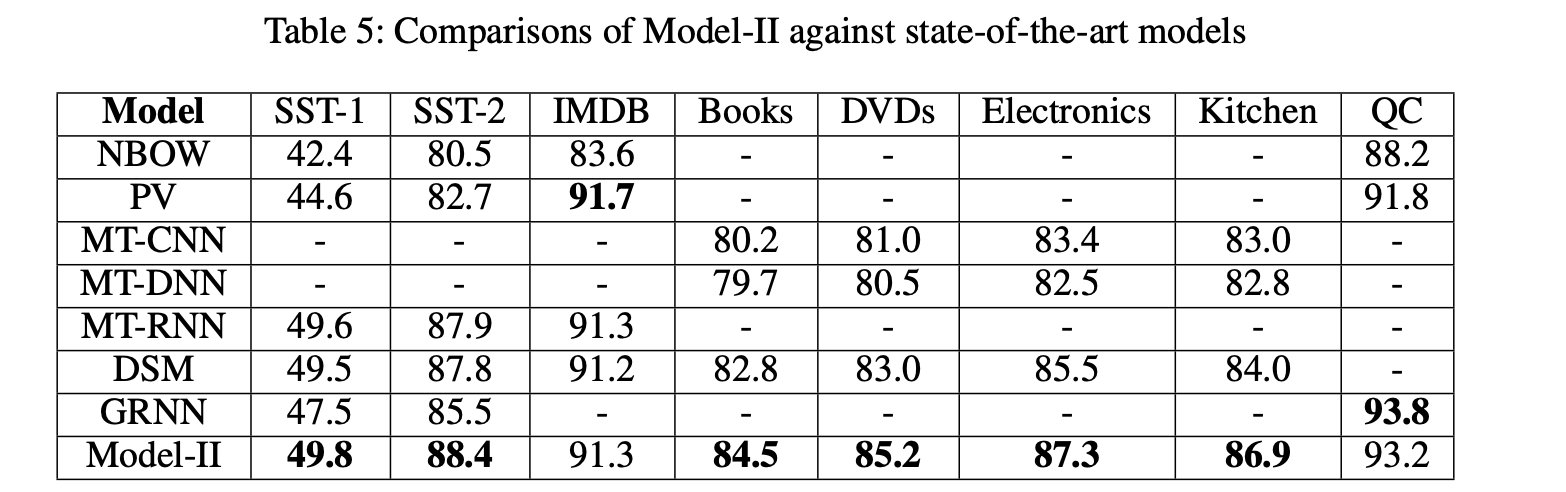
有着较高的提升。所有任务平均提升了3.7%个点。
5. Conclusion
在本文中,我们提出多任务标签嵌入,将文本分类任务中的标签映射到语义向量中。MTLE利用了任务间的语义关联,有效地解决了新任务时的可伸缩和迁移问题。我们探讨了三种不同的MTL场景,在所有场景中,MTLE可以通过标签和其他信息的语义表示来提高大多数任务的性能。在未来的工作中,我们将探索其他的学习层,并将MTLE推广到其他的自然语言处理任务中,如序列标注和序列到序列学习。















 9458
9458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









