






 文章探讨了信号处理中的两个关键指标,SI-SDR(Scale-invariantSignal-to-DistortionRatio)和CI-SDR(ConvolutionaltransferfunctioninvariantSignal-to-DistortionRatio)。SI-SDR常用于评估生成向量与真实向量的匹配程度,而CI-SDR则解决了多通道混响设置中SI-SDR的局限性,通过添加有限脉冲响应滤波器来处理时域卷积。此外,文章还提到了损失函数SISDR_LOSS和其反向计算过程,以及如何应用于多通道源分离和识别。
文章探讨了信号处理中的两个关键指标,SI-SDR(Scale-invariantSignal-to-DistortionRatio)和CI-SDR(ConvolutionaltransferfunctioninvariantSignal-to-DistortionRatio)。SI-SDR常用于评估生成向量与真实向量的匹配程度,而CI-SDR则解决了多通道混响设置中SI-SDR的局限性,通过添加有限脉冲响应滤波器来处理时域卷积。此外,文章还提到了损失函数SISDR_LOSS和其反向计算过程,以及如何应用于多通道源分离和识别。
首先进行名词解释:
SI-SDR:Scale-invariant Signal-to-Distortion Ratio
CI-SDR:Convolutive transfer function invariant Signal-to-Distortion Ratio
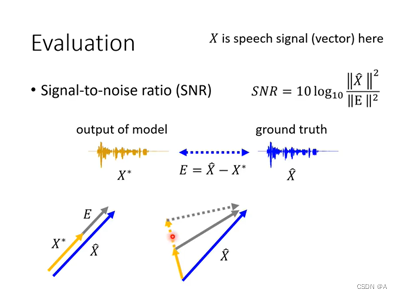
SDR&SNR:
众所周知SDR_loss的计算方法:
SI-SNR或者叫SI-SDR,他将生成向量 X* 投影到真实向量的垂直方向,我们叫他为 XE ,再把XE作为分母,我们可以得出在两向量平行的时候评估结果是无限大的,而且向量X*方向偏差越大, XE 的值就越大,SISDR越小。(越大还原效果越好)

与之相对应的是SNR。SNR是用真实值减去生成值的评分作为分母,真实值的平方作为分子再取对数,所得到的最终结果越大越好。
SISDR_LOSS
对于loss,我们将SISDR的计算过程取反(loss越小越好):
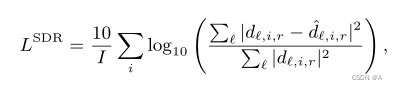
公式参数详解见第二篇文
引入扩展项ˆai,弥补潜在的扩展目标之间的误差和估计。计算方法为:
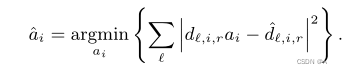
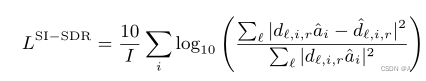
CISDR_LOSS
convolutive transfer function invariant Signal-to-Distortion Ratio (CI-SDR)(时域卷积SDR)
然而当考虑多通道混响设置时,SI-SDR会产生奇怪的伪影。例如,如果SI-SDR是在一个通道作为估计值和另一个通道作为目标之间计算的,即它们具有不同的RIR,虽然听不出什么差别,但SI-SDR显示了巨大的差异。
因此我们引入CI-SDR的概念:
与SI-SDR不同,扩展项a是一个具有512个系数的有限脉冲响应滤波器。与SISDR相比CISDR在对观测信号的处理上多了时域卷积。
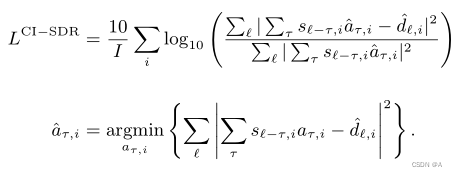
参考
SMS-WSJ: DATABASE, PERFORMANCE MEASURES, AND BASELINE RECIPE
FOR MULTI-CHANNEL SOURCE SEPARATION AND RECOGNITION
CONVOLUTIVE TRANSFER FUNCTION INVARIANT SDR TRAINING CRITERIA FOR
MULTI-CHANNEL REVERBERANT SPEECH SEPARATION

















 6824
6824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









