








论文地址:https://arxiv.org/pdf/2402.03620.pdf
Abstract
我们引入了SELF-DISCOVER,这是一个通用框架,用于让LLMs自我发现任务内在的推理结构,以解决对典型提示方法具有挑战性的复杂推理问题。该框架的核心是一个自我发现过程,在这个过程中,LLMs选择多个原子推理模块,比如批判性思维和逐步思维,并将它们组合成一个明确的推理结构,供LLMs在解码过程中遵循。SELF-DISCOVER显著提高了GPT-4和PaLM 2在具有挑战性的推理基准测试(如BigBench-Hard、基于代理人的推理和数学推理)上的性能,相比于Chain of Thought(CoT)高达32%。此外,SELF-DISCOVER在需要推理密集型方法,如CoT-Self-Consistency,时的表现超过20%,同时推理计算量减少了10-40倍。最后,我们展示了自我发现的推理结构在模型家族之间具有普遍适用性:从PaLM 2-L到GPT-4,从GPT-4到Llama2,并与人类推理模式共享共同点。
引言
在人工智能领域,大模型(LLMs)如GPT-4和PaLM 2在文本生成方面展现了强大性能。然而,这些模型在处理复杂推理任务时仍面临挑战。传统的提示方法,如思维链(CoT),虽然在某些情况下有效,但它们通常依赖于预设的推理过程,这可能不适用于所有类型的任务。
为此,Google的研究人员提出了「SELF-DISCOVER框架,可实现自动发现和构建推理结构,以解决各种任务」。该方法显著提高了GPT-4和PaLM 2的性能,相比思维链(CoT),性能提升高达32%。
背景介绍
大型语言模型(LLM)的基础是由Transformer组成的,例如:GPT-4、PaLM 2,它们在连贯文本生成、指令遵循方面取得了令人印象深刻的突破。为了提升大模型解决复杂问题的能力,受到人类认知理论的启发,人们提出了各种提示(Prompt)方法。例如,Zero-Shot、Few-Shot思维链(CoT)模仿了人们分步解决问题的方式;基于分解的提示(decomposition-based prompting)技术,灵感来自于人们如何将一个复杂的问题分解为一系列较小的子问题,然后逐一解决这些子问题;回溯提示(step-back prompting)技术灵感来源于人类对相关任务的反思。
但是以上的这些技术作为一个原子推理模块,存在一定的局限性,因为当面对给定任务时都会存在隐含的先验假设。相反,本文作者认为每个任务都有独特的内在结构,这是有效解决推理问题的基础。
基于以上考虑,本文作者提出了一个名为自发现(SELF-DISCOVER)的框架,它允许LLMs自发现并组合原子推理模块,并形成一个明确的推理结构,以便在解码过程中遵循。这种方法的核心是一个自发现过程,其中LLMs从多个原子推理模块(如批判性思维和逐步思考)中选择,并将其组合成一个推理结构。
SELF-DISCOVER框架
SELF-DISCOVER框架的核心部分是自发现过程,它允许大型语言模型(LLMs)在没有明确标签的情况下,自主地为特定任务生成推理结构。SELF-DISCOVER框架包含两个主要阶段:自发现特定任务的推理结构、应用推理结构解决问题。如下图所示:
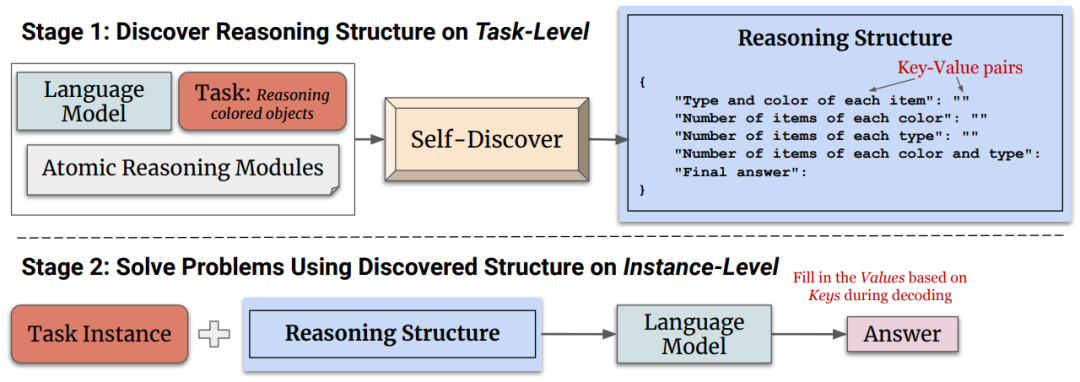
「阶段一:自发现特定任务的推理结构」主要包含三个主要动作:选择(SELECT)、适应(ADAPT)和实施(IMPLEMENT)。如下图所示:
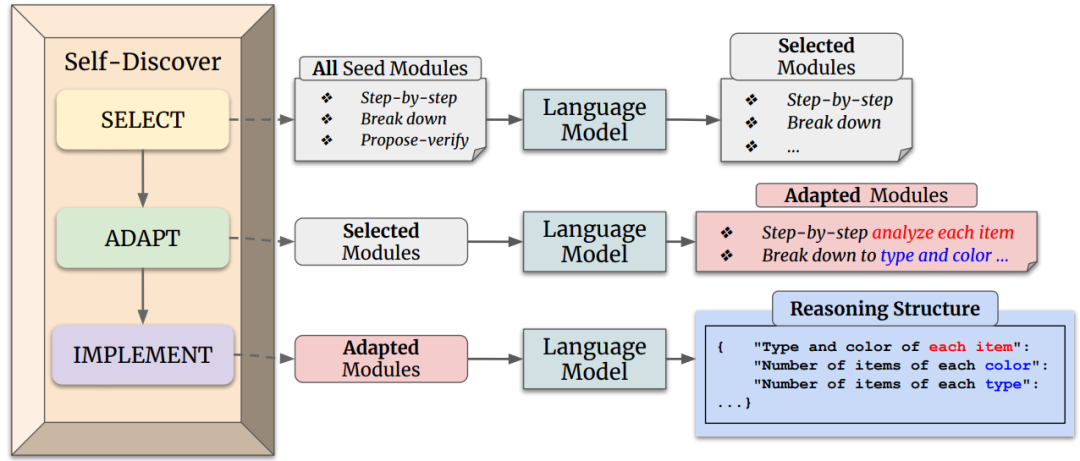
其中:
-
「选择(SELECT)」在这个阶段,模型从一组原子推理模块(例如“批判性思维”和“逐步思考”)中「选择对于解决特定任务有用的模块」。模型通过一个元提示(meta-prompt)来引导选择过程,这个元提示结合了任务示例和原子模块描述。选择过程的目标是确定哪些推理模块对于解决任务是有助的。
-
「适应(ADAPT)」 一旦选定了相关的推理模块,下一步是调整这些模块的描述使其更适合当前任务。这个过程到将一般性的推理模块描述转化为更具体的任务相关描述。例如,对于算术问题,“分解问题”的模块可能被调整为“按顺序计算每个算术操作”。同样,这个过程使用元提示和模型来「生成适应任务的推理模块描述」。
-
「实施(IMPLEMENT)」 在适应了推理模块之后,SELF-DISCOVER框架将这些适应后的推理模块描述「转化为一个结构化的可执行计划」。这个计划以键值对的形式呈现,类似于JSON,以便于模型理解和执行。这个过程不仅包括元提示,还包括一个人类编写的推理结构示例,以帮助模型更好地将自然语言描述转化为结构化的推理计划。
「阶段二:应用发现推理结构」 完成阶段一之后,模型将拥有一个专门为当前任务定制的推理结构。在解决问题的实例时,模型只需遵循这个结构,逐步填充JSON中的值,直到得出最终答案。
这个过程的关键在于,它允许模型在没有人类干预的情况下,自主地生成适合特定任务的推理结构,这不仅提高了模型的推理能力,而且提高了推理过程的可解释性。通过这种方式,模型能够更有效地处理复杂和多样化的任务。
实验结果
在实验阶段,作者主要验证SELF-DISCOVER框架如何提升大型语言模型(LLMs)在处理复杂推理任务上的性能。实验选取了25个具有挑战性的任务,覆盖了算法推理、自然语言理解、世界知识和数学等多个领域。
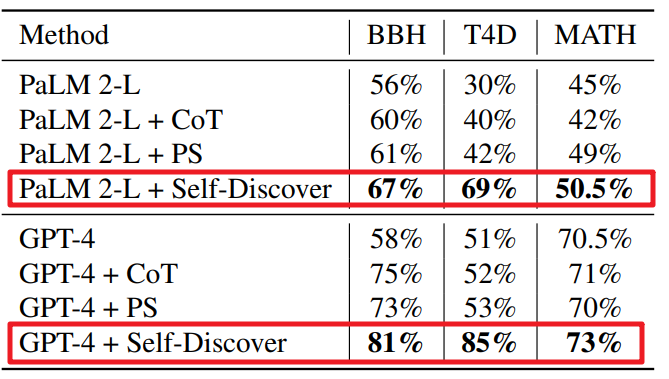
在性能方面,如下图所示,在BigBench-Hard、Thinking for Doing和MATH等复杂推理基准测试中,SELF-DISCOVER显著提高了GPT-4和PaLM 2的性能,与Chain of Thought (CoT)相比,性能提升高达32%。
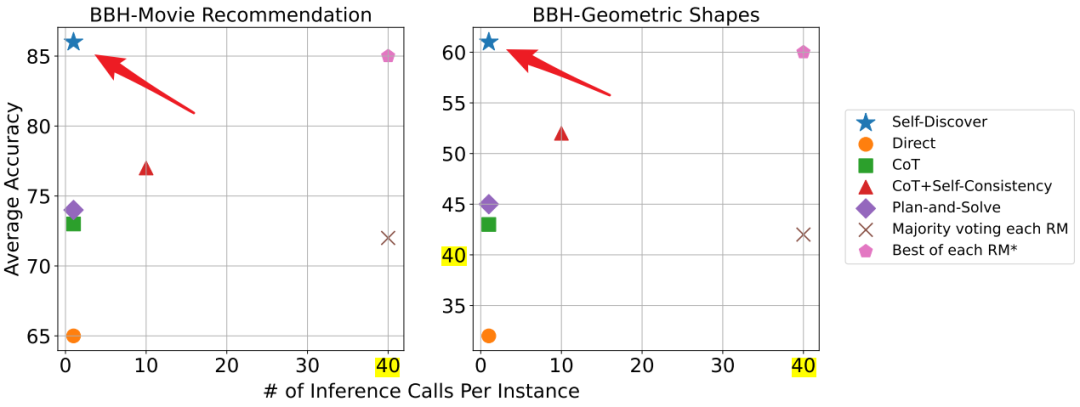
在计算效率方面,与其他推理密集型方法(如CoT+Self-Consistency)相比,SELF-DISCOVER在保持性能的同时,所需的推理计算量减少了10-40倍。
7. 结论
我们引入了SELF-DISCOVER,这是一个高效且性能优越的框架,用于模型从通用问题解决技能的种子集中自我发现任何任务的推理结构。我们观察到,在多个LLMs上,挑战性推理基准测试的性能显著提高了多达30%。SELF-DISCOVER的消融研究表明,组合的推理结构在LLMs之间具有普遍可转移性。展望未来,我们很兴奋地探索更多关于LLM结构化推理的内容,以推动问题解决的边界,并发现人机协作的潜力。
















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











