






本篇文章和下篇文章精简记录一下flashattention1和flashattention2的主要思想和解决问题,首发于我的公众号“AI不止算法”,文章链接在此,本文先记录flash attention1.
引言/动机
FlashAttention是继standard Attention和Memory-efficient Attention(论文:《Self-attention Does Not Need O(N^2) Memory》后,当前主流的Attention优化方法。
在transformer或MHA的profiling中,一般最耗时的部分都在scaled dot product attention部分,它之所以耗时,不是因为计算量大,而是访存量大,访存量大的原因是QKT矩阵的shape为[batch_size, num_heads, seqlen, seqlen],读写内存量与seqlen成平方阶,这导致对HBM或者显存的memory traffic非常大;而且在反向传播中,为了计算QKT matmul输入和权重的梯度,还要再读[batch_size, num_heads, seqlen, seqlen]的QKT来做矩阵乘法,这就导致在训练的计算图中,我们要保存[batch_size, num_heads, seqlen, seqlen]大小的数据在HBM或者显存直到这几个算子(matmul、scale、mask、softmax)的反向传播计算完成。这是非常耗显存的。

解决这种访存问题的惯用手法是算子融合,即把以上左图的这几个算子融合成一个算子。
挑战
在Flash Attention出来之前,已经有了很多了fusedattention算子,但是仔细看,可以发现这其实不是真正的融合算子,只是把matmul kernel、scale kernel、softmax kernel的接口在一个fusedattention算子里面按照计算顺序调了一下,这种手法最多减少了pytorch、TF等框架对算子的调度开销,其实不能真正解决对HBM或者显存的memory traffic。
融合MHA的挑战在于两点:
1.解决softmax,因为softmax是一个row-wise(以行为单位)的操作,必须要遍历softmax一行才能得到结果,由此,后面的matmul不得不等待这个过程,导致并行性降低
2.在寄存器和shared memory复用数据做计算,而不是去HBM或显存上去读数据来计算,然而寄存器数量和shared memory大小都有限,在1的情况下,显然无法将softmax的结果存到这两个存储单元里面供下一个matmul复用,下一个matmul不得不去HBM或显存上读数据
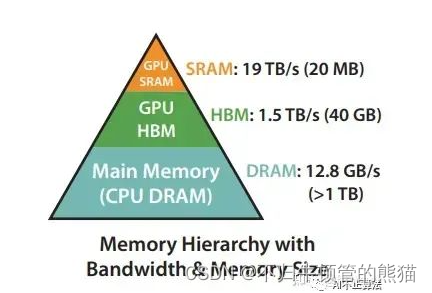
下图是GPU上HBM、shared memory的容量和带宽,和CPU上的memory层次结构也类似,越快的存储单元容量越小带宽越大。
Flash Attention
flash attention的出现,解决了上述两个挑战,通过分块计算softmax得到一个中间结果,并保存在shared memory,送到下一个matmul计算。
具体算法:
# 计算公式
S = Q * (K.transpose(-1, -2))
P = softmax(S)
O = P * V

总的来说,关键在于,把QKVO四个矩阵分块计算,KV矩阵的列维度为外循环(L5),QO矩阵的行维度为内循环(L7),每次外循环我们将得到一行softmax的子块max(分子)和子块sum(分母)(L10),然后把这个中间结果与V矩阵相乘得到O的一行中间结果,而后随着外循环完成,O的一行中间结果不断的更新得到最终结果(L12)
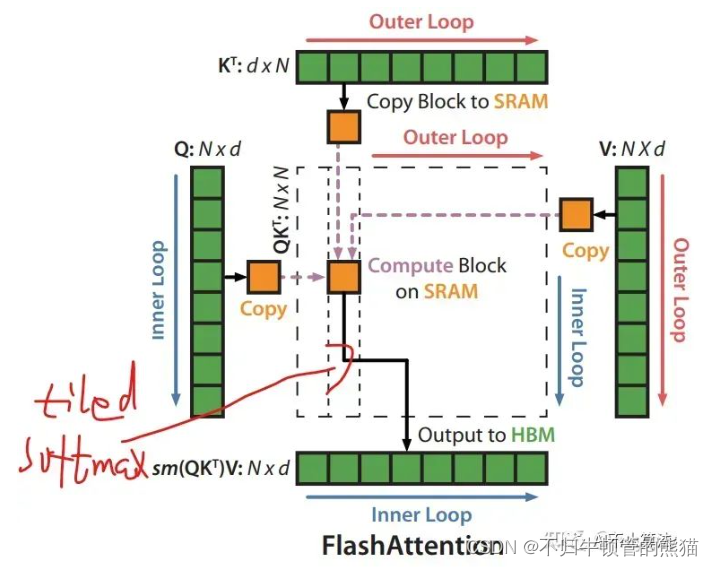
这么说有点抽象,下面通过例子来说明
例子说明:附注释
# 计算公式
# S = Q * (K.transpose(-1, -2))
# P = softmax(S)
# O = P * V
import numpy as np
N = 4
d = 2
S = np.random.random(size=(1, N))
V = np.random.random(size=(N, d))
def tiled_softmax_then_matmul(S, V):
acc = np.zeros(shape=(1, d))
pre_max = float("-inf")
pre_sum = 0
for i in range(N): # 每个token,KV的列维度,为了简洁,这里把Q的行维度设为了1,因此没有了内循环
s_i = S[:,i] # 每列S
cur_max = max(pre_max, s_i) # 当前分块和之前分块一起的最大值
pre_sum *= (np.exp(pre_max - cur_max)) # L10
cur_sum = pre_sum + np.exp(s_i - cur_max) # 当前分块和之前分块一起的指数和
score = np.exp(s_i - cur_max) / cur_sum # 当前分块的softmax结果
scale = pre_sum / cur_sum # 因为上一个分块的结果是基于当时的softmax中间sum组成的分母(presum),现在这个分块又得到了新的中间sum(cursum),所以需要更新:对上一个分块的结果acc做一个scale,保证结果的正确性
acc *= scale
acc += score * V[i,] # scale后的中间结果加上当前分块的P * V = O
pre_max = cur_max
pre_sum = cur_sum
return acc
具体例子:


融合后
融合前,scale dot product attention由左边五个算子组成,融合后,变成了右边一个。

结论
Flash attention1的出现极大加速了transformer的训练速度,如下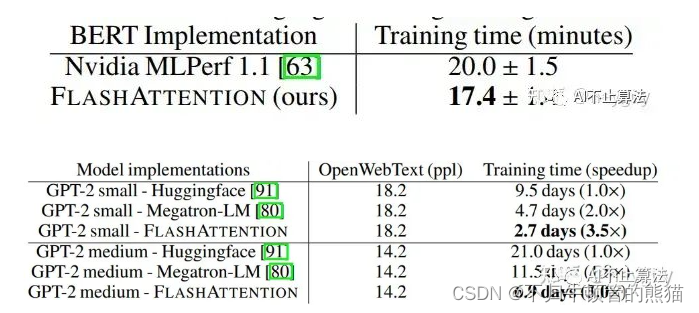
不过还是有很多可改进的地方,比如Q的循环可以放在外面,消除每次KV外循环都要去访问Q的开销;每次外循环都需要去用presum/cursum去rescale中间结果以得到最终结果,这些计算可以通过算法消除,使得尽可能减少CUDA core的计算,增加tensor core的计算,因为tensorcore的FLOPS比cuda core大得多,然而在多数真实情况下,tensor core和cuda core很难overlap,或者overlap的比率很低,所以减少cuda core的计算以提升性能。这些都会在下一篇文章介绍flashattention2介绍到。敬请期待~
欢迎关注我的公众号“AI不止算法”















 3866
3866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









