







 本文概述了样本归一化的重要性,解释了为何训练和测试使用不同均值方差;讨论了梯度为0的情况及其含义,以及随机梯度下降的batchsize设置。还涉及模型选择原则、数据加载器生成器、优化算法(如SGD、Momentum、AdaGrad和Adam)、分布式训练、技巧调整和模型保存。
本文概述了样本归一化的重要性,解释了为何训练和测试使用不同均值方差;讨论了梯度为0的情况及其含义,以及随机梯度下降的batchsize设置。还涉及模型选择原则、数据加载器生成器、优化算法(如SGD、Momentum、AdaGrad和Adam)、分布式训练、技巧调整和模型保存。
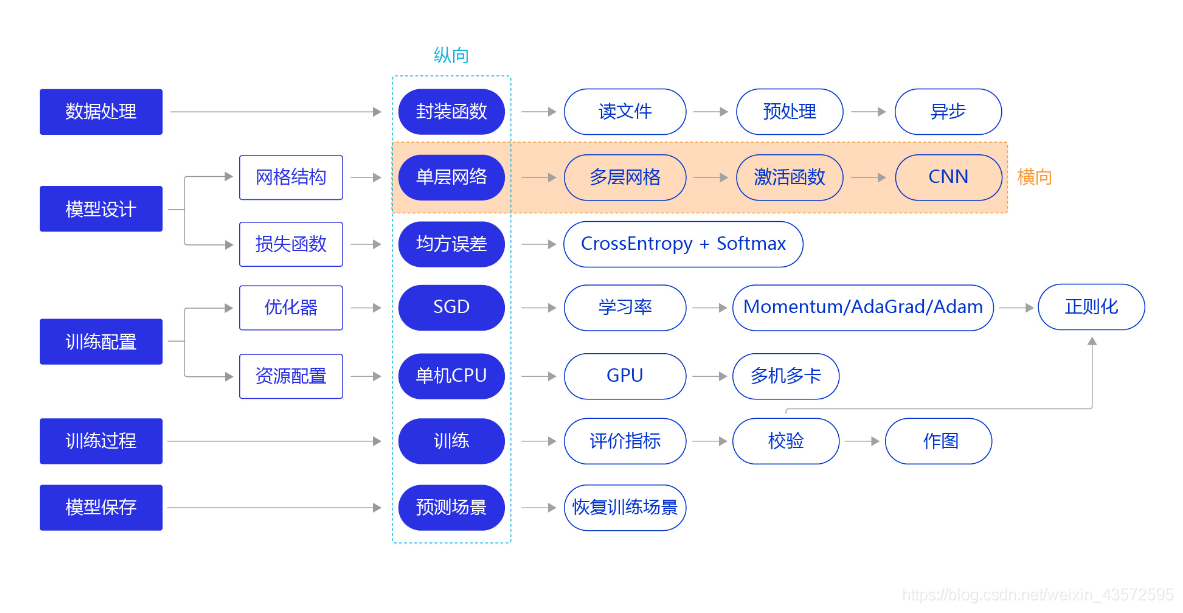
0. 需要去学习哪些基本内容
1. 样本归一化:预测时的样本数据同样也需要归一化,但使用训练样本的均值和极值计算,这是为什么?
答:可以从三个角度理解:众所周知,我们的数据集分为训练集和测试集,对于测试集的均值方差归一化,不能用测试集的均值和方差,而要用训练集的均值和方差,因为真实数据中很难得到其均值和方差。另外,网络参数是从训练集学习到的,也就是说,网络的参数尺度是与训练集的特征尺度一致性相关的,所以应该认为测试数据和训练数据的特征分布一致。最后,训练集数据相比测试集数据更多,用于近似表征全体数据的分布情况。
总结就是认为测试数据的分布应该与训练数据的分布一致。
例如样本A、样本B作为一批样本计算均值和方差,与样本A、样本C和样本D作为一批样本计算均值和方差,得到的结果一般来说是不同的。那么样本A的预测结果就会变得不确定,这对预测过程来说是不合理的。解决方法是在训练过程中将大量样本的均值和方差保存下来,预测时直接使用保存好的值而不再重新计算。
2. 当部分参数的梯度计算为0(接近0)时,可能是什么情况?是否意味着完成训练?
答:可能是到了局部最优。否。可以想象,下山路途中在半山腰碰到了一个又一个平台,平台处是平缓的,这里的梯度接近0,但是我们还没下到山的最底部。
3.随机梯度下降的batchsize设置成多少合适?过小有什么问题?过大有什么问题?提示:过大以整个样本集合为例,过小以单个样本为例来思考
答:batch过大,会增大内存消耗和计算时间,且训练效果并不会明显提升(因为每次参数只向梯度反方向移动一小步,所以方向没必要特别精确);batch过小,每个batch的样本数据将没有统计意义,计算的梯度方向可能偏差较大。
深度学习中的batch的大小对学习效果有何影响? - 程引的回答 - 知乎
https://www.zhihu.com/question/32673260/answer/71137399
4.模型选择应用原则
答:那么当我们需要将学术界研发的模型复用于工业项目时,应该如何选择呢?一个小建议:当几个模型的准确率在测试集上差距不大时,尽量选择网络结构相对简单的模型。往往越精巧设计的模型和方法,越不容易在不同的数据集之间迁移。
5. 数据加载器为什么要做成生成器?
答:同时,在返回数据时将Python生成器设置为yield模式,以减少内存占用。
6. 同步和异步数据读取

- 同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
- 异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
- 异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
深度学习框架中,通常需要定义datasets继承框架提供的数据集类,以及调用DataLoderAPI实现单线程/多线程加载。
7.为什么需要非线性激活函数
答:隐含层引入非线性激活函数Sigmoid是为了增加神经网络的非线性能力。因为如果没有非线性激活函数,整个网络展开后依旧是一个巨大的线性函数。
8.对于分类问题,为什么输出分类概率而不是具体的分类标签数值?
答:如果用不同的数值代表不同的类别,比如1到9表示不同的类别,输出预测结果也是0-9。计算loss的时候是不合理的:因为对于不同的类别应该是没有偏好的,上面说的这种方式会使得不同的分类错误对于loss的贡献不一致。比如label是1,但是分成了9,直接计算loss的结果很大。但是如果分成了2,loss却很小。但实际上2和9应该是同样的level。 当然,可以采用one-hot编码,使得类间距离一致。与此对应,真实的标签值可以转变成一个10维度的one-hot向量,在对应数字的位置上为1,其余位置为0,比如标签“6”可以转变成[0,0,0,0,0,0,1,0,0,0]。所以目前采用softmax算出不同概率,最后取最大概率对应的那个位置上编码为1。
9. 交叉熵损失的原理
答:基于极大似然的思想。交叉熵的公式如下:
L = − [ ∑ k = 1 n t k log y k + ( 1 − t k ) log ( 1 − y k ) ] L = -[\sum_{k=1}^{n} t_k\log y_k +(1- t_k)\log(1-y_k)] L=−[k=1∑ntklogyk+(1−tk)log(1−yk)]
其中, log \log lo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









