









3.2.1 Word Embedding 定义
单词和关联词聚类,作为多维空间的向量。
比如电影评论中,分成两个集群(cluster)。
- 当搜索“无聊(boring)”时,会出现在负面评论的集群中。
- 当搜索“有趣(fun)”时,“funny” 出现在正面评论集群中,“fundamental” 出现在中心,意味着中性评论
本节将介绍如何建立分类器,并提供可视化效果
我们可以想象正面评论中,“fun”、“exciting”这两个词,构建它们的向量(多维的,例如16维)
随着多次的训练,相同情绪的词,会聚集在一起,它们在句子中的位置也相近,向量也相近。我们将向量和标签想结合,便是Embedding的含义了。
3.2.2
TensorFlow Data Services (TFDS)提供很多数据集
使用方法(例如MNIST):
# !pip install tensorflow-datasets
import tensorflow_datasets as tfds
# Construct a tf.data.Dataset
ds = tfds.load('mnist', split='train', as_supervised=True, shuffle_files=True)这里我们用“IMDB评论数据集(imdb-reviews)”
包含50000条电影评论,一半用作训练,一半用作测试
更多详情请查看:
https://www.tensorflow.org/datasets/catalog/imdb_reviews?hl=en
http://ai.stanford.edu/~amaas/data/sentiment/
利用 tensorflow_datasets 导入数据集, 将评论和标签放入表中,并转换成numpy格式
import numpy as np
train_sentences = []
train_labels = []
test_sentences = []
test_labels = []
for s, l in train_data:
train_sentences.append(str(s.numpy())) # s.numpy()获取其数值
train_labels.append(str(l.numpy()))
for s, l in test_data:
test_sentences.append(str(s.numpy()))
test_labels.append(str(l.numpy()))
train_labels_final = np.array(train_labels)
test_labels_final = np.array(test_labels)
vocab_size = 10000
embedding_dim = 16
max_length = 120
trunc_type='post'
oov_tok = "<OOV>"
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length)
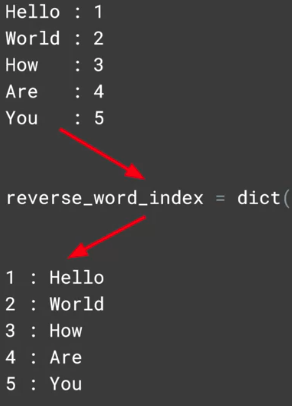
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
print(decode_review(padded[1]))
print(training_sentences[1])显示结果:

model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()嵌入的结果将长度为句子和二维数组 => 一维数组
输出模型结果为:

num_epochs = 10
model.fit(padded, train_labels_final, epochs=num_epochs, validation_data=(test_padded, test_labels_final))
10个迭代,准确度为:

e = model.layers[0]
weights = e.get.weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)输出结果为:(10000, 16) 词汇表中有10000个单词,以16维工作
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])为了打印出来,需要将键值对进行调换:
为了在3D空间可视化,首先将词典和向量分别输出成文件 meta.tsv 和 vecs.tsv
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word+'\n')
out_v.write('\t'.join(str(x) for x in embeddings)+'\n')
out_v.close()
out_m.close()即该单词在向量上的每个维度。上传到 http://projector.tensorflow.org/
点击左侧Load

第一步:上传向量 vecs.tsv
第二步:上传元数据 meta.tsv

3D可视化效果
可以点击蓝点,或者搜索单词
关于损失函数(loss function),作为对预测的信心。随着预测的准确度上升,每个预测的置信度实际上下降了。常常出现在文本文件中。
一种方法是调整超参数时的差异:
vocab_size = 1000 # 之前是 10000
embedding_dim = 16
max_length = 16 # 之前为 32
trunc_tyoe = 'post'
padding_type = 'post'
oov_tok = "<OOV>"
training_size = 20000减少词汇量、用较短的句子,减少填充的可能性

另一种方法是尝试使用embedding
vocab_size = 1000 # 之前是 10000
embedding_dim = 32 # 之前为 16
max_length = 16 # 之前为 32
trunc_tyoe = 'post'
padding_type = 'post'
oov_tok = "<OOV>"
training_size = 20000
更多关于tensorflow datasets 中 imdb_reviews 的内容:
来源:https://www.tensorflow.org/datasets/catalog/imdb_reviews
















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









