







##Tensorflow 之 embedding(一)
####目录
1. embedding的含义
2. tensorflow中embedding实现流程
3. embbeding中如何进行查表
4. 如何训练得到embedding表
####一、embedding的含义
说一个常见的应用,例如在机器翻译应用中,当我输入中文 “我这是在干嘛了?”,然后需要将其翻译成英文,首先第一步你得需要让计算机知道你输入的内容吧,所以你需要将其进行数字化,但是数字化并不是随便给每个分词赋予一个数字,而是有根据的,例如,有三个词:猫、狗、泥土,我们进行数字化后得到对应的向量A,B,C,最起码得保证A与B之间的距离要小于A与C的距离吧。总之,这个过程是有 很多讲究的,那么embedding就是其中一个经典的算法,也就是Google在2013年提出的Word2Vec工具,将单词向量化的一种工具,相比One-hot编码,Embedding方法能够得到更紧凑的向量表示。
####二、tensorflow中embedding实现流程
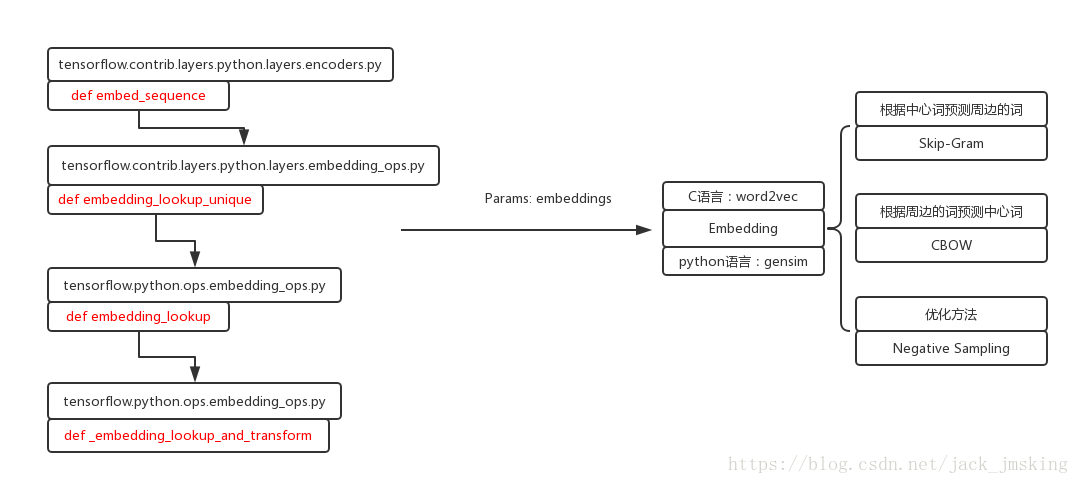
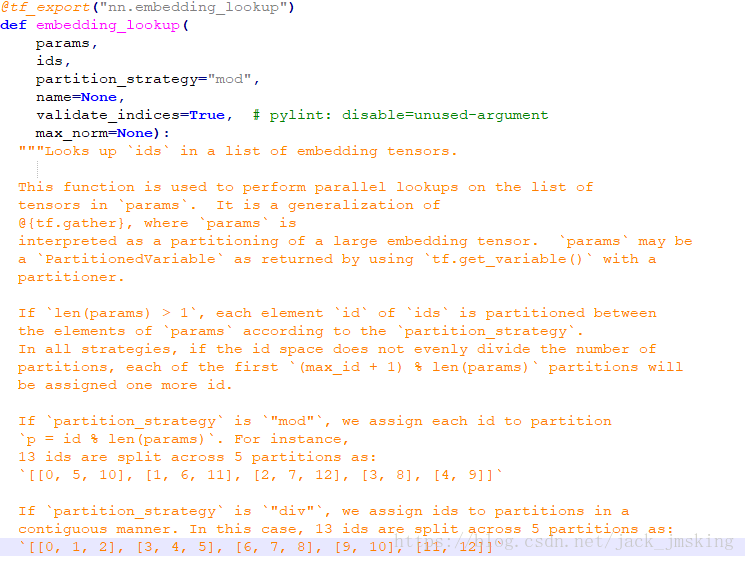
Tensorflow中的embedding主要用于编码端和解码端中对输入的Embedding,接口如下所示:
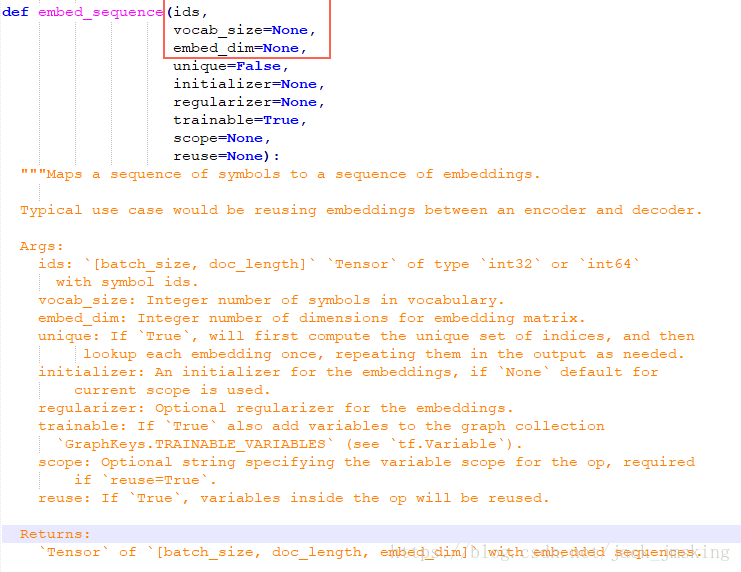
其主要的几个参数:ids、vocab_size和embed_dim,代码实现如下:
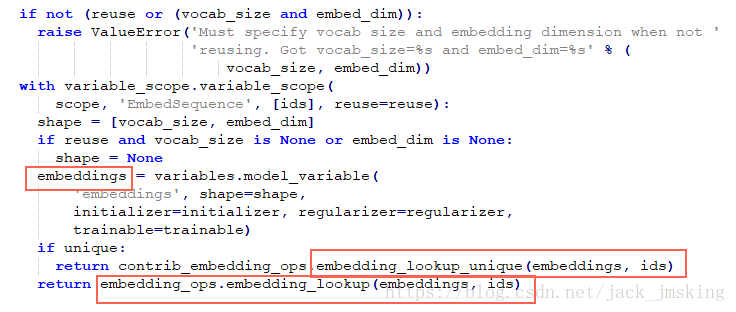
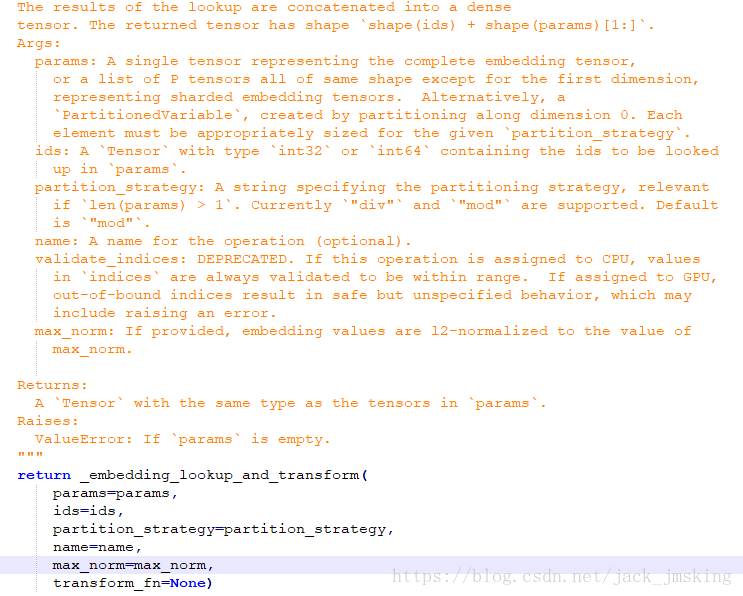
embeddings是通过训练得到,稍后详细讲解。当得到embeddings后,会调用
embedding_lookup_unique或embedding_lookup方法。
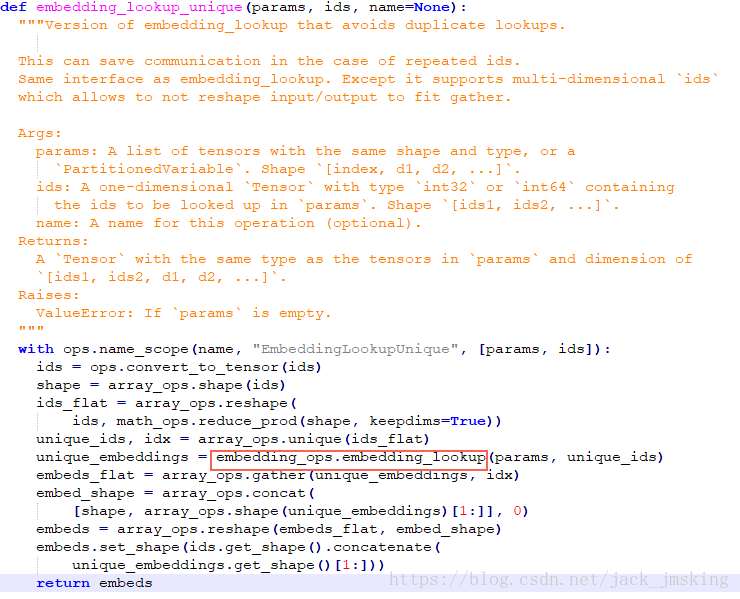
从上面的源代码中可以看到embedding_lookup_unique方法也会调用embedding_lookup方法,接着跟下去有:
再接着跟下去有:
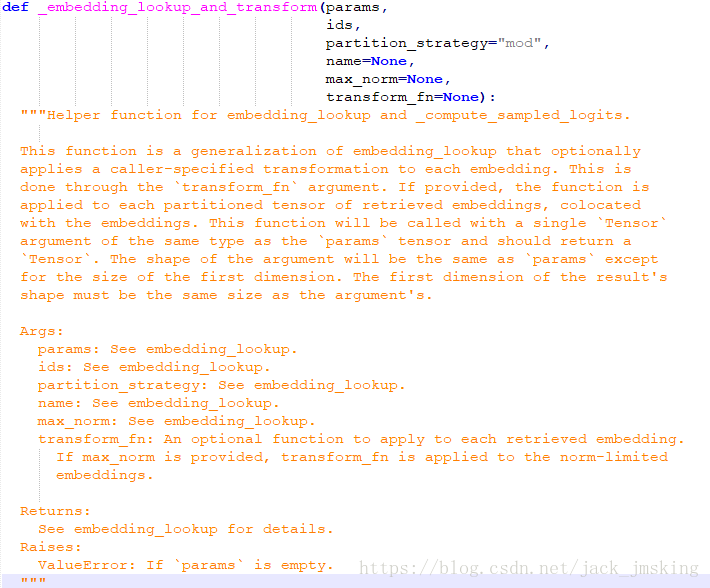
最后调用了一个私有方法,现在我们在源代码级知道了tensorflow进行embedding的大致过程,接下来就是详细的讲解当输入一个词,怎么就得到一个向量了?
####三、embbeding中如何进行查表
在embedding_lookup源代码里面,有三个重要参数params, ids以及partition_strategy,我们着重介绍参数partition_strategy,在embedding_lookup方法里面进行了详细的介绍,可能开始会有点懵,所以在这里通过几个简单的例子进行说明:
Example 1:单tensor下,即embedding_lookup方法中 len(params) = 1
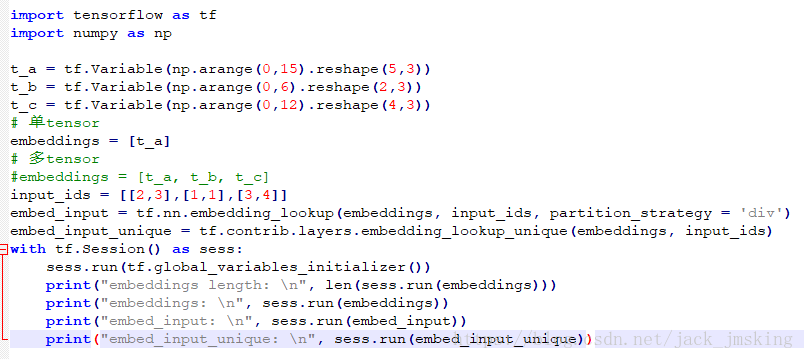
结果如下(修改partition_strategy=’mod’,其结果一样):

我们可以得出单tensor下,有以下结论成立
1.embedding_lookup和embedding_lookup_unique方法得到的结果是一致的
2.partition_strategy参数不起作用
此外我们还需要知道为什么得到的结果是这样的。在此我们基于embedding_lookup方法进行讲解,其过程如下(注意:在多tensor下,且partition_strategy=’mod’ 时,其过程是不同的):

1.对embeddings从0开始递增编号(本例中为0、1、2、3、4)
2.对输入的input_ids,取embeddings中对应编号的向量(本例中为[ [2,3], [1,1], [3, 4] ])
Example 2:多tensor下,即embedding_lookup方法中 len(params) > 1
(1). partition_strategy = ‘div’
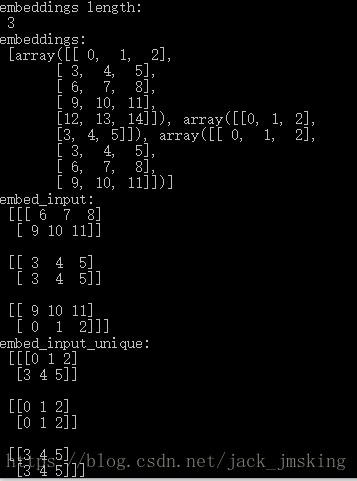
(2). partition_strategy = ‘mod’
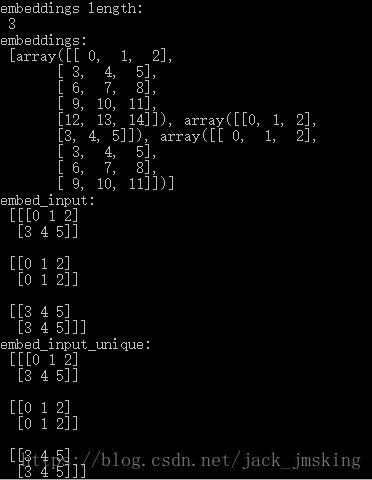
我们发现在多tensor下,发现如下几个现象:
1.在partition_strategy=’div’ 时,embedding_lookup与embedding_lookup_unique方法得到的结果是不一致的
2.在partition_strategy=’mod’ 时,embedding_lookup与embedding_lookup_unique方法得到的结果是一致的
3.在partition_strategy取不同值时,embedding_lookup的值是不同的,但是embedding_lookup_unique的值是相同的
基于上面的几个现象,我们会问,这个结果是否是巧合了?为此我们必须知道这个partition_strategy到底是如何工作的。
[1]. 首先我们基于embedding_look_up方法进行讲解(参数partition_strategy=’div’):
(1)首先得到embeddings不同分区下维度为0的长度(在这里你可以理解为得到embedding共有多少行,例如本例中共有3个tensor,其长度分别为5、2、4,所以共11行)
(2)然后进行分区,这里有三个tensor,即需要分成三个区,当不能均分时,优先依次从前几个分区增加元素。例如在本例中,11/3不能整除,所以划分方式为4、4、3,即从第一个、第二个tensor中取4个元素(这里的元素也是tensor),从第三个tensor中取三个元素,没有的即为空,如下所示,第一个tensor虽然有5个元素,但是只取前面4个,所以第五个元素丢弃掉,第二个tensor需要取4个元素,但是只有2个元素,所以其中有两个元素为空,当访问这两个元素时(即6和7),将会报错。

(3)然后通过embedding中的 (id) div (分区数) ,将得到的结果升序排列,前四个(0、1、2、3)划分到第一分区,中间四个(4、5、6、7)划分到第二分区,最后三个(8、9、10)划分到第三分区。
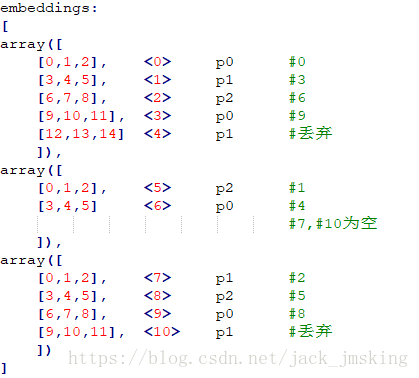
[2]. 接着我们基于embedding_look_up方法进行讲解(参数partition_strategy=’mod’):
(1). 对于前两步同partition_strategy=’div’ 是一致的,对于第三步中,div模式下是从0依次递增,而在mod模式下,是通过embedding中的 (id) mod (分区数) 来决定划分在哪一个分区的,如下所示,其中<>对embeddings进行了编号,p表示所属分区,#表示 id对应的embedding,例如 <2> p2 #6 表示id为6时,输入第二分区,其对应的编号为<2>的embedding。(因为id=0、3、6、9时,id mod 3 == 0,所以属于第一分区,依次对应第一个tensor的前四个元素),在该模式下,当访问id为7或者10时将会报错。
当我们清楚了embedding_lookup的实现方式了,也理解了partition_strategy参数的含义,那么接下来我们来详细的分析embedding_lookup_unique方法的实现方式。
我们知道在embeddings为单tensor的时候,embedding_lookup与embedding_lookup_unique方法的结果是一致的。所以在此我们仅讨论多tensor的情境下。
首先我们把embedding_lookup_unique的源代码直接拿过来了,然后在里面增加了几个print语句以便查看结果。
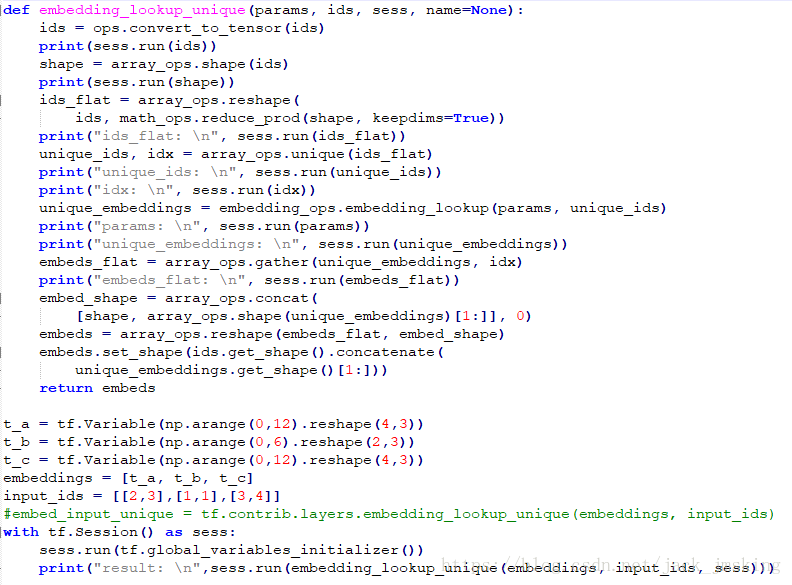
运行后其结果如下所示:
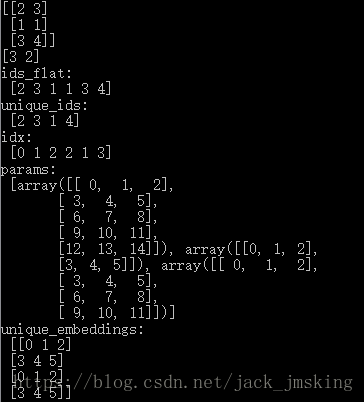

我们将对其中的结果进行详细的分析,首先是ids_flat,unique_ids和idx,其对应结果如下所示,ids_flat是对传入的参数ids进行展平,然后对其进行去重得到unique_ids,而idx记录了ids_flat中的每个元素在unique_ids中的位置。

接下来进入我们之前的分析的embedding_lookup方法中,源代码中直接采用的是mod的分区策略,因此得到 unique_embeddings,那么如何根据unique_embeddings得到原输入ids的embeddings呢?我们便借助上面的映射关系idx得到,例如id=2,其embedding即为unique_ids <0>位置处的值。
####四、如何训练得到embedding表(待续)

















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









